New Snorkel benchmark leaderboards. See the results.
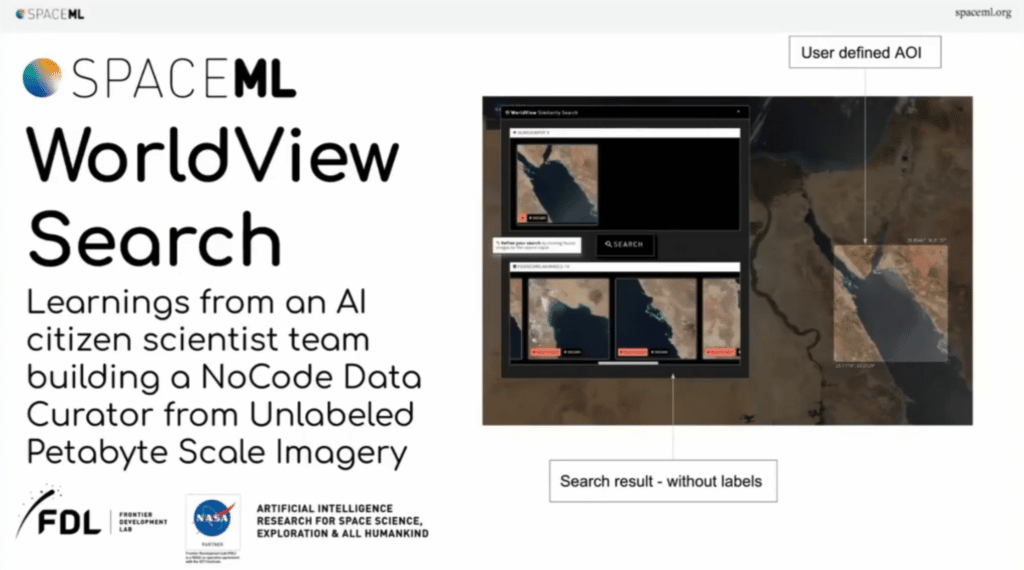
NASA ML Lead on its WorldView citizen scientist no-code tool
Anirudh Koul is Machine Learning Lead for the NASA Frontier Development Lab and the Head of Machine Learning Sciences at Pinterest. He presented at Snorkel AI’s 2022 Future of Data Centric AI (FDCAI) Conference. A transcript of Koul’s talk is provided below. It has been lightly edited for reading clarity.
I’m going to talk about today, a problem that we all have faced as a child and it’s the game of “Where’s Waldo.” It’s basically the game where you have this super large collage where you’re trying to find Waldo, or, depending on the country you are in, Wally.

And it’s somewhere in there. I have looked at this image for a while, I have still not figured out where Waldo is. And NASA faces almost a similar problem.
The problem they face is that when a researcher has to work on a real scientific problem, before working on the problem they have to go and collect data.
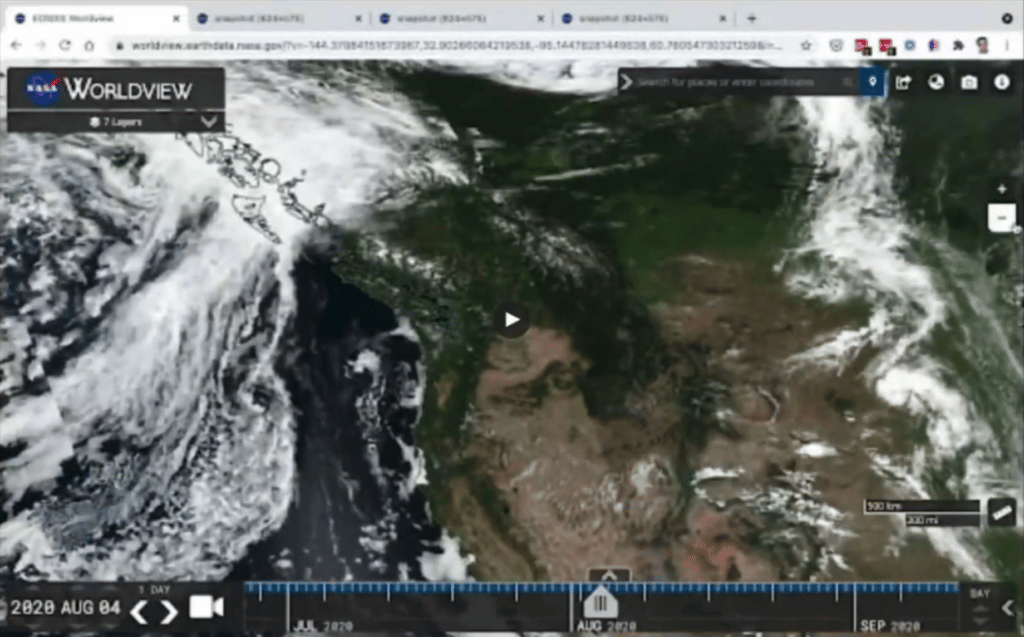
So here’s the life of a PhD researcher trying to find the particular phenomena that they are interested in. For example, here, let’s say the researcher is interested in, let’s say, wildfires.
Great. They clicked on it, they found it, they take a selfie of Earth, and they have one image collected, plus all the metadata.
Now they go on this file chase to find a second example. They found it. Two items collected.
Now they have to find the third item, and they keep moving the mouse, moving the mouse, moving the mouse. And as you can see, that is a pretty tedious task to do. Maybe they get lucky, or maybe this is just a cloud. You could imagine, for deep learning, you need, really, a lot of examples.

