New Snorkel benchmark leaderboards. See the results.
Uncovering the unknowns of deep neural networks by Sharon Li
Learning about the challenges and opportunities behind deep neural networks
In this talk, Assistant Professor in Computer Science Sharon Li shares some exciting work about uncovering the unknowns of deep neural networks. She also shares some exciting challenges and opportunities in this domain. If you would like to watch Sharon’s presentation, we have included it below, or you can find the entire event on our YouTube channel.
Additionally, a lightly edited transcript of the presentation can be found below.
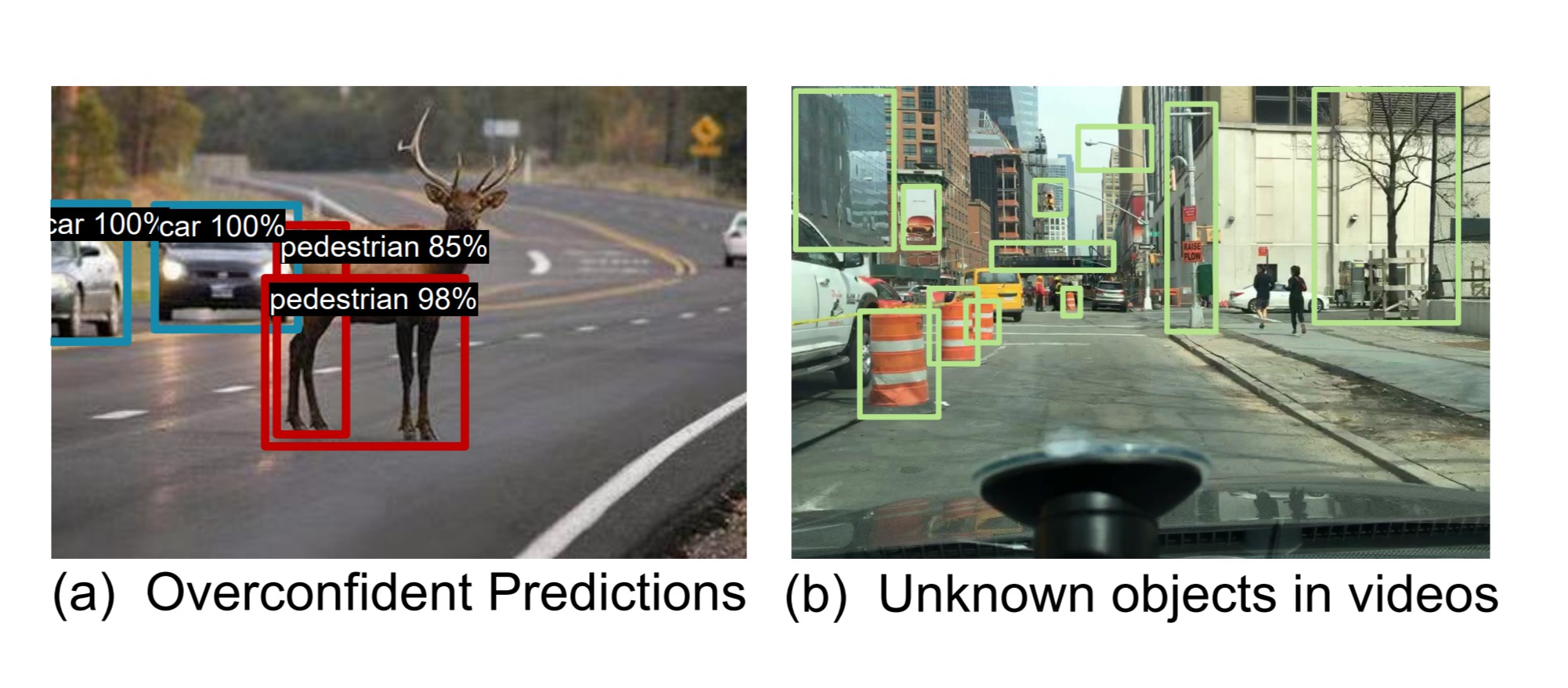
Let’s start by thinking about how would you approach building and deploying a self-driving car model? The typical process is to start collecting some training data with corresponding labels. To simplify some things, we will train it using our favorite machine learning model, and the output typically contains some predefined categories such as pedestrians, cars, and trucks. There are thousands of details to go through in this case, but once we finally have a model with decent performance and we think it is ready to deploy—more unexpected work is found. In machine learning 101, we learn that training and testing data distributions match each other, but this assumption rarely holds in reality. So it is closer to this open-world setting where many unknowns could emerge in the real world. If we take an image from the MS COCO (Microsoft Common Objects in Context) dataset and run it through a self-driving car model that we just trained on the ODD dataset, we can see that the model can produce quite overconfident predictions, for instance, an unknown class cow which was never exposed to the model during the training time.
