Foundation models such as large language models have captured the public’s imagination with their surprising abilities and enormous potential. Foundation model-backed applications like ChaptGPT can write poems, carry on conversations, and help supercharge previously difficult tasks such as summarization, translation, and data labeling.
But that power comes at a cost. Researchers have built most foundation models on top of the popular transformers architecture. This neural architecture, originally introduced in the context of machine translation [1], relies on the computationally-expensive attention operation. Perhaps the most important research on foundation models today is on how to either reduce the cost of computation in attention blocks or to sidestep the issue by building new architectures (not reliant on attention) altogether.
Snorkel and affiliated academic labs at Stanford, Brown, and the University of Wisconsin, have been hard at work addressing this challenge. Below, we highlight some Snorkel-affiliated work from Snorkeler Prof. Chris Ré’s HazyResearch group.
Training transformers-based models faster
The major challenge in training transformers-based models is attention. Attention scales quadratically with the length of the input, and so is especially challenging for long sequences.
While researchers have proposed many approaches for reducing the cost of attention (sparsity, and low-rank approximations, for example), these have not consistently produced wall-clock improvements.
We argue that the reason for this is that such approaches ignore GPU memory reads and writes. This is a critical factor, since modern GPUs have a small amount of very fast memory and a much larger amount of less-fast memory (Figure 1). An effective approach to implementing attention must take this organization into account. This requires fine-grained memory control.
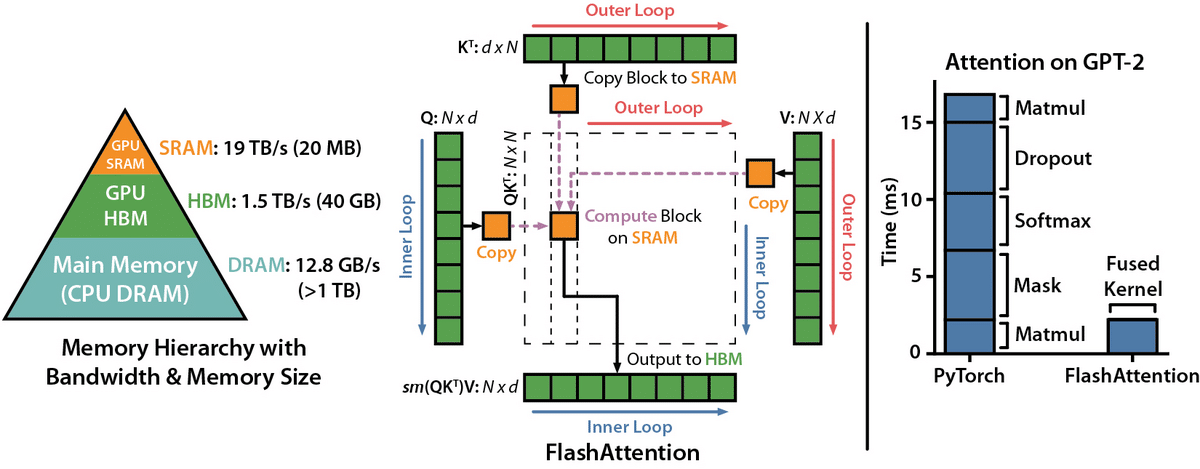
Figure 1 [2]: FlashAttention. Left: GPU high-bandwidth memory (HBM) is slow, so that materializing attention matrices on it is costly. Center: FlashAttention minimizes HBM usage. Right: Substantial speedup from FlashAttention usage over standard PyTorch implementation.
We proposed FlashAttention [2], a new approach to attention that is exact (i.e., not an approximation) and requires fewer memory accesses. The key idea is to avoid materializing the entire attention matrix in slow high-bandwidth memory (HBM) memory. FlashAttention does this by restructuring attention with tiling and by recomputing attention in the backwards pass instead of storing and reading. These simple principles led us to build a CUDA implementation that produces substantial improvements in wall-clock speed and memory consumption. For example (Figure 1), on GPT-2, FlashAttention is more than 7 times faster than the standard PyTorch version.
