Hamsa Bastani presented a summary of her and her co-authors’ ongoing work using machine learning and Snorkel AI’s tools to detect and track activities that are associated with a high risk for global sex trafficking. Their work has large implications for the ability of law enforcement organizations and other stakeholders to fight sex trafficking and protect especially vulnerable populations from falling victim to this illegal trade. A transcript of Bastani’s presentation follows, lightly edited for reading clarity.
Hamsa Bastani: Hi everyone. Thank you for joining me here and thank you to Piyush [Puri] and the Snorkel AI organizers. I’m excited to talk to you guys about some work we’ve been doing on unmasking trafficking risk using machine learning and deep-web data.

Let me first start off by saying this is joint work led by Pia Ramchandani, who’s a Ph.D. student at the Wharton School [at the University of Pennsylvania], and then Emily Wyatt, who is part of the TellFinder Alliance, which is a global counter-human-trafficking alliance of law enforcement partners and other stakeholders targeted at addressing human trafficking.

Sex trafficking is a pretty large problem. As you may know, it’s the third-largest criminal enterprise in the world. In 2017 alone, there were about 4.8 million victims, and as you might imagine it targets the most vulnerable individuals in our society. So, for example, about 20 percent of homeless youth identify as victims of trafficking. And so, there’s been a lot of interest in trying to get a data-driven understanding of this problem so that we can better target our limited law enforcement and nonprofit outreach resources.

There’s been a lot of effort on scraping various sex sales websites that have a lot of suspicious activity to try to understand patterns. But one challenge that we’ve faced is that a lot of these sex sales ads conflate commercial sex work, which is largely consensual work by exploited populations, versus human trafficking. Human trafficking requires us to see a degree of coercion, abuse, or deception in order to actually be able to classify it as trafficking. And because law enforcement resources are so limited, we want to make sure that whatever efforts they’re making are targeted more toward the more insidious crime of trafficking.
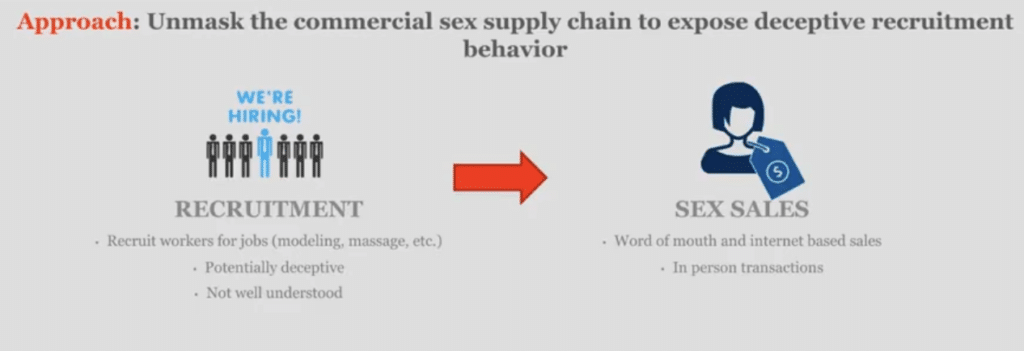
How do you actually distinguish deception? One of the things that, in collaboration with the TellFinder Alliance, we thought about was trying to understand how individuals are actually recruited into these commercial sex supply chains. In particular, one common way in which individuals get trafficked is that people post ads—criminal entities post ads—for non-sex jobs, like “modeling” or “massage” that come with really high paychecks in order to lure these individuals to respond to these ads. Again, these are vulnerable populations, so they might not know that these are scams or they might not actually realize that this [ad] is a non-desirable situation. And so, they actually respond to these ads, they meet with these individuals, and then they get trafficked and forced into selling sex.
One of the ways that we might actually be able to distinguish human trafficking risk from commercial sex work is trying to identify these deceptive recruitment behaviors, which are then linked to sex sales.
