As Snorkel Flow’s customer base and ML product capabilities have scaled, our cloud costs have unsurprisingly increased. In order to grow efficiently, we set out to understand how we can improve our margins while operating state-of-the-art ML software.
Although inefficiencies in cloud spend are common among growing SaaS businesses, it is important for all companies to understand the unique factors that most impact their operating profile. For us, there were two major ones:
- Machine learning development workloads by nature are expensive, potentially requiring specialized hardware (i.e. GPUs) and involve “bursty” (i.e. high load but infrequent) compute.
- We serve large customers (e.g. major financial institutions) with sophisticated IT departments that have nuanced deployment and data privacy needs, meaning we need to cater to a variety of enterprise requirements with our containerized platform.
As infrastructure engineers, we’re deeply interested in designing systems that enable Snorkel to scale efficiently with sub-linear growth of our infrastructure cost. As such, we’ve designed, implemented, and rolled out a multi-faceted autoscaling solution to address cloud cost issues in the context of our Kubernetes deployment model. We have simultaneously sped up our workloads that require burst compute.
We aimed to reduce our cloud spend by 40%. The practices outlined below achieved that reduction.
In this post, we share our process for addressing these scaling challenges, and we hope that it can help facilitate the design of better infrastructure for machine learning systems. If you’re new to Kubernetes, read our Introduction to Kubernetes post to learn more about the basics, and our Machine learning on Kubernetes: wisdom learned at Snorkel AI post to learn more about our journey with Kubernetes thus far.
Let’s dive in!
Why we needed to rethink how we scale
From labeling data programmatically to fine-tuning foundation models, the Snorkel Flow platform experiences varied periods of high compute demand based on the activity of our enterprise users.
Early iterations of our infrastructure used fixed resources. Our users told us that these bursty workloads could take too long to complete and therefore negatively impacted their experience.
Ad-hoc manual scaling up and down of compute resources proved unscalable and error-prone, leading to cloud costs that stayed elevated even during periods of low usage. This is the worst of both worlds—low cloud cost efficiency and slower-than-needed performance. In order to address these challenges, we implemented autoscaling at multiple levels in our infrastructure, which we’ll discuss in the following sections.
