
Alex Ratner, CEO and co-founder of Snorkel AI, presented a high-level introduction to data-centric AI at Snorkel’s Future of Data-Centric AI virtual conference in 2022. His presentation explained data-centric AI’s promise for overcoming what is increasingly the biggest bottleneck to AI and machine learning: the lack of sufficiently large, labeled datasets. His presentation also highlights the ways that Snorkel’s platform, Snorkel Flow, enables users to rapidly and programmatically label and develop datasets and then use them to train ML models.
Below follows a transcript of Alex’s presentation, lightly edited for readability.
To tee it up, and I don’t want to overly confine what we’re going to be talking and hearing about and discussing at this conference today. It’s really quite broad. If you piece the words, data and AI together, you cover quite broad, expansive methods and techniques and applications and systems. So we’re going to be hearing about lots of topics. But I want to at least give our perspective on what motivated us back in 2015 to start talking about this and to start studying it back at Stanford, where the Snorkel team started: this idea of a shift from model-centric to data-centric AI development.

I’m not going to go into as much depth as I sometimes do, because I think by dint of us all being here, we all have some alignment and resonance around the idea that that data is critical today in actually shipping and maintaining and adapting and governing AI systems. And that it really is often the arbiter of success or failure.
Much more so than many other traditional elements—the particular model architecture, the particular serving platform—that are absolutely critical as well. But those elements used to be the blocker, and are often really not the blocker anymore because of all the amazing work that’s been done by the community—often now out in the open source.

It’s a really historically exciting time—definitely in AI, but I venture across many different technology areas. A day or two after some big research lab announces a state-of-the-art result on classifying images, extracting information from text, or detecting cyber attacks, you can go find that same model and replicate those state-of-the-art results with a couple lines of Python code and an internet connection.
But (and there’s always a but) this all depends on having often huge amounts of data that’s been carefully labeled and curated and developed to teach or train that model. So this is where data comes to bite you, and this is where you have to open up and break the old APIs and paradigms of traditional machine learning a bit.

Why is this such a problem that we need to have this carefully labeled and developed data? A huge amount of the data that we actually care about for building machine learning or AI capabilities is not nicely structured with well-defined columns or features, or well-defined labels.
A lot of AI to date, if you think about specifically machine learning, has been built on the backs of canonical use cases where you had the labels already, what we call the training labels that the model learns from. You knew whether an email was spam or not, at least partially, because of people clicking, and reporting the spam; or you knew whether a customer was going to churn or not because you knew that historically. So you could take these labels that you got organically from a data collection process and just teach your model to predict them on new, unlabeled data.
But in most use cases where it was really cheap to outsource data and say, “okay, this is a stop sign. This is a cat. This is a dog.” Even those efforts took years from inception to execution. But most data out in the world—in most organizations, most settings—it’s extremely unstructured, extremely messy, and extremely difficult to label. It’s often very private. You often need specially trained experts, lawyers, doctors, analysts, underwriters, etc., to do that labeling. And that data also is constantly changing.
So this is something that, as we’ve published about with many of the most forward-looking organizations in the space, this is something that stumbles even the largest organizations in terms of trying to get AI effort started.
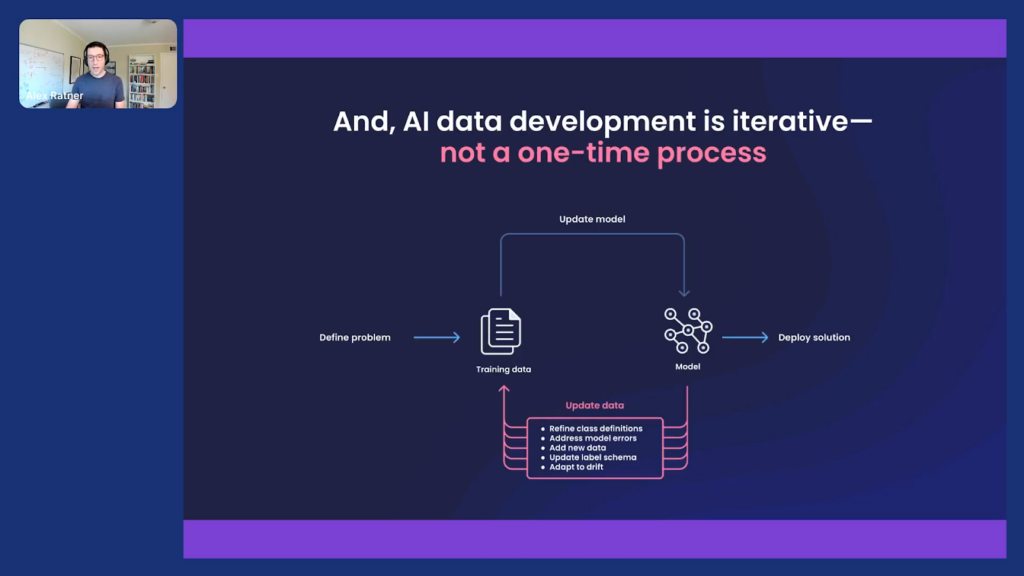
And one of the things that many folks (especially the ones who are blocked on the data development process in the first place) don’t fully realize, but that we’ve seen play out too many times to count over the years, is that AI data development is almost never a one-off process. It’s a constant iteration where you’re coordinating with upstream data providers and incoming data distributions with downstream model prediction, consumers, and business or mission objectives.
Data is changing. What you’re trying to get the model to do is changing. How you’re defining the different things that the model is labeling or predicting is constantly changing. And so this leads to this constant iteration of labeling and relabeling and reshaping and redeveloping the data that fuels and determines ML models.
So all of this points to the pain or pessimistic bottleneck “takes” around data. But the reason why we’re all here today is that not only is this bottleneck important and solvable, but it’s actually, if we take the more optimistic stance, just an exciting new way of building or programming AI. It’s actually, for many reasons that we’ll talk about a little bit here and throughout, a really exciting and compelling new interface to AI development.