How do we actually do this? We start off by looking at deep web data. A lot of law enforcement has now increasingly started looking at websites like skipthegames.com, where a lot of this sales activity goes on, and [where] there’s a lot of risk for trafficking as well. And so these are example data records. There are about 14 million that we received from four adult services websites from the TellFinder Alliance. So these are websites that were earmarked for being tracked by law enforcement because they found them to be suspicious.
I should note that one big limitation is that these posts are all in the English language. So when we’re looking at global records, we’re going to be biased toward English-speaking countries.

This is the post text and generally, you also find structured information, like the location, and some metadata, like the phone number (present here—I’ve actually redacted it because it’s personally identifiable information), email, websites, user information, and so on. This is all in the public domain, but it still might have PII [personally identifiable information] associated with these sex workers. We’re looking at data from about a one-year period.
Let me just show you an example of recruitment linking to sales. So the first panel that we see here is actually a recruitment ad for an escort service. They’re asking, “come work as an escort with Babylon Girls.” “Are you a beautiful young woman?” and so on. You can see there’s no mention of any sex services in this recruitment ad. It’s something we might consider deceptive, because later on what we see is that the same phone number and website that they listed in this recruitment ad appears in many sex sales ads where they’re explicitly selling sex. That means that, basically, the same entity likely is recruiting for one service and then selling for another service. This is what we think has a high likelihood of deception and therefore trafficking risk.
Escort services are a little bit in the gray area. Something that’s even more worrisome is modeling, for instance. In the second panel, we see “apply now, hiring females, we can relocate you” for modeling. Then, that same phone number is associated with a hundred-plus sex sales posts in Canada, the UK, the US, and Australia. This is very, very problematic from a law enforcement perspective because they’re hiring for modeling, which is a non-sex job, and then the same entity is selling sex, which, typically there shouldn’t be a connection there. So, this carries a very high risk of trafficking.
So these are the kinds of entities that we are trying to identify, that are likely trafficking rather than just [hiring] consenting commercial sex workers.
So, you might ask, why is this hard?
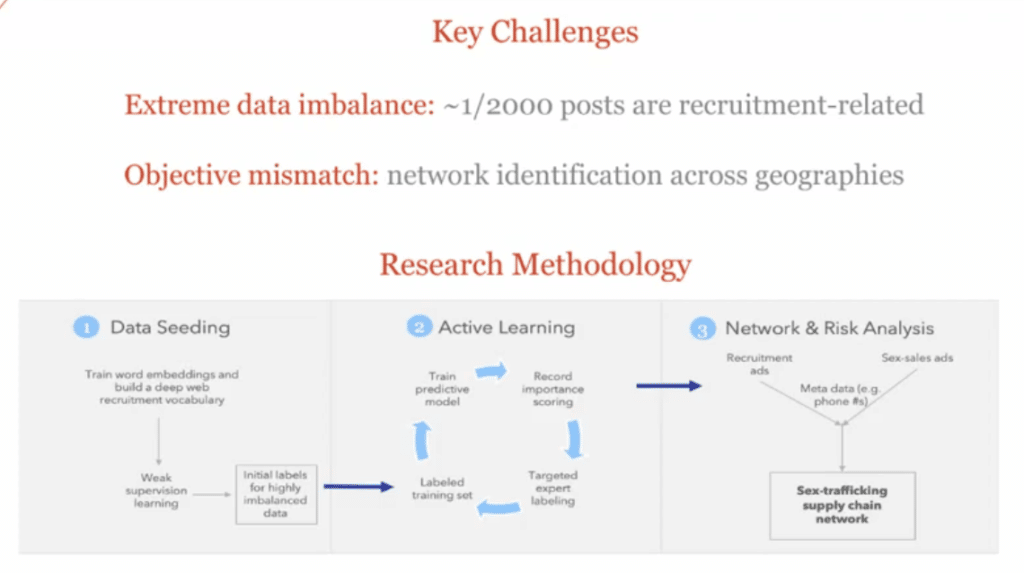
The challenge is that finding recruitment posts is like finding a needle in a haystack. If you look at these websites, they have tons and tons of sales activity, but there’s extreme data imbalance because only one in about 2,000 posts will be recruitment related. So, the first thing we have to do is find these recruitment posts and then use that metadata to actually connect them with sales posts so that we can distinguish which entities have high trafficking risk.