How we designed scalable infrastructure with cost-efficiency in mind
The Kubernetes distribution of Snorkel Flow involves a set of deployments running in a Kubernetes cluster containing pods that run various components of the platform.
In order to address the unique challenges of working with bursty compute workloads, we introduced a new concept for Kubernetes pods, semantically categorizing them as either “fixed” or “flexible.”
- Pods that are “fixed” cannot be safely moved from node to node, either because we would lose important in-memory state (e.g. in-progress compute jobs without checkpointing) or because we want to minimize avoidable downtime for foundational platform components (e.g. the orchestrator for our Ray cluster).
- Pods that are “flexible” can be safely moved to a new node. This distinction is meaningful in the context of autoscaling, since downscaling nodes involves moving pods away from underutilized nodes when they are terminated.
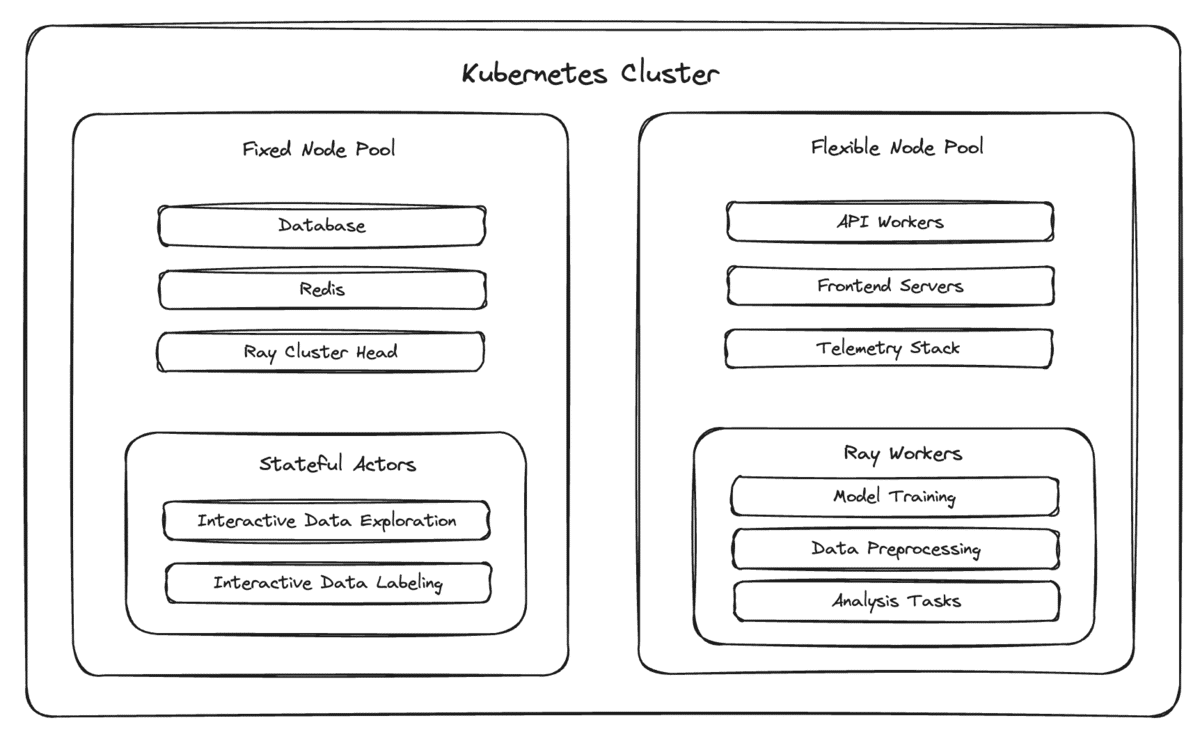
This fixed/flexible framework gave us a domain-specific means to enable automated cluster downscaling, meaning we could turn on the Kubernetes cluster autoscaler without our finance department slacking us every hour.
Our initial approach was to deploy podDisruptionBudgets to prevent the cluster autoscaler from moving “flexible” pods during the day and from moving “fixed” pods at all. While effective, this approach left us unsatisfied; it downscaled far fewer nodes than what was theoretically optimal.
To address this, we layered on a pod scheduling optimization that isolated “fixed” pods to a small “fixed” group of nodes. It scheduled “flexible” and worker pods (which we considered to be “fixed” pods but were ephemeral due to worker autoscaling) in the remaining “flexible” group of nodes.
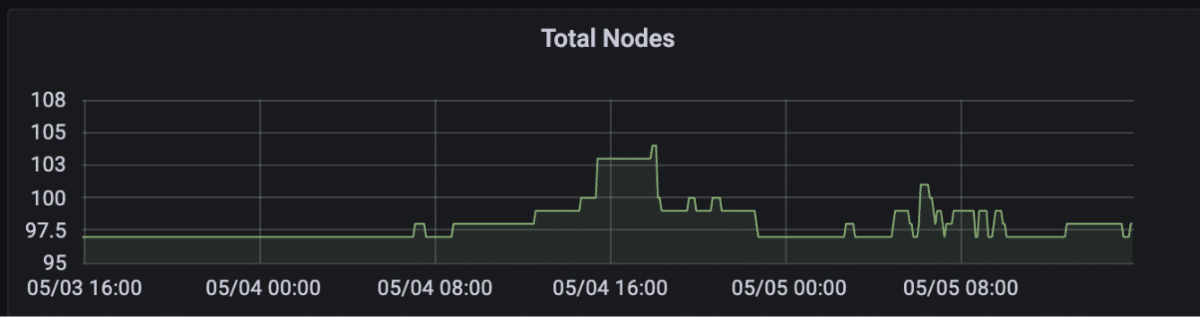
This enabled us to efficiently downscale the “flexible” nodes overnight, when it became safe to move around “flexible” pods and the vast majority of worker pods were scaled down. By enabling efficient downscaling of the vast majority of the cluster’s nodes (i.e. the “flexible” nodes), we finally met our target of cutting our cloud bill for hosting Snorkel Flow by 40%. That was a huge win for the company.
More detail on our autoscaling solution
We can bucket our implementation of the solution described above into three sequential efforts:
- First, we implemented “worker autoscaling,” a custom Redis-based autoscaling service that allows our worker pods to scale up and down based on jobs in the workers’ queues.
- Second, we implemented “cluster autoscaling” by reconfiguring our Kubernetes deployments to allow the Kubernetes cluster autoscaler to scale nodes down in addition to scaling nodes up.
