
The future of data-centric AI talk series
Background
An AI system consists of two parts: the model— algorithm or some code—and data. The dominant paradigm in machine-learning researchers has been for most data scientists, including myself, to download a fixed dataset and iterate on the model. That this has become conventional is a tribute to how successful this model-centric approach has been. Largely thanks to this model-centric paradigm of AI development, today the “code” or model is basically a solved problem.
This emphasis on models has brought us to the point where high-performance model architectures are widely available. However, approaches to systematically engineering datasets has lagged. Today, I find it far more useful to use tools, processes, and principles to systematically engineer your data to improve the performance of your AI system. Just in the past 4-5 months, the Data-centric AI movement has gained a lot of momentum, and now the term “Data-centric AI” appears on many companies’ homepages, where it was almost non-existent before.
As a field, machine-learning teams are still trying to sort out a set of best-practices or principles for the data-centric approach.
What I hope to do here is to lay out what I see as some of the most important principles, or tips, for Data-centric AI development. As a field, machine-learning teams are still trying to sort out a set of best-practices or principles for the Data-centric approach. Typically, the evolution of a new technology proceeds in three steps: things start out with a handful of experts who perform a new task intuitively, searching as they go along for whatever works. After some progress, teams begin to identify principles that can define their workflow, and these ideas are then adopted and applied by others. Eventually, in the final step and as we make more and more progress, people make tools with which to apply these increasingly firm principles in a more systematic way.

When it comes to data-centric AI, specifically, I think the field was in that first “intuitive” phase for quite some time. I think we have now firmly reached the second phase, with intuitive solutions becoming principles and with a common mindset gaining credence within the AI community, thinking about data-centric approaches as the crucial new frontier in machine learning. It is possible we have even reached the very earliest moments of the third phase, especially with organizations like Snorkel, in coming up with a systematic way to apply our principles at scale.
Note: The tips for data-centric AI I highlight below are perhaps a little more applicable to unstructured data—images, audio, and things that humans generally can label, as opposed to structured data.
Top five tips for data-centric AI development
1. Make the labels y consistent
It is much easier for a learning algorithm to learn if there is some deterministic (non-random) function that maps from input x to output y, and if the labels are consistent with this function.
For my purposes here, I will use a simple running example from my own work on AI visual defect inspection in the manufacturing of pharmaceuticals. One major problem we routinely encounter is that human labelers often disagree on how or even whether something can be categorized as a defect, and this produces inconsistent