New Snorkel benchmark leaderboards. See the results.
The benefits of programmatic labeling for trustworthy AI
The following post is based on a talk discussing the benefits of programmatic labeling for trustworthy AI, which was presented as part of the Trustworthy AI: A Practical Roadmap for Government event that took place this past April, with Snorkel AI Co-founder and Head of Technology, Braden Hancock. If you would like to watch Braden’s presentation, we have included it below, or you can find the entire event on our YouTube channel. Additionally, a lightly edited transcript of the presentation can be found below.
If building trustworthy AI systems was easy, everyone would already be doing it. It offers such a clear improvement over non-transparent “black box” systems that the need for trustworthy AI is pretty obvious. One fundamental reason that most organizations are not able to make much progress creating it is because the time-consuming data-labeling process remains a primary barrier, especially with the continued predominance of manual labeling approaches.
Data labeling is a foundational building block of machine learning, but manual labeling remains so expensive and time-intensive that it remains a natural barrier to building a transparent, trustworthy AI system. We created the Snorkel Flow platform to address this data bottleneck by using programmatic labeling. We started the project over five years ago, and in what follows below, I will highlight how our work, first at Stanford and now at Snorkel AI, the company, enables practical ways to achieve trustworthy AI.
Why trustworthy AI in government?

Snorkel AI already supports customers in a variety of different industries, including ones like insurance and finance, which are highly regulated and have a lot of model risk management protocols. It is obviously a good practice to be as ethical and responsible as possible when building AI systems in general, but there are numerous explicit reasons why it is particularly important in government. For instance, executive orders from the White House and mandates from Congress in recent years have asserted that in order to foster public trust in AI, systems need to be traceable, continuously monitored, and transparent. They also need to minimize unintended bias and be auditable, so that one can trace and inspect exactly what happens, both in a final model and in the processes that led to the creation of that model. These critical aspects of AI need to be cost- and time-efficient too, as well as explainable and interpretable in order for users to assess what AI systems are doing and why.

These aspects of trustworthy AI are much more likely to be obtained by building AI systems with technology that fosters a transparent process. It is not generally something that can be achieved with manual data labeling, which remains the most significant bottleneck for AI applications today. In academia or labs, “step 1” is usually simply: “download the dataset.” In the outside world of industry or government, however, where you are solving real-world problems, often steps 1–8 are about actually creating the dataset itself—collecting, determining accuracy, analyzing data annotators, and processing multiple iterations to finally arrive at a usable set. The modeling is really the easy part at the end of all that. Whether your res-net has 132 or 145 layers, it is going to be the data that makes the biggest difference in achieving quality and interpretability.
As a result, data labeling remains a major bottleneck in terms of both time and cost, and it should come as no surprise that it is thus a key roadblock to trustworthy AI.
Five key requirements for trustworthy AI:

