Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
FM Summit shows Foundation Model hurdles and potential
Snorkel AI held its Foundation Model Summit yesterday, bringing together 12 presenters and over 600 attendees at 10 virtual sessions. The event, our first of 2023 (we will hold our Future of Data-Centric AI 2023 conference in a few months), drew registrants from across many sectors, including the tech industry, healthcare, and financial services.

We will make recordings of individual sessions, emceed by Snorkel researcher Fait Poms, available soon. You can request access to the full event video through the form above or read the summary of the Summit’s sessions below.
Opening Address
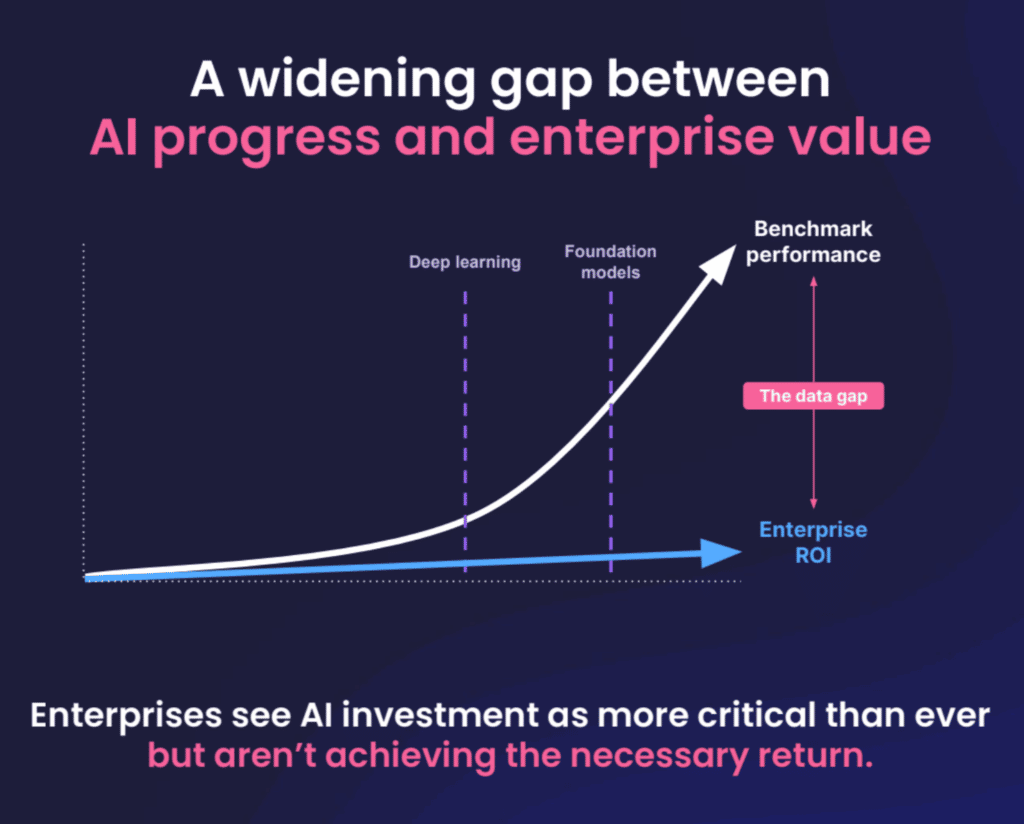
Alex Ratner, CEO and co-founder of Snorkel AI, set the tone for the day’s events by highlighting the breakthrough that Foundation Models represent for AI, along with the growing gap between AI’s power and companies’ ability to gain value from it. The key to closing that gap, Ratner said, is data-centric development—a fact amplified by Foundation Models.
While Foundation Models aren’t practical for enterprises to deploy for most performance-critical tasks, he said they can be used to label data and train smaller models using Snorkel Flow’s data-centric foundation model development capabilities.
Towards Unified Foundational Model for Vision and Language Alignment
Amanpreet Singh, research team lead at Hugging Face, gave the audience an overview of new, more generalized Foundation Models (including UniT and FLAVA) that can perform tasks across modalities. For example, Singh said, FLAVA can handle 35 different tasks across vision-only, language-only, and vision-and-language applications.