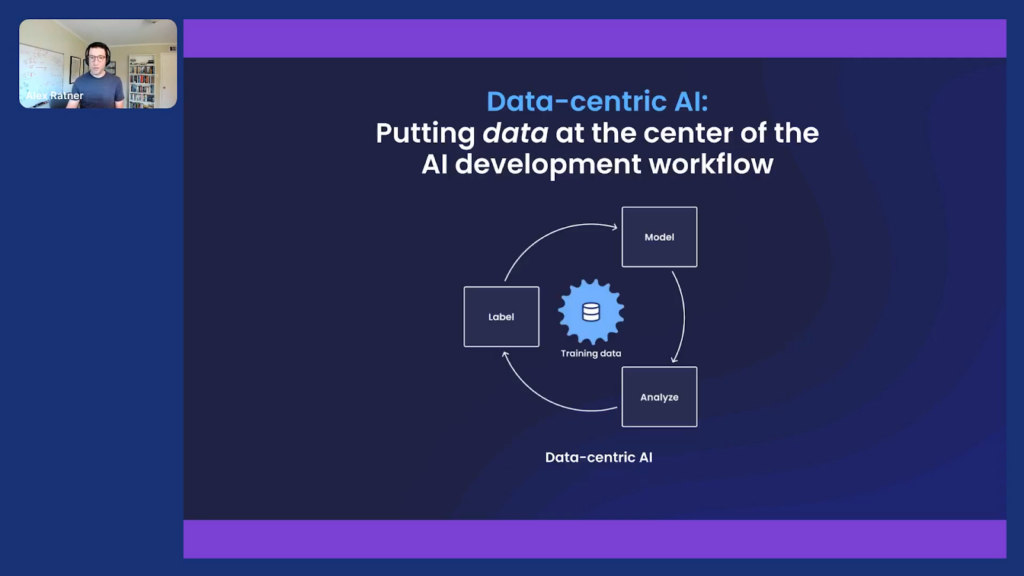
Really when we talk about data-centric AI, at least the definition I’ll venture before diving into a little bit more detail on what we do at Snorkel, is that it’s really just the idea that models used to be the thing that you iterated on, and data was this exogenous thing outside of the process that you got from someone else, or somewhere else, and didn’t really think about or edit.
Model development is still critical of course, but the idea of data-centric AI is that data increasingly is the first-class object of the development process, and this process of labeling and developing and using, and then analyzing and iterating on, your data—and specifically the training data that machine learning models learn—is really emerging as not just the key blocker but the key interface and development process of AI.
So that’s at least what we mean when we talk about data-centric AI.
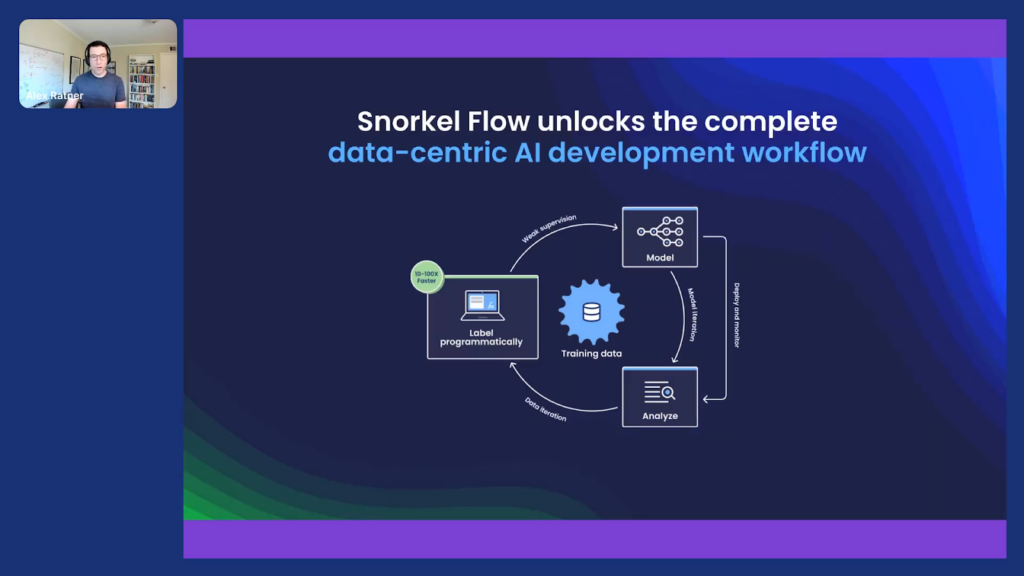
So, now I’ll go a click deeper into what we do specifically at Snorkel and what we’ve been researching, first at Stanford and now at the University of Washington, Stanford, and many other places—and of course, at the Snorkel company on our platform, Snorkel Flow.
This is a platform that supports this new data-centric development loop. It starts with this idea of labeling and developing data through a software development process by labeling and developing programmatically, rather than or in addition to just, “click, click, click,” labeling data points by hand, which a lot of AI today is bottlenecked on. This is then used to train models, and those models then power feedback and analyses that guide how to improve the quality of your data and therefore of your models. It’s this fast, iterative process that begins to look more like software development (no code, or via code) rather than what ML often looks like today, which is waiting weeks or months manually labeling datasets for every single turn of the crank.
So again, I’m going to be sharing a little bit more about Snorkel Flow, but I really intend this to be an illustrative example of one rendition of a new data-centric development process.

I’ll go into a little bit more depth, just so that we’re concrete here about what this looks like. If any of you are interested in more, of course, there’s our website at snorkel.ai, where you can find links to over 70 peer-reviewed publications if you want to get really deep into the weeds. Or, if you want to stay high-level, there are lots of customer and user case studies to see what this looks like in practice. I want to go through it in a little bit of detail, just to give some concrete grounding of what we do and how we conceptualize and support this new data-centric development workflow.