The other issue that I’ll mention is that we don’t just care about getting a good mean squared error. We also want to identify this trafficking supply chain network. So we want to make sure that we’re getting good accuracy and coverage across locations. I’ll talk about that in a bit.
We have a three-part methodology for doing this. In the first step, we’re basically going to try to leverage domain expertise and weak learning—this is where we use the Snorkel tool—to generate an initial, well-balanced training dataset to capture what we kind of already know into a structured format.
Then that, of course, is biased toward what experts have seen, and so we want to actually leverage the power of the data, so we move on to an active learning pipeline to label new posts and identify new recruiting templates that even our stakeholder partners haven’t seen before.
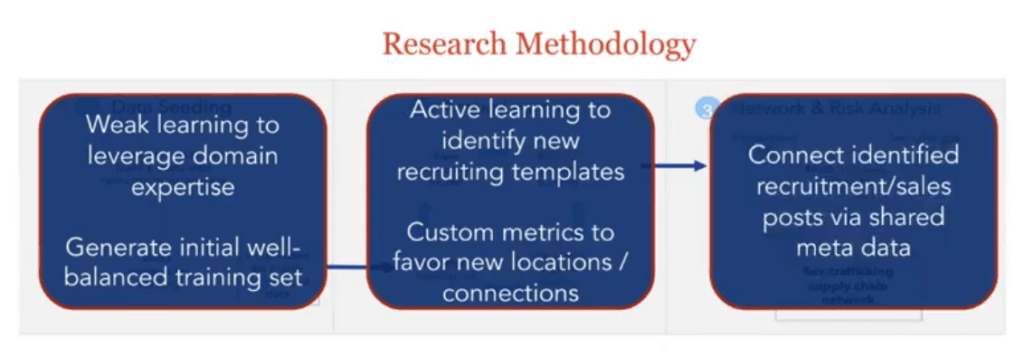
And then finally, we use the metadata to link those recruitment and sales posts to understand the trafficking supply chain, which has various policy implications that I’ll briefly talk about.
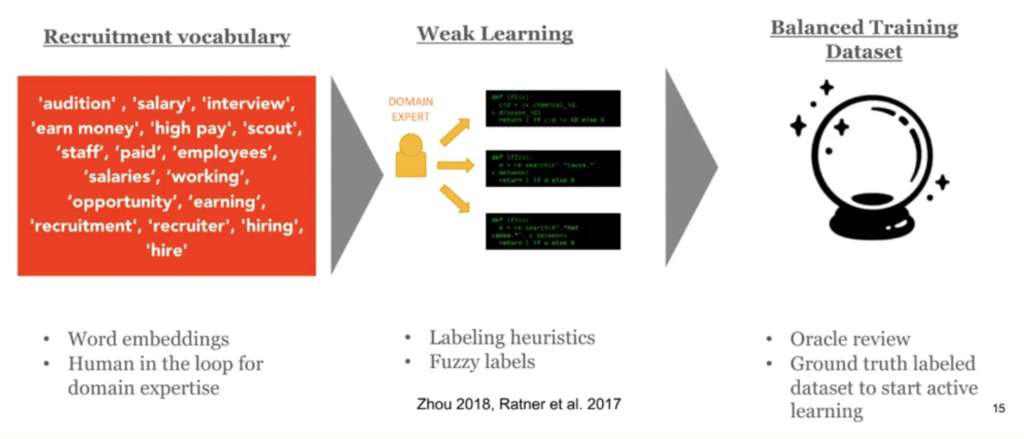
So, in the first step, what we’re basically doing is we talked to a bunch of stakeholders and looked at a bunch of past trafficking cases and we put together a reasonable recruitment vocabulary, and then we trained word embeddings. We looked for any words that were similar or in a neighborhood of this recruitment vocabulary that we identified in the word embedding.