He also highlighted new frameworks for assessing the performance of foundation models, such as asking the models to determine whether a piece of text in the foreground of an image is hateful when juxtaposed with the scene in the background.
Trends in Enterprise ML and the Potential Impact of Foundation Models
Carlo Giovine, a partner at McKinsey QuantumBlack, together with David Harvey, a staff expert at the same firm, told the online audience that companies are not moving fast enough to capture the value potential of AI/ML.
A 2018 study from McKinsey estimated the total global unclaimed value potential from AI/ML at $10-15 trillion, and Foundation Models will enable valuable applications that the firm couldn’t conceive of four years ago.
Some businesses already employ FMs, Harvey said, pointing to a biotech firm that used a foundation model to help identify more than 1,000 potential new drugs in a matter of days. The adoption of these exciting new capabilities, he continued, “won’t be an overnight transition for most enterprises.” The biggest challenge for most companies looking to adopt this technology, he said, will be companies’ need to refresh their frameworks for managing their models’ risks and ethics.
The Ethical Implications of Building A Real-Life Skynet
Joe Penna, Head of Entertainment Technology at Stability AI, wrapped his discussion of the titular SkyNet in under 60 seconds. He used the remaining time to demonstrate the creative potential of content-generating foundation models.
Penna walked the audience through his career—from YouTube creator to feature film director to his work at Stability AI—before showing how generative AI could have saved his productions time and money. For example, he demonstrated AI technologies that would let him generate ideas for movie posters, insert his actors into photographs for ease of shot-planning, artificially change the lighting in post-production and even change a camera angle after the shot had been completed.
He emphasized this point when he revealed that many of the images he showed documenting his career had been created or altered using FMs.
Tutorial on Foundation Models and Fine-tuning
Ananya Kumar, ML researcher at Stanford University, gave an overview of what foundation models are, and why data scientists’ instinct to fine-tune these models may be misguided.
Kumar’s work found that fine-tuning Foundation Models often improves their performance on the test data, but can lead to worse performance on real-world, out-of-distribution examples; fine-tuning, he said, distorts the feature space. His work found that using a method such as linear probing to build and train a layer on top of the model while keeping the foundation weights frozen yields better results for out-of-distribution examples.
The best results, he said, come from training this additional layer first, and then fine-tuning the entire system.
AMA: How are Foundation Models Changing the Way We Build Data Management Systems?
Simran Arora, ML researcher at Stanford University, outlined an approach that she and her collaborators used to get better performance from large language models without doing any additional training on the LLMs themselves.
The researchers built a method that took users’ original questions and reworded them as three to six prompt chains passed to the LLM of choice. After getting responses from the LLM, the method used a weak supervision algorithm to intelligently vote on the response most likely to be correct.
Arora said that the approach yielded a lift in accuracy on all of the popular LLMs they tested on.
Challenges and Ethics of DLM and LLM Adoption in the Enterprise
Ali Arsanjani, director of cloud partner engineering at Google, highlighted some non-obvious challenges and benefits that Foundation Models present for enterprises—including the inadequacy of current machine learning pipelines to handle FM development workflows.
Existing pipelines aren’t equipped to handle generative AI, he said, which will need rules and context evaluation to ensure they are used properly. He gave the example of Sparrow.ai. The company has a healthcare-focused LLM application that can help deliver diagnoses, but the model’s rules require it to explain the reasons behind its conclusions.
For another challenge, he noted enterprises that build multiple downstream applications on a single Foundation Model make it a single point of failure for malicious actors to target. However, he said, making an organization’s core model a single point of failure also makes it a single point to protect.
A Practical Approach to Delivering Enterprise Value with Foundation Models
Jimmy Lin, NLP product lead at Sambanova Systems, outlined the impracticality of businesses deploying generalized foundation models.
“The model is just the starting point,” he said, “There’s more work you have to do to build enterprise value.”