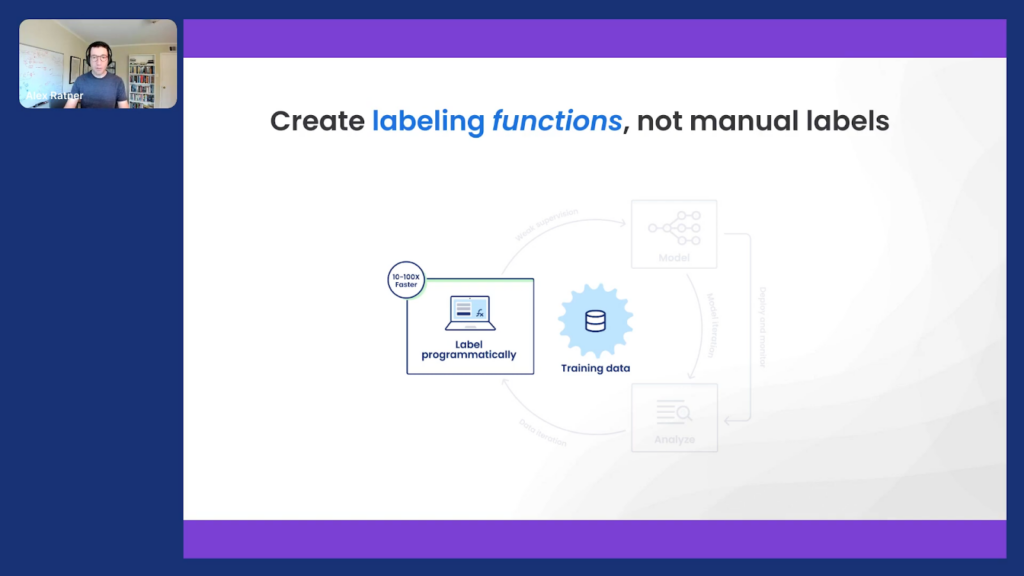
The process in Snorkel Flow starts by writing what we call labeling functions. These can be really simple ways of expressing expertise. So rather than just clicking and labeling one data point at a time, like playing 20,000 questions with a machine-learning model that then has to re-infer all that rich knowledge that was in your head, why not just express it directly to inject that domain knowledge? This could be something really simple.
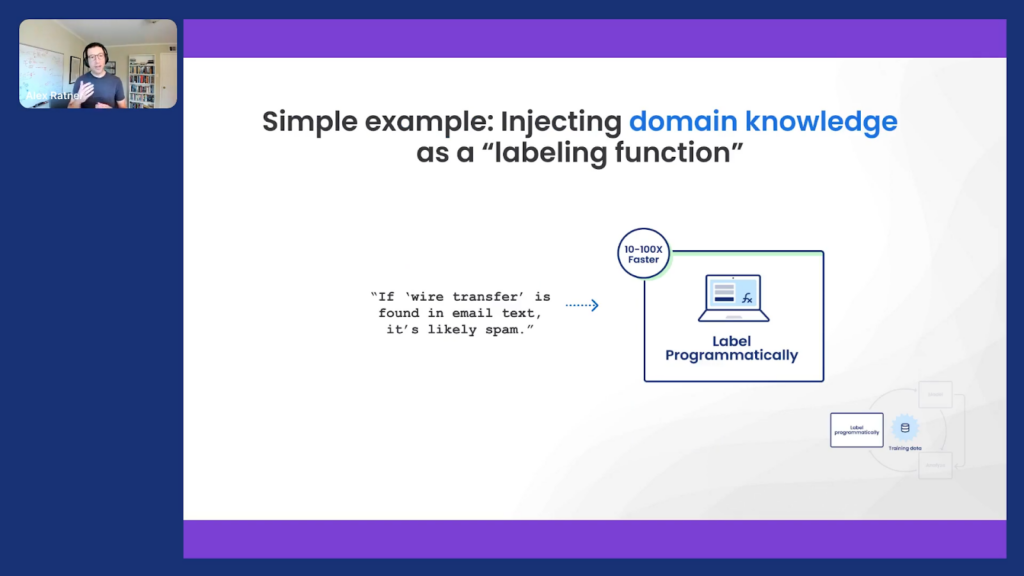
Take that canonical spam classification example: if you see the phrase wire transfer, maybe it’s more likely to be spam.
The challenging part of that, of course, is that simple heuristics or other inputs that we’ll talk about in a bit are not going to be perfectly accurate.
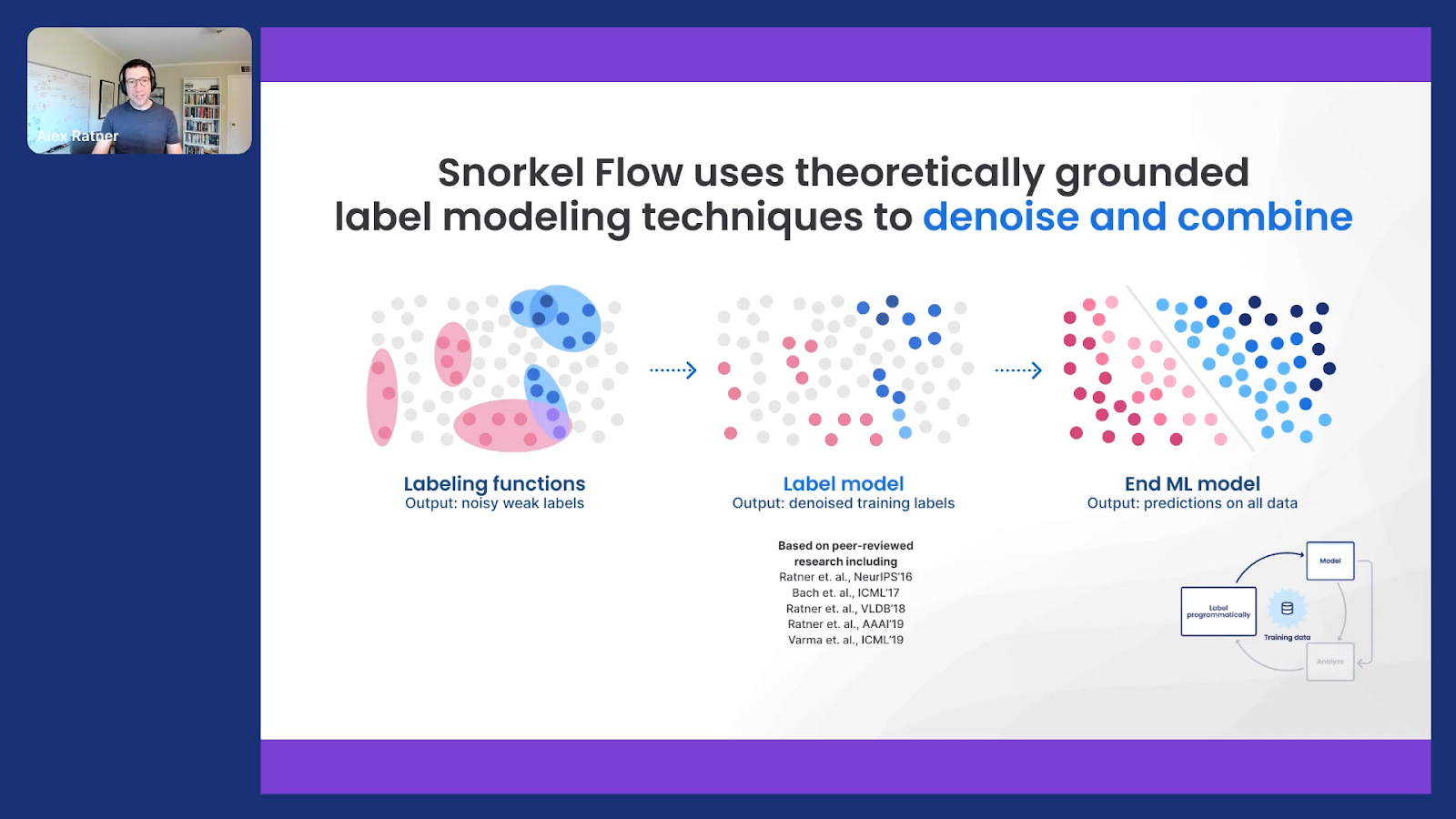
They might disagree with each other. They might conflict and overlap. They’re not going to cover all the diversity of complex data types. This is why in our academic work over the years we’ve referred to this as something called weak supervision, and we’ve worked for years on theoretically grounded algorithmic techniques for cleaning it up and integrating it.
