
To empower our enterprise customers to adopt foundation models and large language models, we completely redesigned the machine learning systems behind Snorkel Flow to make sure we were meeting customer needs. Our journey on this project started with evaluating customer requirements and led to an overhaul of the interactive machine learning system that now powers a core part of our platform.
In this article, we share our journey and hope that it helps you design better machine learning systems.
Table of contents
Why we needed to redesign our interactive ML system
In this section, we’ll go over the market forces and technological shifts that compelled us to re-architect our ML system.
Some background on Snorkel
Snorkel Flow empowers enterprises to build and adapt foundation models. A core part of this workflow involves quickly and accurately labeling datasets using Python functions instead of manual labeling by humans. These Python functions encode subject matter expertise in the form of anything from if/else statements to calls to foundation models.
To build high-quality training datasets for their machine learning applications, our customers iteratively tweak their labeling functions and apply them to their datasets. We’ve found that customers who have a faster feedback loop produce much higher quality training datasets– directly leading to much higher model performance.
The underlying principle here is simple: faster iterations lead to more in-depth analysis and iterations, which in turn lead to better outcomes. This iterative process requires a responsive, interactive experience, which in turn requires low-latency machine learning infrastructure.
The opportunity and the problem
As our customers expand their machine learning initiatives, they take on increasingly complex machine learning projects and use increasingly sophisticated techniques.
This complexity can take many forms. Training sets grow larger to improve generalization and achieve production-ready model performance. Use cases over complex data types such as PDF documents gain priority as our customers have the right tools, like Snorkel Flow, to tackle them. Customers tackle high cardinality and multi-label ML problems, requiring far more training data to cover rare classes. And users accelerate labeling by leveraging foundation models, and in turn, fine-tune foundation models with their training data obtained through Snorkel Flow.
Our original system design did not anticipate this increased scale and complexity. As a result, the system slowed down, preventing our users from getting the interactive experiences they needed to solve their machine learning problems. And despite repeatedly profiling, patching, and working around our existing system, it would still run into slow-downs and out-of-memory errors.
Because frequent patching required a lot of our time and didn’t always deliver the results we hoped for, we decided it was better to rebuild the system from the ground up.
How we redesigned our interactive ML system
Here, we’ll detail the process we followed to arrive at our high-level system architecture.
Start with the customer requirements and product roadmap
When redesigning an ML system, don’t dive in head first. We got as much visibility as possible on the customer requirements and product roadmap to avoid common mistakes.
Here are some common ML design pitfalls we looked out for:
- Incorrect assumptions about the customer and/or problem they need to solve.
- Optimizing for features that the customer doesn’t care about.
- Designing an ML system that is not deployable on customer infrastructure.
- Losing sight of accumulated learnings built into the previous system.
- Failing to anticipate future scaling needs or build the right abstractions for future product roadmaps.
We found it really helpful to loop in stakeholders who understand current customer pain points and future needs—especially product managers and our field team—to find answers to questions along the following themes:
Key user interactions
- Input data characteristics
- What are the bounds on the size of the input data in bytes on disk and in RAM? What are the bounds on the size of a single row or column in bytes? What about bounds on the numbers of rows and columns?
- Is there any risk that this data will get multiplied due to a required pre-processing step?
- What format is this data stored in? Is it compressed?
- Model characteristics
- What ML models are we supporting?
- How big are these models in bytes?
- How long do they take to load in RAM or GPU?
- How will the customer obtain model weights?
- Model/data interaction
- What are the inference latency characteristics per batch when using CPU/GPU?
- How large will our batch sizes be?
- How much maximum memory will our inference use per batch size?
- Operations on data
- What operations are we trying to run on our data?
- What are the latency and memory usage characteristics when running operations on our data?
- How CPU versus I/O bound are these operations?
- How parallelizable are these operations?
Consistency/Availability requirements
- What are our uptime requirements for the system?
- How should we handle exceptions such as node/container preemption or failure, or out-of-memory events?
- Should we perform job checkpointing?
- How important is consistency (in the distributed systems sense)?
Scalability requirements
- What are our latency requirements for key user interactions, and how should they change with increasing data scale or model/operation complexity?
- Should we build with horizontal autoscaling in mind?
Customer usage patterns
- What is the maximum number of concurrent users we should expect using the system?
- What are the relative frequencies of different user interactions?
- What’s the overall peak load on the system in user interactions per second?
- What should the overall user experience look like? This is important for surfacing status updates or errors/exceptions to the front end.
Customer infrastructure profiles
- How will the system be deployed? As SaaS, hosted by a customer on their Kubernetes cluster, Docker, or something else?
