New Snorkel leaderboard. See the results.
Weak Supervision in Biomedicine
In this episode of Science Talks, Snorkel AI’s Braden Hancock chats with Jason Fries – a research scientist at Stanford University’s Biomedical Informatics Research lab and Snorkel Research, and one of the first contributors to the Snorkel open-source library. We discuss Jason’s path into machine learning, empowering doctors and scientists with weak supervision, and utilizing organizational resources in biomedical applications of Snorkel.
This episode is part of the #ScienceTalks video series hosted by the Snorkel AI team. You can watch the episode here:
Below are highlights from the conversation, lightly edited for clarity:
How did you get into machine learning?
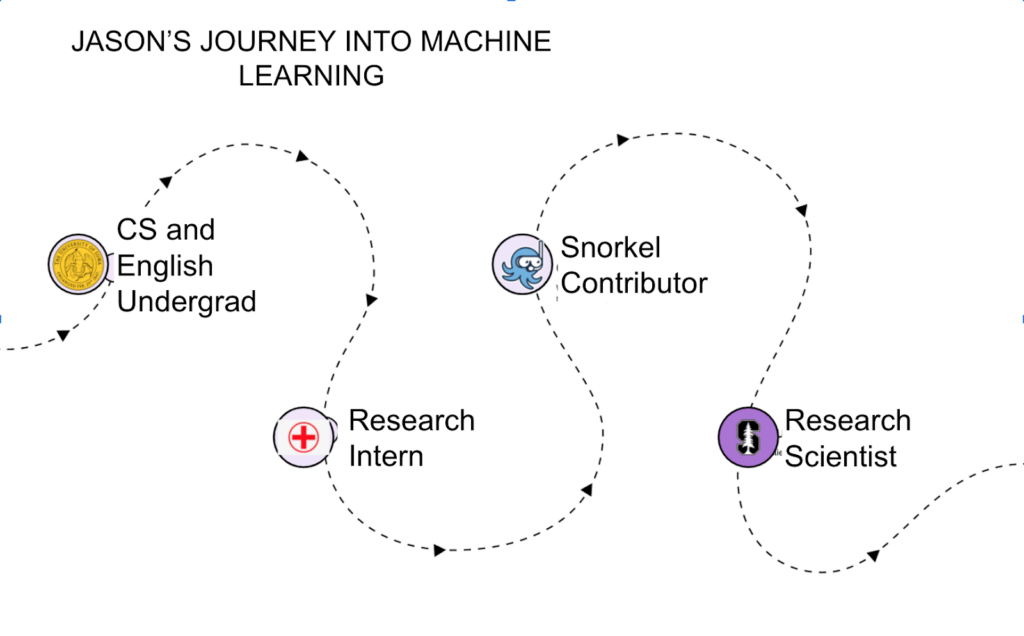
Jason: Originally, during my undergraduate days, I intended to go into medicine. However, I enjoyed engineering classes way more than biology classes, so I shifted and majored in Computer Science and English. I also worked with a research group at the University of Iowa to track infections in hospitals. I suddenly found myself putting sensors on healthcare workers to track their movements and pulling a bunch of data from their hospital infrastructure – all for monitoring and anticipating how diseases spread to the hospital.I was overwhelmed and excited by all of that data. That was the first time when Machine Learning (ML) as a powerful paradigm took root in my imagination. After that, I was sold and went to graduate school, starting to work with EHR data and doing the standard ML work to get there.
What was the first application that you applied Snorkel to?
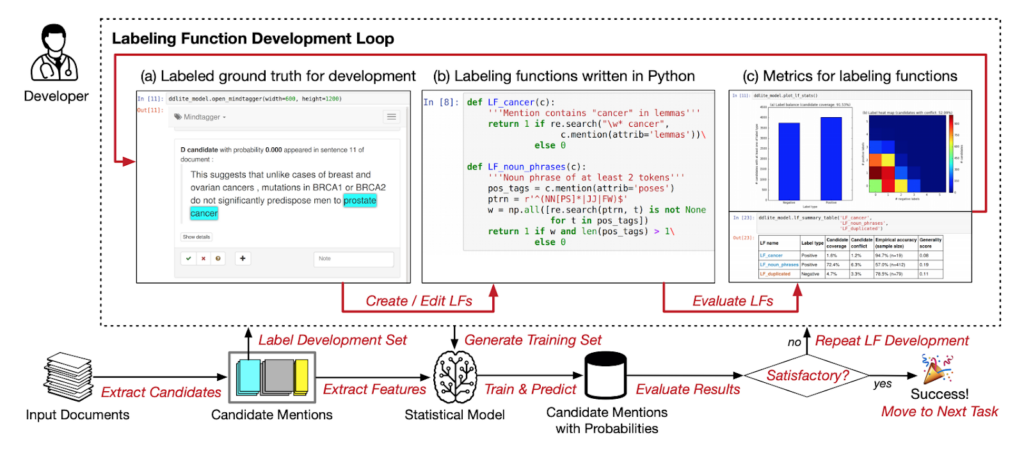
Source: Data Programming with DDLite: Putting Humans in a Different Part of the Loop (Ehrenberg et al., 2016)
Jason: I was introduced to the Snorkel concept while Alex was writing his data programming paper for NeurIPS back in 2016. There was a hackathon we ran at a coffee shop called HanaHaus in Palo Alto. A bunch of people got together to test-write some applications, such as tagging disease names and texts. Those turned out to be one of the experiments that went into that paper.That was my first introduction to the idea of generating training data without using hand-labeled methods. It was a crazy paradigm that made zero sense to me at the time.After that, hackathons started to be a normal process of the Snorkel development cycle. I would collaborate with the other folks working on Snorkel to think about making Snorkel work for real-world problems across various domains beyond biomedicine. That was the kickoff to weak supervision, which I have been sold on and enamored with since those early days in the HanaHaus.
