100x
All articles on
Research

HuggingFace research lead on unified foundation models
Amanpreet Singh, Lead Researcher at Hugging Face gave a presentation entitled Towards Unified Foundation Models for Vision and Language Alignment a Snorkel AI’s Foundation Model Summit in January.


Foundation Model Summit Sessions Show Challenges and Promise
Twelve speakers shared their insights into the present and future of foundation models January event; see what they had to say.


Foundation Models 101: a guide with essential FAQs
Foundation Models (FMs), such as GPT-3 and Stable Diffusion, mark the beginning of a new era in machine learning and artificial intelligence. What are they and how will they impact your business? Find out in our guide.

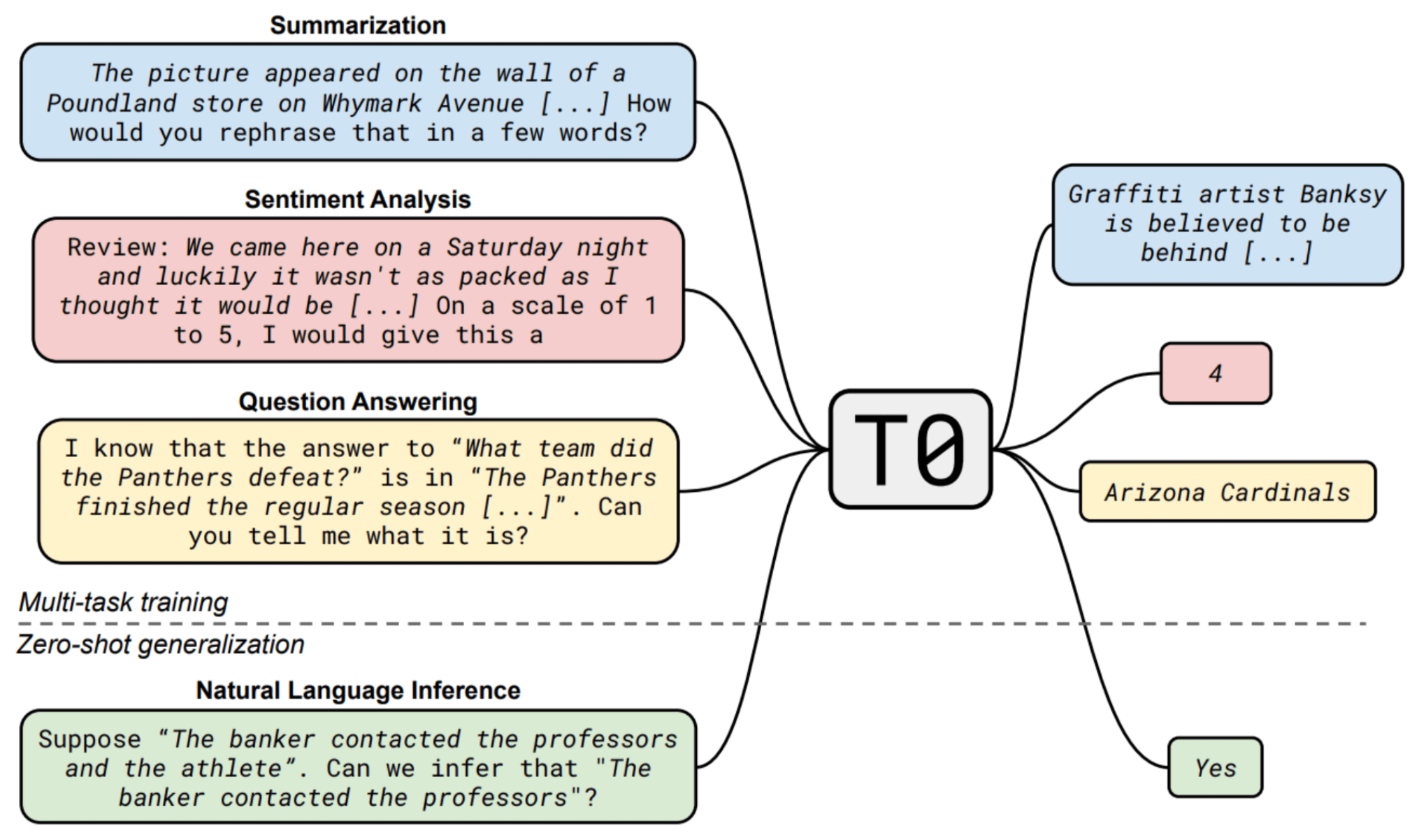
Combining foundation models with weak supervision
Combining foundation model outputs with weak supervision yields faster model development and requires fewer ground truth labels.


