New Snorkel leaderboard. See the results.
Speech AI Demystified | FDCAI Lightning Talk
Sirisha Rella is the Technical Product Marketing Manager at Nvidia. She recently gave a Lightning Talk presentation on “demystifying” speech AI at Snorkel AI’s Future of Data-Centric AI virtual conference. A transcript of her presentation appears below, lightly edited for reading clarity.
I’ll directly jump to our topic: speech AI. Let me share my screen and we can get started.

So, as you all know, voice is the common interface that we use to communicate, and that’s the reason why, every day, hundreds of billions of minutes of speech is generated. And speech AI can help digitize these conversations. Let it be you talking to a digital human in Metaverse worlds, or talking to a real human in a call center, or even talking to your colleagues in an online meeting.
When I say speech AI, it basically includes two technologies: automatic speech recognition (ASR) and text-to-speech (TTS). The interesting fact here is that these are not new technologies and they have existed for the last 50 years. So, let’s take a look at how it all started, where we are today, and what the future is going to look like.

Coming to the evolution of automatic speech recognition, the first system was introduced in 1952 by Bell Labs, which was called Audrey System. This system had the capability to transcribe only digits, which meant the vocabulary size was only 10 [words]. What that means is that “vocabulary size” is basically the number of words that a system can understand.
The next on the timeline was IBM Shoebox. This system had the capability to transcribe words. However, it did it in an isolated fashion, which is very unnatural because, as humans, we don’t pause after each word in general conversations.
In 1976, Carnegie Mellon University introduced Harpy, a system that was able to handle continuous speech, and the vocabulary size increased to 2,000 words. However, in our dictionaries, we have hundreds of thousands of words, and comparatively, this is still a small vocabulary system.
In 2000, statistical algorithms came into existence, and these had the ability to handle tens of thousands of words. However, the problem with statistical algorithms was that, firstly, accuracy had reached a stable stage. Even if companies wanted to further enhance their accuracy, they weren’t able to do it. And secondly, the statistical algorithms pipeline is complex, and one of the reasons is because of force alignment data.
In layman’s terms, force alignment data is: given a text transcript of an audio segment, you need to determine in what particular time a word occurs in that audio segment. So, you need to have that tight force alignment data to develop these statistical algorithm pipelines.
And, in 2014, deep learning came into play addressing some of these challenges, and it revolutionized the way ASR is done. Firstly, the quality is enough that companies were able to deploy deep-learning ASR in production. However, there are a couple of areas of deep learning that ASR developers are trying to enhance the pipelines for.
Firstly: industry-specific jargon.
Let’s imagine an ASR deployed in the healthcare industry. The pipeline needs to be able to transcribe sentences like, maybe: “chest x-ray states that left retro cardiac opacity, and this may be due to athletics, aspiration, or early pneumonia.” Understand there is so much healthcare-related jargon here, and so depending on whichever industry it is—let it be healthcare, telecommunications, or finance—the liaison needs to transcribe them accurately.
Coming to multilingual dialects and accents, if companies want to play big and expand their solutions globally, these pipelines need to understand multiple languages, dialects, and accents.
Then, coming to “noisy environments.”
