
The Future of Data-Centric AI Talk Series
Background
Snorkel co-founder Chris Ré is an associate professor of Computer Science at Stanford University and an award-winning researcher in data-based theory and machine learning. He has co-founded four companies based on his research in machine learning systems. Chris recently presented at the Future of Data-Centric AI virtual event in September, where he discussed his team’s winding journey to data-centric AI and Snorkel AI’s evolution from a project in the Stanford AI Lab to a company leading the shift to data-centric AI at major enterprises.This presentation is summarized below. If you would like to watch Chris’ presentation, we’ve included it here as well, and you can find the entire event on our YouTube channel.
Traditionally within the field of AI and machine learning technology, much of the research and industry effort has centered around a model-centric approach to building systems. By using the model itself as the focus of iterative development, AI teams have made a ton of exciting progress up to now, and model-centric AI has really matured as a result. Models today are increasingly standardized, push-button-ready, and data-hungry. For really the last five years, we have truly been in a new age of deep learning models. But for those of us at Snorkel, this pushed us to ask: what happens next, and how do we progress from here?In 2017–2018, we observed that most AI teams had developed what we jokingly referred to as “new-model-itis.” People focused a ton of energy on constantly writing new models, but they often failed to fully encode their problem into their AI system because of their relative neglect of the data. Yet, a few teams at that time were starting to shift more of their focus toward a data-centric approach, and they began to generate a lot of success in doing so. In contrast to the model-centric approach, we saw that those teams who examined the encoding of the problem more deeply—who scrutinized, measured, and audited data as their primary focus—were building better, more efficient AI applications.
In many modern AI applications, data is the primary encoding of domain knowledge, and data is growing increasingly prominent inside AI.
In many modern AI applications, data is the primary encoding of domain knowledge, and data is growing increasingly prominent inside AI. The issue, though, is that data has mostly been a static asset—something to be collected as a discrete set before the model development takes place. And labeling data by hand is such a costly process that teams often view any revisiting or revising of their training data as infeasible. We began Snorkel as a project in the Stanford AI Lab with the goal of building a data-centric AI framework that could be applied to a broader set of problems than were practical for model-centric approaches with static datasets. In other words, Snorkel sought to free data science teams from being locked into their training data by creating a way to make data labeling programmatic at scale. Excitingly, it did not take long to see the practical applications of this shift show up all around us. By 2018, Snorkel derivatives were already in production at companies like Google, Apple, Intel, and many more. These companies took some of the data-centric ideas from our research and implemented them for Gmail, YouTube, and Google Ads, to name a few. And this glimpse of the exciting possibilities inherent in a data-centric approach drove us to look even deeper into the ways