The future of data-centric AI talk series

Don’t miss the opportunity to gain an in-depth understanding of data-centric AI and learn best practices from real-world implementations. Connect with fellow data scientists, machine learning engineers, and AI leaders from academia and industry with over 30 virtual sessions. Save your seat at The Future of Data-Centric AI. Happening on August 3-4,2022.

In other words, deep neural networks do not necessarily know what they do not know, and this raises significant concerns about the model’s reliability because algorithms that classify these out of distribution samples into one of the known classes can be catastrophic. For example, if we think about healthcare, a medical machine learning model trained on a particular set of diseases may encounter a different disease, and it can cause mistreatment if not handled cautiously. This issue is prevalent not just for stake domains we just saw but also in many other scenarios where machine learning is being used on a day-to-day basis.
I spent some time working in the industry, so my time working with real-world machine learning models and data has given me a strong belief on how important this fallen problem is and how we can build unknown-aware deep learning models for reliable decision-making in such an open world. A critical step towards this goal is to detect out-of-distribution data.
What is out-of-distribution data?
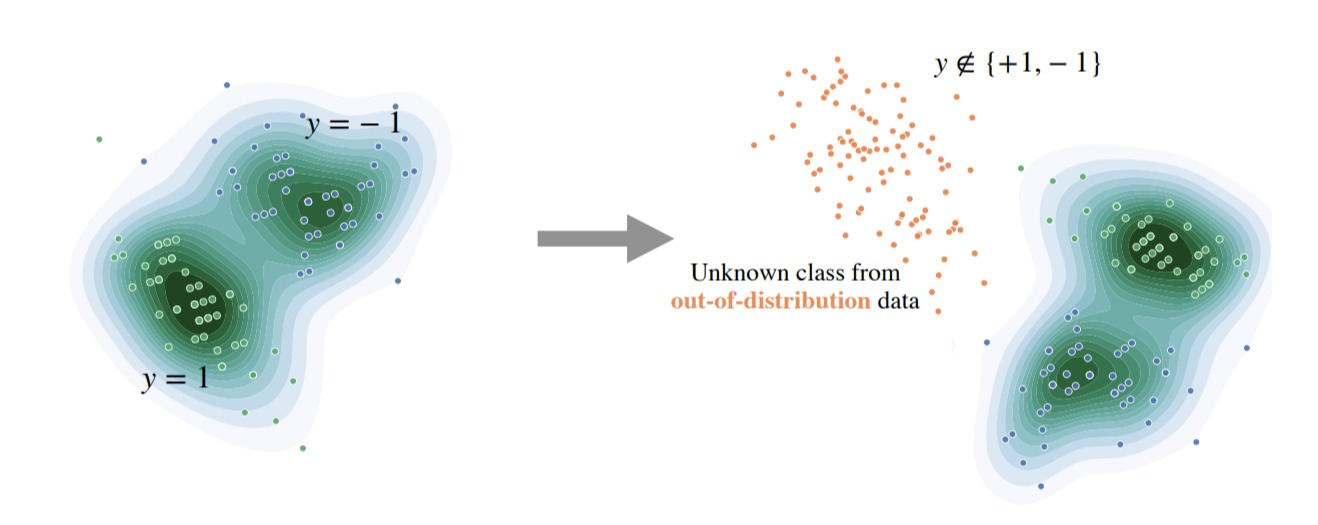
For instance, we have our training distribution, a mixture of two Gaussians for a class label y=1 and y=-1. In this case, our distribution would be the marginal of this joint distribution defined over the input-space x times the label-space y. Now, during the deployment time, some orange dots can emerge that are out-of-distribution from an unknown class other than green and blue. Therefore we do not want the model to predict either y=1 or y=-1. To translate this toy data into some higher dimensional images, we can take CIFAR-10 (Canadian Institute For Advanced Research), a standard computer vision dataset as in-distribution, and SVHN (Street View House Numbers) as OOD, which have disjoined labels. We can say that this OOD(Out-Of-Distribution) is too apparent for us humans, but this could trouble the state-of-the-art neural networks.