Operationalizing knowledge for data-centric AI
Snorkel AI CEO and Co-Founder Alex Ratner’s introduction to data-centric AI from the 2022 Future of Data-Centric AI virtual conference.
How a Brown professor sharpened and shrunk GPT-3
Brown professor Stephen Bach tells Snorkel CEO Alex Ratner about his research into improving foundation models like GPT-3 with curated data.

Cleanlab CEO shows automatic data-cleansing tools
Cleanlab Co-Founder and CEO Curtis Northcutt presents his company’s automatic, universal and open-source tools to quickly clean data sets.
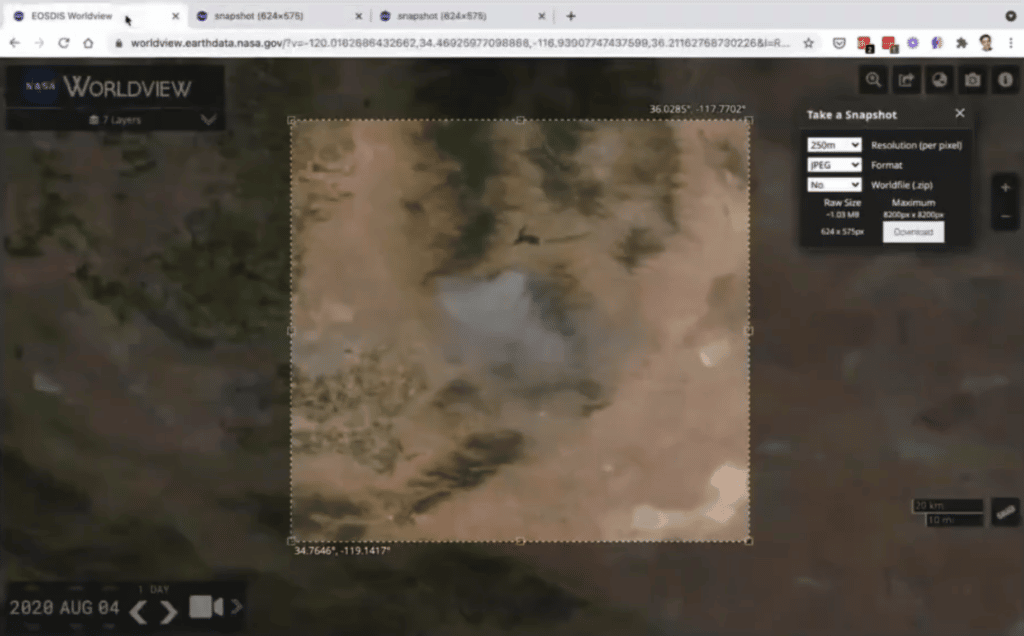
NASA ML Lead on its WorldView citizen scientist no-code tool
Anirudh Koul is Machine Learning Lead for the NASA Frontier Development Lab and the Head of Machine Learning Sciences at Pinterest. He presented at Snorkel AI’s 2022 Future of Data Centric AI (FDCAI) Conference.
