
Most data science leaders expect their companies to customize large language models for their enterprise applications, according to a recent survey, but the process of making LLMs work for your business and your use cases is still a fresh challenge.
Building a custom LLM deployment raises a lot of questions. How do you host this enormous model? Do you start from scratch or with an off-the-shelf model? Do you go open source or closed source? How do you serve the model, and who do you serve it to? How do you monitor its output? What other tooling do you need to bring it into production?
But the most important challenges center on data. When it comes to AI, your proprietary data is your moat. Using your data properly creates a competitive advantage no one can take away. However, how you identify, clean, and curate the right data to customize your own LLM has a big impact on your model’s ultimate value—and doing it right takes a lot of work.
That work breaks down into two stages:
- Preparing a corpus of unstructured text for self-supervised pre-training. This is the stage during which the model learns the relationship between words.
- Preparing a corpus of prompts and responses for instruction tuning. This is the stage during which the model learns how to follow instructions and build responses.
Below, we’ll break down the challenges associated with each stage and approaches to tackling them.
Customizing LLMs is imperative for enterprises
Large language models make for exciting demos, but solve few—if any—business problems off the shelf. The generalized nature of their training data and the semi-random nature of their outputs create unignorable shortfalls in accuracy.
But their potential has captured business leaders’ imaginations.
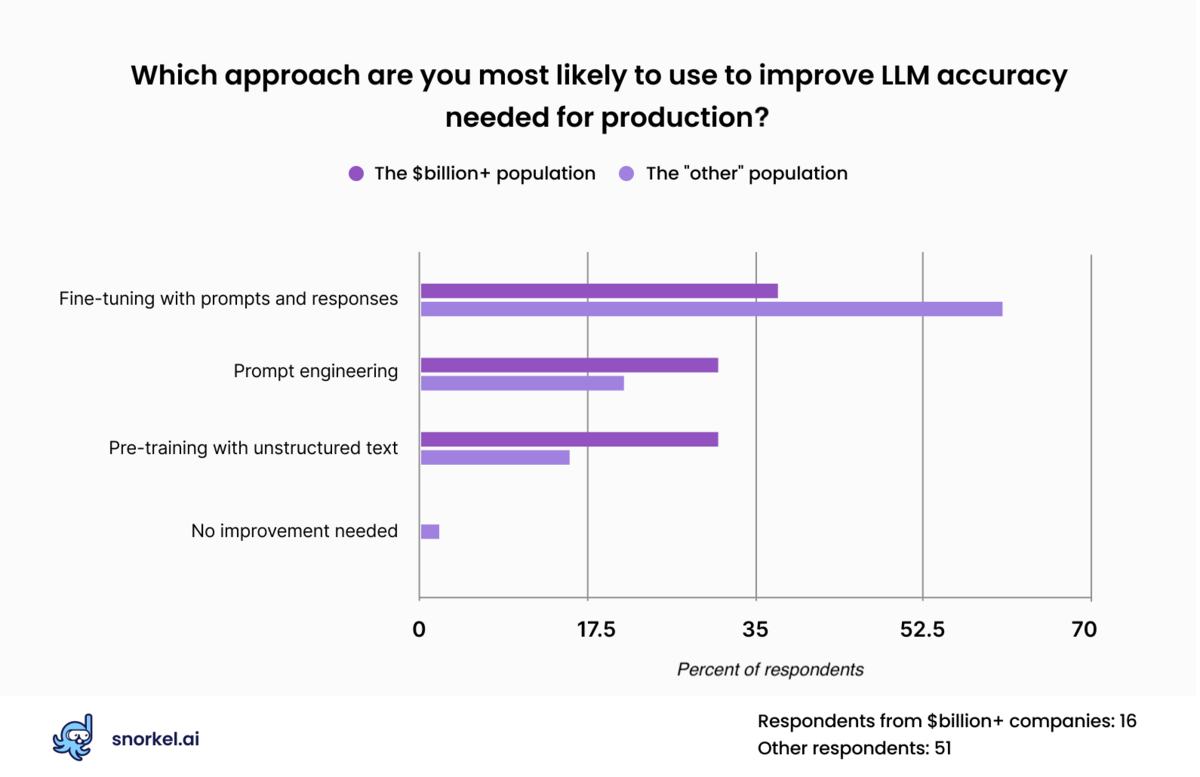
During our The Future of Data-Centric AI virtual conference, we asked attendees how they expected to coax production-level accuracy out of LLMs.
The aggregate data offered these clear takeaways:
- All respondents from companies with a valuation of at least a billion dollars said that zero-shot responses from off-the-shelf models were insufficient.
- About 75% of all respondents said they expected to use data to heighten LLM performance before they would consider it production-ready.
- Most said that they would expect to fine-tune their data with prompts and responses.
- Nearly 20% of responses said they would pre-train the model with unstructured data.
Pre-training with unstructured data
Pre-training with unstructured data sounds simple: gather proprietary data from across your organization and dump it all into a self-supervised learning pipeline. But it’s not that straightforward.
Before pre-training with unstructured data, you have to curate and clean it to ensure the model learns from data that actually matters for your business and use cases.
Data selection
First, you need to choose which sources of textual data you want to use. Do you want to dump all text from your organization’s Slack workspace into your corpus? Probably not. While Slack represents a rich source of insight into your organization’s focus, knowledge, and culture, it also holds a lot of irrelevant and (more importantly) sensitive conversations.