SVHN is just one of the OODs that the model would encounter, and there are many other unknowns on this complex data manifold. Therefore, out-of-distribution detection is indeed a challenging problem.
Challenges in deep neural networks
The first challenge is the lack of supervision from unknowns during training. Typically the model is trained on the in-distribution data only, in our case, the in-distribution data (green and blue dots) is trained using empirical risk minimization. We cannot anticipate where these orange dots can emerge because there is a massive space of unknowns, especially in the high dimensional space. The high-capacity neural networks further exacerbate this problem we are working with nowadays.

In this plot, if we look at the decision boundary in the middle, which tries to distinguish between orange and blue classes, we can see that the decision boundary undesirably includes and covers some of the OOD data red dots here. It is on the same side as these orange dots, so it will be classified as orange dots during inference time which is undesirable behavior. We do not perform density estimation using deep generative models because it has some unique challenges and can be challenging to optimize.
Post-hoc out-of-distribution
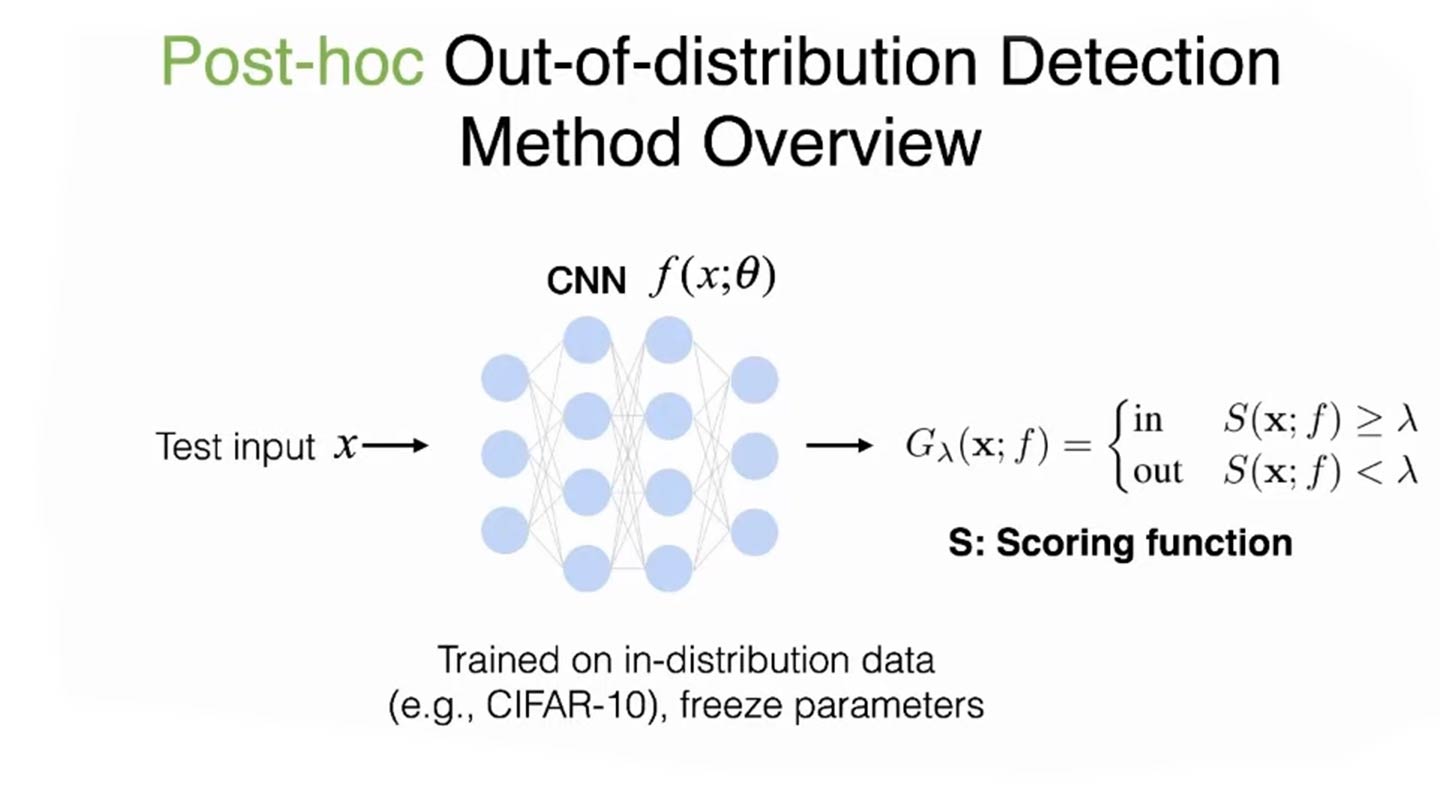