FlashAttention has already been adopted by many organizations that train foundation models. It has been incorporated into the core PyTorch library and the Huggingface transformers library, and in products from Microsoft, Nvidia, and beyond.
For more on FlashAttention, check out our blog post and paper, or try the code for yourself here!
New architectures: state-space models
While transformers have been excellent at handling sequence tasks where the length is small or medium, their reliance on the attention mechanism means long sequences are hard to handle. FlashAttention helps, but longer and longer sequences still present a struggle.
This is a big blocker, as many types of data consist of such sequences, e.g., audio, speech, health data, video, measurement systems, and other types of time series. Ideally, we would like to have an architecture that can handle information across long distances, deals well with the continuous nature of time series, and leads to efficient models—both in terms of training and inference.
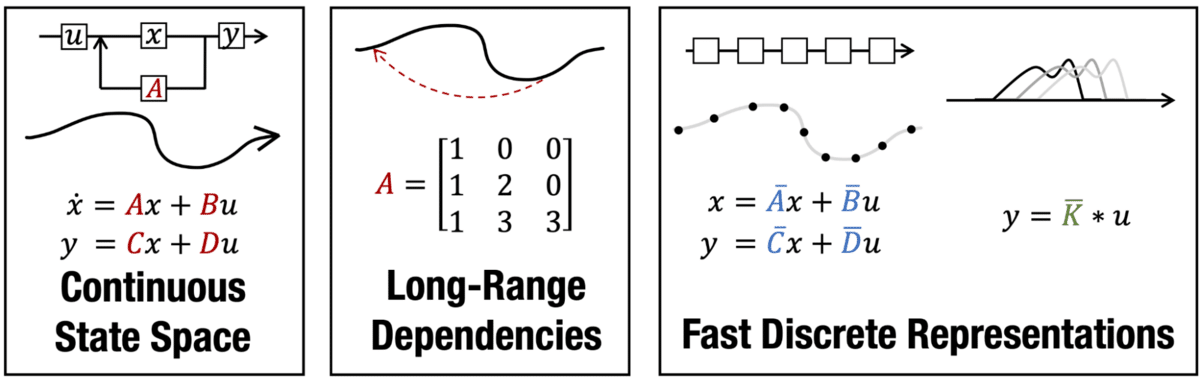
Figure 2 [3]: S4 models build on a simple state space model (left) that is continuous-time and excellent on handling long-range dependencies. A key ability is to obtain computationally efficient discretization.
To meet these needs, we developed a new architecture, leading to a powerful new class of state space models. Structured State Space Sequence Models (S4) [3] build on a workhorse tool that every electrical engineer is used to: the linear time-invariant system. The basic idea is simple continuous state space models (SSMs) are defined by two equations—one capturing the change over time to a hidden state x(t) and one capturing the relationship between the hidden state, an input u(t) and an output y(t) (Figure 2).
The two equations are parametrized by learnable weight matrices. Since we work with discrete data, the SSM is then discretized with the bilinear method. Finally—with a bit more magic—the weight matrices can be parametrized to have a specific structure that enables both very high performance and excellent efficiency. A more detailed exploration of the motivating ideas and connections to existing areas can be found in our S4 blog posts and Sasha Rush’s Annotated S4 post.
The S4 model led to state-of-the-art performance—often by significant margins—on a large number of tasks, including all of the tasks in the Long Range Arena (LRA) benchmark. It was the first model to handle the Path-X task (with sequences of length 16384). Even more excitingly, we’ve been able to extend state space models to a variety of scenarios, including SaShiMi for audio generation [4]—leading to some fun samples, along with time series [5], and finally, language models, as we describe in our next section.