This basically gives us a bunch of weak learners that we can use to try to generate an ensemble model. We did this using the Snorkel tool, and we had a domain expert label these posts in order to get actual ground-truth labels. This gave us a balanced training dataset to start with.
But, like I said, this balanced training dataset is great, but it’s going to be very biased toward what human experts already know. So, then we use this [balanced training dataset] to jumpstart an active learning process.
In classic active learning, we label very uncertain posts so that, with a very limited budget of labels, we can try to get to as high-functioning of a model as possible. But here we don’t just care about mean squared error like I mentioned.
We also care about coverage across the network. So, we modify the usual prioritization score in active learning to capture network-based attributes. We also throw in node uncertainty—are we getting enough labels in a particular city or location?

And we also throw in things like edge uncertainty—are we sure whether or not there is an edge in this human trafficking supply chain in this particular location? This helps us do better network discovery.
Just to illustrate the value of this kind of approach: like I said, only about one in 2,000 posts really are going to be recruitment related. So, if you took a random sample out of the data and tried to label it, you really wouldn’t get very far, because your hit rate would be about that 0.06 percent. Before you can really train a neural network, you’re going to have to label millions of posts.
So what we did, to recap, was that weak learning approach to get that initial training dataset. That helped us get a training dataset that actually has 22 percent positive labels, so it’s not so imbalanced. But unfortunately, we only found three different recruitment templates because it’s based on what stakeholders already know. So it basically focused on modeling, massage, and escort, which are kind of well-known recruitment templates.
That’s why we jump-started this active learning process, where we reviewed a whole bunch of new posts where our model was uncertain to get good coverage across the network. That, of course, reduces the fraction of positive labels. It goes down to 14 percent because we’re labeling a lot more posts now, and a lot of them might be negative. But now, we were able to identify over 25 different recruitment templates. A lot of these were even new to our stakeholder partners. We also found a bunch of recruitment locations that I’ll talk about in the policy implication section. This was really interesting because we’re really getting those data-driven insights that we wanted.
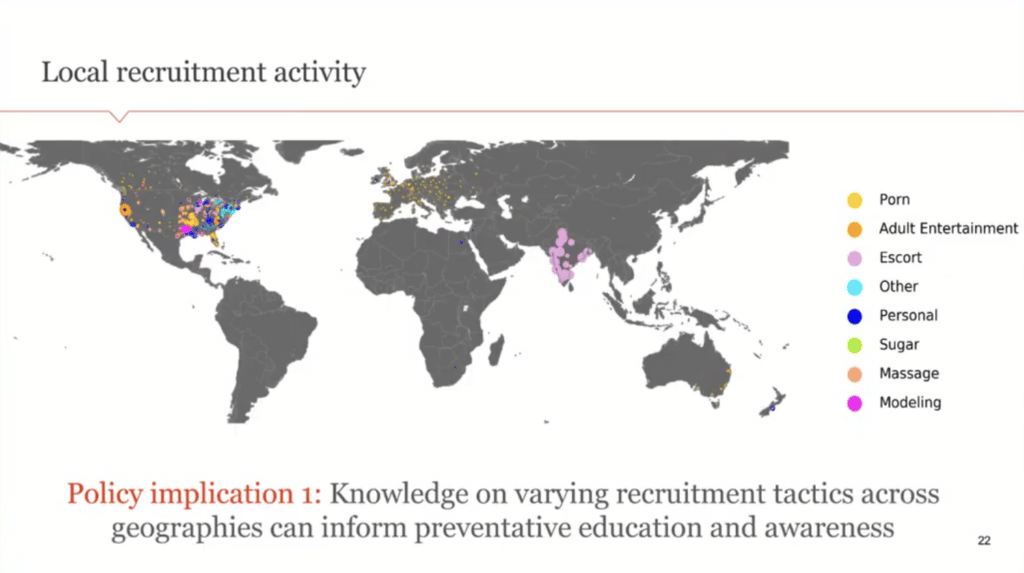
Let me quickly walk through some of the policy implications here. This is the main result that we get. This is a map of the world. Like I mentioned, we’re looking at English language websites that are being tracked by law enforcement right now, and so there’s a bias, as you can see, toward the United States, the UK, and a little bit of India. We don’t get coverage in other locations, but we hope this framework would be useful if we were to track websites in other languages as well. There are some challenges with doing natural language processing and word embeddings in those locations, but for the English language posts, we see that these colors represent the type of recruitment activity that’s happening in that location.