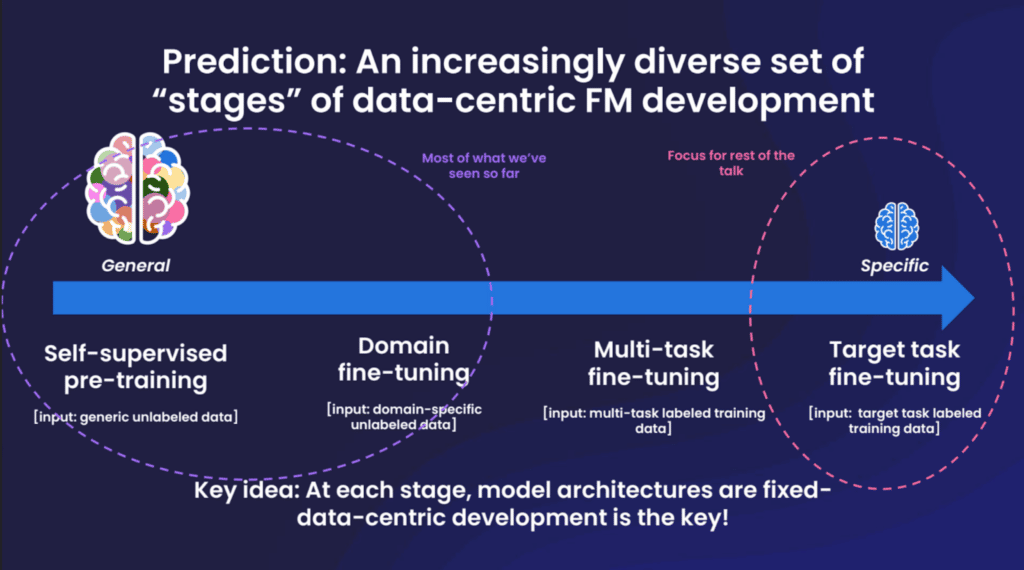
Businesses can get a better return, Lin said, by observing a four-stage pipeline: start with a generalized model, fine-tune that model with a dataset specific to your domain, further fine-tune the model with a dataset specific to your task, and then deploy the model.
However, he noted that building a usable model is only part of the challenge; the deployed model has to aim at clear business objectives and meet existing work processes where they are.
Generative AI is… Not Enough?
Jay Alammar, director and engineering fellow at Cohere, suggested attendees tame their enthusiasm for generative AIs.
The performance of the current generation of models is not reliably impressive, he said, citing Stack Overflow’s ban of ChatGPT-generated answers (which tended to be readable, but often wrong). He highlighted the milestones that generative AI has crossed in the last decade, indicating that later generations of the technology will likely be more reliably impressive, but also noted that the models themselves are only part of the solution.
These models will truly show their value, he predicted, when paired with other technologies such as search engines.
Demo of Foundation Model Development on Snorkel Flow
Braden Hancock, co-founder and COO of Snorkel AI, closed the summit with an overview of how our company has incorporated Foundation Models into the Snorkel Flow platform.
Full-scale foundation models like GPT-3, Hancock said, are “very large and a little unwieldy,” which makes them a poor fit for many enterprise applications. But Snorkel Flow allows users to get value from Foundation Models in much slimmer deployments.
Hancock kicked off the demo by showing an example of Snorkel Flow’s new “Warm Start” feature, which auto-suggests a handful of labeling functions using foundation models. He followed that up with two examples of a feature that allows users to use natural-language prompts to seed labeling functions. In one case, he wrote a prompt that asked the topic for each document and paired those topics with a dictionary that mapped specific topics to specific categories. In a second example, he showed how the platform could handle a direct question like “Is this about politics?”
Closing his presentation, Hancock pointed to three recent Snorkel case studies for applications in online commerce, online advertising, and banking which used Foundation Models to rapidly build data sets that might not have been possible without them.
Final Thoughts
We appreciate all of the attendees’ time and questions at the FM Summit. We will soon make videos of the sessions available. In the meantime, you can register for a live demo of Snorkel Flow on February 16 which will feature the platform’s new FM capabilities.
Topics

Matt Casey
Matt Casey leads content production at Snorkel AI. In prior roles, Matt built machine learning models and data pipelines as a data scientist. As a journalist, he produced written and audio content for outlets including The Boston Globe and NPR affiliates.