
An introduction to AI in cybersecurity with real-world case studies in a Fortune 500 organization and a government agency
Despite all the recent advances in artificial intelligence and machine learning (AI/ML) applied to a vast array of application areas and use cases, success in AI in cybersecurity remains elusive. The key component to building AI/ML applications is training data, which traditionally must be manually labeled by subject matter experts (SMEs) in order to train ML models to perform a given task. Organizations seeking to develop custom AI/ML applications for cyber use cases face numerous challenges, each of which is addressed by Snorkel Flow:
- Availability of training data: Unlike other domains, where open-source training datasets are often readily available, datasets featuring real-world cyber events within enterprise networks are rarely released, stifling the development of AI/ML applications. Organizations are left with the daunting task of creating custom labeled datasets required to train ML models.
- Truly massive scale: The amount of network traffic generated on a daily basis by enterprises of every size is almost inconceivably large. Relying on teams of cyber analysts to manually review and label all of this data by hand in order to train ML models is a complete non-starter.
- No two networks are alike: Each enterprise network and policy environment is unique, requiring custom ML training datasets specific to each network’s unique characteristics. The varying definitions of normal versus malicious traffic, and the distinction between authorized and prohibited activities, render “one-size-fits-all” training data and models largely ineffective.
- Dynamic threat environment: Cyber adversaries are creative and adaptive, constantly evolving their tactics, techniques, and procedures to circumvent security measures. Static solutions that don’t allow network defenders to respond to constantly-changing threats will always be one step behind.
Snorkel Flow enables organizations to quickly and easily build their own labeled ML training datasets in-house, on their own network data and relying on their own cyber analysts’ knowledge. This allows them to train custom AI applications specifically suited to the unique nature of their networks and policy environments, and adapt these applications rapidly to accommodate network/policy changes or shifting adversary tactics. All of this can be achieved without any sensitive data leaving the organization within a fully governable and auditable workflow.
In this series of articles, we highlight two major case studies in which Snorkel AI customers overcame these challenges to develop AI/ML applications for cyber use cases with Snorkel Flow:
- A Fortune 500 telecommunications provider uses Snorkel Flow to classify encrypted network data flows
- A U.S. Government agency uses Snorkel Flow for application classification and network attack detection
AI in cybersecurity case study: Fortune 500 telco uses Snorkel Flow to classify encrypted network data flows
A globally-recognized Fortune 500 telecom company used Snorkel Flow to classify encrypted network data flows into their associated application categories. The customer’s data science team faced a number of challenges for this task, including:
- Their past experience of labeling network traffic data by hand was too slow, noisy, and expensive, requiring precious time from network data experts.
- Their existing probe used a static set of rules based on a fixed set of Service Name Indicators (SNIs), leading to a brittle solution that was difficult to adapt.
- Their previous approach also struggled to accommodate changing data distributions, such as responding to network trouble tickets or alarms.
- Multiple tools were required to cover the end-to-end machine learning pipeline, from data exploration and labeling, to model training and analysis.
Task description: Classifying network data flows
To evaluate Snorkel Flow’s ability to accelerate the development of ML models and AI applications for network data use cases, this customer compared a new solution they developed in Snorkel Flow against an existing solution based on a fully-supervised ML model trained on 178,000 ground-truth data examples. The Snorkel Flow solution was also compared against a baseline model trained on a subset of 2,000 examples from this ground-truth dataset. The goal was to see whether Snorkel Flow could enable this organization to produce a solution capable of replacing the fully-supervised ML in a fraction of the time required to manually label a ground-truth training dataset.
In this data, individual flows contained categorical and text features like source/destination port and IP address, SNIs, and forward/backward packets. Flows were then preprocessed to include statistical features, such as forward/backward inter-arrival time (IAT) statistics, flow bytes per second, and flow packets per second. Users of varying skill levels combined a number of different strategies for this effort, including creating no-code labeling functions with Snorkel Flow’s built-in network data visualization tools, writing code-based labeling functions using Snorkel Flow’s Python SDK, and leveraging Snorkel Flow’s ability to auto-generate labeling functions based on self-training and semi-supervised methods.
Results with Snorkel Flow
From an initial subset of only 2,000 ground-truth labeled examples, this telecom customer used Snorkel Flow to produce an additional 198,000 programmatically-labeled examples. A model trained in Snorkel Flow on this 200,000-example training dataset was 26.2% more accurate than a baseline model trained on the subset of 2,000 examples, and within 0.2% accuracy of a fully-supervised model trained on all 178,000 ground-truth examples. For aspects of the data that change over time, such as SNIs (which are prone to drift in production settings), the Snorkel Flow model was compared with a static rules-based solution and the baseline model described above. Incredibly, the Snorkel Flow model was 77.3% more accurate than the rules-based approach and also outperformed the baseline model by nearly 10%. An additional experiment was performed to test Snorkel Flow’s ability to adapt to changing distributions in the data, like the proportions between application types in the network traffic. Here, the Snorkel Flow model beat the baseline model by over 20% and managed to slightly outperform a fully-supervised model as well.