Typically, we train the model on the in-distribution data(CIFAR-10) using empirical risk minimization. Now, we will take the network without modifying its parameters. During the inference time, for any given input, we will use a scoring function for OOD detection; if the input is below a certain threshold, then we are going to reject it; otherwise, we will produce the class prediction as usual. The advantage of post-hoc OOD detection is that it does not interfere with the original model or the task, especially if it has already been deployed and running in the production. The apparent baseline is to use a Softmax confidence score. However, it does not seem to work well because neural networks tend to produce quite overconfident predictions, and therefore we can see areas heavily overlapping between in-distribution versus out-of-distribution.
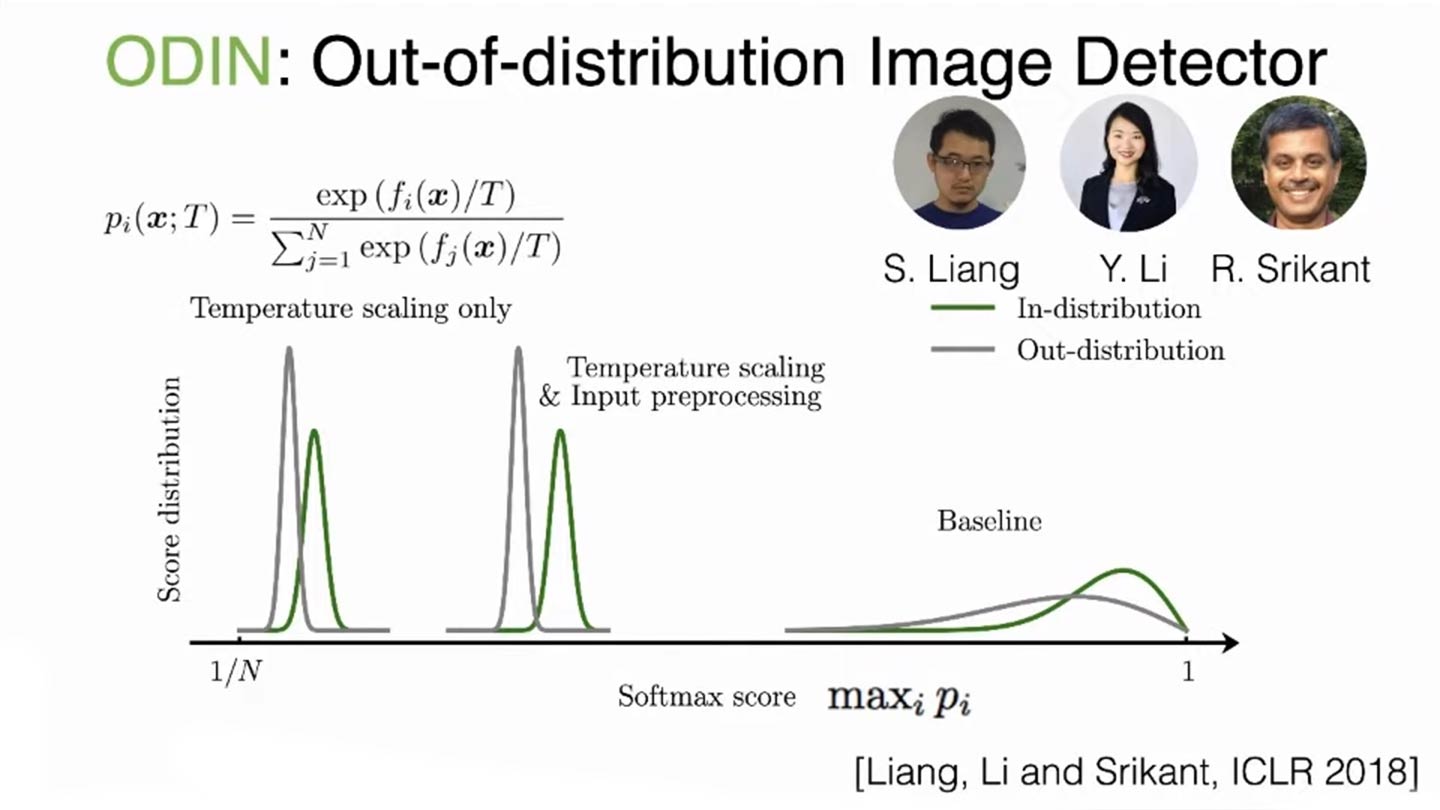
Our early work on ODD was one of the first to address this issue using temperature scaling and input pre-processing, and mathematically we can show that a large temperature has a strong smoothing effect and will make Softmax score distributions more separable between the two types of data.
In our recent neural networks paper, we proposed an energy-based OOD detection framework that leverages the energy score derived from the output logic of this neural network for detection. So, the energy-based function takes an input x and corresponding label y, producing a scalar called energy. This function can be non-probabilistic, and if we want to turn this into a probability density, we can do so using Gibbs distribution. In this work, the key idea is to replace the Softmax confidence score with the energy score for OOD detection, and so with the energy score, the distribution now becomes much more separable, particularly the in-distribution no longer has a spikey distribution that we saw earlier.
To evaluate our approach, we train, in this case, a model on CIFAR-10 as in-distribution and evaluate SVHN as OOD. Here we measure the performance in terms of FPR95, which is the fraction of OOD that is misclassified as in-distribution when 95% of the in-distribution is correctly labeled. We want this metric to be as low as possible, and so if we use a Softmax score, this FPR is roughly around 48.87%, and in contrast, using an energy score can reduce this substantially to 35.67%.
The advantage of the energy score is that it is effortless to use, and it does not require any hyperparameter tuning. If you are interested to learn more about it, you can check out our latest papers.
