Amanpreet Singh, Lead Researcher at Hugging Face gave a presentation entitled Towards Unified Foundation Models for Vision and Language Alignment a Snorkel AI’s Foundation Model Summit in January. Below follows a transcript of his talk, lightly edited for readability.
I am currently a lead researcher at Hugging Face, where I’m working on multimodal models. Before this, I was working at Meta research where I used to work on vision and language problems, but also was helping on the production side of things with products like Marketplace, Search, and others. So it was all over the place.
Today, we are going to talk about foundation models for vision and language alignment. In the past few months or even years, there have been a lot of foundation models popping up around generative AI, specifically. You must have seen ChatGPT and two models before that.

In this talk, we will focus specifically on the vision and language alignment. How do we align the two modalities that exist separately, generally? The agenda today is to first learn how to build a unified foundation model, which is a unit paper from ICCV (International Conference on Computer Vision) 2021. Then we will learn how to take it a step further by pre-training it. And then finally, we will talk about some nuances of the evaluation—when we evaluate these models and how to step up these evaluations to the next step once we build these strong regional language-aligned models.

The question is, how do we build foundation models that can solve tasks across modalities?
By modalities I mean, specifically, NLP (natural language processing) or computer vision, and also the domains which require the combination of both of them. An example would be visual question answering, where you are answering a question based on an image, and then you are required to use both the text domain as well as the computer vision domain to answer.
Domain-specific tasks come with a variety of challenges, but first: why do we even need to care about this particular aspect of the field?
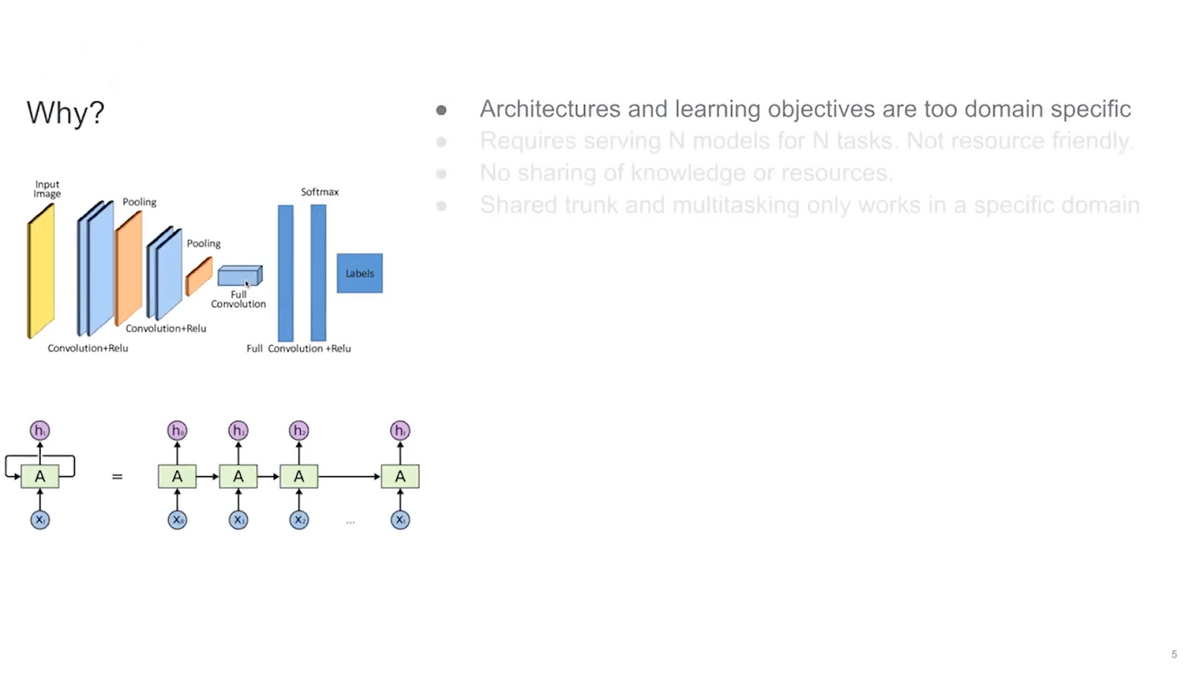
The first part of the answer is that the architectures and learning objectives are too domain-specific. If you think about vision, for the past few years before the transformers for vision were introduced, they were very specific to the vision itself and didn’t really work with text. And similarly, for the text before transformers were introduced we only had LSTMs (long short-term memory networks), which didn’t work for vision.
So the architecture is a learning objective today. For example, language modeling objectives or other objectives such as diffusion objectives really work well for vision or NLP, but they don’t work cross-domain.
Okay, why do we want a unified model?
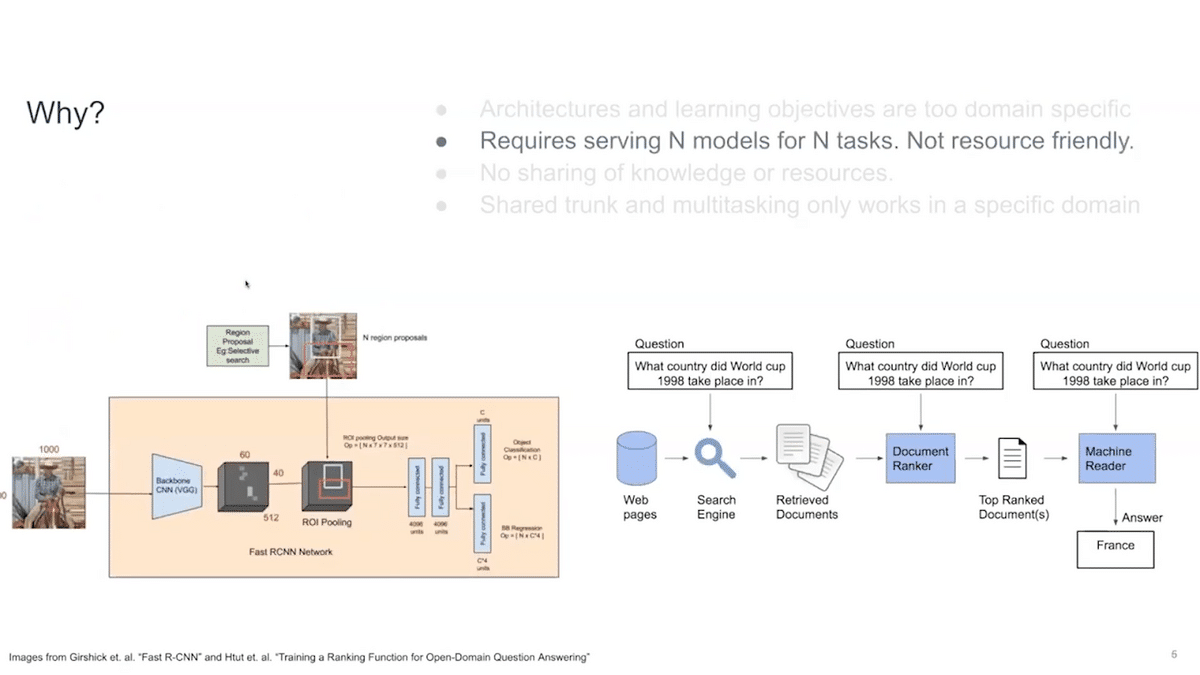
For N tasks, we need to serve N models. If you don’t have a single model, this is not resource friendly and actually consumes a lot of compute and is expensive.