- Third, we implemented “node downscaling optimizations” by grouping “fixed” pods into a small group of “fixed” nodes to prevent “fixed” pods from interfering with the downscaling of the remaining nodes.
Worker autoscaling
The Snorkel Flow platform abstracts compute into a paradigm where jobs wait in Redis queues and workers run as processes in worker pods.
We implemented a worker autoscaling solution for worker pods by running a recurring function in Snorkel Flow’s backend API. Every few seconds, this function checks the Kubernetes cluster and Redis for both upscaling and downscaling eligibility.
If there are jobs waiting in the relevant Redis queue(s), it will ask the Kubernetes API to provision additional worker pods to process these jobs. If the Redis queue is empty and there are no running jobs in the job registry, it will ask the Kubernetes API to destroy the worker pods to free up reserved CPU and RAM resources.
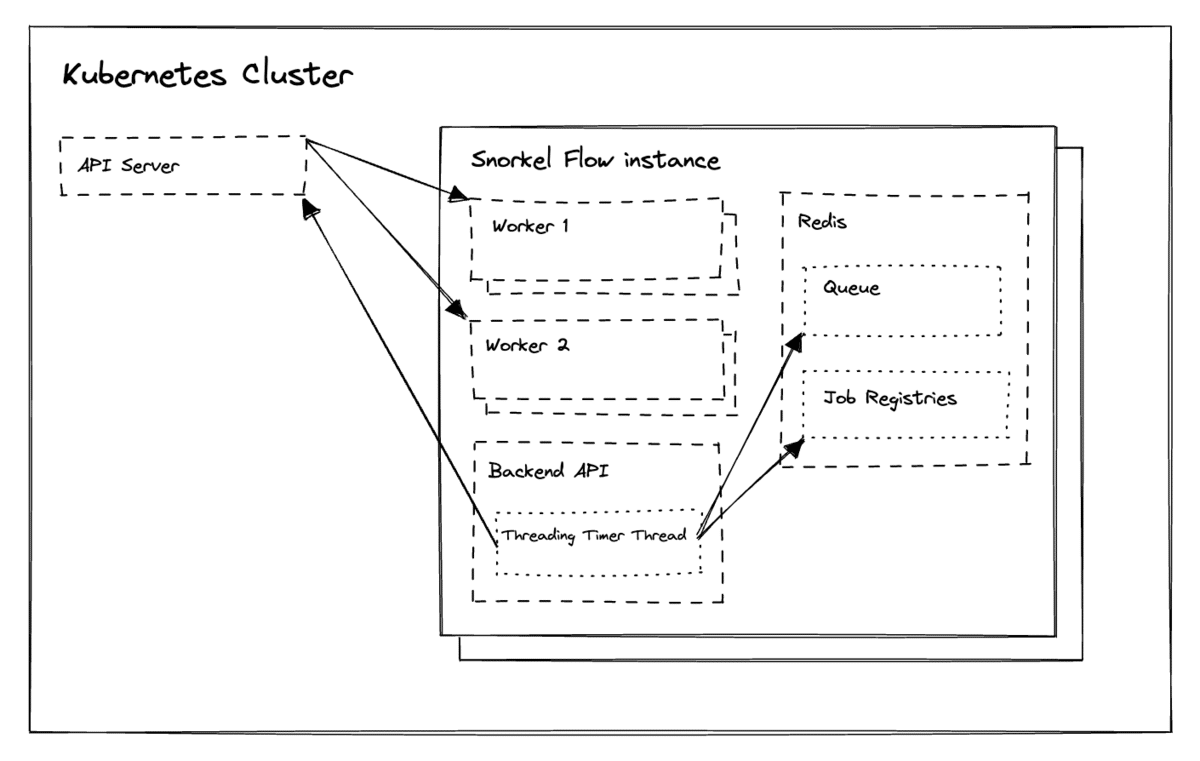
With this worker autoscaling implementation rolled out, Snorkel Flow’s worker pods became ephemeral, appearing in the cluster only when jobs needed to be processed.