results. Labelers might contradict one another on whether something is a “scratch” or a “chip,” for instance. Further, they might categorize a very minor defect and a major defect as the same thing. What we found was that by simply systematizing the defects according to “scratch length,” and then relabeling the images, it resulted in a much more consistent data plot.
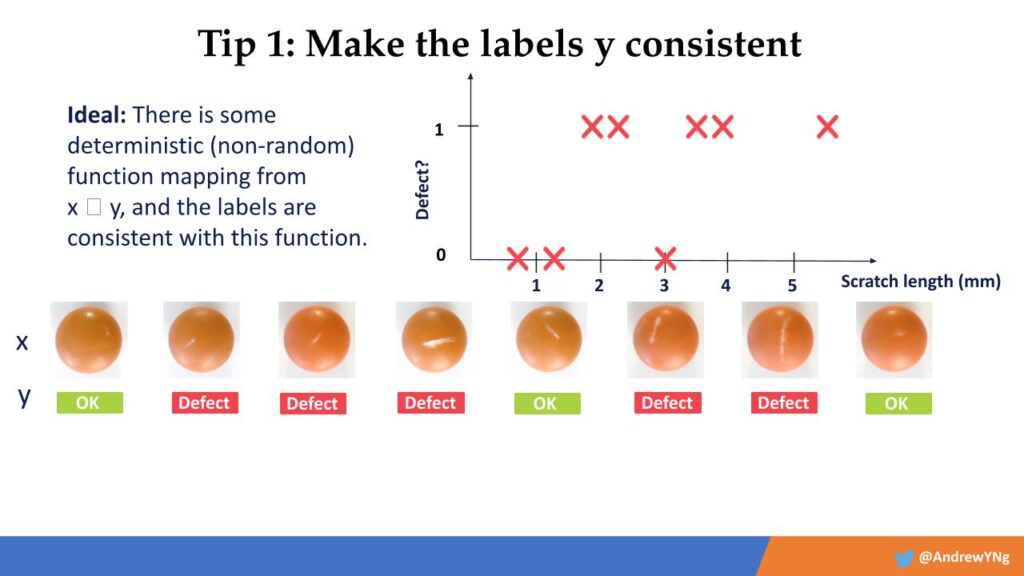
versus
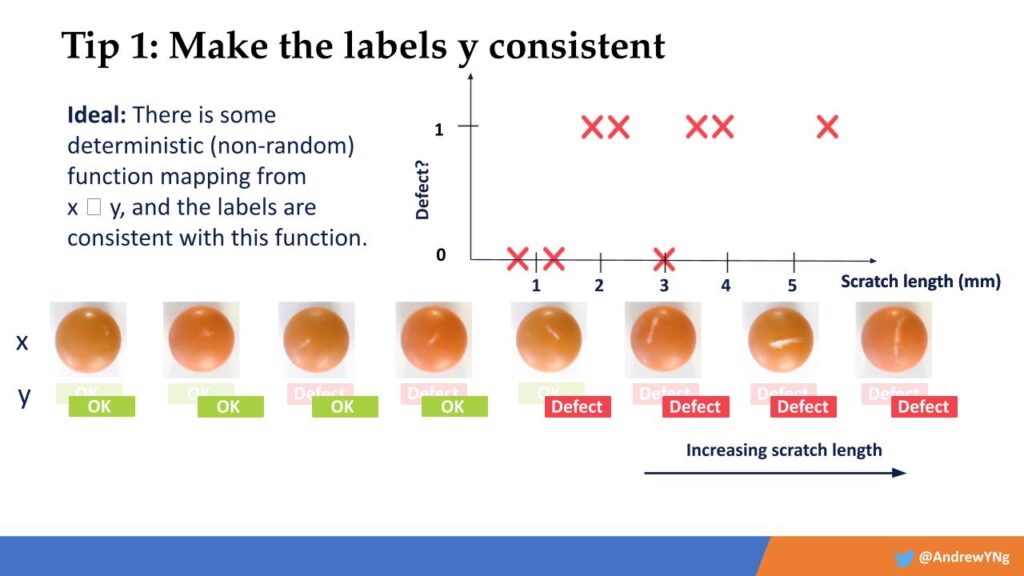
If you are able to make the data more consistent like this, it turns out that your learning algorithm has a much easier time making accurate predictions.
2. Use consensus labeling to spot inconsistencies
Labelers can be inconsistent in their label decisions in a lot of ways. But if you use multiple labelers on the same tasks, it will identify many of those data points that are creating your inconsistent results. Examples include, in this case, the label names, the bounding box size, the number of bounding boxes, and so forth. Working to get all these variables consistent across labelers can save a lot of time down the road and greatly improve results.
Here, labeler 1 has labeled a defect as a “chip,” while labeler 2 labeled the same defect as a “scratch.”
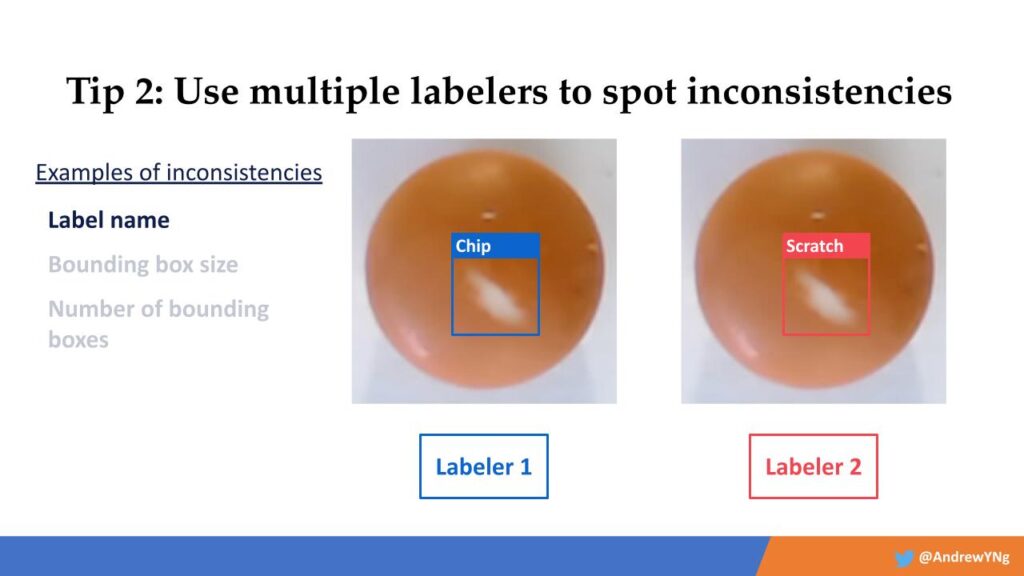
Bounding box size also matters for consistency:
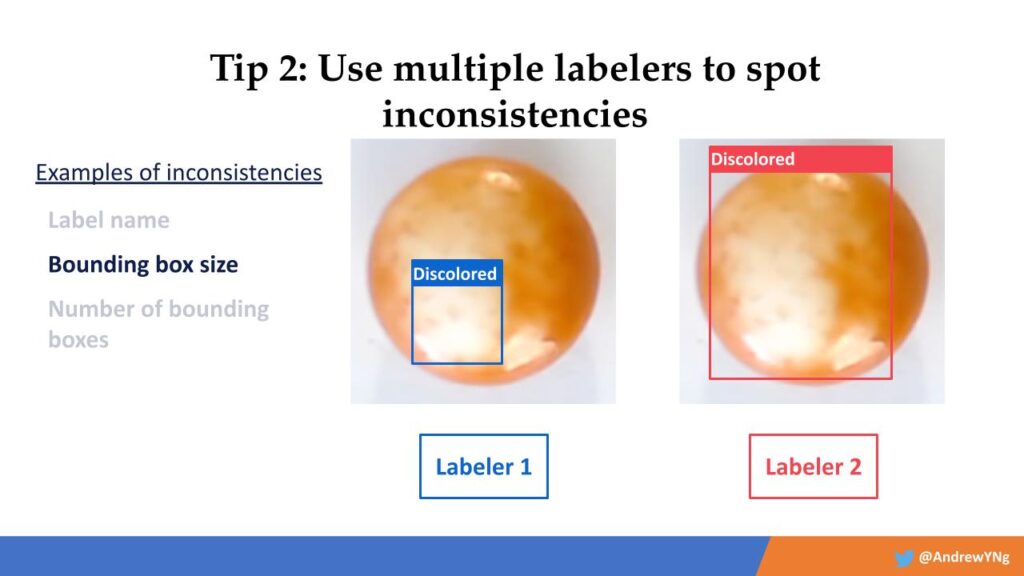
Then, how many bounding boxes do your labelers use? Here two different labelers have marked defects in an inconsistent way.
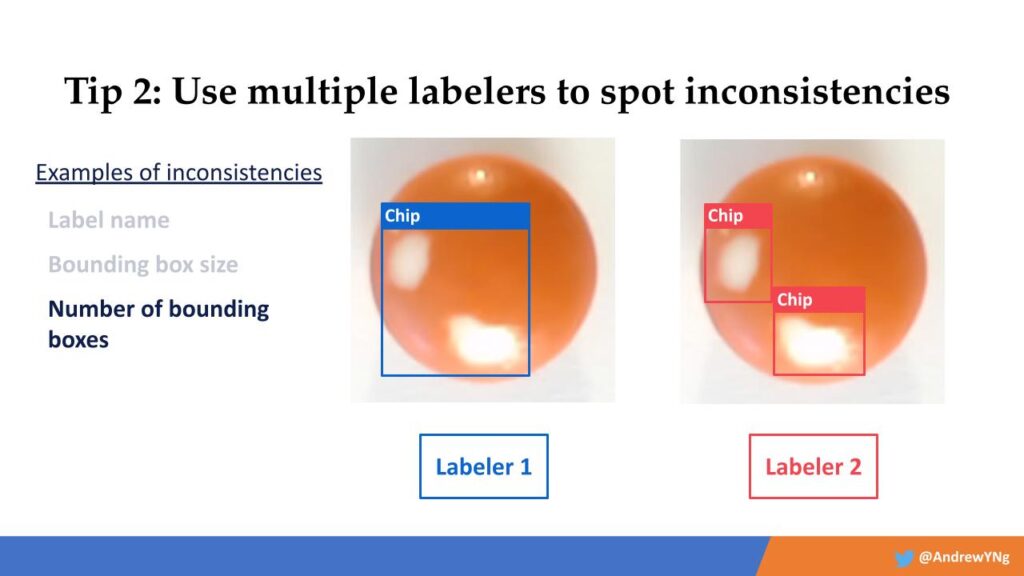
By using more than one labeler for particular labeling tasks, you can begin to triangulate where many inconsistencies in your data are coming from.