it could be implemented at a larger scale and for broader applications.From 2018 to 2020, we witnessed several new data-centric AI startups get well off the ground. SambaNova, for example, sees the future of AI in dataflow, which changes how you build systems in fundamental ways. Inductiv, recently acquired by Apple, uses AI to clean data and prepare it before deploying it for applications. Snorkel AI has created a platform that can manage the data and the knowledge to build AI applications.So, if data-centric AI is the best method for building the foundations of long-lived AI systems, what is it exactly, and how is Snorkel AI approaching it?
Data-Centric AI Application Development
An AI application requires three fundamental, interconnected parts: a model, a data set, and hardware. Model and computing hardware and infrastructure have made tremendous progress in recent years. And model-centric AI is great for many discrete applications. Now, in fact, models are often packaged and downloadable commodities, ready for use by anyone. Hardware’s progress has been on a similar trajectory, driven by cloud infrastructure and specialized accelerators. But training data has not reached this level of practical utility. And that’s because it cannot really be a broadly useful commodity. Training data is specific to your project within your organization. It encodes your specific problem, and so it isn’t traditionally relevant outside your context. Because of that specificity, model-centric AI has so far not been very dynamic or expandable. State-of-the-art hardware and models are readily available. Training data is not.
It’s hard to make training data a downloadable commodity because, unlike in the artificial environment of a classroom or research lab where data comes in a static ready-to-use set, in the real world, it emerges from an extremely messy and noisy process, and it is customized to your specific application.
It’s hard to make training data a downloadable commodity because, unlike in the artificial environment of a classroom or research lab where data comes in a static ready-to-use set, in the real world, it emerges from an extremely messy and noisy process, and it is bespoke to your specific application. While Team Snorkel is always careful to emphasize that “data-centric vs. model-centric” isn’t a binary question, we do have evidence that model differences have traditionally been overrated and that data differences are usually underrated when it comes to building better AI. Ultimately Snorkel asks: if we prioritize a focus on data, what are the foundational techniques, both mathematical and abstractions, that allow us to get better, more useful training data and get it more quickly?One real-world example of the data-centric approach came out of a 2019 collaboration Snorkel did with Stanford Medicine on using AI to classify chest x-rays. We spent a year on the project creating large datasets of clinical labels, evaluating the effect of label quality, and working to publish our results in a peer-reviewed clinical journal. What we learned using already-available models was that no matter which model we ran the data through, it only resulted in two- or three-point differences in accuracy. What mattered for our results to a much greater degree than the choice of model was the quality and quantity of the data labeling. Dramatically improving training signal and data augmentation, then, is one key to pushing the state of AI forward.
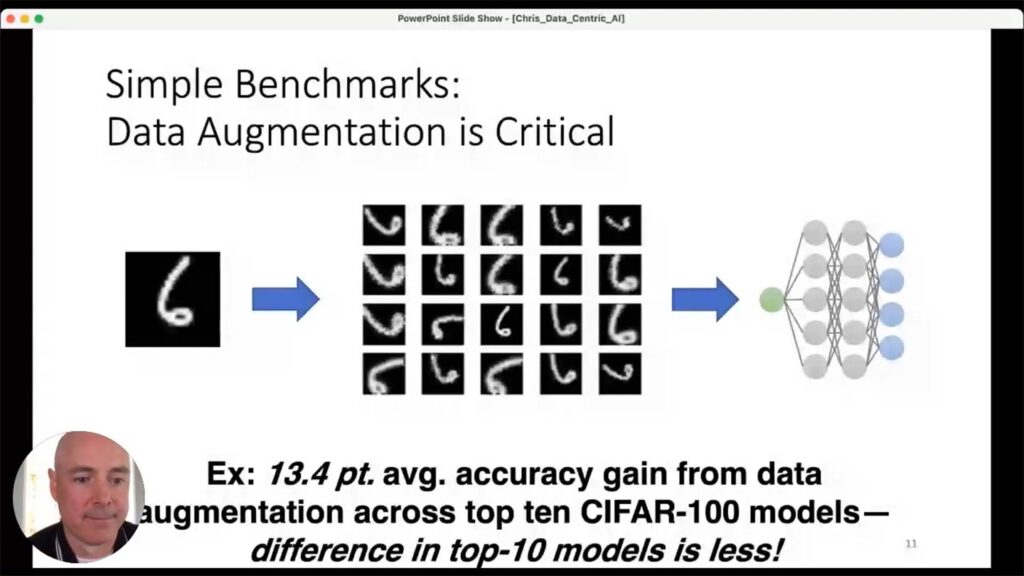