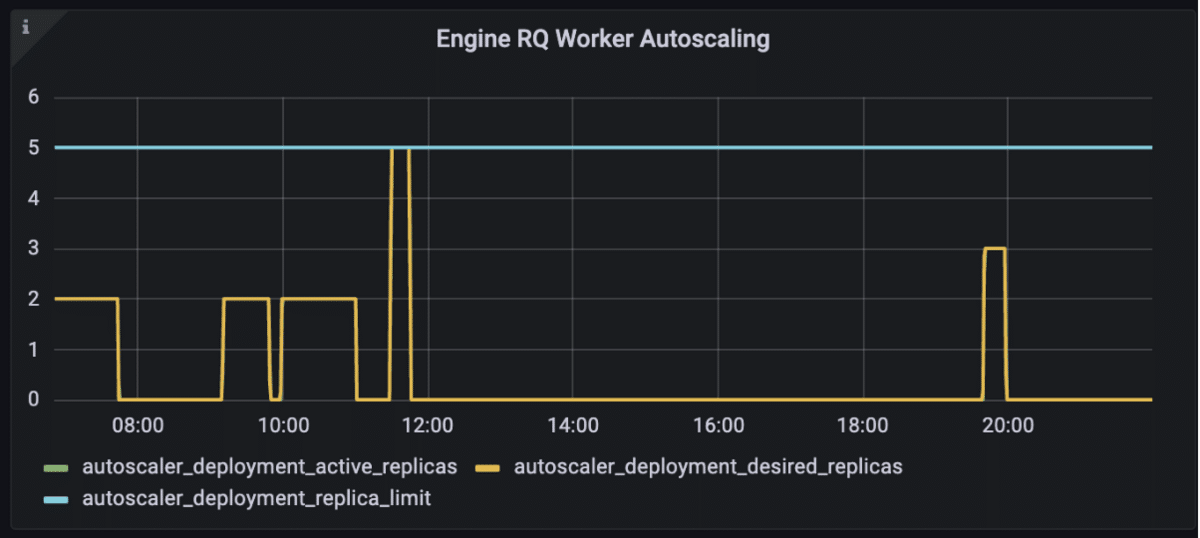
Cluster autoscaling
The PodDisruptionBudget resource protects certain pods against disruption (e.g. voluntary restarts) by allowing for the specification of the maximum number of pod replicas that can be unavailable at any given time. Setting this value explicitly to 0 for a deployment ensures that the cluster autoscaler will not downscale nodes running the deployment’s pods.
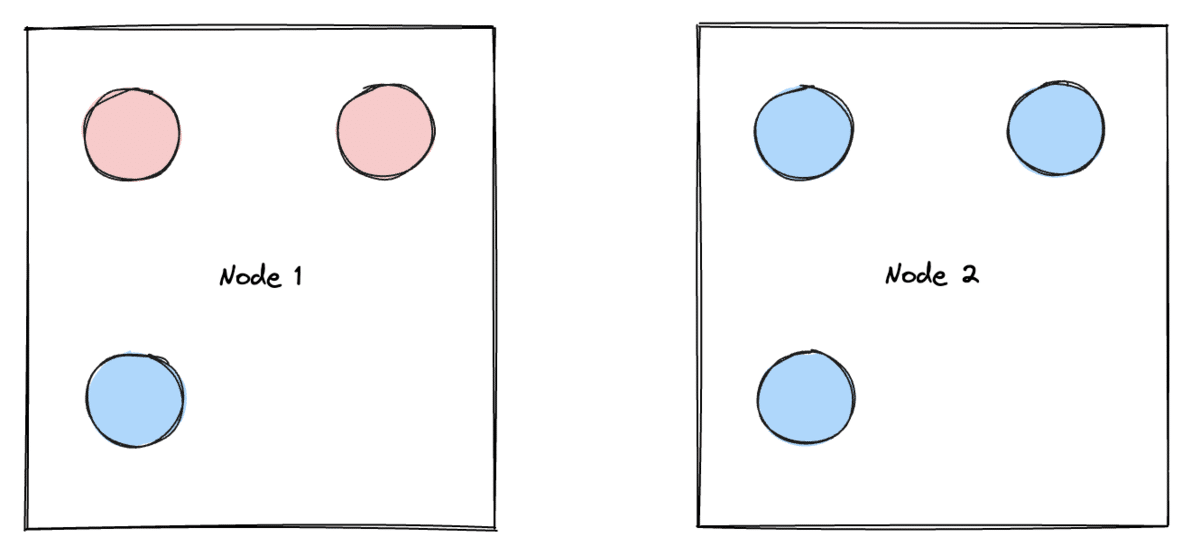
Rolling this out to our hosted Snorkel Flow instances enabled us to safely allow the cluster autoscaler to downscale underutilized nodes. However, the cost savings we realized were marginal—we were still unable to downscale the majority of our nodes since all Snorkel Flow pods are protected by an associated podDisruptionBudget.