Pre-training an LLM on an omniscient view of your organization could cause it to surface confidential information, raising legal and compliance concerns. Other potential data sources, such as company emails, pose similar problems.
Casting too wide a net could also degrade rather than improve performance on the tasks you care about most. A recent study on the composition of pre-training corpora found that wide-ranging data sets generally created better-performing LLMs, but omitting or filtering data sources improved responses on more specific tasks and reduced the likelihood of toxic responses.
To get the most out of your unstructured data sources, you must carefully select which subsets to use.
Potential sources of pre-training documents:
- Company/community chat platforms, such as Slack or Discord
- Customer-focussed discussion forums
- Company emails
- Marketing materials
- Company website
- Internal company documentation
- Other proprietary data
Data cleaning
Once you’ve narrowed down your sources of unstructured data, you need to clean it.
Your curated data will fit the general shape of what you’re looking for, but it will still have complications and rough edges:
- Irrelevant information
Project-specific Slack channels (as well as many other data sources) will likely contain irrelevant side conversations. Data scientists can clean this up ahead of pre-training in a number of ways. For example, by generating embeddings for a wide sample of texts, you can use unsupervised clustering techniques to identify the topics in the data. This would provide a strong guide for what portions of the embedding space to remove. - Duplicate information
Each time someone copies and pastes an email, each time they cross-post a message from one Slack channel to another, that’s duplicate text. According to Julien Simon, chief evangelist at Hugging Face, removing those duplicated texts can create a noteworthy performance improvement. You can weed out these duplicates during the data-gathering process. In some cases, this may be as simple as using rules-based approaches to split and sort the data. In others, text-embeddings and similarity search can go a long way.
Pre-trained but not fine-tuned
Once a data science team carefully selects data sources, minimizes irrelevant information, and deduplicates repeated text, they can select a large language model architecture and pre-train it. But it won’t yet be ready for use, bringing us to step 2.
Instruction-tuning
Organizations can build significant performance improvements on their highest-priority tasks in multiple ways. While reinforcement learning with human feedback (RLHF) often yields positive results, this process can be expensive, labor-intensive, and likely beyond the reach of most companies.
Instruction tuning offers a more scalable solution. In some cases, data teams can meet their performance goals by fine-tuning with prompt and response alone. To do that, they must curate the right dataset by identifying prompts and response analogs, filtering them for quality, classifying them by task, and establishing a class balance for the training set.
Finding training prompts and responses
The first step to instruction tuning is to identify appropriate prompt and response pairs. Depending on the targeted task, developers can do this in many ways. Below follow three possible approaches, from least to greatest effort:
- Use an existing training data set. In April 2023, Snorkel AI and Together.AI worked with a group of collaborators to build the open source RedPajama LLM using two open source repositories of prompt and response documents. Our researchers then created statistically significant improvements to that model by carefully curating the training data. For a proprietary general-purpose model, such public data sets may be sufficient.
- Create a dataset through data mining. Prompt and response analogs could include any dialogue-like written text, such as forum posts, text messages, and FAQ documents. In this approach, developers identify likely prompts (such as short sentences that end in question marks) and then use heuristics to identify the best response, such as the top-voted response.
- Hand-build prompt response pairs. Data teams struggling to find enough relevant data can hand-build their own dataset. To ensure quality, project leaders can supply annotators with responses to write prompts toward. Databricks did this on their Dolly 2.0 data set by giving people paragraphs from Wikipedia. You may be able to do the same with texts from your company’s domain or documentation.
Whatever method you use, you will be left with a large number of prompts and responses of varying quality. The next step is to pare that down to the prompts and responses most likely to improve your model.
Curating prompt-response pairs
Once you have prompt-response pairs, you need to curate them—both for quality and for task balance.
- Quality
Due to the nature of language, quality is subjective and difficult to measure. Some open-source datasets include human-supplied quality ratings, which isn’t helpful when working with proprietary data. Data teams can ask annotators to label responses for quality, but that isn’t a sustainable solution.
For a scalable solution, our researchers built an open source response quality model that may be useful to teams trying to tackle this problem—either as a final solution, or a starting point for their own.
- Balance
Prompts also need to be categorized by task to balance the final training set according to prioritized tasks. The correct approach to ratios on this topic is still an open question and may vary depending on the organization’s priorities. Generally speaking, you’ll want more examples for tasks you expect to encounter a lot, and fewer for tasks that you expect your model to perform less often.
At the end of this process, you have your own LLM pre-trained and instruction-tuned. But that’s only the beginning of the journey. Production LLMs require continuous maintenance and LLM evaluation on specific tasks and use cases across the organization.
Customizing LLMs is challenging but achievable
Building out a custom LLM creates value for enterprises, but also presents a big task. The data development challenges described above are only a fraction of those that stand between wanting a custom, organization-specific large language model and deploying one in production.
But they’re also the most important.
As a final note, this only describes the beginning of the journey. How users interact with large language models will change over time, necessitating continuous maintenance such as periodic instruction tuning using methods like RLHF. But that’s a topic for another post.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.

Kristina Liapchin
Lead Product Manager
Kristina is currently leading product at Snorkel AI. She oversees the core capabilities that enable enterprises to leverage and implement state-of-the-art foundation models and LLMs in practical, real-world scenarios. She is passionate about using data and technology to solve real-world problems.
Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