Then, there is no sharing of knowledge or resources. BERT shares this common domain across all of the NLP tasks. And then, for example, Fast R-CNN shares its base for bounding box classification, but there is no knowledge sharing across domains.
For example, let’s say I learned something from vision. How do I apply that knowledge to NLP as well? There is no sharing of knowledge resources across domains, generally.

Then, the shared trunk and multitasking currently, is only working in a specific domain. For example, ChatGPT only works for text. It doesn’t incorporate images in any way. How do we move one step further?
Now we can discuss why we need to do this. What are the challenges we face when we start doing it?
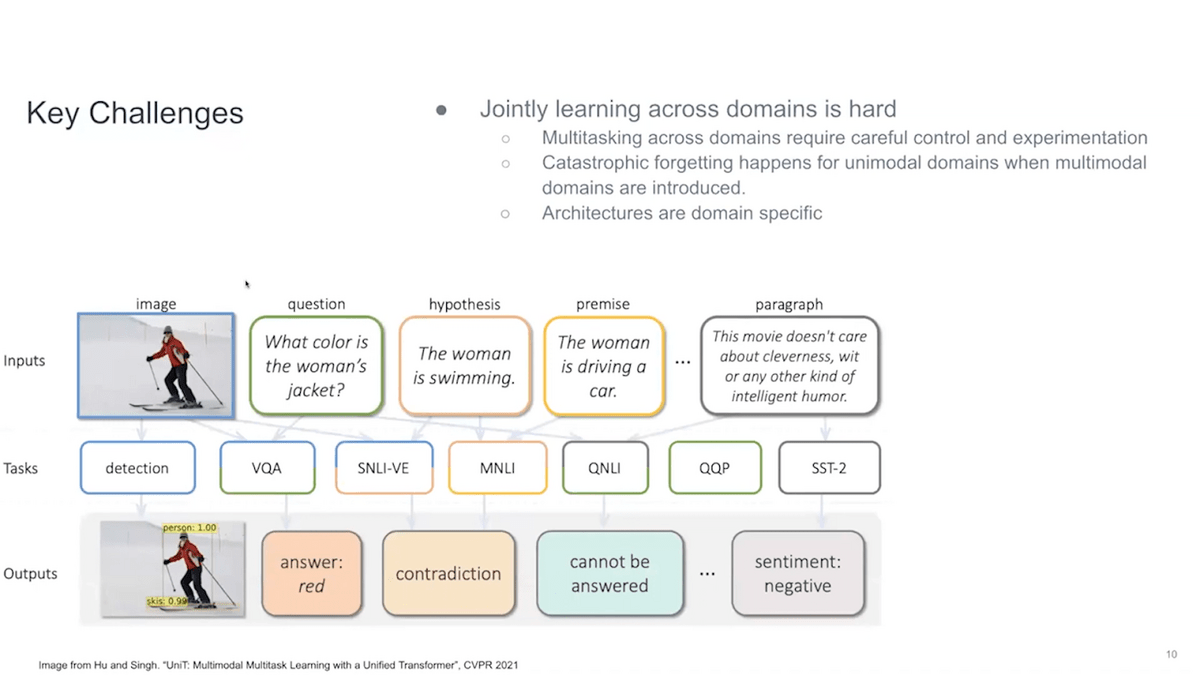
The first problem comes once you start moving beyond one single domain. Let’s say in this picture I’m showing you that we want to apply various tasks across domains. Object detection is a purely vision task. Then VQA (visual question answering) and SNLI-VE (Stanford Natural Language Inerence Visual Enhancement) require using both of the domains to answer or correctly predict these questions. Then MNLI (Multi-Genre Natural Language Inference), QNLI (Question-answering Natural Language Interface), and QPP (query performance predictor) are all of the GLUE benchmark tasks, which are NLP tasks, and only involve text. So if you want a model that works across all of these tasks, you need to do some sort of multitasking.
But, in general, whenever you go to do multitasking, it requires very careful control and experimentation. You can’t learn one of them and then lose the other information. So when you try to move from unimodal domains to multimodal domains, you usually lose information. There is a forgetting that happens. You do better at the combination modal task, but you start doing worse on the unimodal task. This is not something that we want.