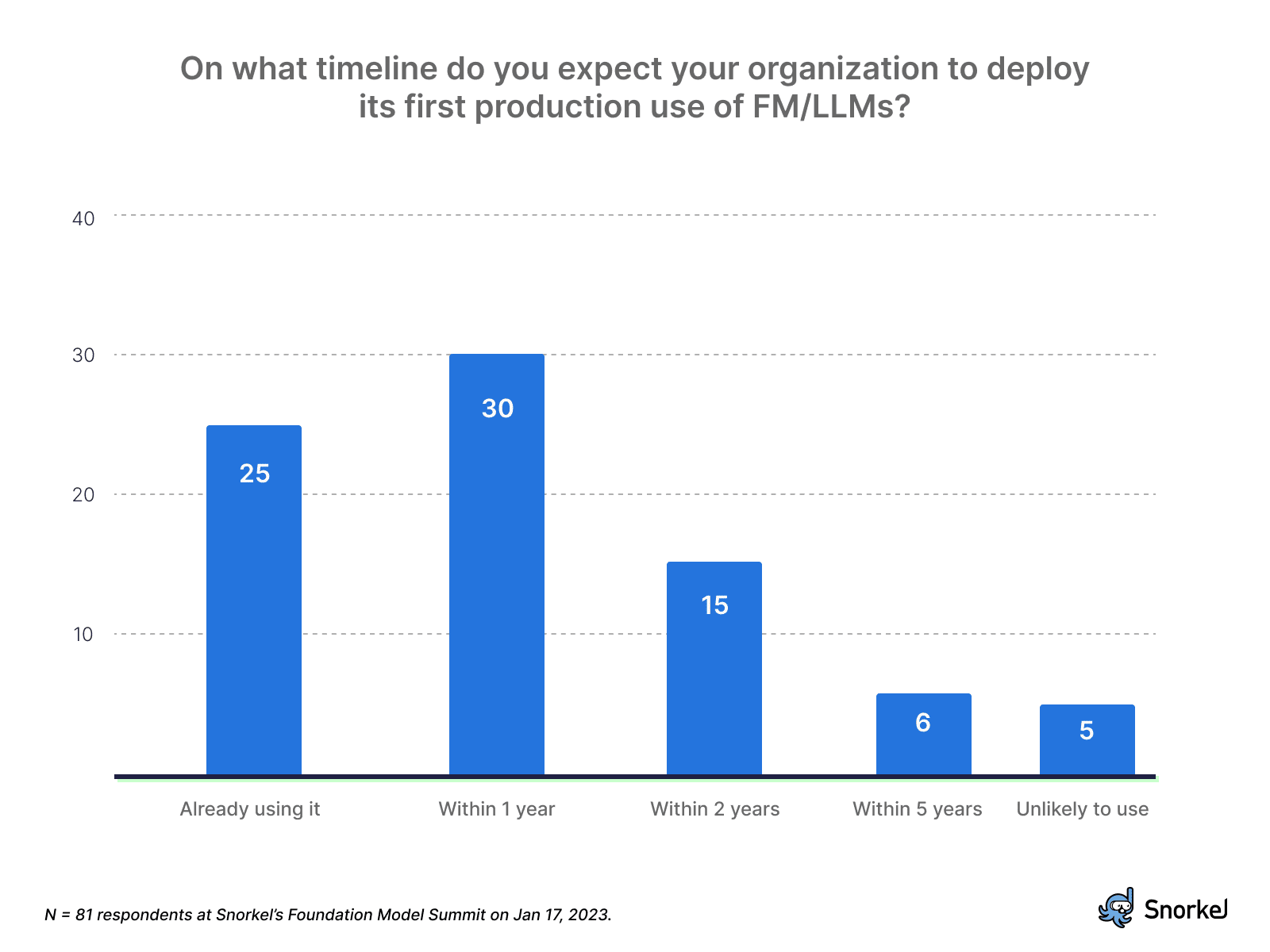
Accuracy top concern for Foundation Model adoption—Poll
Most poll respondents at Snorkel AI’s recent Foundation Model Virtual Summit named questionable accuracy as the biggest barrier preventing them from getting organizational value from Foundation Models.