- How much CPU/RAM/GPU do they have access to?
- How available is their compute? Do their nodes often get pre-empted?
Future roadmaps
- What future key user interactions or scaling requirements should we anticipate in 6, 12, or 18 months?
To recap, our challenge was to enable users to run any number of labeling functions of any complexity over any amount of data—stably, and at blazing-fast speed—while keeping Snorkel Flow deployable for all of our customers.
Deployability and “Customer infrastructure profiles” are vital for building enterprise ML systems. Unlike pure SaaS applications where we can fully control the deployment, enterprise software that handles sensitive data must often be deployed on the customer’s cloud infrastructure. For example, building a system that depends on fully elastic GPU availability makes no sense if our customers don’t have GPUs to spare. Sometimes, we even need to limit our process memory usage because our customers’ clusters limit RAM at the pod, namespace, or node level. Ignoring these considerations could render our systems undeployable.
After all, you’re not just trying to build something cool; you’re trying to build something useful. Know your customers!
Think about how technical limitations affect the customer requirements
We needed to lay out how the limitations of computer systems might affect the feasibility of the requirements. This gave us the opportunity to think through the tools at our disposal, uncover solutions to technical blockers, and explore the space of possible designs.
At this stage, it’s also important to understand the limitations and bottlenecks of previous systems and avoid repeating design choices that caused pain in the past.
Here are some of the factors we thought through:
- Storage: Our datasets are often many gigabytes or terabytes in size. In compute-constrained deployments, they cannot be easily stored in RAM. We also need to perform random access on data. To accommodate these requirements, we store working versions of datasets on disk in the Arrow IPC format.
- Disk to RAM/GPU I/O: Reading gigabytes of data from disk in chunks and running an operation over each chunk helps us save RAM. The tradeoff is significant latency from disk or network I/O. On the other hand, persisting a dataset in RAM across jobs can make operations blazingly fast at the cost of RAM space. The same goes for persisting models across jobs to avoid having to reload weights.
- Network or IPC latency: How much latency will we incur from nodes or processes communicating with each other? How much will serialization/deserialization impact latency?
- Zero-copy reads: For customer datasets that only contain fixed-length types, it’s possible to perform zero-copy reads on Arrow IPC buffers. However, this often isn’t possible, requiring processes that want to read a dataset from disk to copy that dataset in RAM.
- Data parallelism and shared resources: In most cases, it’s preferable to perform data parallelism. However, if the operation, such as using a large language model, has a large memory footprint, then each parallel process would have that same large memory footprint.
- Copy-on-write semantics: If we perform parallel processing, loading a dataset or model into RAM and then forking off a child process would allow the child process to read the dataset or model without incurring another copy in RAM.
- Memory-aware scheduling: One common source of instability is out-of-memory errors caused by trying to run a job on a worker without sufficient resources. We wanted to only run operations on a cluster if there were enough resources to do so.
- Restarting versus reusing processes: Spawning a new process per task can help avoid out-of-memory events. Reusing processes is much faster, but risks accumulating memory leaks.
- Data locality: If our compute cluster is spread across multiple nodes, how important is it that we ensure that computation happens as much as possible in a single node to take advantage of cache locality?
- Autoscaling: Building with autoscaling in mind requires us to think about designing systems that are resilient to containers and processes being added or removed.
- GPU-sharing: On a given node, it’s good to know when it’s possible for different jobs or users to share a GPU to avoid GPU out-of-memory events or inefficient utilization.
Prioritize and discuss trade-offs when you can’t make everyone happy
After laying everything out, we observed that if we wanted to reduce our latency on I/O bound operations, we needed to pre-load data and models into RAM and perform in-memory processing. If we wanted to reduce our latency on CPU-bound operations, we needed to perform parallel processing.
We couldn’t just design a system that held everything in memory even though it’d offer a fast experience. For a given customer, if many concurrent users are trying to process different datasets, we’d require a ton of RAM to serve all of them, more than most of our customers had on hand.
Parallel batch processing reduced the RAM requirements because we could have a pool of workers read a chunk of the dataset into memory, run an operation over the chunk, and release it. For CPU-bound operations, this out-of-core processing would offer significant speedups due to data parallelism. But for large datasets, we’d need to repeatedly load chunks of data, leading to latency due to disk I/O.
We had no clear right answers. And we still lacked clarity on our must-haves. After considering a few possible designs, we had four competing priorities:
- Resource efficiency.
- Low latency.
- Deployability and stability.
- Concurrent usage.
In order for us to properly think about tradeoffs, we needed to know which characteristics of our system were the most important to optimize for. After rounding up our stakeholders again, we decided that our priorities should be:
- Deployability and stability.