What is weak supervision applied for different modalities?
Jason: It’s different by modality in my experience.The text modality benefits a lot from the ML ecosystem, with tools like HuggingFace and spaCy. Images, especially medical imaging, have their own challenges. You need to think about how to wrangle different sources of labels effectively. Both text and image modalities can benefit from traditional methods that work and new methods that show promise.We have worked with the time series domain – analyzing sensor data to detect freezing of gait in Parkinson’s patients. This modality benefits from a controlled experimental setting and requires substantial domain expertise. Down the road, we can certainly think of more novel ways to apply weak supervision there.
How does Snorkel empower domain experts?
Jason: There is a narrow band of application settings where you know a single individual or a small team of individuals can make a lot of progress in building a fancy model. However, in the healthcare setting specifically, there are various logistical challenges to handling the data.There have been great efforts from groups like the OHDSI initiative out of Columbia, which is taking observational EHR data and putting them into a standard format so that people can develop ML models over them more easily. That type of setting, where you could specify a model and deploy it on multiple hospitals with their data in the same format, is tremendously valuable. In addition, you can plug in auto-generating labels, denoising supervision sources, and auto-ML tools in order to accelerate the model development process.There’s a long road to travel in terms of the general vision to empower frontline clinicians or biomedical scientists.Let’s be concrete about this. Doctors often need guidance on how to make clinical decisions. They have strong insights into things, but it’s challenging to translate such intuitions into a formal problem which a model can be trained over.
Source: Shah Lab
In the Shah lab where I’m working, Nigam Shah has a big effort called the green button to explore marshaling a massive amount of data to provide real-world evidence on demand, more or less. That’s a compelling idea but requires huge efforts across data and scientists to enable this pipeline for answering simple guidance questions.I think COVID-19 has highlighted how people had immediate questions they’d like guidance on:
- If I send this patient home on supplemental oxygen, will they come back in 30 days?
- What’s the likelihood that they will be re-admitted for a health problem?
These fog-of-war questions are super important in clinical care, so how can we build ML infrastructure that enables asking them? Unfortunately, that’s where a lot of work still needs to be done.
From a clinical DevOps perspective, one might ask: how do we maintain, monitor, and update ML systems in an institution?
We have organizations like Google and Apple making forays there. But hospitals are still behind in terms of having the right infrastructure or even having the right practices to maintain infrastructure in a clinical setting. Thus, there are many issues left to be resolved before we can reach the dream setting – where clinicians are more empowered to answer their own questions fed by AI in the background.
How did Snorkel help to repurpose organizational knowledge for ML?
Jason: Concepts like ontologies and concept graphs are part and parcel of medicine, which deals strongly in canonical terminologies (like SNOMED) or medical codes (like ICD-9-CM). Those are standard ways where information is communicated and exchanged, potentially across hospitals and organizations.The most straightforward and most readily available concept/terminology classification process is first to extract a bunch of clinical notes, tag a bunch of concepts, then bend them into broader and more fine-grained categories. Such structured knowledge representations are immensely useful.