Looking across benchmark data, using the right set of data augmentations is a relatively unexplored avenue for getting greatly improved accuracy out of almost any model you might choose. Again, it’s not that a renewed focus on data is more important than modeling. Rather it’s that the potential of data augmentation for building more robust models remains relatively understudied, and it’s something Team Snorkel has been working on for a while now. Google’s AutoAugment, for instance, now uses learned-data augmentation policies that emerged from the first learned-augmentation paper, written by Snorkel co-founders Henry Ehrenberg and Alex Ratner in 2017 1. As another example, one of our former post-doctoral researchers, Sharon Y. Li (now a professor at the University of Wisconsin), helped train a model at Facebook in which she used weakly-supervised data to help build the most accurate, state-of-the-art model with the Imaginet benchmark. (Sharon wrote a series of blogs for the Stanford AI Lab that provide a snapshot of how she accomplished this 2 for those who might want to know more.)

But there’s a well-understood yet still tremendous challenge to overcome here too, which is that traditionally, manual data-labeling is expensive, tedious, and static. That is one of the foundational challenges that Snorkel wants to overcome.
The Training Data Bottleneck
Training and labeling data by hand is slow and very costly. Data’s quality and quantity often are based on how many humans—usually subject matter experts—you can throw at the process and for how long they can work. Static data sets mean you might start out with manual labels that turn out to be impractical for the model you are trying to build. To use a straightforward example, maybe you began by using “positive” and “negative” labels, but it later becomes clear you really need a “neutral” as well. Re-labeling all that data means you have to throw out all your previous work and start over.
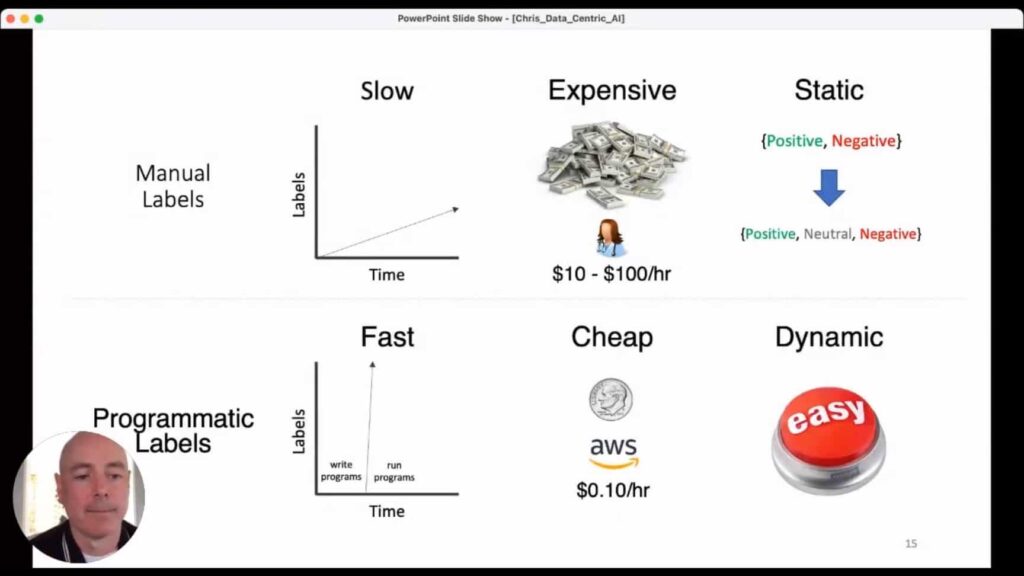
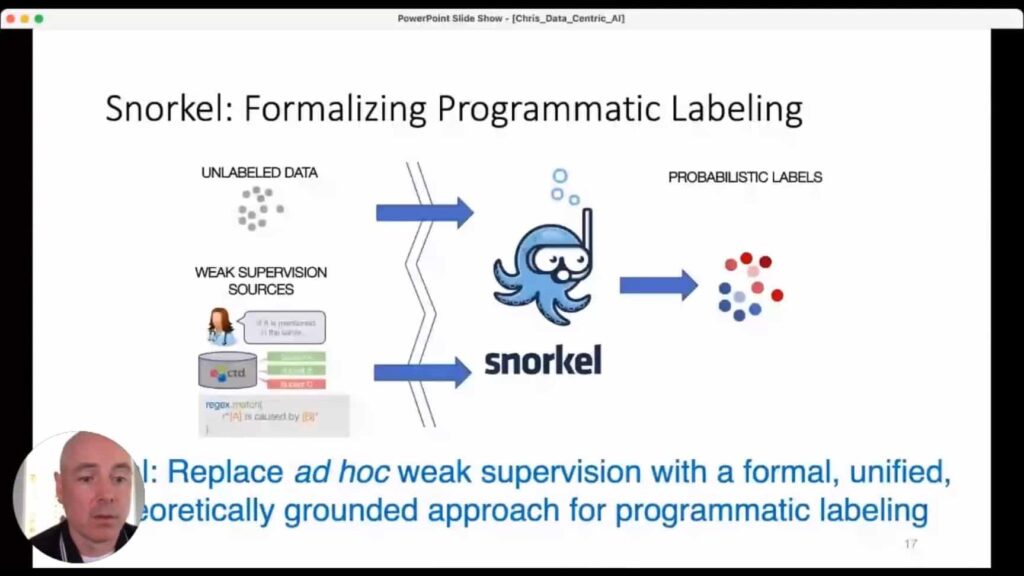
Snorkel’s approach to this problem is programmatic labeling. The key idea is that if you can write some code that handles data labeling for you, building an effective model will be much faster and much cheaper, because you can move at the speed of a machine. That speed also allows you to treat the data with software and engineering tools that allow for dynamic data sets that can be reconfigured on the fly to allow them to be redeployed much more quickly. But there’s a tradeoff with all this, and that is that programmatic labels are generally very noisy.Using weak supervision for data labeling is not a new idea, as we know. Pattern Matching; Distant Supervision; Augmentation; Topic Models; Third-Party Models: all of these are well-established ways of getting large amounts of lower-quality feedback data. But we realized that even this weak-supervision data was still being applied in isolated ways, and that ad hoc application limited the progress that could be made with this labeling method. The Snorkel project’s original goal was to replace this ad hoc weak-supervision data with a formal, unified, theoretically grounded approach for programmatic data labeling. Snorkel as a company has expanded this perspective in an array of different directions that now encompass the whole workflow for AI, but the formalization of programmatic data labeling is where things really started for us.