Another exciting thing about the energy-based framework is that it not only works for the multi-class classification but also for the multi-label classification problem. The previous studies have primarily focused on the detection in the multi-class setting where each sample is assigned to only one label, which can be pretty unrealistic in the real world. For example, if we look at the photos on our phones, each photo most likely has multiple objects of interest. Multiple abnormalities may be present even in a medical image. The main challenge in the multi-label setting is how do we estimate uncertainty by jointly leveraging the information across different labels instead of just relying on the one dominant label. In the case of multi-label, we cannot estimate this likelihood because it requires the sampling combinatorically across different labels, so this problem is more challenging than multi-class. We propose this novel scoring function that considers the joint uncertainty across labels and provides some mathematical interpretation from a joint likelihood perspective. In particular, collective energy takes the summation of level-wise energy score, and we can imagine having multiple dominant labels is indicative of in-distribution and vice-versa. Despite its simplicity, joint energy can be surprisingly effective and has less joint likelihood interpretation. The joint energy works quite competitively compared to previous baselines.
Deep neural networks summary

We need to move beyond post-hoc OOD detection methods as they are not sufficient to mitigate this problem of OOD because they do not fundamentally change how the model is trained. If we think about existing learning algorithms, they are primarily driven by optimizing the accuracy of the in-distribution data. We can see that the middle plot’s decision boundary can overshoot and produce an overconfident prediction even though we know it can discriminate among the three classes pretty well. However, they are ill-fated for OOD detection purposes, and therefore we need training time regularization to account for uncertainty outside in-distribution data explicitly. The ideal decision boundary should be something like the right side, which is more aligned with the in-distribution data density.
One way to achieve this is using our proposed energy regularization, which has these dual objectives during the training time, one for classification using the standard cross-entropy laws. So this minimizes the risks on the known dataset, and the second term is intended to minimize the risk for the unknowns, and so this regularization essentially shapes the energy surface explicitly using the squared hinge loss and tries to make the energy as separable as possible between the two types of data. We have this in the first margin the first tries to pull down energy for the in-distribution data, and the second term tries to push the energy to be high for OOD, and so the result of this training is stronger separability measured by the energy score as we can see on the rightmost plot. In contrast, the previous two plots are based on the post-hoc methods; one uses Softmax score, and the other uses the energy score, and both are derived from the pre-trained networks, and we can see that the performance gain is substantial on reducting FPR down to 1%.