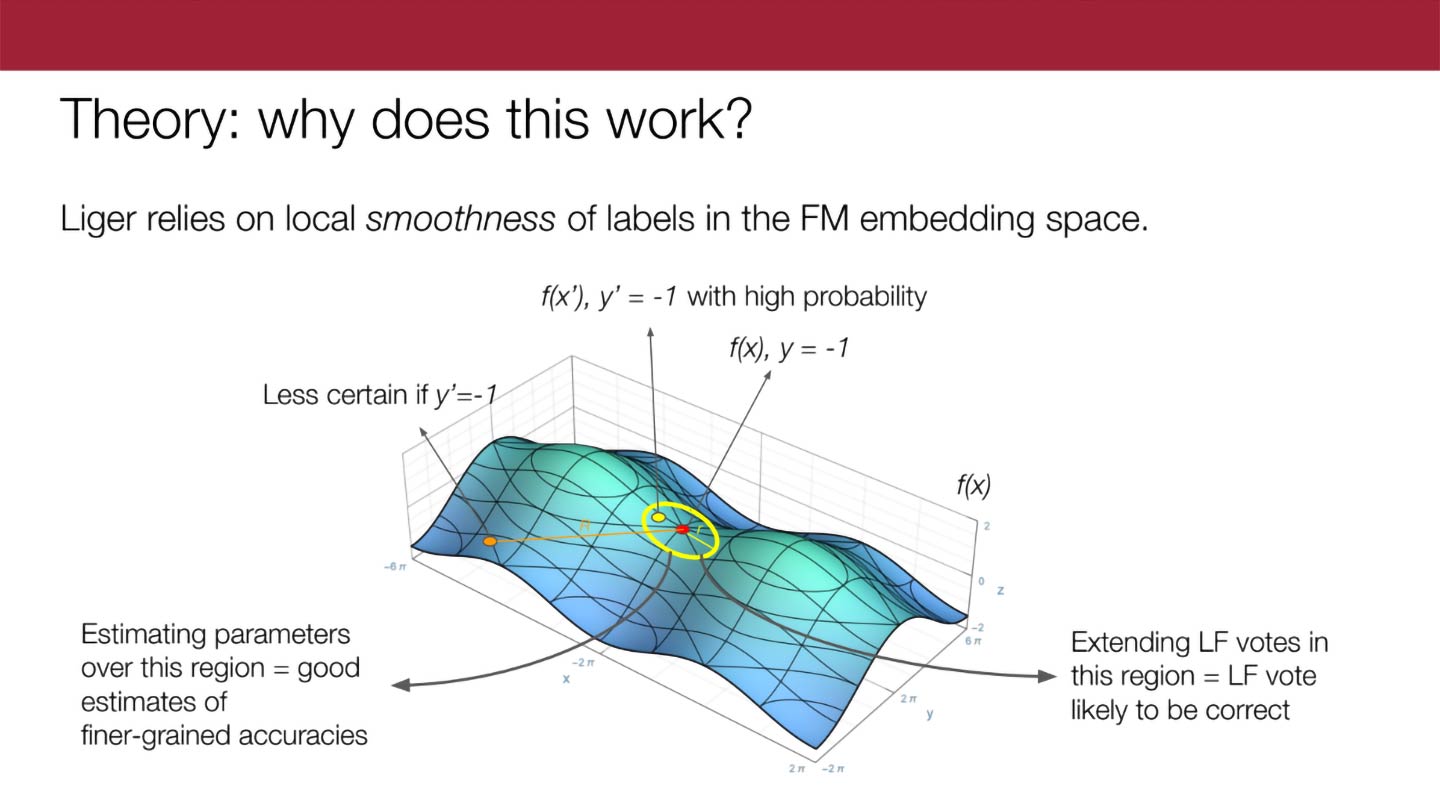
How Foundation Models bolster programmatic labeling
Snorkel CEO Alex Ratner interviews Mayee Chen about how Liger improves the effectiveness of programmatic labeling through foundation model embeddings.
