Create a data-centric AI application using Snorkel Flow to save time spent on manual labeling and information extraction related to environmental, social, and governance (ESG) factors from earnings call transcripts. Rapidly and accurately extract all existing and new factors from the transcripts to make the right investment decision.
Earnings season is a busy time for both companies and investors. Given investors’ growing focus on environmental, social, and governance (ESG) factors, it is not unusual for companies to comment on their ongoing ESG-related goals and initiatives.
The wealth of information in earnings calls transcripts makes it hard to find a specific topic. Earnings call disclosures receive a high level of analysis compared to other reports. However, analysts have to deal with the challenge of going through those calls individually and highlighting the sections related to their research topic.
As companies integrate ESG into their business strategies, they include more information in their quarterly earnings call. A significant challenge with this uptake in reporting ESG information is that companies generally do not track ESG’s financial effects but instead report on financials and ESG separately. Therefore, extracting ESG factors from earnings calls can enable investors to conduct an in-depth financial analysis.
In this blog, I will show how I used Snorkel Flow with weak supervision at its core to extract sentences related to any ESG factors. For this project, I used earnings call transcripts for S&P500 from 2019Q1 till 2022Q2 downloaded from the SEC website.
Finding ESG Factors – needle in the haystack
Fast and accurate analysis of earnings calls is a proven tool to stay competitive in the investment market. However, the amount of manual work required to extract relevant information (including ESG factors) is prone to error and time-consuming.
In this blog post, I will show how I used Snorkel Flow to train a machine learning model to extract sentences from more than 5000 earnings calls that have information related to ESG factors.
Snorkel flow enables efficient collaboration between experts with domain knowledge and ML engineers to train an ML model to extract the relevant sentences. I will show how, without any labeled data, I used programmatic labeling and weak supervision to capture expert knowledge, label training data, and train ML models to extract relevant information in an iterative approach.
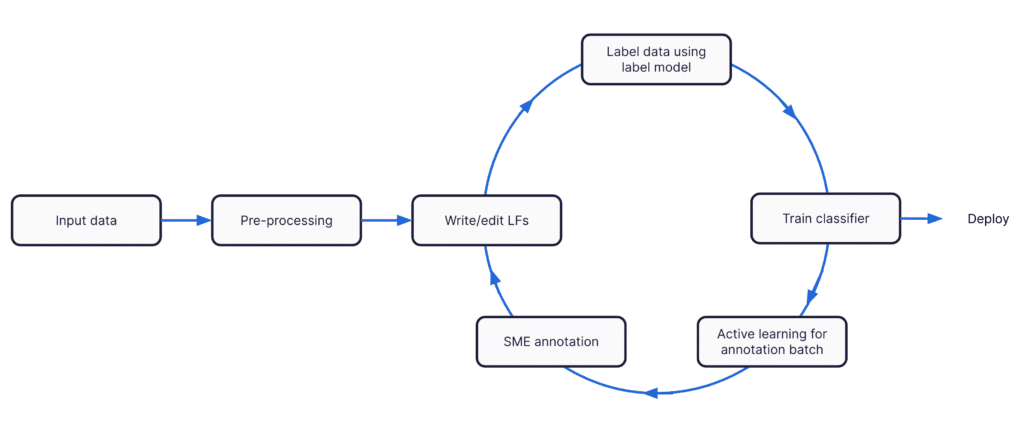
The steps I used to build an NLP application are as follows:
- preprocessing the data,
- encoding SMEs’ knowledge as labeling functions,
- weak supervision to create a generative label model,
- training a classifier,
- using active learning to reduce the search space for annotating GT,
- Expert annotation of the data for quality control,
- iteration!
Input Data
As mentioned before, I have downloaded more than 5000 earnings calls of S&P 500 companies from 2019Q1 to 2022Q2.
In addition to the transcripts, my data has additional columns, including ‘’name’, ‘symbol’, ‘quarter’, ‘year’, ‘date’, ‘sector’, ‘subSector’, ‘headQuarter’, ‘dateFirstAdded’, ‘cik’, ‘founded’.
Preprocessing
In Snorkel Flow, you can process your data using operators. In addition to built-in operators, you can create custom operators to compose complex data flow pipelines from simpler building blocks.

For this example, I used operators to
- Separate the Management Section and Q&A and use the management section for the rest of the analysis
- Detect sentence boundaries using a pre-trained sentence segmentation model

After running the pre-processing steps, we now have 200k spans to classify whether they contain information on any ESG factors.