Again, if you want to go deeper, there are lots online and in the literature about it that we and others now have worked on. But the key idea is that you can rapidly and programmatically label and develop your datasets, and then Snorkel Flow can clean this up and integrate it into a clean training set to train your model.
From there, the key part, of course, is iterating as quickly as possible. Seeing where you’re able to successfully train a machine-learning model, where there are gaps—which are often explained by gaps in the data quality or data coverage—and then using various analysis tools to rapidly iterate.
So that’s at least the conception of the core data-centric development workflow and the way that we uniquely support it as something that looks more like a push-button or programmatic software development process over minutes or hours or a couple of days, rather than what it often looks like in practice, where it’s weeks or months of sending spreadsheets back and forth, begging your line of business or subject-matter-expert partners to label more data.
Today, I’m going to go one click deeper. Hopefully, that gave both a quick summary of what we build at Snorkel but also an example of what a data-centric development workflow—that’s actually being used out in practice—can look like. But I want to go one klick deeper and give a little bit of a hint of where this is all going and where some of our research and development work is really taking this, along with lots of other exciting trends in the space.
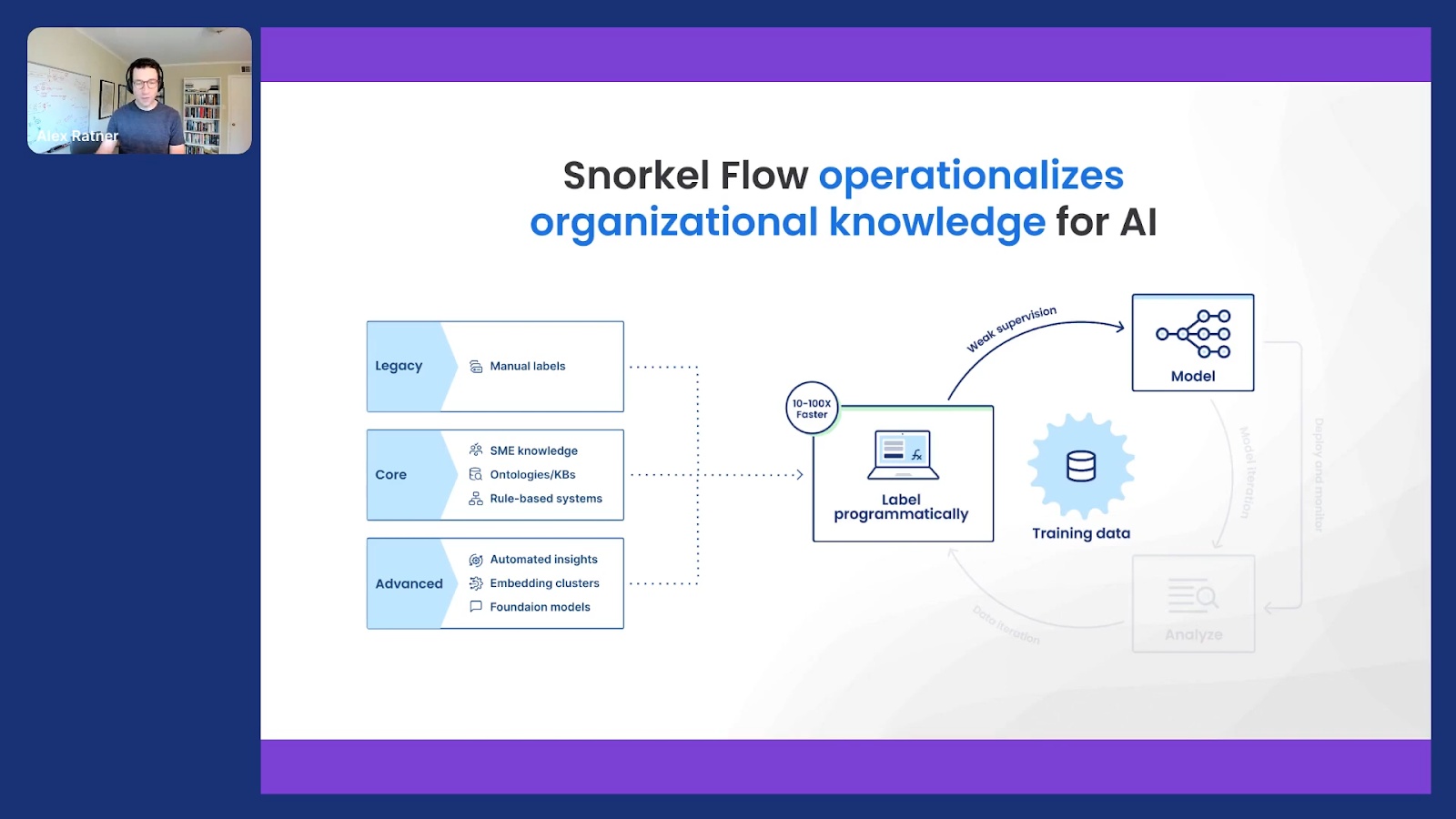
There’s a bigger idea at play than just looking for a keyword or a phrase like wire transfer and using it as a trick to label data. The broader idea—and this is something that we’ve worked on and published about for years and there have been some recent papers our team has put out if you’re curious about more detail—is trying to find a better way to operationalize all this rich knowledge, which sometimes we talk about as “organizational knowledge,” that can be used to teach or train machine-learning models, and that is currently often being thrown away.