In today’s world, most of the people who are interacting with these applications have noisy environments. For example, just imagine a person who is calling a call center. I don’t think this is going to be a quiet place, as if he’s looking for a place to meditate. And, how many of you have background noisy environments while you are talking in online meetings, or sitting at your home? So these ASR pipelines need to be noised up first.
Coming to contextualizing words.
So, there are homophones, right? Homophones are basically words which sound the same, but their meanings are different. For example, “peak of the mountain,” versus “let’s peek at something.” So the “peak” in both of these sentences sounds the same, however, the meaning is completely different. So, the ASR pipelines need to transcribe these words accurately, depending on the context.
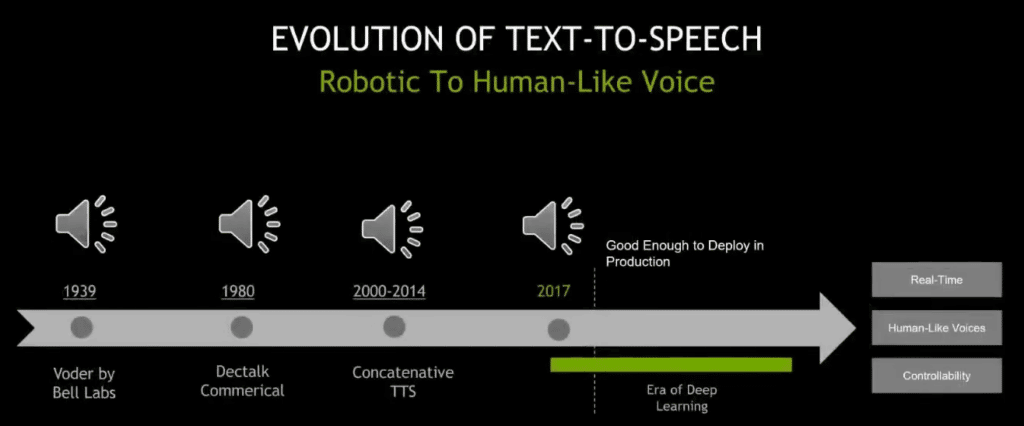
Moving on to the evolution of text-to-speech (TTS). It has a similar story as ASR and it has existed for the last several years. So the way TTS is measured is based on how human-like the generated synthetic voice is. I’m going to play the first text-to-speech system and then [I will play] deep-learning-based text-to-speech, and you can see for yourself how deep-learning-based text-to-speech sounds more lifelike.
[Rella plays audio clip]: [garbled]
So, it’s basically saying—I know it’s difficult to understand—but it’s basically saying, “she saw me.” Then, this is deep-learning-based text-to-speech.
[Second audio clip]: “You’ll be receiving a text message on your phone confirming the details of your order.”
So, if you can observe the deep-learning-based voice, it has that human aspect to it, right? It has the pitch, speed, and intonation—when to raise the pitch and when not to.
And also coming to deep learning, TTS developers are also working on and improving a couple of areas, such as real-time and human-like voices and controllability.
So, coming to real-time and human-like voices. Basically, the TTS pipeline has key deep-learning models, in addition to non-deep-learning components. To generate a human-like voice, all of these need to work together in real-time, in under a very few milliseconds because you can’t ask a question of an application and then wait for several seconds to hear a response.
Coming to controllability. Of course, the pipeline should be flexible enough to control the paralinguistic elements—which are, again, pitch, duration, and intonation—so that we can make it more expressive depending on our use case.
What really is fascinating to me is that some of the companies have already made a significant stride in deploying speech AI in production. So, I’m going to talk about three such compelling use cases.

The first one is T-Mobile. Their use case is Expert Assist. They’re using ASR to transcribe the conversations between customer and agent, and analyze those conversations to provide real-time recommendations to agents. And, of course, what they did is they also fine-tuned the model’s 10 pipelines on a regular cadence to make sure that the pipelines understand their domain and industry-specific jargon, like whenever customers are calling their call centers.
Coming to Tarteel AI, they have an application that helps users to recite the holy book Quran. They’re using Arabic ASR to identify the errors that users make. So, of course, they did not build the model from scratch. Instead, they took a highly accurate model and fine-tuned it on an Arabic dataset to make it work for Arabic.
Data Monster has a similar story and focuses on a children’s reading tutor application.

So, if you want to learn more about speech AI, we provide starter kits for both speech recognition and text-to-speech. And if you want to receive the latest news about Nvidia speech AI, you can scan the QR code on my screen and then sign up for the newsletters.
Yeah, that’s all I got, and thank you for having me here.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Team Snorkel