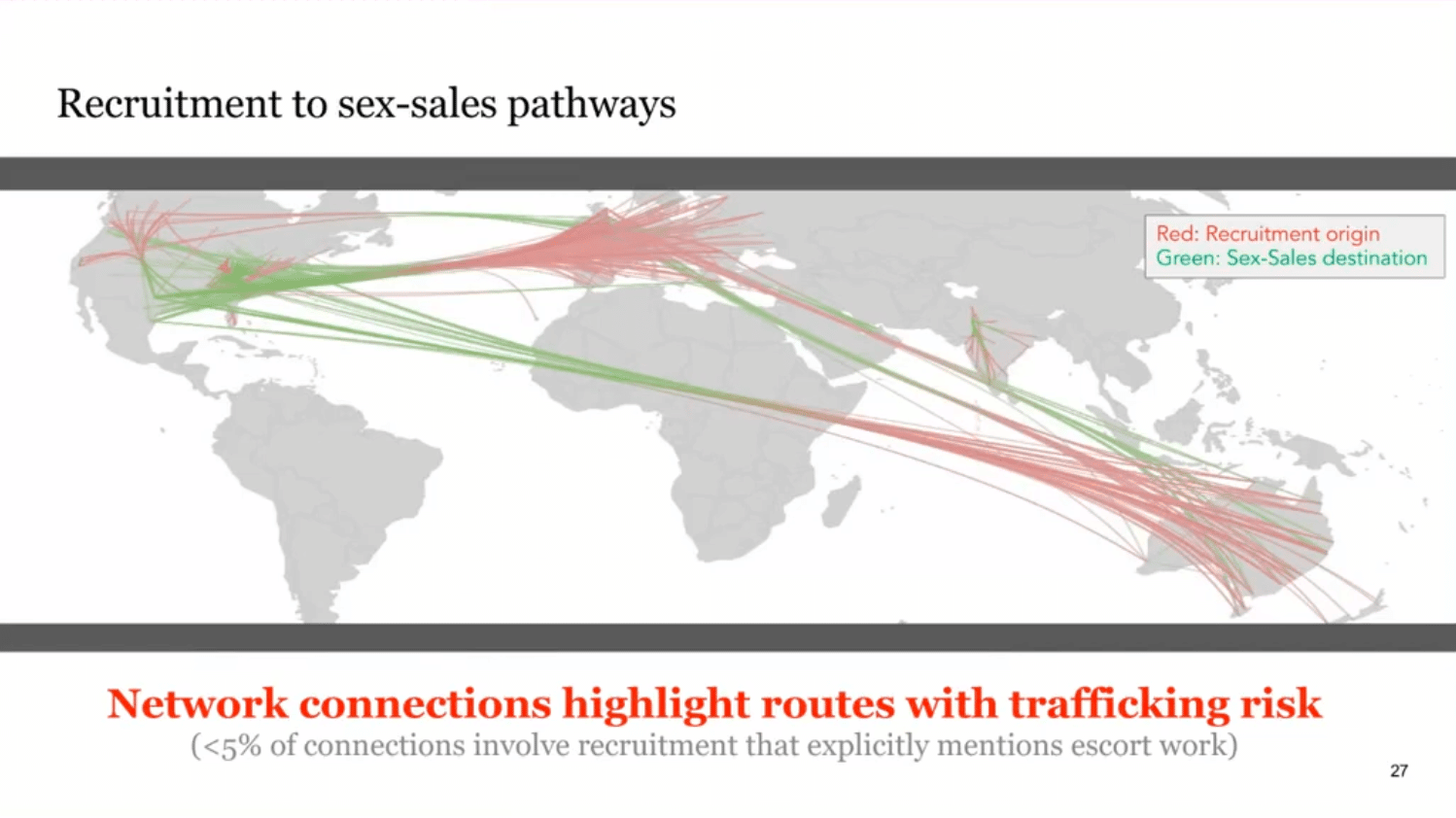
Unmasking Trafficking Risk in Commercial Sex Supply Chains with Machine Learning
Hamsa Bastani presented a summary of her and her co-authors’ ongoing work using machine learning and Snorkel AI’s tools to detect and track activities that are associated with a high risk for global sex trafficking.

Prompting and weak supervision to build better, smaller models
Snorkel AI co-founder and CEO Alex Ratner recently interviewed several Snorkel researchers about their published academic papers. In this video, Alex talks with Ryan Smith, Senior Applied Scientist at Snorkel, about the work he did on using foundation models to build compact, deployable, and effective models.