- The ability to govern and audit your training data and understand where it came from.
- Trustworthy AI requires that you know not just your final result but also the process that created that result. Your dataset might have a hundred thousand labels in one big set. Without an understanding of the process, it will be opaque—a kind of “soup” of data with no real structure behind it.
- The ability to explain AI decisions and errors.
- You will always discover problems and areas where your model performs poorly. There are always artifacts, surprises, clusters, and slices of data in which you see variable performance—it is never homogenous.
- Being able to explain those differences is important not just for liability reasons but also because it simply promotes better quality results to see why a model behaves in the ways it does.
- The ability to systematically correct biases.
- We do our best to keep biases out of models, but it is nonetheless nearly impossible to do so, because there are so many unintended biases that creep into any model.
- The best way to address those is having the ability to efficiently iterate. Once you detect a bias, you need to be able to smoothly and quickly address it to produce an improved iteration of your dataset.
- A tight feedback loop between your subject-matter experts (SMEs) and your data scientists.
- The people who have the most knowledge about what your labels mean must be able to have a continuous dialogue with those who are actually building models and calculating metrics.
- If SMEs and scientists remain in silos, numerous problems creep into a model or dataset, whether in the form of misunderstandings, misalignments, or a lack of efficient iterability.
- Ensure the integrity of your supply chain
- You need to know the “full bill of materials” for what went into creating a model. What does it rely on? What does it not rely on?
- In other words: how are upstream components such as third-party training data and pre-trained models affecting your final results?
- This improves trustworthiness by creating more certainty about your model and anything that might be poisoning your data or introducing biases.
Programmatic labeling offers huge benefits for trustworthy AI that just are not possible with hand labeling.
If you can bypass the manual-labeling bottleneck and make something more explicit, measurable, inspectable, and programmatic, it enables you to meet all five of these key requirements for trustworthy AI.
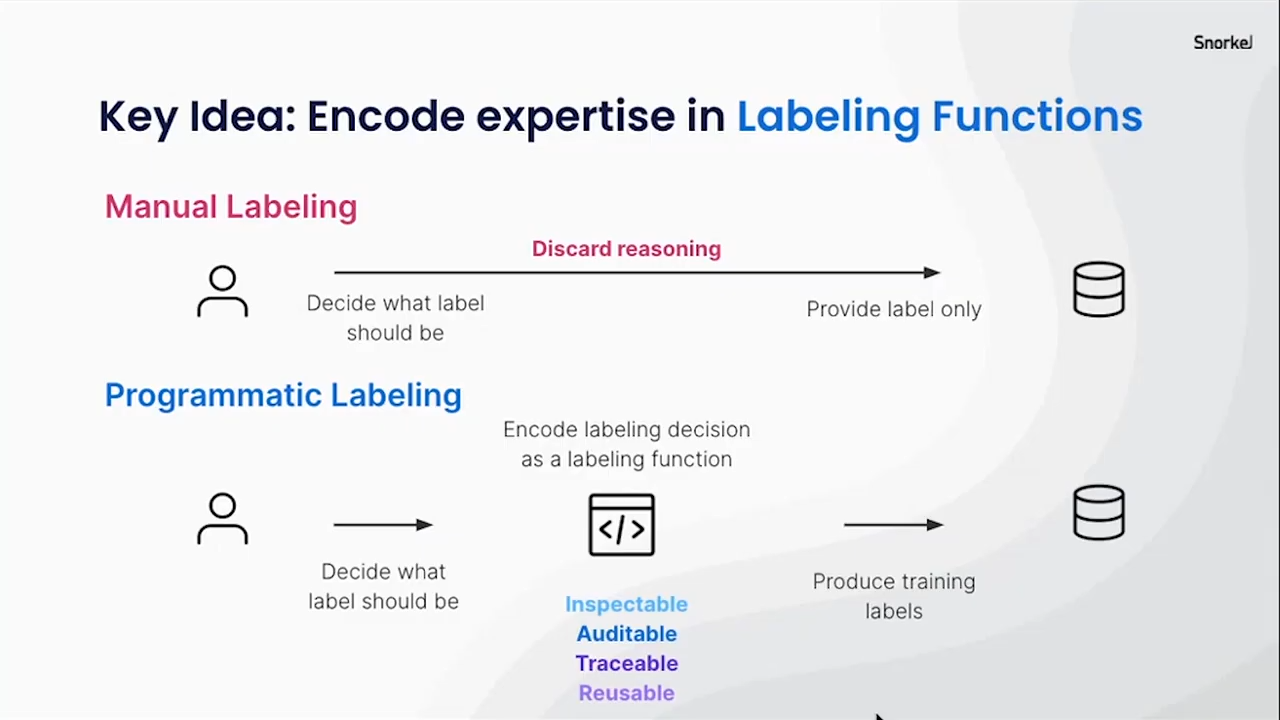
The key to programmatic labeling is labeling functions. When you manually label something, like, for example, in training a spam classifier, you can inspect individual emails, documents, and data points and figure out why you think something is “spam” or “not spam.” But you effectively toss all that nuance and reasoning out when you then simply provide the label. This is incredibly inefficient. Your labeler has richer knowledge than the simple label, but that knowledge is not effectively used in most labeling pipelines. Instead, you essentially hope your model can relearn what your SME already knew, and there is no guarantee that it will figure it out as you feed it labeled data points.
With programmatic labeling, contrastingly, you look at a data point, decide what the label should be, and then with Snorkel Flow and the way it captures labeling rationales, you can create a labeling function to employ that nuanced SME input and label all of your data programmatically. Snorkel provides a very user-friendly and accessible platform for SMEs who perhaps cannot write code and empowers them to insert their expertise into a function that can then be inspected and that makes explicit what exactly went into a given label decision. The labeling function, in other words, actually produces the training labels, but the entire process is still very much driven by the SMEs and their deep domain knowledge. The model is not teaching itself, rather, it is driven by real expertise while also producing results with the speed and processing power of a computer. That comes with a lot of benefits that I will explain below.