So if you look at a standard machine learning process today, it’s often, “okay, we come in, throw out all the old stuff and start—click, click, click—labeling data” to build this huge training set to train a machine-learning model. If you look at it from that perspective, it should almost seem like a criminal waste to be throwing away all this knowledge that’s in people’s heads that’s been codified in various systems of record, and that also exists in more advanced forms out there, often in the public domain.
So from this perspective, the idea of a labeling function that I just went over, it’s really just an API or a basic atomic unit for leveraging all of this information to more rapidly and automatically label and develop datasets and therefore AI.
I’m going to try to substantiate that with three quick examples.

First, this may seem like a step backward, but it’s actually a big part of what we were trying to support from the very beginning. You can actually use this whole framework and this idea of labeling functions, of weak supervision, to subsume and manage massive manual data annotation groups. So just to give one quick example—this is actually a classical problem that’s been studied for years and that some of our theory builds on—you might have a whole bunch of labelers and, as many of you who have actually tried to label and develop datasets for AI know, they’re not all going to be perfectly accurate. They’re likely going to have their own different expertise areas.
If we take that spam example, maybe someone’s really into pyramid schemes, credit card fraud, etc. And they may have, not just different accuracies but different expertise areas. You might have spammers that are worse than a coin flip in terms of labeling. And figuring out how to wait and model and adjudicate and combine all of this input and how to clean it up. This is something that is subsumed by the techniques we’ve worked on for years.
So this is an example of how you can take legacy techniques of hand labeling. Maybe take stale datasets you have lying around or take some of the very expert annotators that you have as partners and use this paradigm of data-centric AI in this programmatic way to kind of subsume and manage it.
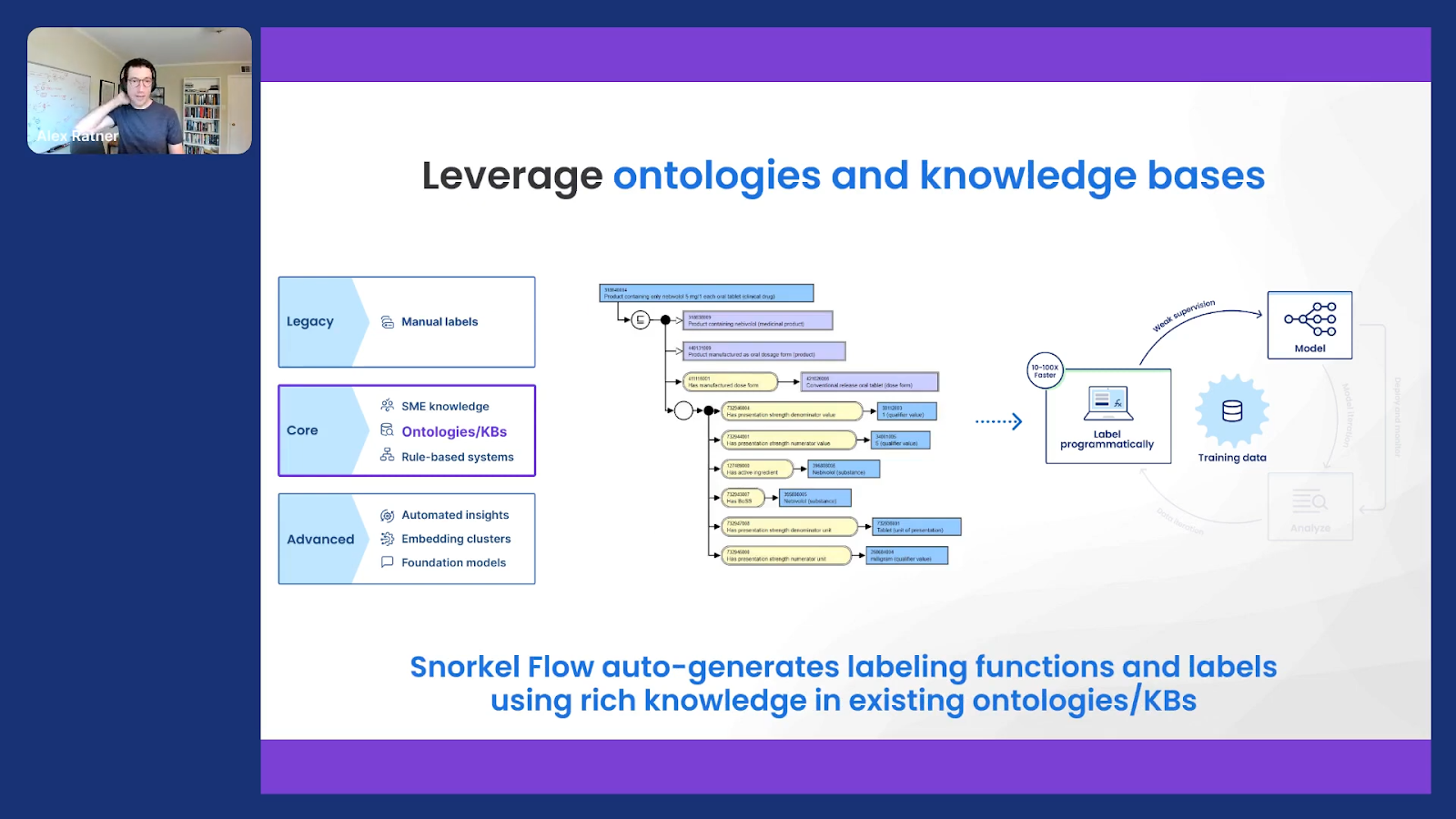
Taking a step forward, I gave an example of using some domain expertise. Again, if we’re thinking about our little spam example, domain expertise might be looking for a phrase like “wire transfer,” but there are many more advanced techniques that we have both published about over the years and built around in Snorkel Flow with many of our customers.