Programmatic Labeling
We need to write at least one LF for each class (Environmental, Social, Governance, Other). There are multiple options for writing LFs. The first step is to write high-precision labeling functions for each class – think spearfishing. This is where collaboration with SMEs becomes critical.
Snorkel Flow provides a vast collection of LFs that you can choose from. For the first LF, you can use a keyword with high confidence related to the Environmental factor.
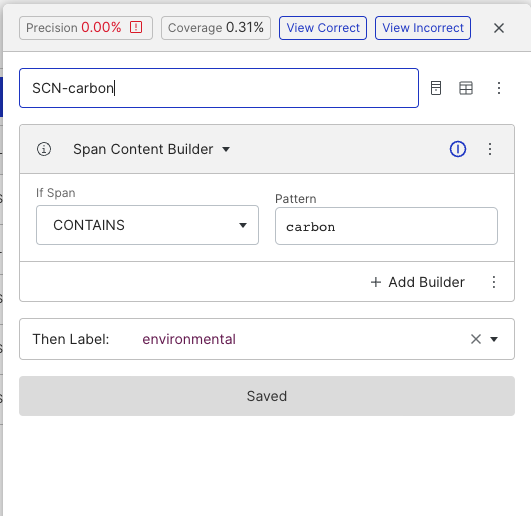
We initially want to use a keyword that our SMEs have high confidence in their precision. However, the reported precision is 0%. This is because we start with no ground truth for the 3 ESG factors, and all spans are labeled as “Other”.
Another commonly used LF is a dictionary-based one, especially when you have a knowledge base for a particular factor. For example, you have an internal knowledge of thematic keywords. For this example, we use an external list of keywords related to Governance factors.

Context LFs are helpful when you must ensure particular keywords exist close to each other. Here is an example that can help us find Social factors related to “Safe Working” conditions.

Lastly, we create a length-based LF where it assigns “Other” to any sentence with a length of fewer than five words.

Now, we can turn to a weak supervision approach, using the above rules and heuristics that assign labels to unlabeled training data as LFs, to label the dataset. Snorkel Flow uses a Label Model (a novel, theoretically-grounded modeling approach) to estimate the accuracies and correlations of the labeling functions using only their agreements and disagreements. It then uses this to reweight and combine their outputs, which we then use as probabilistic training labels.

You can see that with those 4 LFs, we managed to label more than 17k data points! Just imagine how long it would take if your SMEs wanted to label that volume.
Model Training
Once spans are labeled using programmatic labeling, we can train an initial classifier in Snorkel Flow. You can train preconfigured, state-of-the-art ML models for a range of modeling tasks with a single click using our Model zoo or the integrated notebook with our python SDK to bring your model.
The goal for the initial classifier is to make predictions to enable an active learning process explained below.
Narrowing down what experts need to label using active learning
We can easily filter the predictions with high confidence and create an annotation batch for our experts. This is an essential step to only keep high-confidence predictions, so your expert time is spent on examples that are relevant to ESG factors. This approach can save hours of precious excerpt time and get you closer to training a high-performing ML model faster.
Here is an example of how you can generate more ground truth quickly.

Based on your domain knowledge, you can decide on what factor I should assign Covid related sentences to. For this example, I will assign “social” to sentences containing information about working conditions throughout covid. This translates to a labeling function that looks for covid and the context around it in the transcripts.
Iterate!
Now, we can iterate through the above steps to improve the quality of the training data and model performance. This is what we call a data-centric approach.
Through iteration and similar to Covid related sentences, I decided to assign sentences related to Electric Vehicles and Emission Reduction as Environmental factors, Ethical Considerations for Social.
Next steps
Using Snorkel Flow, I was able to create an end-to-end ESG factor extraction application and overcome the common challenges by using:
- Programmatic labeling scales the ability to label complex, domain-specific text as training data.
- Model-guided error analysis to identify data quality issues—including incorrect ground truth labels—and iterate rapidly to improve.
- Collaboration between domain experts and data scientists across labeling, modeling, and iteration.
Instead of extracting data by hand and labeling it, your team of experts can devote more time to deriving investment strategies.
Sign up for a live demo on www.snorkel.ai/demo.

Recommended articles
View all articles

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 29, 2026
•

Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration
June 25, 2026
•