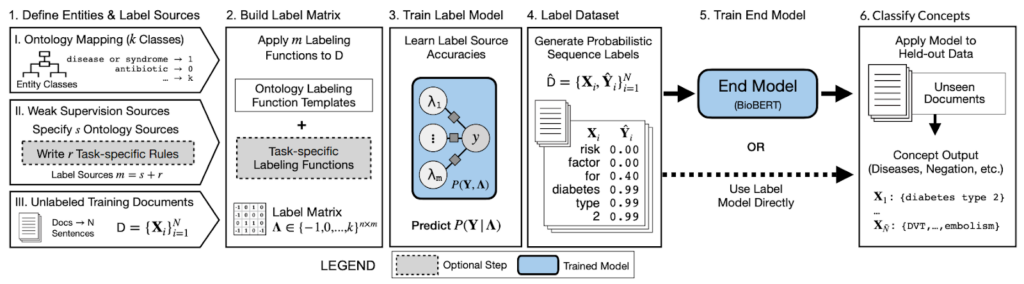
Source: Ontology-driven weak supervision for clinical entity classification in electronic health records (Nature Communications, April 2021)
If you talk with people in this domain, the classic problem is figuring out how to deal with “cathedral” data artifacts like the Unified Medical Language System. They are very noisy, especially if you want to reason over multiple ones. That’s where Snorkel has been nicely suited.You can use Snorkel to combine noisy signals, reason about and correct the noise, and get the same benefits as with hand-labeling.Other classically hard problems such as relation extraction and link prediction across concepts are immensely suitable towards knowledge graph representations. You can pour ontological concepts into Snorkel to build such applications.Ontologies represent the canonical input of virtually every clinical concept pipeline. Snorkel can simply slide into existing workflows and provide the practical benefits while having minimal changes to the infrastructure in place.
What are the challenges of dealing with rapidly changing data?
Jason: COVID-19 has revealed this exact setting. Let’s look at a concrete example.When the pandemic initially started, there were many questions about risk factors, which are crucial to figuring out who needs to be tested for COVID. For example, it was unclear what symptoms are necessarily strongly associated with COVID, how to discriminate COVID from other respiratory illnesses, do you live with someone who has been confirmed as a diagnosis, have you recently traveled, etc. Unfortunately, these things do not show up in structured EHR data. There’s also no setup to answer these questions quickly.
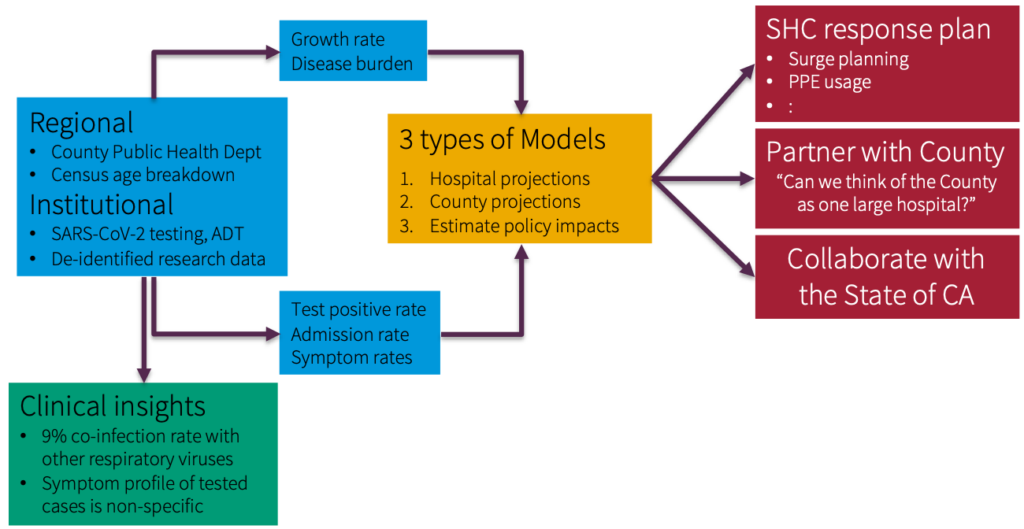
Source: Profiling Presenting Symptoms of Patients Screened for SARS-CoV2 (Medium, April 2020)
This scenario is a great use case for Snorkel. In a day or two, people could look at a small sample of notes and generate enough heuristic rules, such that when combined, they did a solid job of extracting the correct information.Specifically for the symptom example, we worked with the Gates Foundation and ran Snorkel daily in real-time on emergency department notes generated by Stanford. Our goal was to extract symptoms and summarize the state of what people were presenting in the emergency room. The data has since then has been used by Carnegie Mellon for various modeling purposes.As things change on the fly, you need a paradigm like weak supervision to respond appropriately.There are many scenarios where things change – due to crazy pandemics, shifting practices, changing behavior, etc. These changes need to be baked into your training data. There are many interesting settings where you need the flexibility in controlling what is fed to your model training procedure.Where To Follow Jason: Twitter | Github | Google Scholar | Academic Page | Research GateAnd don’t forget to subscribe to our YouTube channel for future ScienceTalks or follow us on Twitter, LinkedIn, Facebook, and Instagram.

Team Snorkel