Upon closer examination, we realized that this protection does not need to exist all of the time. Workloads are bursty and most user interaction with Snorkel Flow occurs during a customer’s business day, meaning we can safely relax this protection outside of business hours. Similar to worker autoscaling, we implemented a recurring function that toggled podDisruptionBudgets “off” overnight for an instance’s “flexible” pods by setting the maximum number of unavailable pod replicas to 1, up from 0. Worker pods disappearing overnight due to worker autoscaling and toggling “off” podDisruptionBudgets for “flexible” pods overnight made it possible for the cluster autoscaler to downscale many more underutilized nodes than before. Customers deploying Snorkel Flow in their cloud can configure this as needed.
Node downscaling optimizations
Even with the above improvements, we saw that a majority of underutilized nodes were not being downscaled at all.
Upon further investigation, we realized that the issue stemmed from “fixed” and “flexible” pods occupying the same node. This was problematic because a “fixed” pod, pseudo-randomly assigned to a node containing “flexible” pods, would “pin” that node and prevent it from being downscaled, even when it’s underutilized. This lack of control over the scheduling of “fixed” pods led to periods where the vast majority of the cluster’s nodes could not be downscaled, even though they represented far more compute power than we needed at the time.
We leveraged the podAffinities Kubernetes resource to address this, which enabled us to constrain which nodes a pod is eligible to run on based on the labels of other pods already running on any given node. We added labels to our pods to differentiate between “fixed” versus “flexible” pods, and added a podAntiAffinity stanza to our deployments configuration to ensure that “fixed” pods are not scheduled on nodes running “flexible” pods, and vice versa.
This implementation of podAffinities allowed us to split nodes into two functional groups, the “fixed” group of nodes containing “fixed” pods that can never be safely moved between nodes (e.g. Redis due to cache), and the “flexible” group of nodes containing “flexible” pods that are either ephemeral (i.e. workers) or safe to move outside of business hours (e.g. overnight).
Although possible with manual intervention during platform maintenance, we cannot automatically downscale the “fixed” nodes. This solution, however, allows us to automatically downscale the “flexible” nodes because we’ve isolated the unmovable pods into the “fixed” nodes.
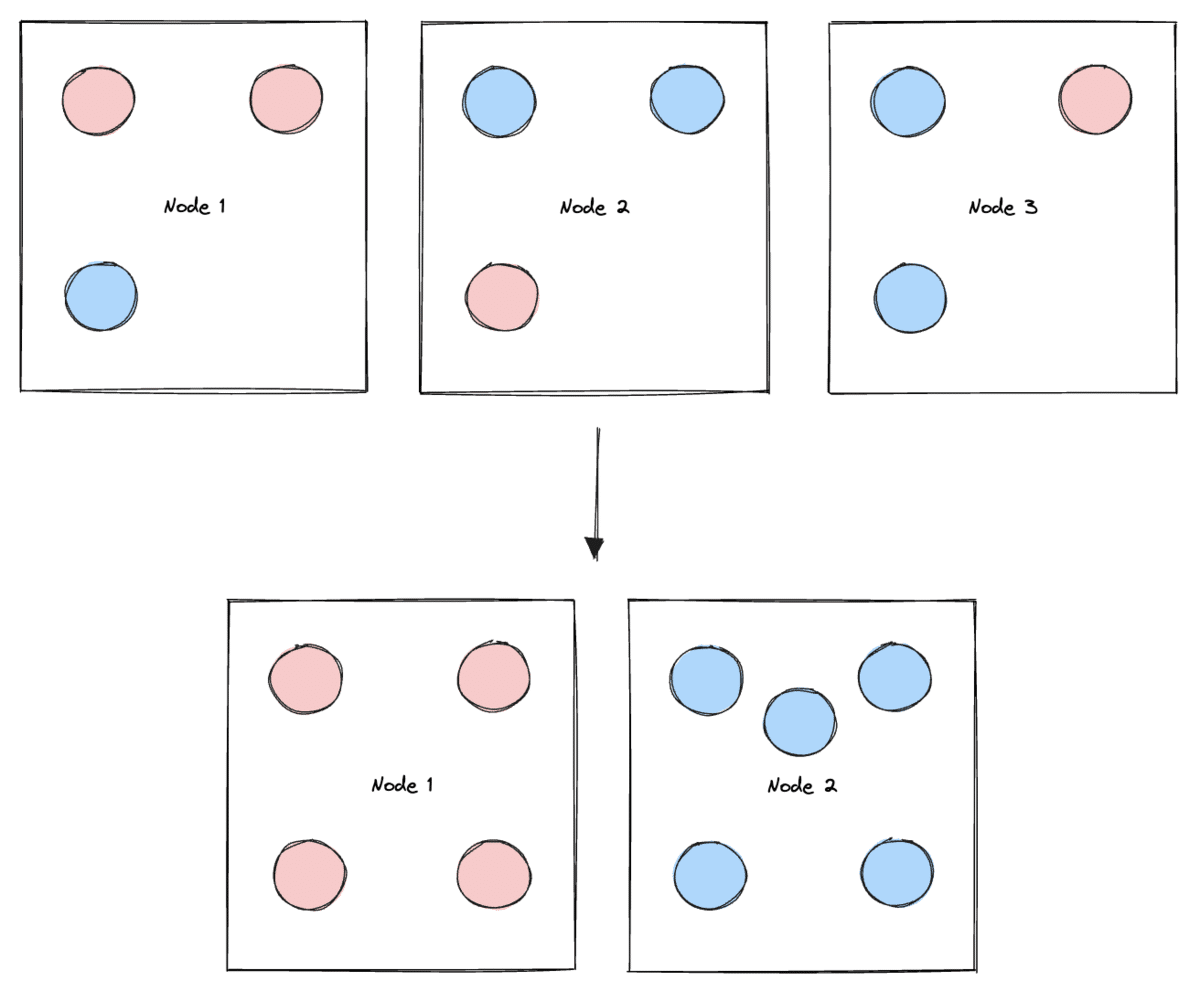
This semantic differentiation between groups of nodes helped us realize significant additional savings since the “flexible” group of nodes represents >90% of the cluster’s total nodes.
A suite of solutions that saved us 40% on cloud costs