3. Repeatedly clarify labeling instructions by tracking down ambiguous labels
And I do mean repeatedly, throughout all iterations of your data. Over and over again, work to find examples where a label is ambiguous or inconsistent. Then make a decision on how it should be labeled—the old rule applies here: almost any decision is better than no decision.
Then, document that decision in your labeling instructions to create a source of truth. In general, labeling instructions should have illustrations of a concept. For example, for this case, we should show some examples of “scratched pills”; examples of borderline cases and near misses; and any other confusing examples. Once this document is created, keep emphasizing its contents, over and over. We have found it produces significant improvements in label quality.
4. Toss out noisy/bad examples
It is important to remember that more data is not always better. If there are scattered examples that are consistently throwing results for a loop, it can produce better results to simply toss them out. Sometimes machine-learning teams feel it is almost sacrilege to throw out data points from a set. But if it is done appropriately, it usually improves model performance.For example, in this slide, you can see six examples. But, the camera was poorly focused in a handful of them, which can lead to bad labels and bad predictions. It is often best to simply get rid of this noisy unreliable data if they constitute a relatively small percentage of your dataset

5: Use error analysis to focus on a subset of your data, rather than the aggregate
Within a given dataset, there are many different slices of that data on which you can work. I have found that trying to improve the data in a broad generic sense is simply too vague to be effective. If you can identify which slices of your data are giving your model the most trouble, you can isolate those slices and use data augmentation, label clean-up, and other techniques to create improvement.
My typical workflow is to use error analysis repeatedly to decide which parts of my learning algorithm’s performance are unacceptable, and which parts I want to improve. So, for example, if I decide that model performance is not good enough on “scratches,” I can isolate the subset of scratches and try to improve label consistency on this single issue, rather than trying to “improve the data” as a whole. By doing this, you affect significant improvements in model performance without having to address your entire dataset at once.
Summary
One of the common misconceptions about data-centric AI is that it is really about data pre-processing, but I don’t like that framing. The iterative workflow of developing a machine-learning system should really involve entering the data over and over again as a continuous part of the development process. Improving data is not strictly a pre-processing step but more of a core process of the iterative cycle. We should treat it as such. Engineering your data is one of the most powerful tools you can use to fix whatever problems your error analyses have revealed. Once you improve some data, you then go right back to training the model and again using error analysis, creating an ongoing “loop.” And data improvement tactics should be central to all the parts of machine learning—from training to deployment and right through to monitoring and model maintenance. This “closes the loop” of your iterative cycle.
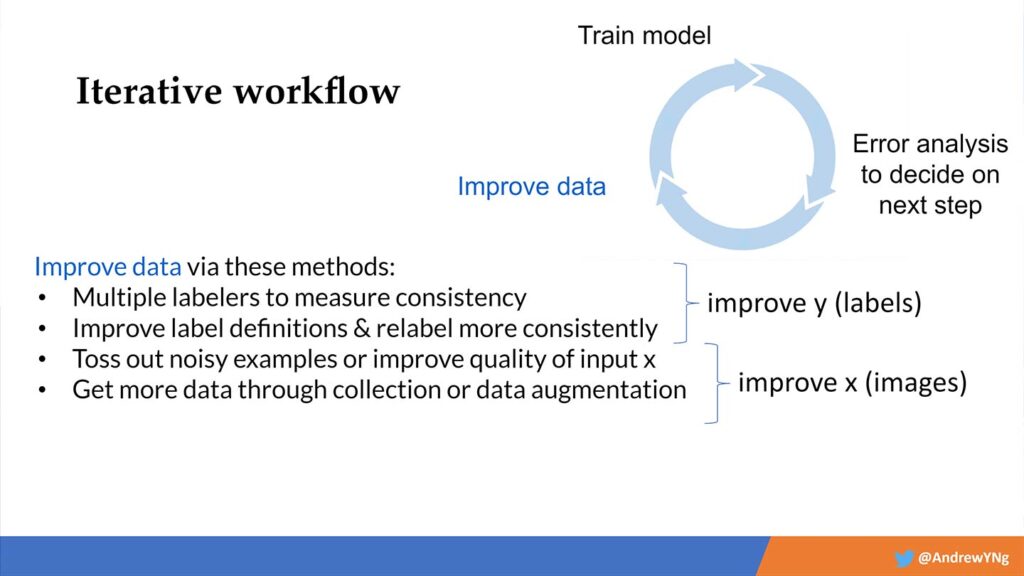
So, how do you “improve” your data?