- Concurrent usage
- Low latency.
- Resource efficiency.
This was because we wanted to:
- Ensure that our system could work reliably for all of our customers (subject to minimum operating requirements).
- Guarantee that many users could work on the platform at once.
- Optimize performance for customers who have ample resources.
- Use compute as efficiently as possible.
Now things got fun. It was time to think through different designs. For each design, we found it helpful to lay out how the performance and resource usage would look as we increased the scale of the dataset across different operations (model inference, similarity scoring, regex execution, etc.). This allowed us to clarify whether the design would help us achieve stability and concurrency, or if it optimized for performance and efficiency.
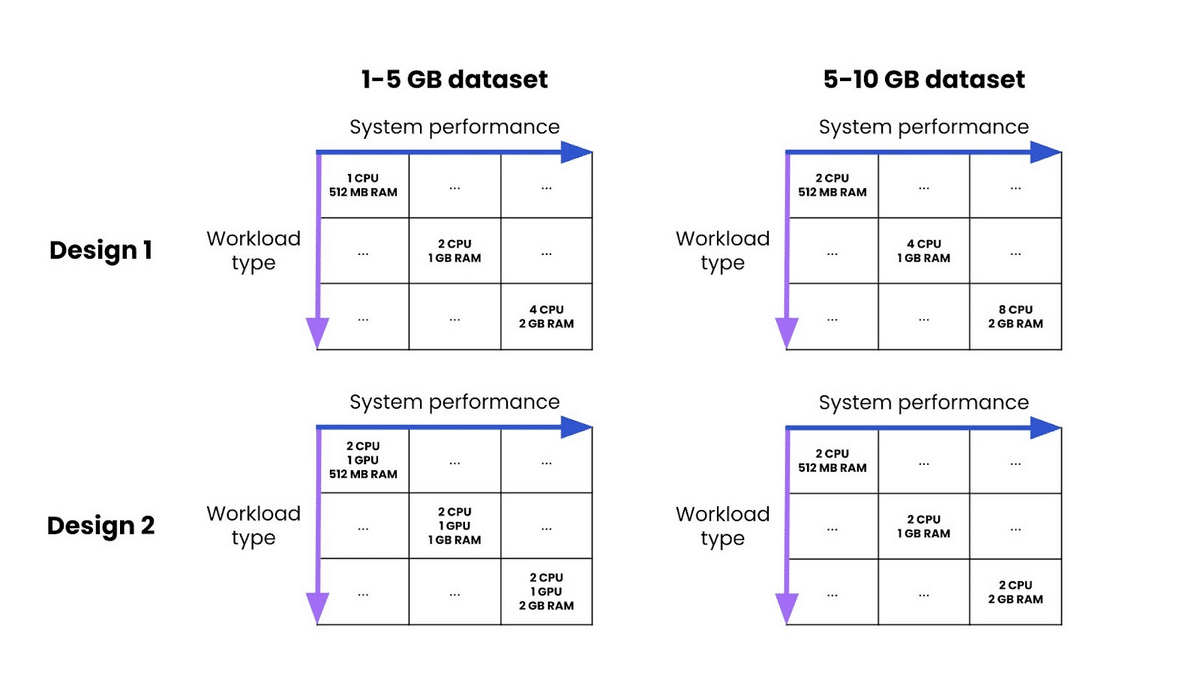
As we thought through designs and whether or not they were deployable, we also realized that we could bucket our customers into two categories: compute-constrained and compute-abundant.
This meant that we could build a resource-conservative system for constrained customers, and a highly-performant version for customers with ample resources. If the abundant customers ever ran out of resources, traffic could always fall back on the part of the design intended for the constrained customers.
By pursuing this hybrid architecture, we could have the best of both worlds.
What our interactive ML system architecture ended up looking like
After iterating through a bunch of designs, we found that:
- For our compute-constrained customers, a distributed task queue pattern was the best approach. With a fixed pool of resources, workers could consume any number of tasks submitted by any number of users. As long as a customer had the minimum required resources, we could deploy anywhere (setting performance expectations appropriately). Using out-of-core computation, we could process datasets of any size by reading chunks of data from disk to memory.
- For our compute-abundant customers, an actor pattern with in-memory processing was the best approach. We could instantiate actors that would keep data in-core for blazing-fast computation by avoiding disk I/O latency, especially from loading big datasets or large models. This could also support sudden bursty workloads with minimal latency. Greedy parallel processing spawned from that actor was an optimization we could consider later on.