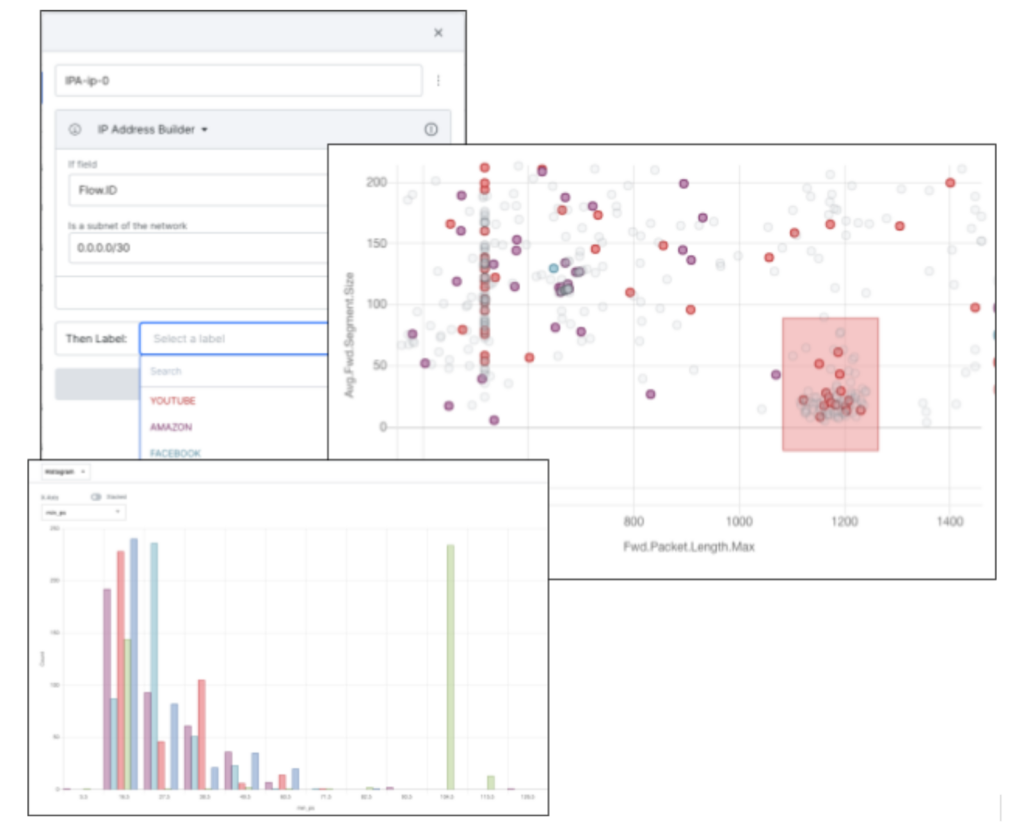
Ultimately, using Snorkel Flow enabled this customer to:
- Deliver high-accuracy ML models for a network data application quickly, without being slowed down by an extensive hand-labeling process.
- Develop adaptable solutions that provide a marked improvement over brittle, rules-based approaches.
- Build applications that are robust to network data drift, by maintaining consistently-high performance scores even when data distributions change.
- Help network data experts and data scientists to work together, using first-class network visualization and data processing utilities in a unified platform.
Encouraged by these impressive results on their first Snorkel Flow project, this customer is now developing a new application focused on anomaly detection for IMS network equipment metrics. This effort will identify real-time anomalies over time-series data, starting with the number of call attempts per second.
AI in cybersecurity case study: U.S. Government agency uses Snorkel Flow for application classification and network attack detection
A major AI center of excellence within the U.S. government selected Snorkel Flow to evaluate programmatic labeling as a means of accelerating the development of AI/ML applications for multiple cyber use cases. For this, ML models created in Snorkel Flow were compared with models trained on pre-labeled datasets. This group recognized hand-labeling as inadequate for their purposes for a variety of reasons:
- Sensitive data cannot be shared externally for crowdsourced or outsourced labeling. Internal access is also frequently restricted to only those with a valid need-to-know, making the task of labeling ML training data even more difficult.
- Labeling data by hand leads to ineffective workforce utilization. Experienced cyber SMEs are in high demand and short supply. There simply aren’t enough available to hand-label millions (or tens of millions) of individual data points.
- Labeling data isn’t a “one and done” task. ML training data must be frequently updated to adapt to changes in real-world inputs or shifts in organizational objectives, which only magnifies the scalability issue.
- ML models trained on hand-labeled data lack explainability. For an important policy decision or military action, it’s essential to articulate precisely why a specific choice was made. The need for trustworthy AI extends this to AI/ML.
