
Programmatic labeling moves a classic technique from interesting to high-impact
So much of real-world AI development entails working with text data that’s messy — in fact, 80%+ of enterprise data is unstructured. And while state-of-the-art models get a lot of the glory, creating the training data that conveys what your model needs to learn is more often the biggest determiner of AI application success.
This is the heart of Snorkel Flow’s mission: to make this critical part of the AI development process — labeling training data — faster, while also making the quality of the resulting training data far better. We pioneered programmatic labeling to transform data labeling from a tedious, static effort done as a precursor to the “real” AI development workflow to a software-like experience that’s central (and crucial) to the end-to-end AI workflow.
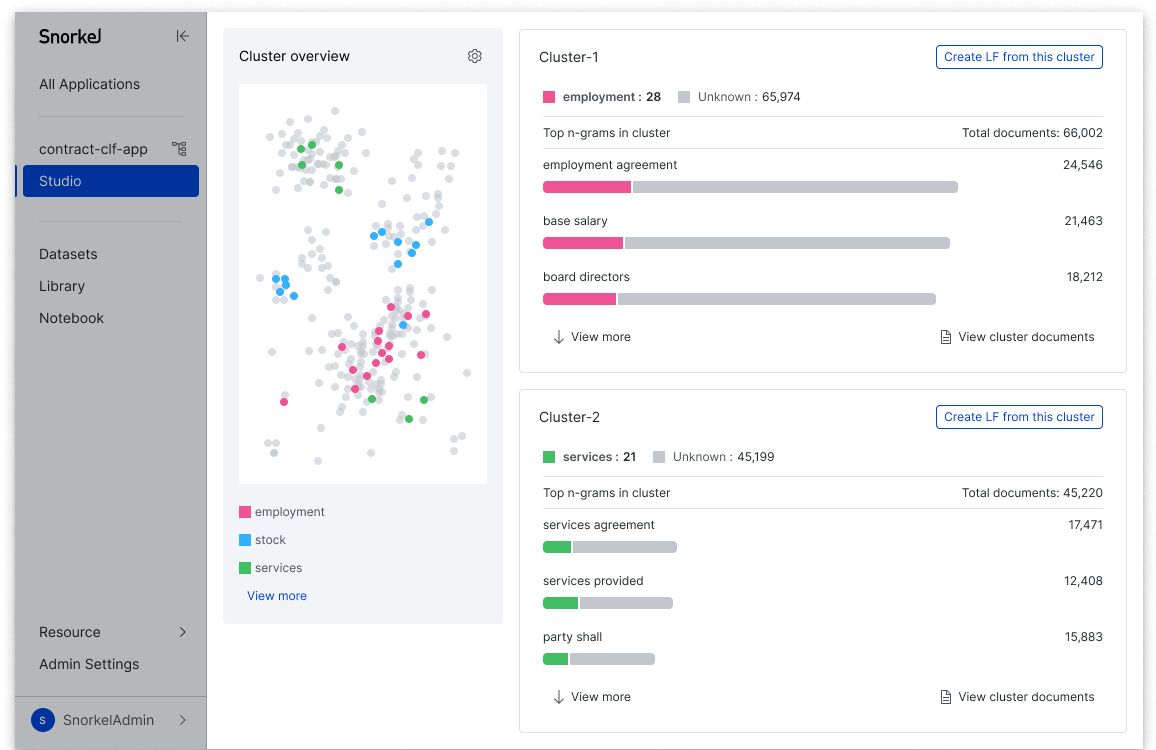
Today, we’re excited to share our most recent innovation on this front, Cluster View. With this feature you’re able to quickly create and cluster embeddings, but beyond simply getting a general orientation as you explore your data, you can take immediate action by using the clusters to label data programmatically. Cluster View takes you from the overwhelm of a massive unlabeled and unstructured dataset to quality-labeled training data at what can feel like “magic-button” speed.
Speed AI development with rapid training dataset creation with Cluster View. With powerful discovery and automation capabilities you can:
|
The big picture (literally)
Let’s start out with the problem. AI teams often need to work with a dataset that they don’t know much about. Together with their domain experts, they work through individual documents one-by-one to understand how to label in the first place. For many tasks, this is a prerequisite to establishing the label schema for the project.
A helpful, tried-and-true strategy is to compute embeddings for your data and then use those to identify semantically similar groups. This is especially helpful when you’re not sure where to start. Clustering data using embedding distance can surface natural groupings to inform how you might define (or refine) your label schema.