Over the past several months, we’ve been hard at work addressing the unique challenges of designing efficient infrastructure to support ML development workloads without skyrocketing infrastructure bills, sacrificing developer velocity, or impairing user experience.
While the new pod grouping and autoscaling techniques detailed above played a major role in achieving and exceeding our cost reduction targets, we of course combined these with other effective practices to cut our cloud bill by over 40%:
- Resource right-sizing through node utilization monitoring via Prometheus and working with backend engineers to understand resource requirements for different components in the platform
- Cloud configuration optimizations where we worked with engineering leadership and our partners at AWS to implement Savings Plans and swap nodes to more efficient VM types
- Internal process changes where we worked with customer-facing teams to design and operationalize processes to reduce idle compute
We hope that sharing our thought processes and solutions helps you build better infrastructure for ML systems, which are rapidly becoming more important as machine learning, large language models, and other foundation models make their way into production for organizations all over the world.
We love hearing from other folks working on related infrastructure and software challenges, so please reach out if you have thoughts or questions!
Acknowledgments
Many thanks to David Hao, Will Huang, Edmond Liu, and Alec Xiang for helping to make this technical vision a reality for Snorkel. Special thanks to the aforementioned as well as Matt Casey, Will Hang, Henry Ehrenberg, Anthony Bishopric, and the entire infrastructure engineering team for their thoughtful feedback on this article.
Come work with us
At Snorkel AI, we work diligently to make it easier for enterprises to build better AI solutions, faster. We integrate cutting-edge research with industry-leading design and engineering to create new, powerful, and user-friendly tools on our Snorkel Flow platform. If that sounds like work you'd like to do, check out our careers page! We’re actively hiring for engineering roles across the entire stack.

Recommended articles
View all articles

Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration
June 25, 2026
•

Agentic AI evaluation: Closing the gap with better benchmarks and data
Alex Ratner, co-founder and CEO of Snorkel AI, spoke at @Scale: Systems & Reliability about one of the most underappreciated problems in AI deployment: our ability to measure agents has been outpaced — arguably for the first time in the history of the field — by our ability to build them. The talk digs into what it actually takes to close that
June 23, 2026
•
Snorkel Team

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•
Snorkel Team