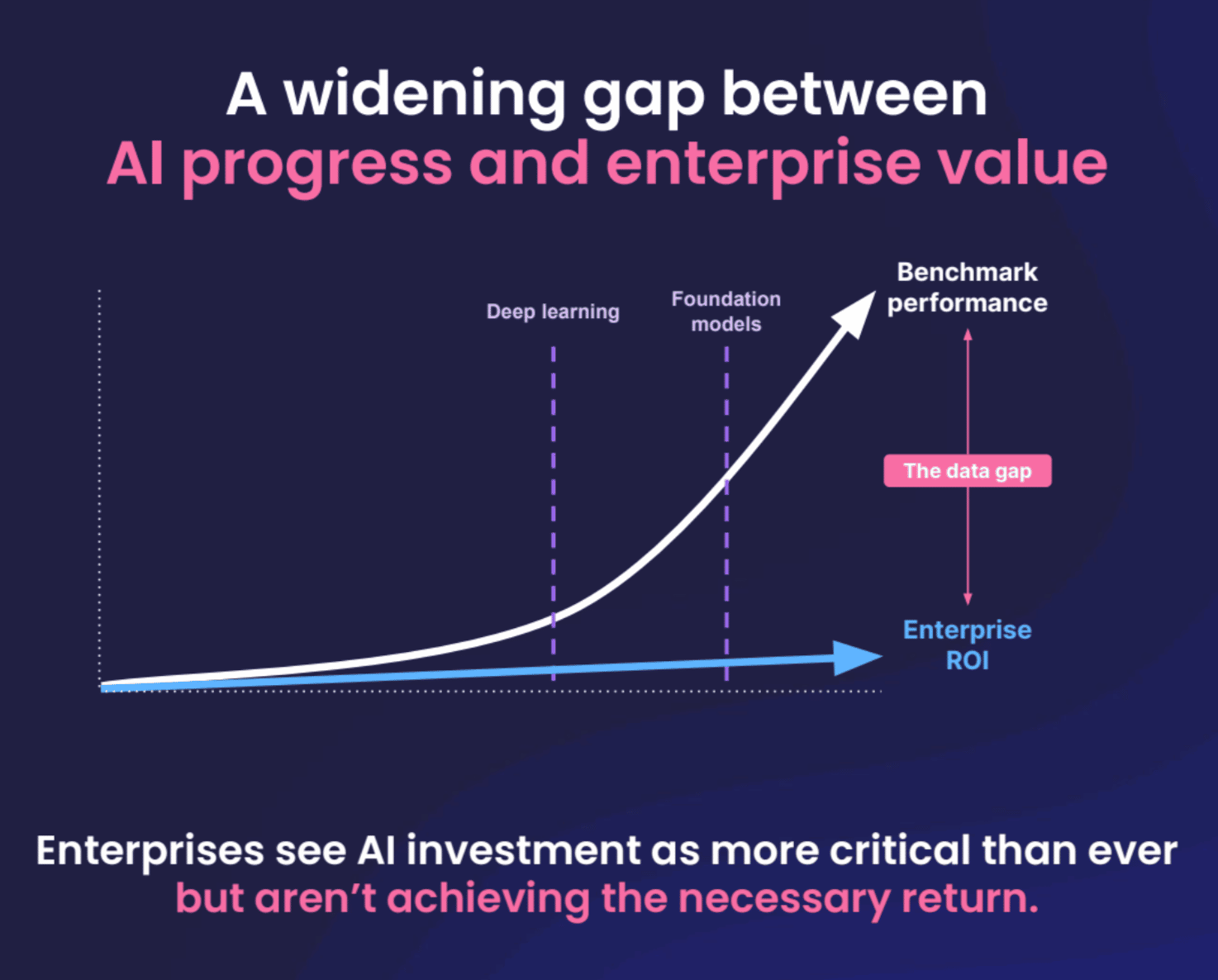
FM Summit shows Foundation Model hurdles and potential
Snorkel AI held its Foundation Model Summit Jan 17, bringing together 12 presenters and over 600 attendees at 10 virtual sessions. The event drew registrants from across many sectors, including the tech industry, healthcare, and financial services.

Contrastive Learning boosts Foundation Model specialization
Snorkel AI co-founder and CEO Alex Ratner talks with Ananya Kumar about the work he did on improving the effectiveness of foundation models by using contrastive learning, image augmentations, and labeled subsamples.

Ask Me Anything approach bolsters foundation models
Researcher Simran Arora tells Snorkel CEO Alex Ratner how she improved foundation model effectiveness by using “Ask Me Anything”-style questions.

See how Snorkel can help you get up to:
Faster data curation
40x
Faster model delivery
99%
Model accuracy