Before we get there, though:
What is a labeling function and where does it come from?
A labeling function can actually be many things. A simple example, if you are working on a text use-case, is a function that highlights particular phrases or headers or keywords that indicate that a data point should be a certain class. But they can be much more sophisticated than that. Essentially, anything you can express in code can be a labeling function. Sometimes that is identifying patterns or attributes of your data. Sometimes it is wrapping existing resources—if you already have manual labels, for example, they can be used. If you have existing models, those can also be used.
The important thing is that with labeling functions, your data is no longer mixed indiscriminately in a way that prevents you from removing or isolating specific parts of it. You have control over your data and the ability to identify the effect of particular portions or slices of data on your quality or your biases. It makes the dataset and the model transparent in all your downstream operations.
A running example: Lending discrimination
With lending, as with many use-cases in which you need trustworthy AI, it is explicitly illegal to rely on certain protected attributes such as race, color, religion, sex, etc., in deciding to whom to loan money. If you do so even accidentally, there are not only penalties and fees but significant reputational risk as well.
Key Requirement #1:

Looking at the first requirement of trustworthy AI outlined above, how do you govern and audit your AI or machine-learning training data to prevent this discrimination from happening?
If you are using manual labeling, you have potentially hundreds of thousands or millions of data points, and because there is no structure or transparent process behind them, if you need to inspect them, you have no choice but to do so one by one, on a case-by-case basis. This can quickly become cost, time, and resource prohibitive. If given our lending example, there are certain attributes that cannot factor in a decision—you need to be able to see if any of your labelers explicitly used or referred to them. You can perhaps perform some searches for these attributes, but you are still wading through a soup of labels.
With programmatic labeling, on the other hand, you have an intermediate artifact, your labeling functions, that can tell you in a much smaller order—maybe tens of data points instead of hundreds of thousands—where to find your explicit problems or errors. It is a far more palatable approach that allows you to be comprehensive, because you can identify exactly where you might be referencing any forbidden attributes. While this does not eliminate the potential for implicit bias, which I will cover below, any kind of inspection you want to do around the explicit labeling process can now be done in one sitting, rather than over a weeks- or months-long effort of inspecting each individual data point.
Key Requirement #2:

How do you then explain outputs and errors? With manual labeling, it is not enough to simply say, “I didn’t explicitly factor in race or gender.” It is entirely possible that a labeler’s decision was influenced, consciously or not, by anything from an address to a name—types of information that have been shown scientifically to bias decisions. This kind of implicit bias is hard to root out since it happens inside the heads of your SMEs or labelers and you cannot really know what things affected their decisions to employ particular labels. They may not even know themselves.
Programmatic labeling’s benefit is that it makes the implicit, explicit. With programmatic labeling, as your labelers come to their conclusions, they have to codify explicitly what factors they used to make their decision. In that process, they might simply recognize the implicit biases themselves and correct it. But if not, at the very least, you have the ability to go back and identify what is and is not contributing to the label for a specific example. You can also inspect what is affecting your model’s performance on specific data points based on which labeling functions might be introducing bias and therefore poisoning your training set.
Key Requirement #3:

The third crucial aspect of trustworthy AI is the ability to detect and eliminate bias. While ethical AI users work to detect and eliminate as much bias as possible from the outset, any model that is deployed long-term and that has a life cycle (which is increasingly the norm for real-world use-cases) will inevitably contain biases. You must be able to monitor your system for changes over time on distinct subsets and the overall quality of output.
With a manual-label approach, how would you detect and correct biases? Modifying individual data points is nearly futile in its potential to improve things. Even modifying multiple data points at once quickly becomes like playing whack-a-mole as you attempt to change enough data to make a difference in your overall “label soup” and the model performance. Even that can be relatively undoable, because you are re-labeling from scratch. It is painful because the economics of manual labeling are such that every label requires the same amount of human time to perform. Not only do you pay the same cost for your first label as your millionth label, you then pay that same cost a second, third, and fourth time, whenever you need to update your training set.
By contrast, with a programmatic approach, you have captured domain knowledge within functions that can now be executed on hundreds of thousands of training labels that are programmatically generated. When you need to make a change, you can change a small number of labeling functions that you have identified as contributing to downstream bias, then simply push the re-execute button and relabel your training set in a parallel way extremely quickly, often in minutes or even seconds. After doing so, you will have regenerated an updated iteration of training labels that no longer have that biased source.
We plan on using machine learning for the long haul, and for applications where you are no longer simply trying to prove a simple concept—”can AI work for us once?”—a programmatic approach allows you as an organization to invest in a system longterm, recognizing that you need to factor in not just the first model training but all the subsequent ones as well. Programmatic labeling makes that process scalable yet transparent enough to detect and address biases in your system.
Key Requirement #4:

We have heard from companies and organizations with which we have collaborated, time and time again, that they can never get enough time with their SMEs. Often the only interface that they can use is to ask for more labels or for clarifying examples. Because the manual labeling process is very slow and because SME time is spare and expensive, this creates very sporadic, loose feedback cycles. This in turn reduces the number of times that teams can iterate, because you have an interface that is just not suitable for efficient feedback.
With programmatic labeling, you can utilize an endless cycle of improvement, where your SMEs have captured their knowledge in functions. Now, a data scientist can answer a lot of their own questions by inspecting what was captured. Moreover, when they have ideas for new uses for the dataset or deeper questions for clarification, there is a far more efficient interface: a new labeling function or an updated comment on an existent labeling function, rather than an unstructured soup of labels. It becomes, by orders of magnitude, a much faster operation.
Key Requirement #5:

Because manual labeling is so painful in terms of cost and time, we have had partners ask us: isn’t there some pre-trained model that we could use that is “good enough.” Often there is an element of “settling” here. Pre-trained models do have some exciting cherry-picked demos out there. But typically, when you then apply them to your specific problem, the model simply cannot encapsulate your unique particulars to give you good results. Anything trained with general-purpose knowledge can never fully grasp the nuances of your particular problem, your specific class definitions, or your domain expertise.
Not only are there these performance drawbacks with pre-trained models, but you do not really know what training data went into the model or what process was used to create it. Odds are that it was a manual process, where, again, you have the inevitable issue of being in the dark about what implicit biases might be affecting your outputs.
With programmatic labeling, you get “supply chain” integrity and a full “bill of materials” that allow you to know every source of supervision that went into your model. You can inspect it and identify it. You can still use pre-trained models. They are not useless, but with them, you cannot control or identify what is being used or contributing to unwanted effects within your model. With programmatic labeling, you can find them and remove them, or, if you figure out some particular data points are not actually the source of a problem, you can always factor them back into your set.

In summary, manual labeling, which is the approach we have all used for decades to feed these increasingly sophisticated models, simply is not up to the task anymore. As AI becomes operationalized at scale and moves out of the lab into the real world, trustworthiness is a much higher priority than ever before. Programmatic labeling provides a path to ethical, trustworthy AI that is highly scalable and iterative, allowing an organization to deploy practical AI solutions in a responsible and effective way.

If you would like to see some of this information in a little more technical detail, we do have public demos periodically for which you can register and see us walk through a simple task to get a better sense of how Snorkel Flow works. For that and for any other questions, feel free to follow up with our federal team at federal@snorkel.ai.
Bio: Braden Hancock is a Co-Founder and Head of Technology at Snorkel AI. Before Snorkel, he researched and developed new interfaces to machine-learning systems in academia at Stanford University, Massachusetts Institute of Technology, Johns Hopkins University, and Brigham Young University, as well as in industry at Facebook and Google.
Q & A
There follows a brief question and answer session.
Can my subject matter experts still write labeling functions even if they can’t code?
Absolutely, yes. Snorkel Flow really provides you with source code and labeling functions that shouldn’t really scare SMEs. We have seen this approach used very effectively by SMEs because you can put all sorts of high-level interfaces on top of labeling functions. You can say, for example, if you are writing keyword-based labeling functions, “just highlight the keyword; or, just give me that list of keywords; or just point to the document where it is relevant,” and you can compile that input down into a function that handles the boilerplate code and returns the right label. Snorkel FLow provides dozens and dozens of different templates, based on observed usage, of ways that experts want to express their labeling decisions. You can actually see some of those in our demos and some screenshots on our website showing a veritable zoo of labeling function templates. Anything from those very simple keyword-based things to embedding-based approaches or wrapping models.
If I can label my data points programmatically, then why do I need a classifier?
That is a very good and very common question, and we are glad when people ask it because it shows they are engaging and thinking this through. A training label you have created looks a lot like a prediction, and it is fair to wonder, “am I basically just building a rule-based system?” Are expert systems just coming back?
With programmatic labeling you really get the best of both worlds, wherein your inputs are these rules—which we have noted have a lot of benefits like inspectability and reproducibility, the ability to re-execute, etc.—but your labeling functions typically are not full classifiers. The fact that you can weakly label a portion of your dataset is often a reflection of the fact that it is focusing on some very specific subset of your data, rather than having the full nuance of the full decision space. So you get these labeling functions and have them label portions of your dataset, and sometimes they will agree and sometimes they will disagree. When you know the model, you can learn confidence-weighted training labels for some portion of your data. Because rarely can you actually enumerate rules to cover 100 percent of your data. And then this training set becomes something you can use to train a model and that can generalize beyond your rules.
So, in this situation a machine-learning model can take advantage of a much richer feature set: distributed and learned representations; word embeddings; transfer learning; all kinds of things. The reason machine learning is doing so well on so many tasks today is because it does have an incredible amount of power to draw on, but it still needs those training labels. There is much more here that I do not have time to go deeply into, but essentially you use your rules to create the training set using a relatively small number of features that you can use to directionally guide those training labels. But then your model can take advantage of a much richer variety of features. It can learn not just those specific things that you have enumerated in your rules, but rather all the trends that are present in your training set.
Interested to learn more about Snorkel Flow? Sign up for a demo and follow Snorkel AI on Linkedin, Twitter, and Youtube.
Featured photo by Tara Winstead.

Team Snorkel