Let me give an illustrative example, using a simple named-entity recognition problem, to better demonstrate why what Snorkel does has so much potential to push machine learning forward. Imagine we have a document, and we want to know which names in the document are those of people and which are hospitals. Bob Jones, here, is a person, and of course, Saint Francis does not refer to the actual saint but rather to a hospital.

We can use several forms of weak-supervision label training. We could write a quick python function with an off-shelf classifier that says Saint Francis is a person.

We could also refine that existing classifier and combine it with some extra rules.Unfortunately, it still wrongly returns Saint Francis as a person.

We could next use our database of hospital names—a distant supervision technique—to label it as a hospital.

The classic problem remains, though: these sources are noisy. There is no source for ground truth. But for Snorkel, that’s ok. Because we can use a technique to de-correlate them, and we don’t need any hand-labeled ground truth to do it.
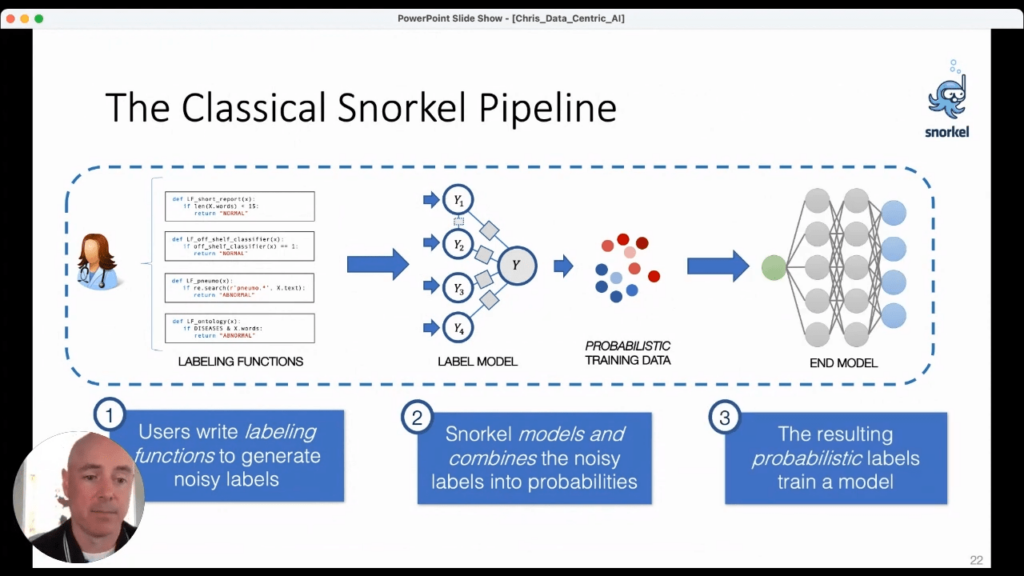
Snorkel’s “classical” flow goes like this: 1. Users write labeling functions to generate noisy labels.2. Snorkel models and combines those noisy labels into probabilities3. Snorkel uses probability theory to optimally combine all of the information about the sources and the functions to generate probabilistic training data that can then be fed into any deep learning model we want.And Snorkel’s work shows that we can modify virtually any of the state-of-the-art models to accept this probabilistic data and improve their performance.The key idea is that at no point in this flow do we require any hand-labeling of the data. Developers do not hand off data to be labeled and returned at some future date. Rather, the developer is integral to the labeling process. So, the question becomes: if we eliminate the hand-labeled-data bottleneck, how far and how fast can we go?
Theoretical Foundations
One problem, of course: how do we know how accurate our probabilistic labels are? Well, can we learn the accuracy of annotators without labels? Research shows the answer is yes, to information-theoretic limits. This is demonstrated by Mayee Chen and Fred Sala 3.Can we learn the correlations between annotators without seeing label data? Under certain mild assumptions, Chen and Sala demonstrate again that, yes, we can. Even without labeled data we can still recover how correlated our functions are.Can we use data labeled in this way for de-biasing? If we know there is bias present that is hard to express in a programmatic way, can you resolve it with labeled data? Again, yes. In fact, I wrote a paper 4 that shows this is doable in an optimal way.