Future opportunities for deep neural networks
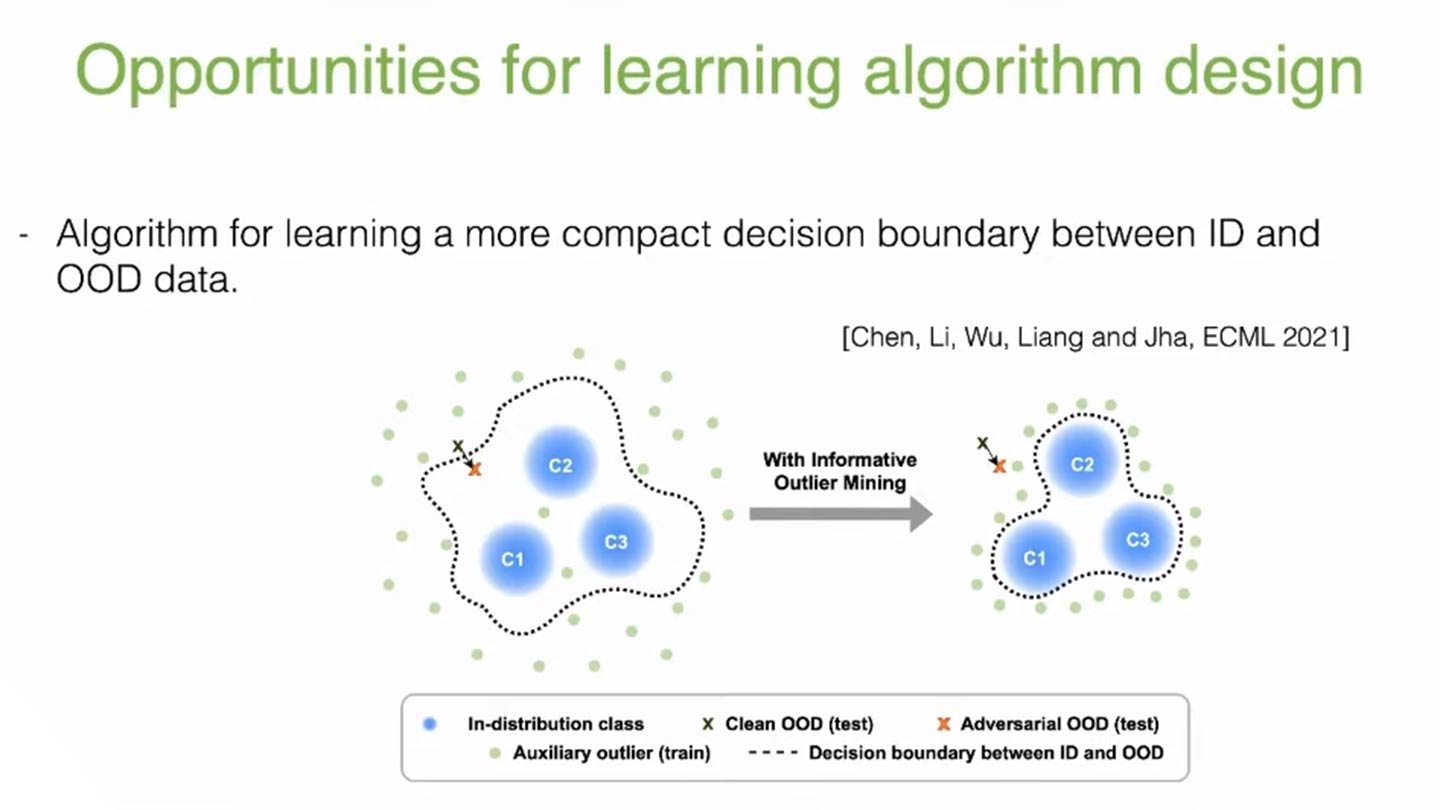
At this point, we need some algorithms that essentially try to learn a more compact decision boundary that cares about the distribution of the data and considers the potential risks associated with the unknowns. Other than that, there are also great opportunities to think about how we can consider and evaluate a more realistic data model. The current evaluation can not be too simplified to capture some of the nuances of the problem in the real world. For example, much current work is evaluated on the common benchmark CIFAR-10, which contains low-resolution images of size 32 by 32 with only a handful of classes. Now, the methods that work well on CIFAR-10 data may not necessarily translate into a real-world setting with more visual categories. Moreover, it turned out that OOD detection performance decreases quite rapidly as the number of classes increases. This behavior is because the decision boundary quickly becomes a lot more complex. Our recent paper develops a group-based OOD detection framework that tries to bridge this gap, and our methods also offer excellent scalability to larger datasets with up to 1000 classes. As part of the paper, we also released a new benchmark based on ImageNet.
An exciting research question to think about is how do we formalize the notation of OOD? As we know, there can be many issues in our training data, and one such issue is potential bias and severe correlation. For instance, we know that the bird species is often correlated with the background. When the model is trained with this bias, it would manifest downstream of the detection. For example, the spurious OOD with similar background information but different semantics can be challenging to detect. It is important to model this data shift by considering both these invariant and environmental features.
If you’d like to understand and explore more about this research, please visit the following research repositories on Github:
- Energy-based out-of-distribution detection (Energy OOD).
- MOS: Towards Scaling Out-of-distribution Detection for Large Semantic Space.
Bio: Sharon Li is an Assistant Professor in the Department of Computer Sciences at the University of Wisconsin Madison. Previously she was a postdoc researcher in the Computer Science department at Stanford University, working with Chris Ré. She earned her PhD from Cornell University in 2017, where she was advised by John E. Hopcroft. Her research has received several awards, including the Facebook Research Award, and Google-Initiated Focused Research Award, and was named Forbes 30 Under 30 in Science. Li is a faculty fellow at the Madison Teaching and Learning Excellence (MTLE) program.Where to connect with Sharon: Website, Twitter, Linkedin.

Team Snorkel