Also, architectures are very domain specific. We have vision transformers, and we have transformers for text, but we can’t directly combine them.
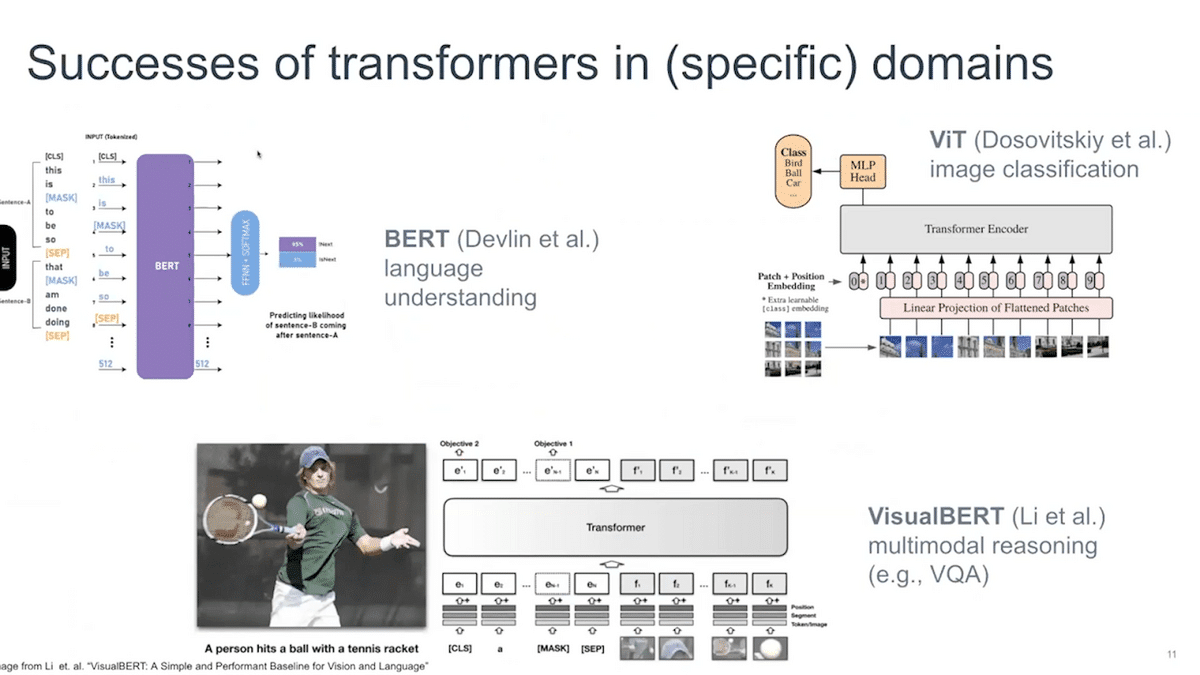
Let’s take a little detour to the history of the transformers. As you might know, in the NLP domain, BERT has been the starting foundation model. It basically was able to use a shared trunk to solve many tasks.
On the image side of things, vision transformers came in and overtook the vision domain. Similarly, in the combined form, where you have NLP as well as vision, you can use VisualBERT, which is a transformer alternative. You basically feed the images and text to this VisualBERT and then it can do a variety of tasks on multimodal reasonings, such as VQA and others we will see soon.
So transformers are now in all of the domains, including audio, so they have been quite successful in unifying the architectures.
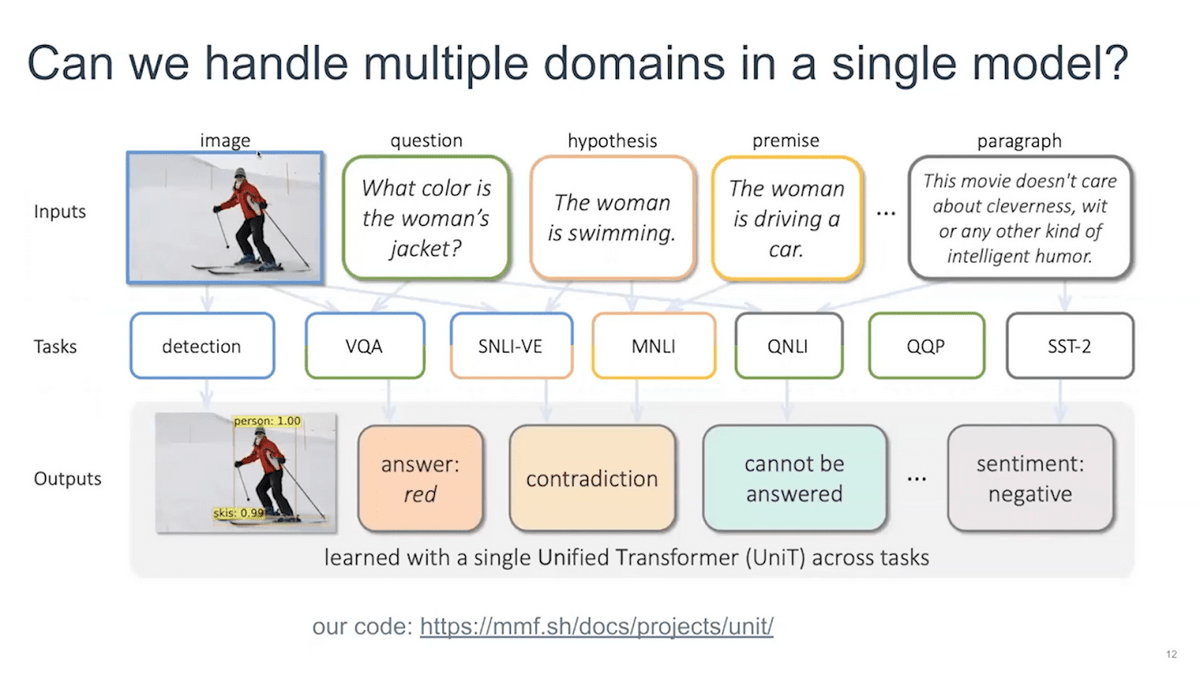
Can we actually help use transformers to handle multiple domains in a single model?
In this particular work, we try to do this by learning a single transformer model, which we call UniT, short for “unified transformer.” We want to address vision-only tasks, detection, multimodal reasoning tasks, VQA, and GLUE benchmark tasks—all within a single shared model.
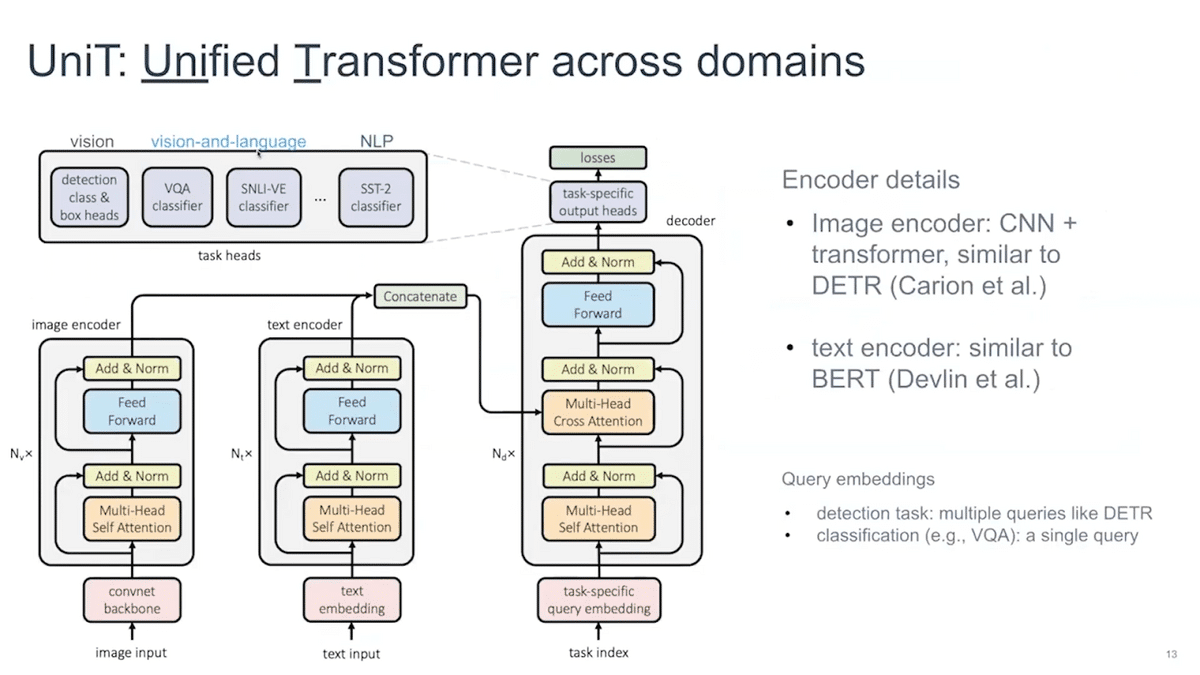
How do we do this? We extend the transformer encoder architecture, which you might have seen in translation applications, by allowing you to take either image input, or text input, or even both, and handle tasks across domains. This includes vision-only tasks like detection.
You can see there are two encoders here. We basically build two separate encoders for image and text inputs. And if both of them are present, we concatenate after the individual encoders and then pass them to the decoder itself. The question is: once you have this unified representation, how does a decoder know which task you are doing?
What you’ll do is you will have a set of query embedding vectors for multiple tasks that can produce not only stuff like bounding boxes for object detection but also other outputs like VQA. The security embedding vector also tells the model which particular task it is trying to do. This is how it works, and we call this model UniT. We hope that by training this model end-to-end on multiple tasks, we’ll be able to handle all tasks within one single model. When we train this, we train this model jointly on all of our tasks that we care about, whether it’s object detection or whether it’s any other sort of NLP task or VQA task.
In practice, does it work?
Yes, it does work. You have to do a little bit more control on the exact sampling ratio of the task. You can feed different inputs and get different query embeddings for different things. It does work out of the box. We can get it to converge on all of the seven tasks ranging from the ones that we discussed, and they can be addressed to a single encoder-decoder architecture.
In general, if you are doing only the image-only task, you can just pass on the image, not concatenate anything. Then for text, you only pass on the text. If they’re both, you just pass them both together and then pass it to a decoder. And then finally you collect its output.