One example that I find quite exciting because of this practical ability to reuse knowledge that’s already been established and built up, is this idea of taking in ontologies or knowledge bases and using this to programmatically or automatically label data. We’ve done a lot of work here in the medical domain and others as well, where you often have these rich ontologies, knowledge bases, databases, dictionaries—lots of names for what these look like—where people have codified all this rich knowledge. Rather than just throwing it away, we can use it to auto-generate labels and train machine-learning models that can then learn to extend beyond what’s in these expansive but sometimes brittle knowledge bases.
So this is another way in which this idea of labeling function is just an API to try to get existing knowledge into the modern ML stack.
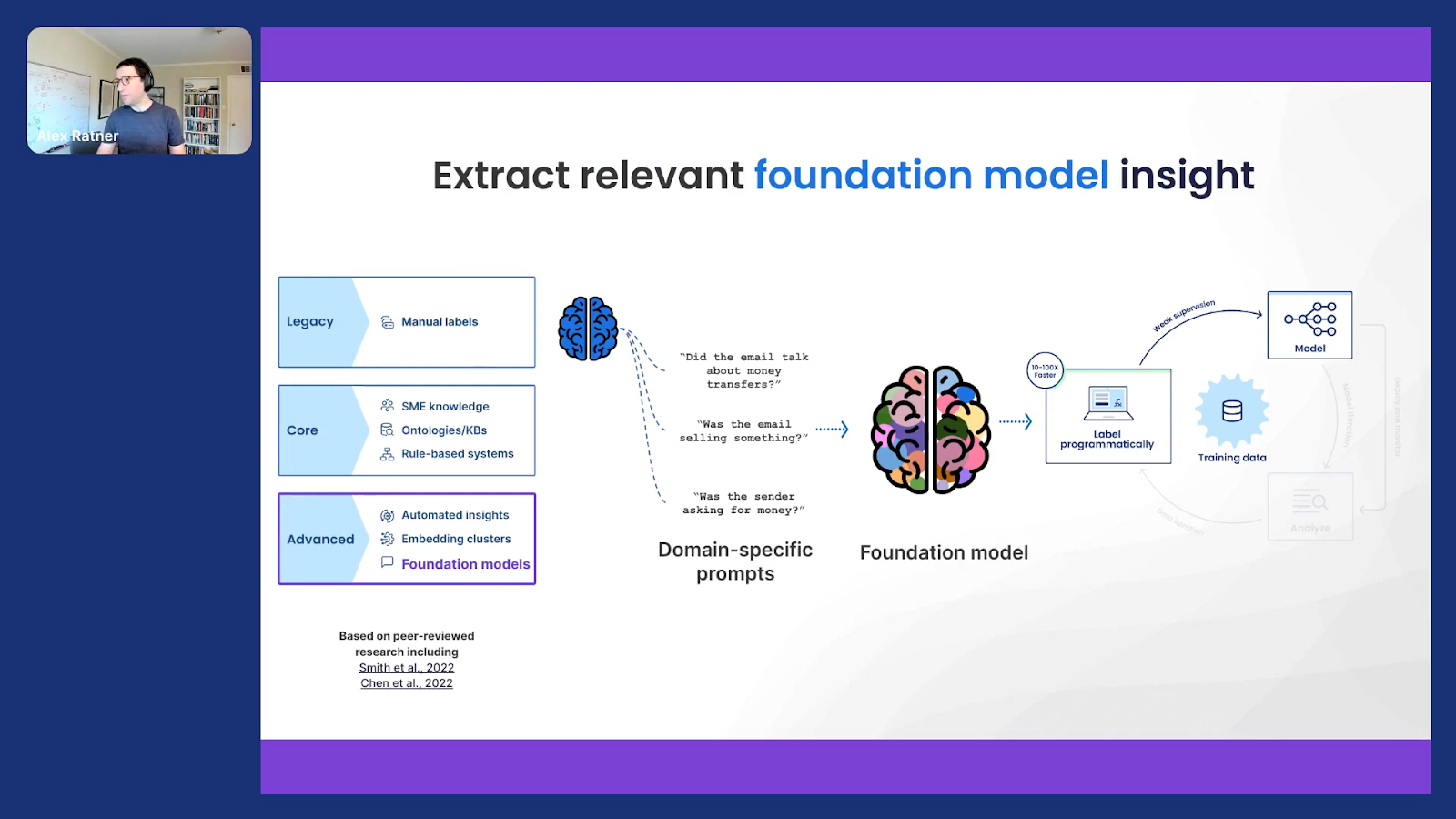
And a final example, and I’ll go into a little bit more detail just to wrap up in the last two minutes, is one that we’re quite excited about around this idea of large language models or foundation models.
This is something that my co-founder, Chris Rè over at Stanford, has been doing a lot of work on. We’ve been doing a lot of work on it at the company. We just posted a paper and there’s a bunch of others from the various other teams if you’re interested in the deeper details. But at a high level, we can use these increasingly large language models, the GPT-3s and beyond of the world, to actually train these custom, specific models that are deployable and tuned on our specific datasets and problems of interest.
So let me give a little bit of an example of what this looks like.

Just a quick recap: I think many of us in this group have seen all of these exciting large language models or foundation models that have been scaling up in quite an amazing way over the last couple of years.