Yet, while clustering embeddings is a great way to generally orient yourself while exploring your data, it isn’t always actionable beyond that point. Clusters in your data are typically correlated with specific classes, but are rarely entirely separable or clean enough for labeling ground truth in bulk. You still face the daunting task of manually labeling tens or hundreds of thousands of individual data points. Maybe you can outsource the labeling, or use tooling to marginally accelerate your labeling, but at the end of the day, you’re constrained by the time it takes to review and label documents one at a time.
The Snorkel Flow solution
Snorkel Flow is uniquely able to make these embedding-based clusters actionable using programmatic labeling powered by labeling functions. These are essentially simple programs that encode the rationale behind a labeling decision, whether that be human insight, an existing organizational resource (such as existing noisy labels or legacy models), or in this case, a portion of the embedding space identified as being correlated with a particular class.
It’s ok if your labeling functions are noisy, label imperfectly, or conflict with one another in some places. Our label model will intelligently aggregate and reconcile them in order to auto-label training datasets that are larger and have higher quality labels than any individual source could produce on its own.
With Cluster View, we created a new labeling function type tailor-made to capture the insights from your embeddings and apply them at scale; this is especially powerful as a way to warm-start your labeling process. You can label large swaths of your dataset upfront even before you’ve trained your first model. To accelerate the labeling workflow even further, Snorkel Flow can auto-generate these new cluster labeling functions using a small amount of ground truth data. From there, all you need to do is accept or reject them, rather than writing them from scratch.
Let’s dive into the Cluster View workflow to explore the full value our team has built.
Create your Cluster View
When building an application in Snorkel Flow, you can click a button to create a Cluster View using state-of-the-art embedding techniques on your data. Already have high-value embeddings? You can easily bring them into the platform.
From there, the platform uses smart clustering algorithms developed by our Research team to take the guesswork out of this step for you. Snorkel Flow identifies meaningful groups of data and displays them using an interactive data map.
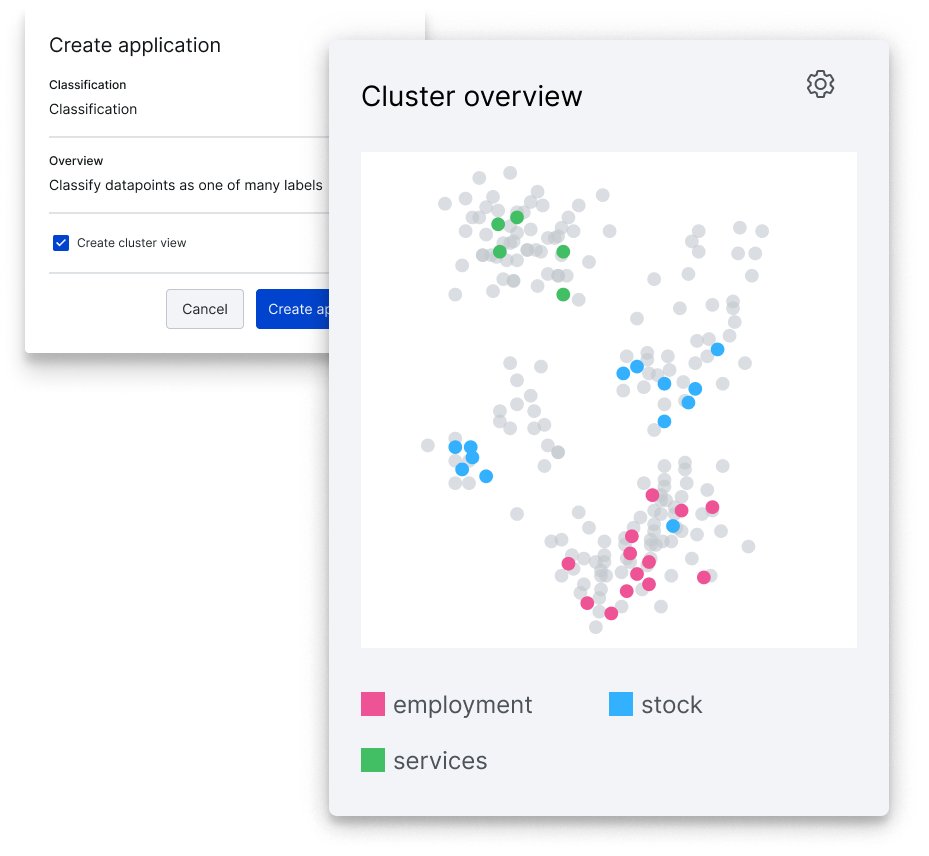
In addition to the plot, you’re shown data-driven cards of information for each cluster. These help you explore your clusters at varying levels of detail to uncover hidden structure in the data and evaluate whether that structure is meaningful based on your knowledge of the data and problem at hand. This takes you from staring at a dauntingly large data set of complex text data to a curated, meaningful visualization of your data in just a few minutes.