These are some of the examples from object detection, question equivalence, and VQA where it actually works on all of the domains.
This actually gives us a unified model, a foundation model, to move forward, where we actually directly supervised training on all of the tasks.

The model that we just talked about was just supervised-trained on all of the tasks that we cared about. If you don’t do any pre-training, you leave a lot on the table.
There are other examples from the past. When you do BERT pre-training, you get awesome results on the NLP task. You can do pre-training on the vision transformers, and then you can see that you also got impressive results on all of the downstream vision tasks. You can also do something like VisualBERT or VLBERT where you actually pre-train on the image captioning dataset, and then you can just get impressive performance on the vision and language tasks as well.
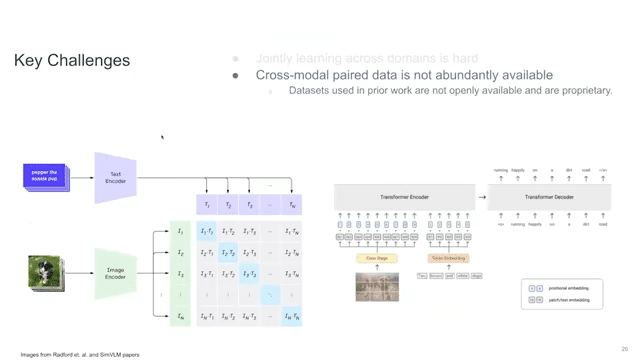
Jointly learning across domains is hard. The best tool that we have is UniT, but another problem that we face as researchers working on open domain problems is that the cross-modal paired data is not generally abundantly available. CLIP was trained on 400 million image-caption examples, but the data was never released. All of the datasets used in the prior work—for example, Google uses the JFT 1.8 billion dataset, which is their internal dataset—they’re not available openly and are proprietary.