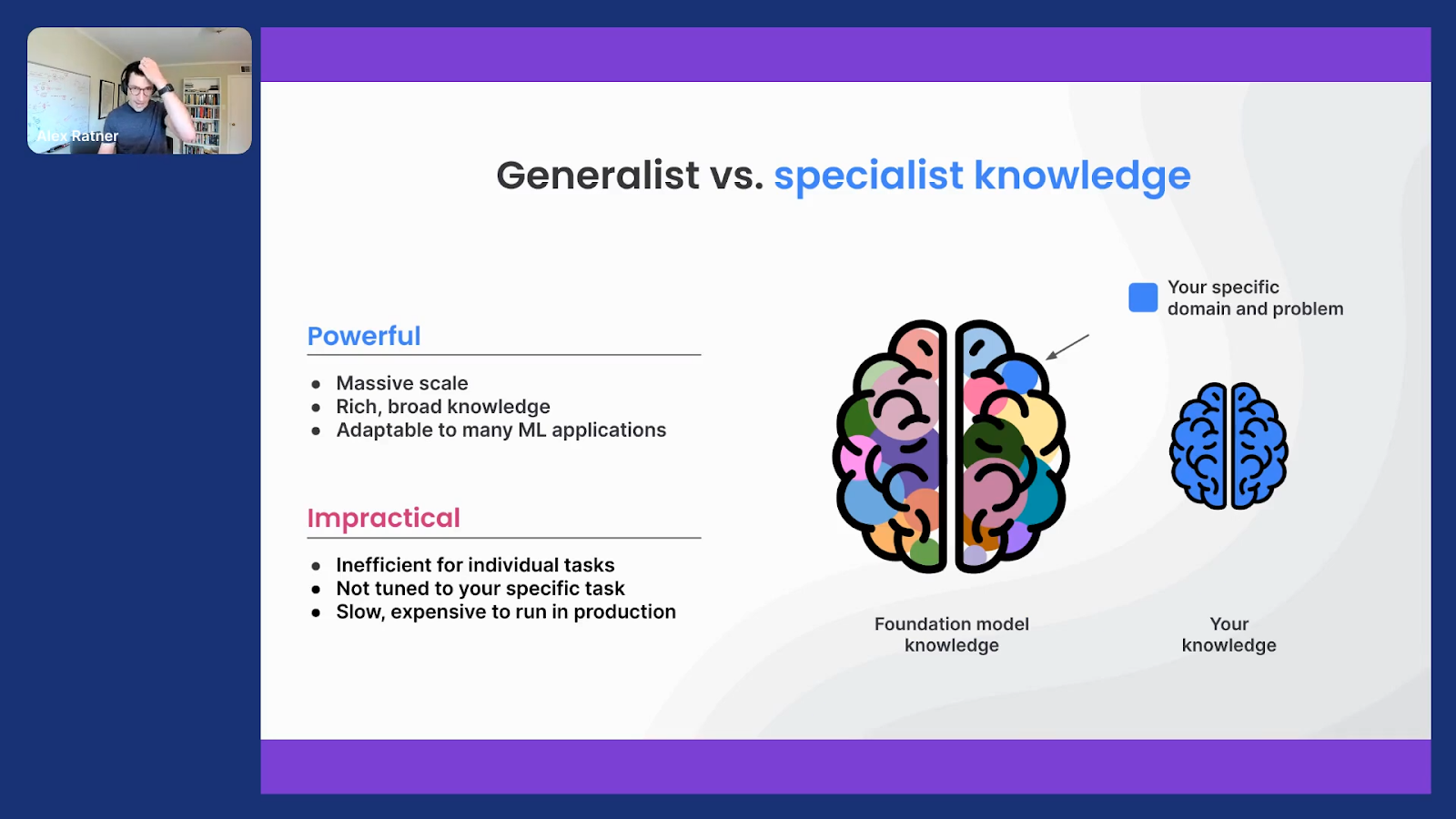
This is super high-level, but these models are amazing because they’ve basically been pre-trained or self-supervised on all of this data that’s out there. Often, this is internet or web data. They have all of this massive scale, they have this rich, very broad knowledge that can be applied, and there are tons of really incredible demos out there showing some of the breadth here that can be applied—with very little fine-tuning or prompting—to a whole range of problems.
However, when it comes to building a deployable machine-learning model that is actually performing at production-grade quality on your specific data, your specific problem— especially when your specific data and problem is not something that looks just like standard Wikipedia articles or web data—this becomes very challenging. So these foundation models still need considerable data labeling and development or prompting or prompt tuning (there are lots of exciting new techniques coming out), but they need basically teaching to actually zero in and perform at quality on these specific datasets and problems that you actually want to ship AI applications around.
They also are incredibly slow and expensive to run in production. So a lot of where the world has been moving, including in some of the work we’ve been doing, is figuring out: how can we use all this rich knowledge, but distill it and tune it for our specific problems into deployable models?
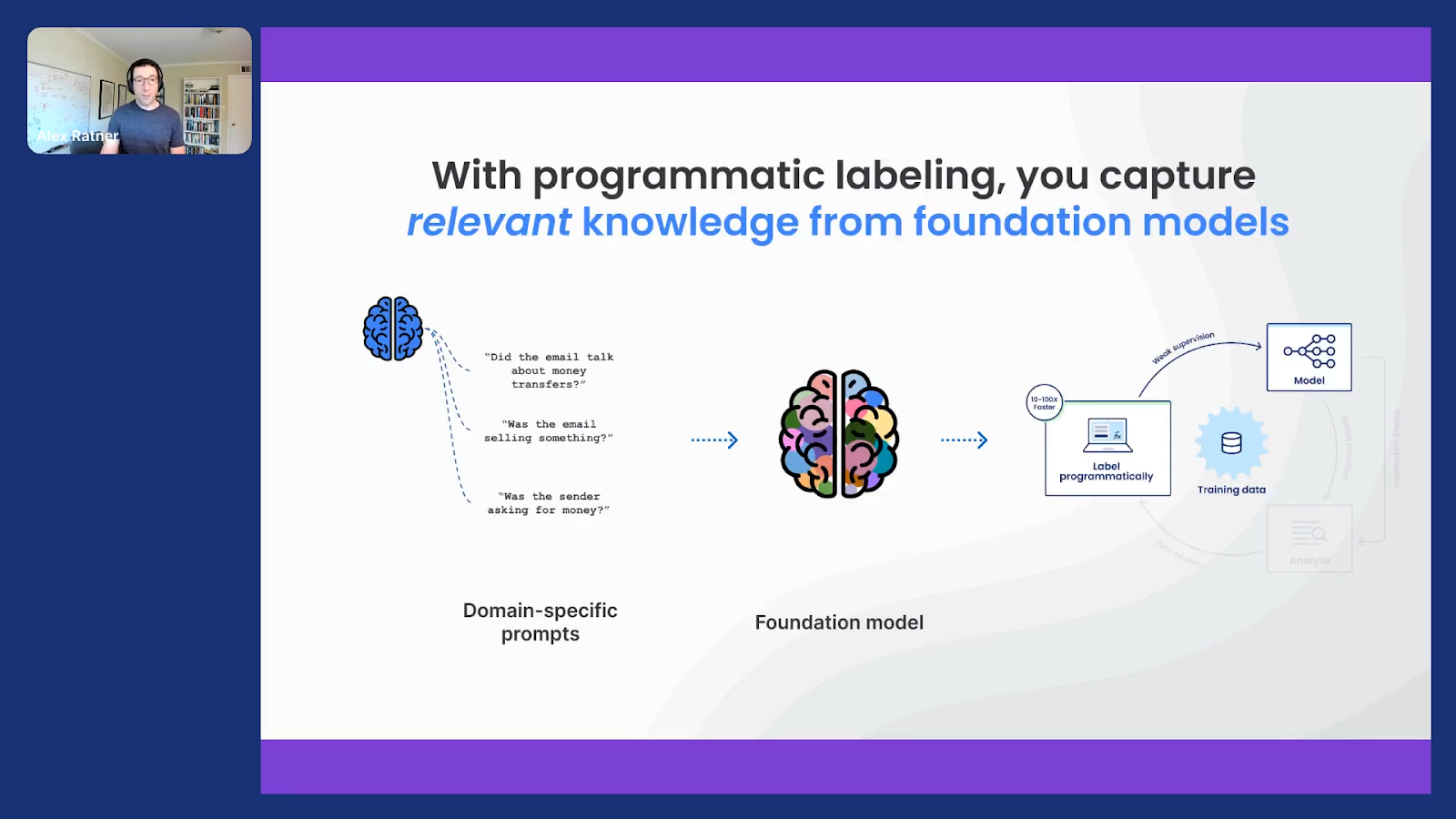
This is another thing that we are very excited about. Another example of this idea of programmatic labeling as just a bridge between rich knowledge that’s out there and, in this case, combining it with domain-specific knowledge in the form of prompts or labeling functions to use it to power custom model development.