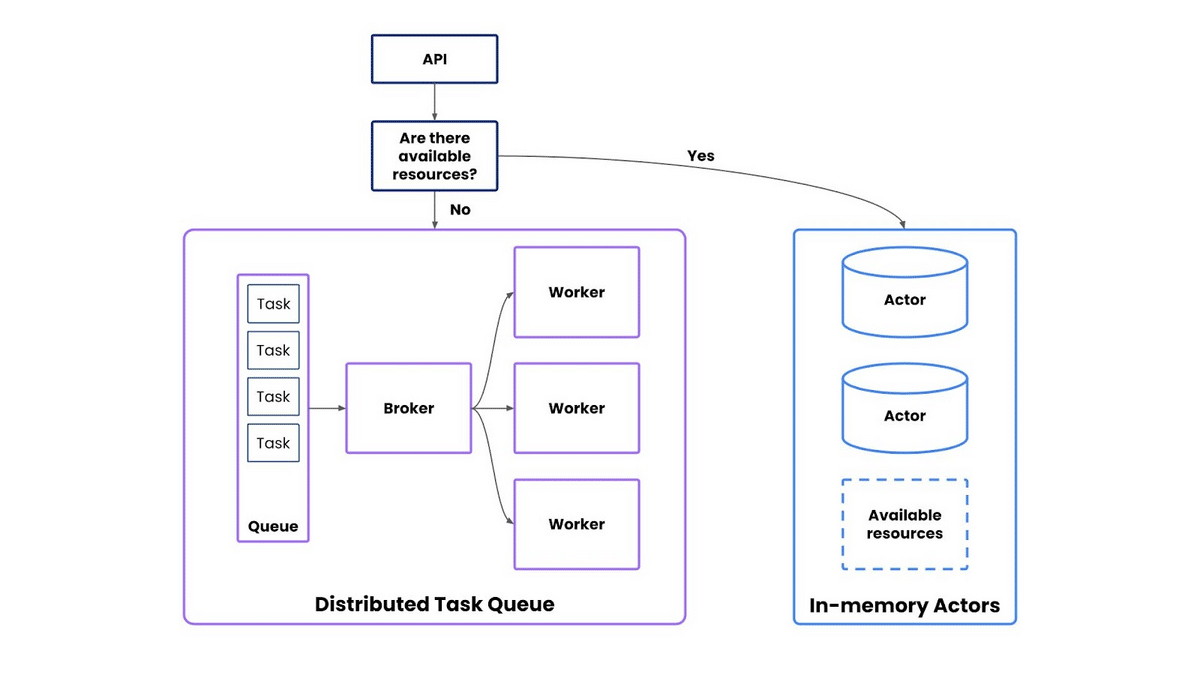
Based on the available resources left on the cluster, we could route user traffic to the task queue, or spin up a dedicated actor.
To achieve our goal of system stability, we also needed memory-aware scheduling. Rather than roll our own, we considered multiple frameworks and ultimately chose Ray for:
- How well it fits our hybrid task + actor design.
- Memory-aware scheduling as a first-class citizen.
- Developer experience.
- Community and support.
- Ease of autoscaling.
Conclusion
To summarize:
- Always start with the customer requirements and the product roadmap.
- Consider how computer systems and the underlying hardware will impact the performance and deployability of your ML system.
- Think about what it would take for your system to be deployable with your customers.
- Rank or prioritize business objectives so that you can make the right trade-offs.
- Explore combining approaches to satisfy more business objectives.
Building low-latency distributed ML systems for enterprises is tough! That’s not only a lot of buzzwords in a sentence, but also a set of difficult constraints to satisfy with real business outcomes.
We hope that sharing our process helps you build better ML systems, especially as foundation models and large language models become top of mind for enterprises all over the world.
Acknowledgments
Many thanks to John Allard, Varun Tekur, Manas Joglekar, Raviteja Mullapudi for co-designing and bringing this technical vision to life. Special thanks to Matt Casey, Henry Ehrenberg, and Roshni Malani for their thoughtful feedback on this article.
Come work with us
At Snorkel AI, we work diligently to make it easier for enterprises to build better AI solutions, faster. We integrate cutting-edge research with industry-leading design and engineering to create new, powerful, and user-friendly tools on our Snorkel Flow platform. If that sounds like work you'd like to do, check out our careers page! We’re actively hiring for engineering roles across the entire stack.

Will Hang
Senior Software Engineer
Will is a SWE and TL on interactive ML infrastructure at Snorkel AI, empowering users to quickly run ML workloads over large datasets. Previously, Will cofounded include.ai, a Sequoia-backed company acquired by Retool, and spent time at DeepMind and Google Brain, working on deep reinforcement learning for chip design. Will studied Computer Science at Stanford.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