It might be through porn, escort personals, “sugar daddy,” massage, modeling, and so on. You can see that there’s actually a lot of variation by location on the type of recruitment activity that’s happening to lure vulnerable people into this trafficking supply chain. This is really interesting and important because there’s a lot of nonprofit outreach work and social workers who try to educate these vulnerable individuals, like the homeless and so on, to understand how they can distinguish actual job offers [from] these trafficking or scam-related job offers so that they’re not put in an exploited position. Having knowledge of the local recruitment tactics in that location can really inform preventative education and awareness so that they’re able to better combat this sort of exploitative recruitment.
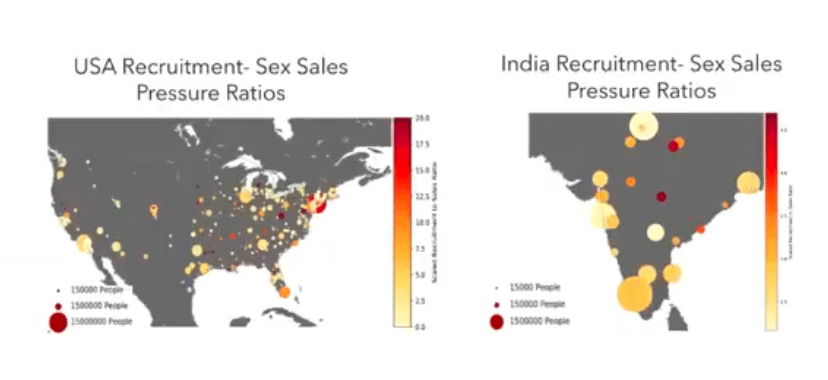
Next, we can look at “recruitment” versus “sales pressure.” Here, just for clarity, we’re just focusing on the US and India. The color of these dots represents, for that particular location: what is the recruitment-to-sex-sales pressure ratio? If it’s a very yellow dot, it means that there are way more sales happening compared to recruitment. If it’s a very red dot, it means that there’s a lot of recruitment happening compared to sales. The size of the dot here captures the population. So, what we’re seeing here is a lot of large yellow circles, and then we’re seeing many small red circles, which indicates that sex sales are very predominant in urban, large cities. And this matches what we see in practice. So that’s why a lot of law enforcement stings are concentrated in locations that are very dense and high-population.
But, we see that recruitment is actually quite different. A lot of recruitment is happening in areas with smaller populations that are less urban. This is very important because there’s not a lot of law enforcement coverage in those locations, so we might not be able to even have visibility into this pernicious activity that’s happening there. Knowledge of this is important because different jurisdictions might want to collaborate to try to stop both recruitment and sales.