For pre-training, we collected a dataset from all of the publicly available sources, which was around 70 million in image-text pairs. This collects basically everything that’s publicly available. After we collected this dataset, the LAION dataset also came out, which is around 400 million in a smaller subset, but also 5 billion in a larger subset. You can also look at it. The PMD is just a little bit cleaner than LAION in a general sense. You can pre-train on LAION than fine-tune on PMD.

The other key challenge after this is that, before, jointly training was hard, but also jointly pre-training across the domains was super hard. Our objectives don’t align with each other and are very domain specific. Language modeling is a very domain-specific task. Image masking is super domain specific. Then also caption masking or image-text matching is also domain specific.
These models are huge and they require massive compute. As you move toward multiple datasets, you require even more compute. Then, many vision and language datasets are not open source.

The next model that we want to talk about is FLAVA, which is “Foundational Language and Vision Alignment Model.” This particular model is one foundation model that works across CV, NLP, and V&L (which is “Vision & Language”), and it has impressive performance.
In the paper, we test 35 tasks across NLP, CV, and Vision & Language domains, and it has actually impressive performance on all of them. This is a massive step compared to UniT, where we only tested eight tasks and nine datasets. This is 35 tasks—huge compared to what we were doing before. The data and models and everything is public for this particular model.
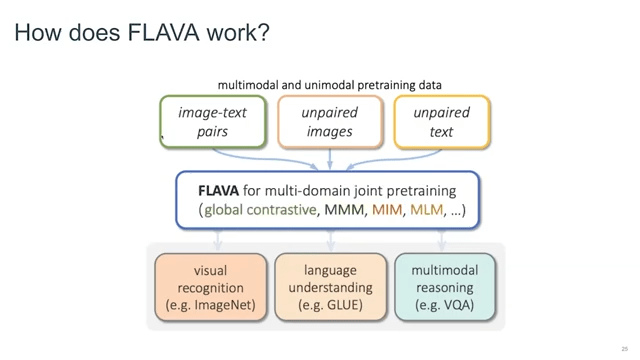
So what does it look like?
Think about all of the data that we have publicly available, which is unpaired text. All of the datasets such as VILE (Vial Imaging and Label Extraction), Common Crawl, and everything, which doesn’t really have images attached to them. Then unpaired images such as ImageNet and all of the vision classification datasets. And then the image-text pairs from PMD or LAION, for example. We want something in the middle—which can give you visual recognition, like ImageNet classification, and language understanding in GLUE as well, and then multimodal reasoning, for example, VQA, CLEVR, and all those datasets—in a single model. How do we achieve that?
So FLAVA is a multi-domain joint pretraining architecture or objective where you can leverage the objectives from all of the unimodal domains and just learn them jointly. In the FLAVA paper, we show how you can combine them together in a single architecture by extended unit and learn them together so that you can actually solve all of these tasks together by just fine-tuning or even doing zero-shot or doing linear prompting.
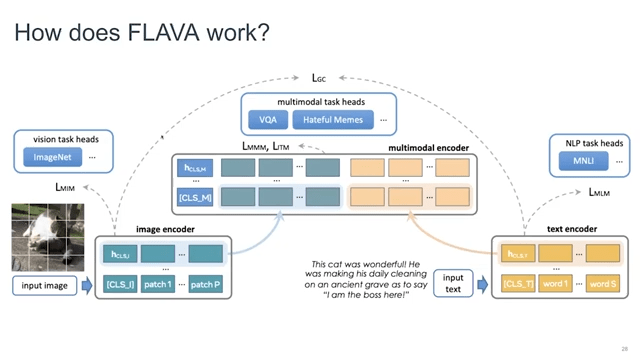
How does it work in practice?
We have tested mixing the encoders together. It doesn’t really work. You want to separate image and text recorders because they learn very different kinds of embeddings, so you want to separate them.
To avoid mixing responsibilities, separate image and text encoders are used in FLAVA. For example, to train the image encoder, we use MIM loss, where you mask the image. In the ViT vision and transformer, you convert the image into patches; you mask these patches, and you try to recreate these patches again based on the extra information present inside the image. The masking ratio is super high, so you are actually not seeing a lot of the image, and then you try to reconstruct it. Then you have just a vision task head, just on the top of the image encoders, and this task doesn’t really see NLP or any other data that comes in. So the image task only cares about the image data itself.
Then you also add a text encoder head, and then you use any sort of NLP loss that you care about—in this case it was MLM (mass language modeling)—and then you take all of the unpaired input text and just pass it in the model and then train this task head on top of the text encoder.
When you have a task that cares about both text and images, you will add an extra encoder on the top, which takes output from the text encoder and the image encoder and directly passes it inside the multimodal encoder, which is maybe six layers. Then you apply all of the multimodal pretraining objectives on top of the multimodal encoder. So, image-text matching, because you have captions we try to match them with non-matching captions and the matching captions as well. And then you have global contrasting laws. That doesn’t really go to the multimodal encoder, but only works on image and text encoder, similar to the CLIP objective, where you try to align image and text embeddings into the same semantic space.
Then you also have the mask multimodal modeling, where you actually mask both the image as well as the text and you try to predict both of them to the other modality. So, you mask either one, the image or you mask the text and you try to predict it to the other modality, whichever is present.
This is how it works. It is a very big architecture with five losses on top. And you have to basically sample the datasets accordingly so that you learn them properly.
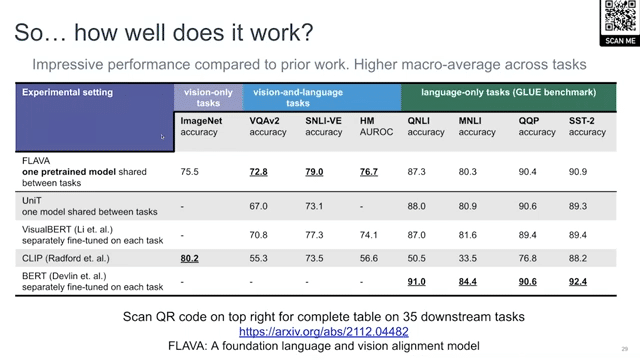
How does it work in practice?
It has actually very good performance compared to VisualBERT and CLIP on most of the image tasks and even compared to BERT on NLP tasks. It also has much better performance than UniT. Overall, the global macro-average of FLAVA on all of these tasks is much higher compared to any of the baselines. For more details, you can just select the QR code and see all of the tasks. There’s a big table in the paper.
The next key challenge that we usually see is that the current evaluation benchmarks are saturated and not relevant. The problem is that once you create these models they’re already very good at the already existing benchmarks. Very close to human accuracy.
This chart is for the VQA v2 dataset. Since it was introduced in 2015, the performance has almost saturated, and it’s almost close to human performance. But the question is: have we actually solved visual question answering as a task?
In the next few slides, I will show some datasets that I have, with others, created to actually test these various capabilities in the models that we care about, but that the current benchmarks don’t really test.