State space models as language models
While the initial inspiration for our work came from the time series world, state space models can also operate as language models—though they have traditionally underperformed attention-based models. In our recent work, we studied what leads to this capability gap, and used these insights to build a new model, H3 (Hungry Hungry Hippos) [6] that can close this gap.
It turns out that we can improve the performance of SSMs by crafting special structures inside the learnable weight matrices designed to memorize tokens and compare them to previous tokens. Doing so enables state space models to handle the type of associative recall required for behaviors like in-context learning exhibited by more popular large language models.
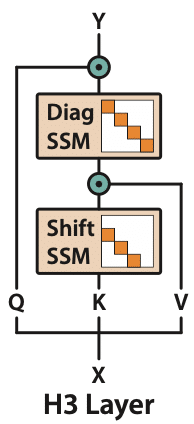
These principles led to a simple drop-in attention replacement, nearly matching transformers performance-wise (and with a tiny bit of attention—two layers—outperforming transformers). Better yet, jointly with Together, we used these ideas and some new innovations to scale up training, obtaining a 2.7 billion parameter model that is nearly 2.5x as fast at inference time compared to transformers-based models.
Larger convolutional language models
In some exciting new work, researchers are tackling ways to obtain subquadratic attention replacements. The motivating idea is simple: we’d love to be able to prompt language models with enormously long sequences: entire textbooks, or perhaps all of the text we’ve ever written! How can we take a step in this direction?
Inspired by our earlier analysis[6] on associative recall, we found that attention has several key properties that yield a quality gap when compared to potential subquadratic replacements, including data control and sublinear parameter scaling. Inspired by the need to match these properties, we introduce Hyenas, operators that compose two kinds of primitives that are subquadratic: input gating and long convolutions.
For long sequences, this starts yielding enormous speedups: 100x improvement for 100K-length sequences!
Snorkelers continue architecting the future
The work that Snorkelers have contributed to—and continue to contribute to—will push the field of foundation models forward. In these four projects, our researchers have contributed to training transformers faster, extending the memory range of large language models, and offering an entirely different architecture than those currently ascendent in the large language model space.
Keep watching this space to see what Snorkel researchers do next!
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!
Bibliography
- Vaswani et al, “Attention is all You Need”, NeurIPS 2017.
- T. Dao et al, “FLASHATTENTION: Fast and Memory-Efficient Exact Attention with IO-Awareness”, NeurIPS 2022.
- A. Gu et al, “Efficiently Modeling Long Sequences with Structured State Spaces”, ICLR 2022.
- K. Goel et al, “It’s Raw! Audio Generation with State-Space Models”, ICML 2022.
- M. Zhang et al, “Effectively Modeling Time Series with Simple Discrete State Spaces”, ICLR 2023.
- D. Fu et al, “Hungry Hungry Hippos: Towards Language Modeling with State Space Models”, ICML 2023.

Fred Sala
Chief Scientist
Frederic Sala is Chief Scientist at Snorkel AI and an assistant professor in the Computer Sciences Department at the University of Wisconsin-Madison. His research studies the fundamentals of data-driven systems and machine learning, with a focus on data-centric AI, foundation models, and automated machine learning. He and his group received the 2024 DARPA Young Faculty Award, a best student paper runner-up award at UAI ’22, the outstanding Ph.D. dissertation award from the UCLA Department of Electrical Engineering, the NSF Graduate Research Fellowship.
Recommended articles
View all articles

Agentic AI evaluation: Closing the gap with better benchmarks and data
Alex Ratner, co-founder and CEO of Snorkel AI, spoke at @Scale: Systems & Reliability about one of the most underappreciated problems in AI deployment: our ability to measure agents has been outpaced — arguably for the first time in the history of the field — by our ability to build them. The talk digs into what it actually takes to close that
June 23, 2026
•
Snorkel Team

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•
Snorkel Team

The Art and Science of Building AI Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build AI benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents with
June 16, 2026
•
Snorkel Team