This is just a sample. At this point, Snorkel has published literally dozens of papers 5 that fully show we can learn the structure of and do estimation for what are called latent graphical models and get new results. In some cases, our results improve on the standard supervised data that the industry has been using for decades.In fact, beginning as early as 2018 Snorkel’s approach to data-centric AI has been applied in many places across the industry. And not just in corporate research papers, but in changes to real production systems that you have probably already used from places like Gmail, Apple, and YouTube 6 7. While these ideas are still being refined, what we see right now is that many industrial systems are using enormous amounts of weak supervision and doing so not as an afterthought but in ways that fundamentally change how people build their system and that change the iteration cycle. It is really exciting, because it speaks to how valuable and useful Snorkel’s ideas can be for the industry’s progress given further work and development.

The core of Snorkel AI as a company is the incorporation of this data-centric perspective to the entire workflow for AI. We use it for monitoring what we are doing over time; for how we understand the quality of workflows; for how we get SMEs on board; for how we take an organization’s existing domain expertise and bring it to bear on the problem at hand. If data is the record of your problem, Snorkel seeks to produce tools to better reflect what you care about inside that data. And that is what we view as the promise of data-centric AI for meaningfully moving machine learning forward.Ultimately, Snorkel AI is committed to thinking about data first, because doing so, in formalized programmatic ways has real theoretical, algorithmic, and practical advantages over model-centric AI.If you’d like to watch Chris’ full presentation you can find it on the Snorkel AI Youtube channel. We encourage you to subscribe to receive updates or follow us on Twitter, Linkedin, Facebook, or Instagram.
- Ratner, Alexander J., Henry R. Ehrenberg, Zeshan Hussain, Jared Dunnmon, and Christopher Ré. 2017. “Learning To Compose Domain-Specific Transformations For Data Augmentation”. Arxiv.Org. https://arxiv.org/abs/1709.01643.
- “Automating The Art Of Data Augmentation”. 2021. Hazyresearch.Stanford.Edu. https://hazyresearch.stanford.edu/blog/2020-02-26-data-augmentation-part1.
- Chen, Mayee F., Benjamin Cohen-Wang, Stephen Mussmann, Frederic Sala, and Christopher Ré. 2021. “Comparing The Value Of Labeled And Unlabeled Data In Method-Of-Moments Latent Variable Estimation”. Arxiv.Org. https://arxiv.org/abs/2103.02761.
- Chen, Mayee F., Benjamin Cohen-Wang, Stephen Mussmann, Frederic Sala, and Christopher Ré. 2021. “Comparing The Value Of Labeled And Unlabeled Data In Method-Of-Moments Latent Variable Estimation”. Arxiv.Org. https://arxiv.org/abs/2103.02761.
- “Research Papers”. 2021. Snorkel AI. https://snorkel.ai/resources/research-papers/.
- Bach, Stephen H., Daniel Rodriguez, Yintao Liu, Chong Luo, Haidong Shao, Cassandra Xia, and Souvik Sen et al. 2018. “Snorkel Drybell: A Case Study In Deploying Weak Supervision At Industrial Scale”. Arxiv.Org. https://arxiv.org/abs/1812.00417.
- “Overton: A Data System For Monitoring And Improving Machine-Learned Products”. 2021. Apple Machine Learning Research.

Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