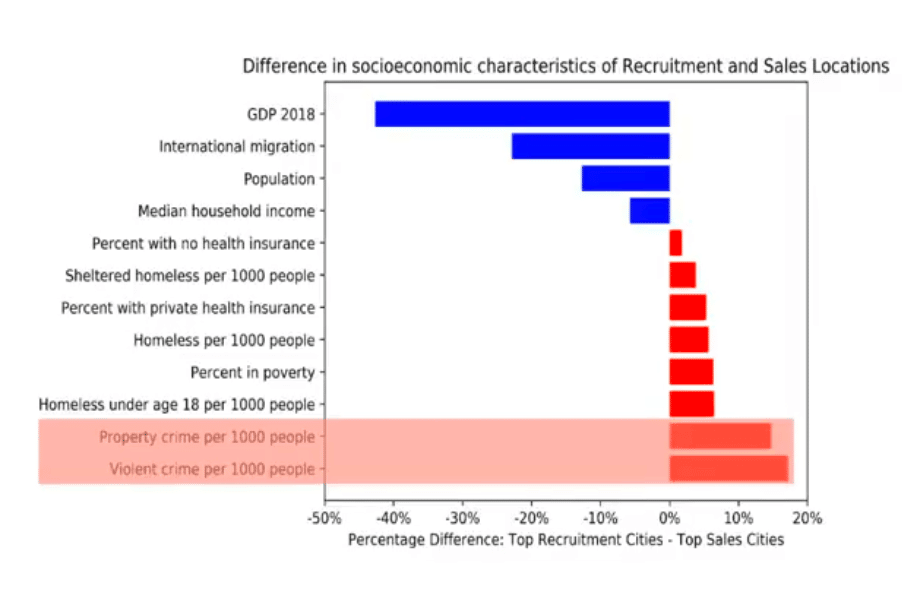
Just to illustrate this a little bit, we can look at the socioeconomic characteristics of locations that are focused on recruitment versus sales. Red here means that it’s mostly recruitment. Blue means that it’s mostly sales.
We see that in recruitment-driven areas, there’s a lot of property crime and violent crime. Again, these are places that tend to have a lot of vulnerable people who are exposed to dangerous conditions. On top of that, they also have a high number of homeless individuals. These are the sort of vulnerable populations that are often targeted by these recruiting approaches, and this matches what we might expect.
Then if we look at the sales locations, they’re very different. These are places that have a high median household income and a high GDP. These are also the places because they’re naturally richer, they tend to have more law enforcement resources and more nonprofit efforts targeted toward helping people as well. So, we’re raising a flag here that we might want to target these smaller locations where a lot of this pernicious recruitment activity is happening. There might be some effort for these different jurisdictions to share resources so that they might be able to help each other when thinking about these trafficking supply chains.

Next, we can look at something called the recruitment-to-sex-sales pathways. Here we’re just visualizing this network and we’ve just picked out the really high-density edges here. What we’re looking at here is, there are a lot of counts of flows from one city or one location to another. This is a directed graph. The red portion of the line is where the recruitment occurred and the green portion of the line is where sales occurred. Some of these were what we expected to see. Before we started working on this, our law enforcement partners said that there’s a lot of movement of victims recruited in the Midwest and actually being sold on the different coasts in the US. And so we see that. There was also an expectation that there were a lot of Eastern European women who are being trafficked into the US, and so we also see this. That checks out.
One thing that we really didn’t expect to see is all this recruitment activity in Australia coming into the US. That’s something they’re looking into that came out of this analysis that we’re not sure is real or not yet.
I want to note that most of these connections don’t explicitly mention escort work. These are really deceptive recruitment [efforts] in that they’re often going after modeling, massage, and those types of recruitment that are really quite separate from sex sales.