Even more so than with image data, understanding a set of text documents at a glance is a hard problem; there’s no “thumbnail” view that’s easy to scan. We’ve helped solve for this in two ways. First, we use text mining strategies to pull out salient n-grams that distinguish each cluster of data from the others. Second, you can review relevant snippets of individual documents right in the same UI pane — this delivers on a core principle of Snorkel Flow: keeping your data front-and-center throughout the AI development workflow.
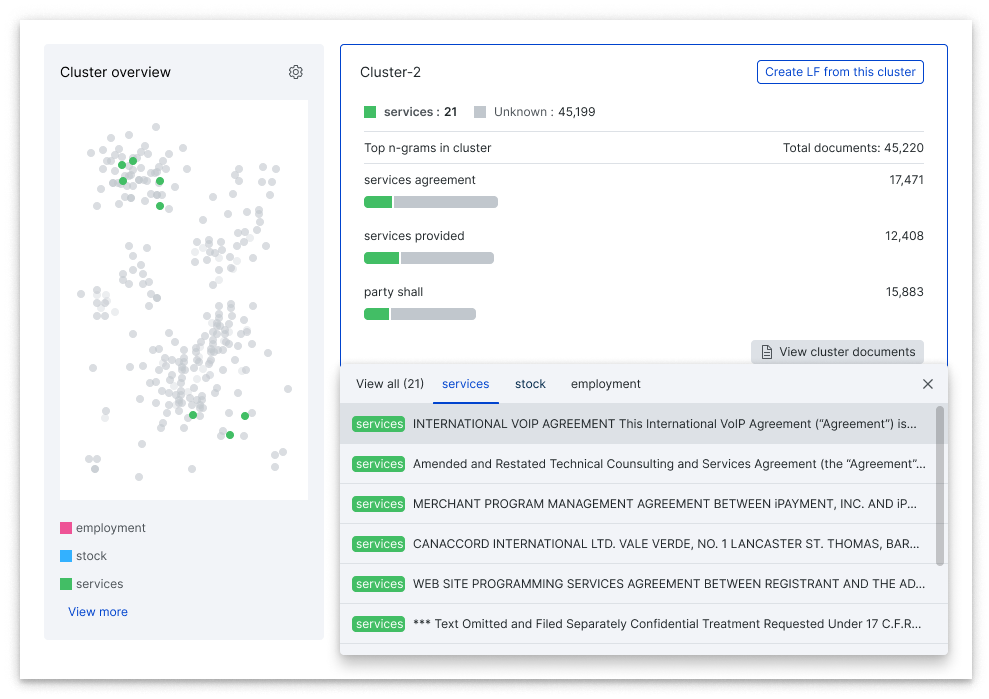
Beyond the initial clusters, you can explore your data more granularly using Snorkel Flow’s search functionality to filter on data points that match certain queries. For example, you can inspect the embeddings for all documents that contain a certain keyword or match a given regular expression. As you slice through your data to drill deeper, clusters are automatically recomputed to show you the new distribution of your filtered documents across clusters.
Now that we’ve made data exploration from embeddings more powerful, transparent, and granular, let’s talk about how we make it actionable.
From insight to action: Cluster Labeling Function
While the value of data exploration and understanding your data from Cluster View is awesome, the game-changer is our ability to pair Cluster View with the programmatic labeling technology Snorkel Flow pioneered.
For each of your clusters, Snorkel Flow can use a small amount of ground truth data (think a hundred labeled documents, not thousands) to auto-generate Cluster Labeling Functions that you can review and choose to accept to be used as sources of weak supervision to label your training data en-masse.
To inform your decision of whether to save an auto-generated cluster labeling function, you can use your expert judgment and insight into each cluster as well as the estimated precision and coverage of that labeling function which we provide automatically in the platform. This same auto-generated labeling function option is available on filtered views of your clusters as well, allowing you to easily create targeted, granular labeling functions.