The first one is hateful memes, where you have an image and you have a “hateful” text, which might not be hateful in certain contexts, but might be hateful in some contexts.
The model has to tell whether this particular meme or this image with text is hateful or not. This was a very hard task when it came out. Most of the models were doing it at random. As of now, the best model with a lot of hyper-parameter tweaks and a lot of external knowledge is doing 78.4 ROC AUC, and FLAVA is doing 77.7. Human accuracy is around 84. So, there’s still a way to go, but it does test whether these models can understand hate speech or not.
Then there is Winoground, which is a very interesting dataset. You have the same text, same words in two separate images, but their word order is different. When the word order changes, the meaning of the sentence changes.
We have aligned images with these texts and the model has to differentiate which caption belongs to which image. They are cross groups that you have to differentiate. With this particular dataset, all of the current models are doing very badly because they don’t really understand how the context changes when the words shift.
The best as of now is 14.5, which is very low. I think the score for random would be 13.3. FLAVA is almost close to that. So most of the foundation models are not able to understand the true relation or the reasoning or the compositionality behind the sentences and the images. Human accuracy on this one is very high, it’s almost close to 90, and most of these models are not anywhere close.

We talked about VQA before, and as the graph shows and as the models say, they have solved VQA as a task. And we were curious about this, whether it’s actually solved. So we collected a dataset on top, which is collected adversarially, and we saw that it’s actually not anywhere close to solved. The human accuracy on this data dataset was 85, whereas the best model at that particular point in time, which was the VQA model, was only doing 34.3%. Whereas FLAVA does 36.4.
Finally, there is a missing component in even DALL-E-like models. They’re not able to understand the text inside the images. For example, you see the question: “What does it say near the star on the tail of the plane?” These models are not able to understand the text written inside the images, and they just don’t understand how it’s done. If you ask it to generate images with text, it basically creates clutter on top of the image.
We created datasets for captioning these images and also visual question answering on them. FLAVA does really well on it as of now, 38.4. But the best without OCR is only 34. So there’s much to do here in terms of these things.
What did we learn today? Let’s revisit the key challenges.
Jointly learning across domains, you can use UniT. For cross-modal data you can use PMD or LAION. For jointly pretraining you can use FLAVA objective and you can extend it to audio by adding a new audio encoder on top. It should work out of the box. You just need to tune the samplings of the datasets themselves. Then the current evaluation benchmarks are not relevant. I’ve introduced a lot of the new benchmarks that we worked on, which try to focus on specific capabilities of the models.

Finally, the future.
We are working on an extension of FLAVA. We’re creating a bigger model of FLAVA, which we call FLAVA XL, using LAION and some of the other datasets that are not publicly available. We are doing Flamingo, which is a chatbot just on top of images, in production at Hugging Face.
So, we will soon see more of these regional language foundation models . UniT is available through MMF, and FLAVA is in Hugging Face transformers. And thank you for listening to the talk.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.

Recommended articles
View all articles

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•

The Art and Science of Building AI Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build AI benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents with
June 16, 2026
•
Snorkel Team

Cua-Bench: benchmarking computer-use agents on professional software
TL;DR We built a benchmark of 25 expert-authored KiCad schematic-editing tasks and ran a frontier computer-use agent against them. The headline numbers: 1. Why build a computer-use benchmark for electrical engineering? Most computer-use benchmarks today live in the same handful of apps: web browsers, file managers, generic productivity suites. Those evaluations are useful, but they share a structural weakness —
June 15, 2026
•
,