Task description: Application type classification
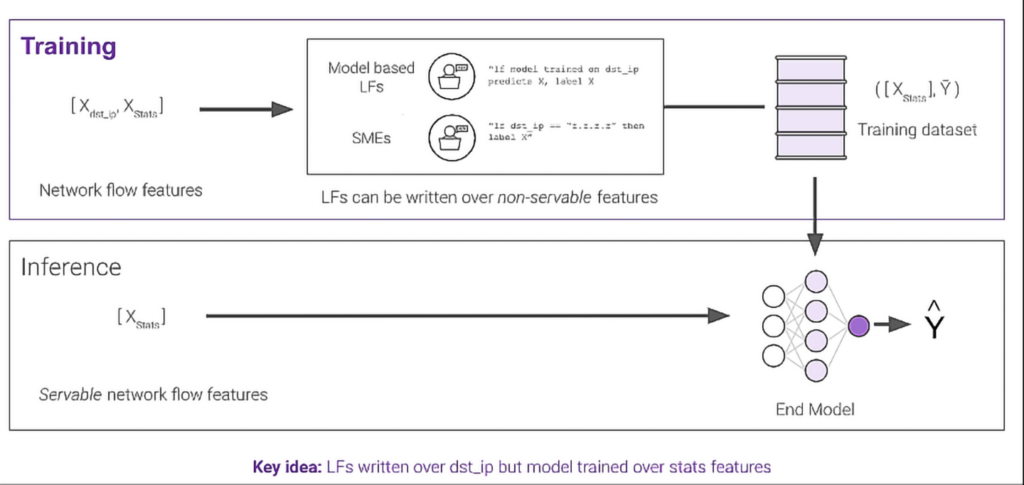
The dataset for this task consisted of network packets collected from different applications, described using 50 data features and containing over 2,700,000 total records. The feature set included a mix of packet statistics (e.g., packet count, length of traffic, etc.), along with source/destination IP addresses and ports. Destination IP is very useful for predicting application type, but generally not advisable for use in training an ML model because applications often change the destination IPs used over time, and a model trained on this feature would not be able to adapt to such changes. Snorkel Flow provided a way to use the destination IP to quickly label training data with labeling functions, while preventing the resulting ML model from using it for training in lieu of more reliable packet statistics. In Snorkel Flow, we refer to this as a “non-servable” feature: a feature that can be used for labeling the data, but should not be relied upon as a feature for model training or prediction.
That is, as shown in the image below, destination IP was incorporated as a non-servable feature for the labeling functions (LFs) used to label the training data, alongside packet statistics and port information as servable features. However, at inference time, the trained model only relies on the servable features (i.e., packet statistics and port information), excluding destination IP as a non-servable feature.
Results with Snorkel Flow
Using Snorkel Flow, the customer’s team of data scientists and cyber SMEs programmatically labeled nearly 280,000 records using just 6 labeling functions. All the labeling functions had extremely high precision, with four achieving 100% precision, one hitting 99%, and another reaching 96% precision, and each with coverage proportional to the class distribution in the original dataset. An ML model trained in Snorkel Flow on this programmatically-labeled dataset was compared with a baseline model trained on 2,000 pre-labeled examples (representing a typical hand-labeled dataset for this kind of task). The Snorkel Flow model trained on the programmatically-labeled dataset outperformed the baseline by 7.4 points on an F1 scale. Additionally, the built-in targeted error analysis tools in Snorkel Flow were leveraged to discover and address several errors in the original dataset for this task. For example, a number of DNS traffic records were improperly labeled (by the source) as various different application types, rather than being labeled as DNS traffic itself. Snorkel Flow made it easy to quickly filter the dataset to identify these examples, leading the customer’s cyber SMEs to determine that all DNS traffic should be treated the same, rather than being grouped inconsistently into traffic examples from different applications. Overall, based on the error analysis performed in Snorkel Flow and the data errors detected, 41% of the original dataset was relabeled.
Task description: Network attack detection (Port scan vs. Benign traffic)
For this second task, a dataset of ~30,000 network packets with 85 features (e.g., packet length, IAT, etc.) was used to characterize traffic as either benign or part of a port scan attack. Instead of relying on interactive SME input in Snorkel Flow, here is an existing network attack ontology was directly transformed into labeling functions.
Results with Snorkel Flow
With just two labeling functions derived from the ontology, 100% of the original dataset was programmatically labeled in Snorkel Flow (i.e., all 30,000 examples). An ML model trained on the programmatically-labeled dataset achieved 88.1% accuracy.
Based on these initial successes, this federal customer is now exploring further work using Snorkel Flow to enable other mission-critical applications for AI in cybersecurity, and also extending the deployment of Snorkel Flow to non-cyber areas like financial analysis.
For organizations building AI applications using programmatic labeling and the data-centric AI approach pioneered by Snorkel and enabled by Snorkel Flow, solving all of these challenges becomes possible. To learn more about Snorkel and how we can help your organization accelerate the development of AI solutions for cyber use cases, or to request a demo, follow us on Twitter, Linkedin, Facebook, or Instagram. or contact us to learn more.

Recommended articles
View all articles

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 29, 2026
•