To improve your y labels, you can use multiple labelers to measure the consistency of your labels. You can also improve label definitions and then relabel your data with more consistent labels. These tactics are slightly more applicable to unstructured data.
You can also improve your input x. For example, in our sample case above, you could refocus the camera you are using to identify scratches. You should also toss out noisy examples from your set. If you find that your algorithm is doing poorly on one slice of your data, then get more data through additional collection or data augmentation techniques
.In almost all situations, improving the data should not be a “processing” step that you do once. It needs to be part of the entire process of iterative model development, as well as all the steps of machine learning beyond.
The most important shift in machine-learning technology over the last decade has been the successful development of deep-learning models; The most important shift of the current decade, though, will be toward an approach that prioritizes the data. But in order to properly prioritize the data, you have to engineer it effectively. These tips will put you on the path toward accomplishing that:
- Make your labels y consistent
- Use multiple labelers to spot inconsistencies
- Clarify labeling instructions by tracking down ambiguous examples
- Toss out noisy examples
- Use error analysis to focus on subsets of your data for improvement
Q & A
At the end of his presentation, Andrew took a few questions on the tips for data-centric AI from the audience. They are paraphrased below, along with his responses.
Q: “If we toss out noisy examples from the training set, how will the model learn to handle such examples in the “real world”?”A: There are always exceptions and nothing is an absolute, of course. It is a judgement call. If you expect to see a lot of those kinds of examples in real-world deployment, then perhaps you do need to keep them in the training set. The tip I proposed here is primarily for whenever you have slightly “weird” or atypical examples—say 3 out of 50 or something like that. If there are only a few, you are still better off tossing it out. If you are a large company, with millions of users, it could be a different case. But for the majority of AI teams and companies, they normally have many fewer users and many fewer such examples. In those situations, it is very often the quality of your data that determines whether you can get your application to work.Q: “Most data teams are afraid of going back and touching massive datasets after they have been built. Will a data-centric AI approach allow data teams to iterate on vast datasets?A: Similar to the first question, so much depends on the nature of your data. When you have a very large dataset, you perhaps do not want a data scientist laboriously re-labeling ten million examples manually. For situations like that, you will need to rely on more automation to identify problems, or else you need to set up processes to have annotators to gather or relay for a large set of data.Q: How can we practice Data-centric AI application when we don’t have access to all the data annotators or the data-generating infrastructure (like focusing the camera)?A: That can be a tough situation, and it can kind of just be an “it is what it is” scenario. I can recall one story of a team, in a manufacturing context, that was using a camera to inspect parts. And the camera was slipping during data collection. It kept creating data drift and each time they tried to address the problem, the camera slipped again. Eventually, someone just said “why don’t we stop training the model and tighten the screw on the camera stand?” They were lucky to be in a situation where they had access to that infrastructure. Sometimes data augmentation can allow you to change the x input even if you don’t have that access. But sometimes you can only do so much, when dealing with images off the internet or some other similar scenario.Q: What is the tradeoff between cleaning labels versus gathering more data and modeling, assuming we have a good held out data set?A: Once again, it depends a lot on the application. I have usually found that for smaller datasets, modern neural networks are basically a low-bias, but potentially high-variance machine. If you have, for instance, 10,000 examples or fewer, for a computer vision problem, a modern neural network of reasonable size is pretty low bias. So I tend to spend less and less time messing with the model, because it is increasingly a solved problem. This is less true of really massive datasets, however. Q: Do you have any specific tips for structured data? Recent surveys suggest that structured data remains the main data modality in the field, so how would your tips apply here?A: It is true that a majority of the world’s enterprise data is structured, but it is actually much more heterogeneous. With unstructured data, a .png file is a .png file is a .png file. So, actually unstructured data is more universal. In general, it is harder to rely on human labelers with structured data (again, depending on the application). With structured data, it is usually more difficult to synthesize new examples, so when I work on structured data problems I end up more often entering features than creating brand new examples. I focus my time on augmentation or error analysis. Data-centric AI allows you to engineer one slice of the data at a time, which is why if you find that your system is biased against one demographic, it is actually a very powerful tool to use for responsible AI. How else can you engineer the performance of one subset of the data? This applies to structured as well as unstructured data.
If you’d like to watch Andrew’s full presentation you can find it on the Snorkel AI Youtube channel. If you’re interested in learning more you can read Andrew’s tips for a data-centric AI approach, on the Landing AI blog. We encourage you to subscribe to receive updates or follow us on Twitter, Linkedin, Facebook, or Instagram.

Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