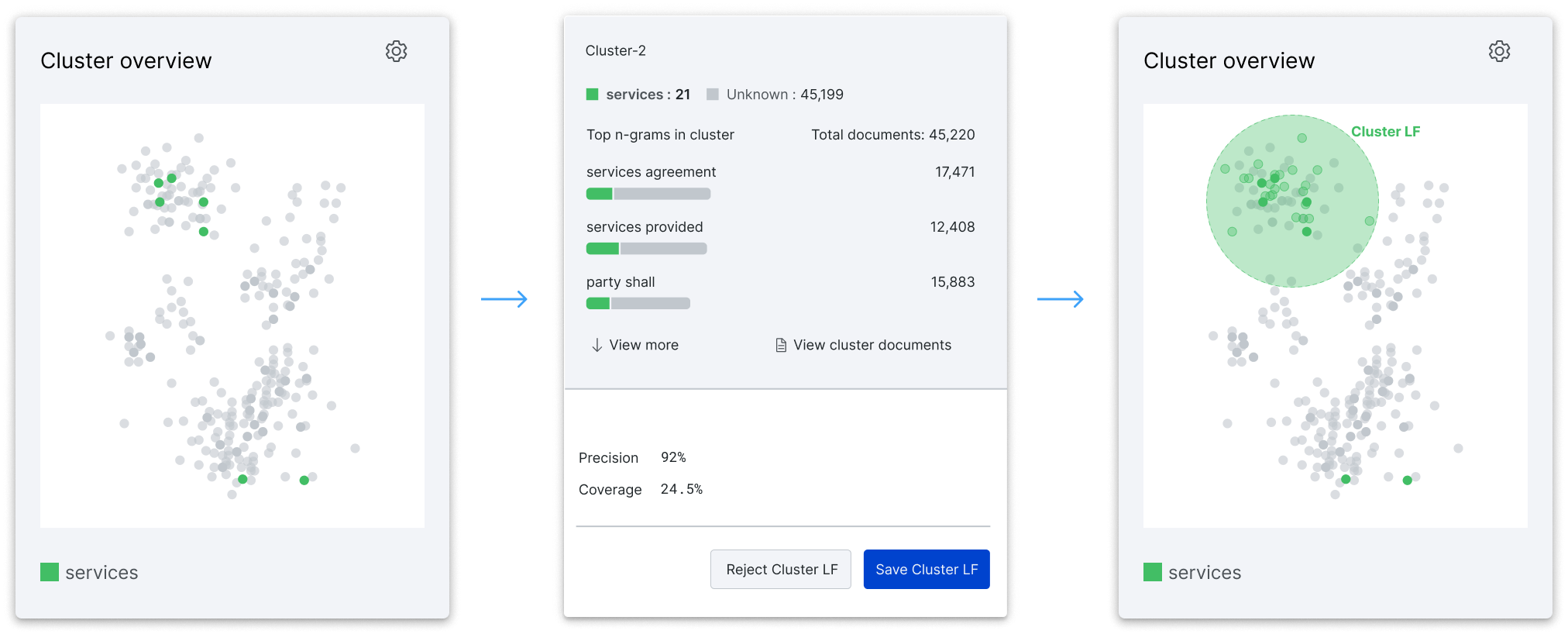
These clusters are parameterized such that even new data points that you may add to your dataset in the future can be identified as belonging to that part of the embedding space. And importantly, these parameterizations are more intelligently selected than simple centroid or distance-based approaches that suffer from the curse of dimensionality and tend to underperform in the higher dimensional spaces typical of unstructured text.
These auto-generated labeling functions are a great way to bootstrap your labeling effort, and the insights from cluster exploration provide high-impact inspiration for additional labeling functions you can quickly write in Studio.
Faster time to AI delivery
If you’re stalled or bottlenecked on training data labeling, especially when it’s not clear where to start, Cluster View is a massive accelerant.
To play back the workflow: we take your large, unstructured dataset of complex text documents and provide you with a visualization of embedding-based clustering at the click of a button.
Next, you’re able to inspect each cluster to understand the meaning behind it and explore explicit data points. You can filter your clusters using the search functionality to see how specific slices of data distribute across clusters to uncover more nuance.
As you understand clusters, you can take informed action in-platform by saving and applying auto-generated labeling functions that are used to programmatically label your dataset in minutes.
From there, you continue the core Snorkel Flow workflow of label, model, and adapt. This means using immediate feedback from model-based error analysis to quickly identify error modes and iterate programmatically to improve. On the way to production (or after going live) you can easily adapt to changes by editing a few labeling functions, never wholesale manual relabeling.
To see Cluster View in action, request a demo of Snorkel Flow today to see Cluster View in action!

Molly Friederich
Director of Product Marketing
Molly leads the product marketing team at Snorkel AI, partnering closely with cross-functional teams to bring the value of data-centric AI to AI/ML teams.
Prior to Snorkel AI, she spent nearly six years at SendGrid and Twilio, supporting organizations’ ability to engage customers using email APIs and marketing software.
Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