We have shown empirically—and now it’s exciting to have demonstrated with some early customers and users of these techniques—that the biggest bang for your buck is when you can actually combine all of these sources. These large language models and embeddings and automated techniques; the rich, existing structured knowledge that you have in your knowledge bases or in your subject-matter-expert collaborators’ heads; and lots of labels if you have them or you want to get them for specific slices of the data that are tricky—you can combine them all together using Snorkel Flow as an orchestration solution to use them to superpower your model development in this data-centric way.
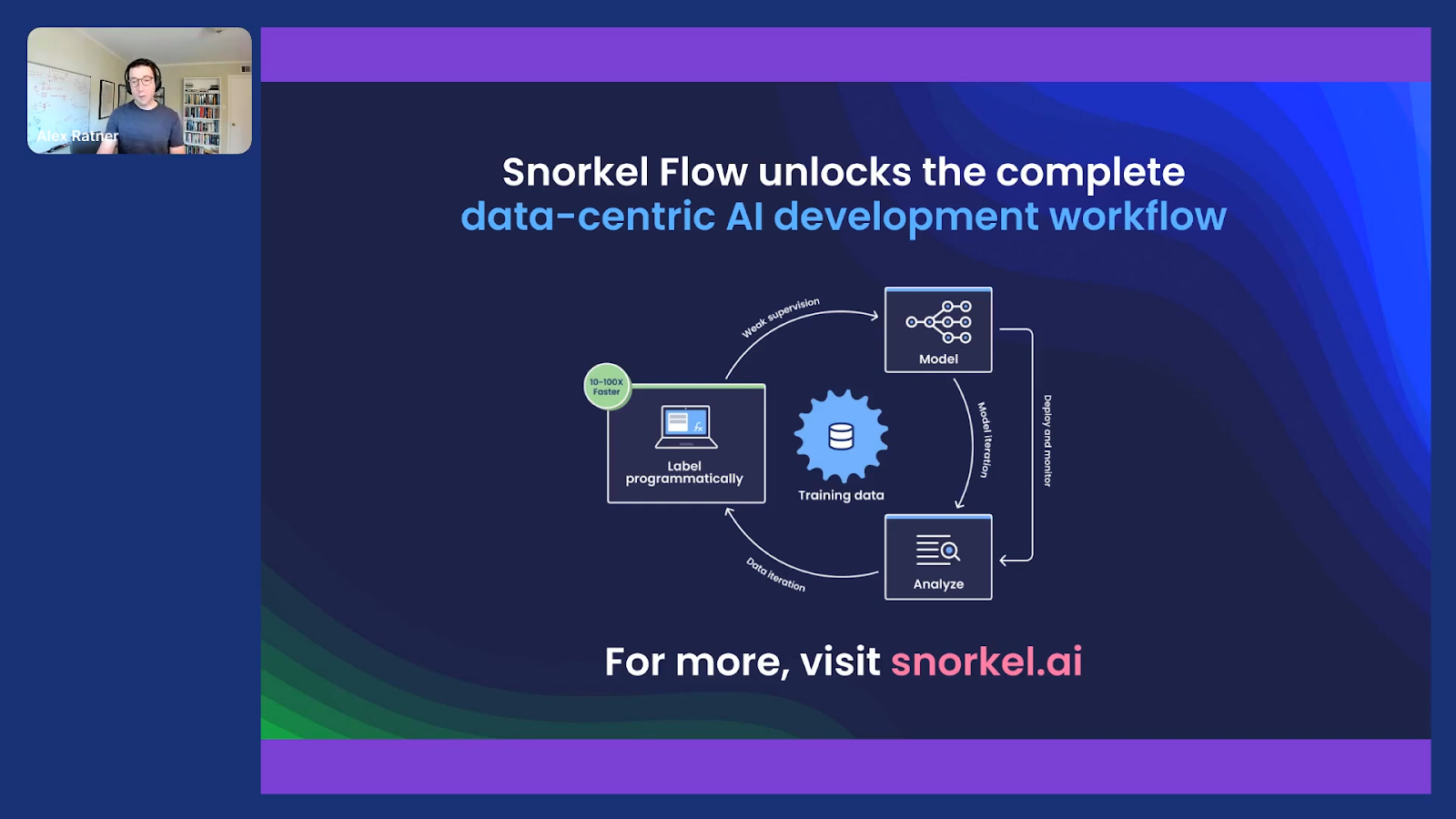
So that’s where I’ll wrap up. Here again, if you’re curious about some of those details or about the broader idea of this data-centric loop at the programmatic level that Snorkel Flow defines, please check out our website which also has links to all the academic papers over the years.
Catch the sessions you missed!
The Future of Data-Centric AI 2023, our two-day free virtual conference, brought together thousands of data scientists, AI/ML practitioners, researchers, and the AI community at large to hear about and discuss the latest trends and research in data-centric AI. If you registered for the event but didn't see all the sessions you wanted, you can now catch up. The recorded sessions are available for registrants at the same Zoom portal as the live sessions.

Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