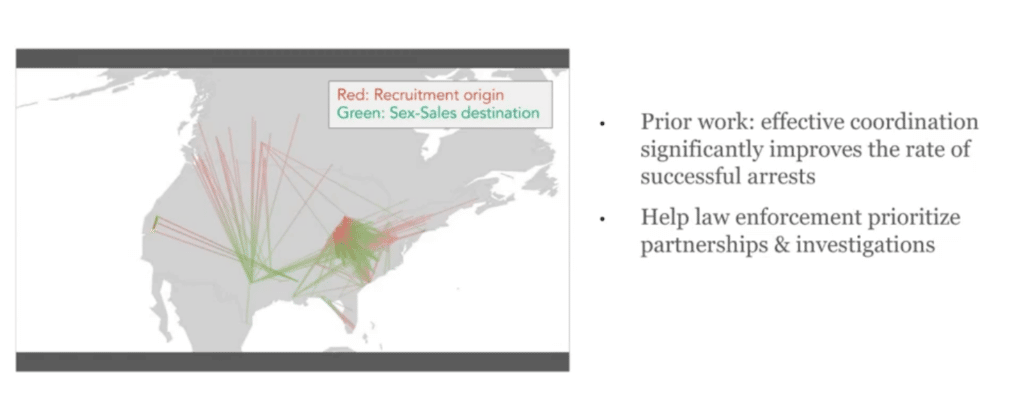
Why is this important? Basically, there are a lot of results showing that when law enforcement organizes sting operations in order to arrest these trafficking entities, coordinating with different jurisdictions or different departments can be hugely helpful. But, it’s very difficult to figure out who to coordinate with if you’re in law enforcement because there’s no prioritization that’s been offered. They’re usually coordinating with people that they know, [jurisdictions where] they have friends, other departments, and so on.
But this supply-chain view can tell us, “Okay, so we see victims being recruited at point A and being sent to point B, and so probably the police departments in A and B can coordinate in order to attack the supply chain from both ends. This can significantly improve the rate of successful arrests without putting too much burden on our law enforcement resources to actually partner with everybody under the sun because then that becomes too untenable. This is really, hopefully, going to inform better resource allocation.
Just to summarize, these, we believe, are the first large-scale views into commercial sex supply chains. [It is] really characterizing recruitment into the supply chain, all the way to sales, which gives us a new view of human trafficking risk that we can’t see just from the sales side. This is really a two-sided platform.
This methodology, we think, can be useful for other use cases that require uncovering granular local patterns from large-scale unstructured text data.
And before I end, I just want to, again, thank my co-authors, Pia Ramchandani and Emily Wyatt from the TellFinder Alliance. It’s been a lot of fun working with them.
Thank you.
Piyush Puri (Host): Hamsa, thanks so much for the presentation. That was great.
We do have a few questions that are coming in now. So if you don’t mind, I’d love to get your take on some of these.
So the first one we have is: “Have you seen any benefit to active learning versus simply retraining on new and old data? Is this data being passed back to the labeling phase for human expert review?”
HB: Yes. Active learning was actually hugely helpful here because if you just randomly label the training data, your hit rate is so small. You label, you know, 20,000 posts and 10 posts will be recruitment related. That is way too imbalanced for it to fit any kind of deep neural network model. So, we actually need active learning in order to make sure that we’re characterizing enough recruitment posts. [With] all of these posts, once we pick out a post, we have a human expert label [it], which is why we need active learning in the first place. The labeling is very time-consuming and also a bit traumatic because you have to read these really disturbing posts to assign a label.
PP: Yeah, I can imagine. Another question is: “What are some examples of labeling functions that extend beyond keyword matches?” [The questioner] is interested to know how domain experts are capturing complex signals.
HB: In the beginning, we only looked at keyword matching for that weak learning phase, and that was kind of sufficient. Then in the second phase, where we did active learning, that’s where we’re fitting an LSDM model. We haven’t actually tried to interpret what the LSDM model is. That’s a good question. Maybe we should do that. But it’s learning complex nonlinear functions on the word embeddings directly. There’s a pooling layer for the post, so it’s kind of your standard architecture. We saw it converge after labeling about 50,000 posts. So, that was reasonably manageable with limited trauma.
PP: Got it. So, if the audience wants to continue to follow this work that you’re doing, what’s the best way to follow the work that you guys do and reach out to you with any follow-up questions?
HB: Feel free to reach out through my email. I have a website, or through LinkedIn, or Twitter, anything.
PP: Okay. Well, Hamsa, thanks so much. We really appreciate you joining us today.
HB: Thanks so much, Piyush. Take care.

Recommended articles
View all articles

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 29, 2026
•

Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration
June 25, 2026
•