Whereas in this case, finding one, two, or three is taking us so long, imagine if you had to do that over 197 square miles, and that is one day of data. Whereas from satellites, we have 20 years-plus of data. And then there are N number of products. Very quickly, this problem becomes pretty unscalable. I think you’ll agree with me.
Finding similar items, what a particular researcher needs, is basically the task here. Is it possible for the researcher to find, exhaustively, all examples of wildfires, of cyclones, of icebergs breaking, but making an exhaustive collection? So, deep learning, similarity search is a very easy, simple, task.

But in this case, it becomes slightly harder because, number one, the data is ultra-large-scale. Number two, there are no labels. So, usually you come up with a pre-trained network or a network trained on your particular task, which will be really able to find similar conceptual items easily. Problem is, we don’t have any labels, so how do we even train a network for infrared imagery? Thirdly, there are multiple concepts. So, unlike ImageNet where there’s one concept in one place, you could have a hurricane, a desert, an ocean all inside the same image. It becomes harder. And finally, this data is really unbalanced. Ocean water accounts for 70% of data. Whereas, you know, hurricanes would be like 0.0001 [percent].
So, training a network to understand this imbalance becomes harder. And that’s why I think this is some sort of a “moonshot” challenge to be able to solve this problem. But then, well, I’m presenting here, so I probably will have a demo ready, right, to show you. So that’s what we’ll see.

So let’s say, here we go. In this example, here’s a real system, which is running. This particular researcher is interested in, let’s just say, these fluffy clouds, because I don’t know what the scientific name for this is. They find it, they search for it, and voila, the system is able to find similar patterns. Keep in mind, none of this data is labeled at all.
Maybe the researcher is interested in more of the structure where one side is dense and one side is more sparse, and the system kind of picked out those kinds of patterns. Alright, so the system is making sense.
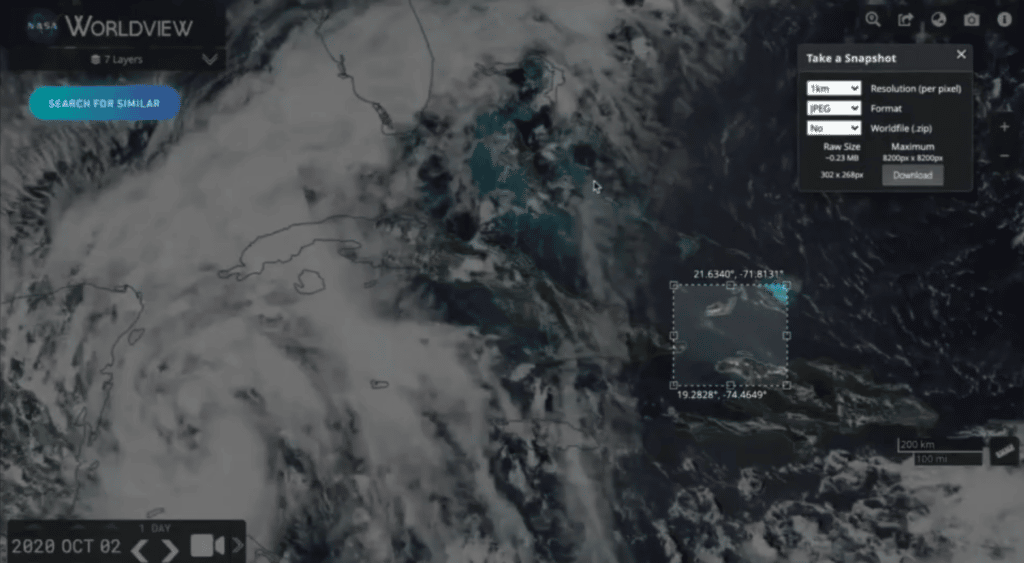
Now, we have all been stuck in this COVID world. Maybe you want to go on this nice vacation.
So you’d be looking for those places with the bluest of the blue oceans. We go and search for that, and let’s see what the system is able to find.

I think I know my vacation spot already at this point. And that’s the power of self-supervised learning.
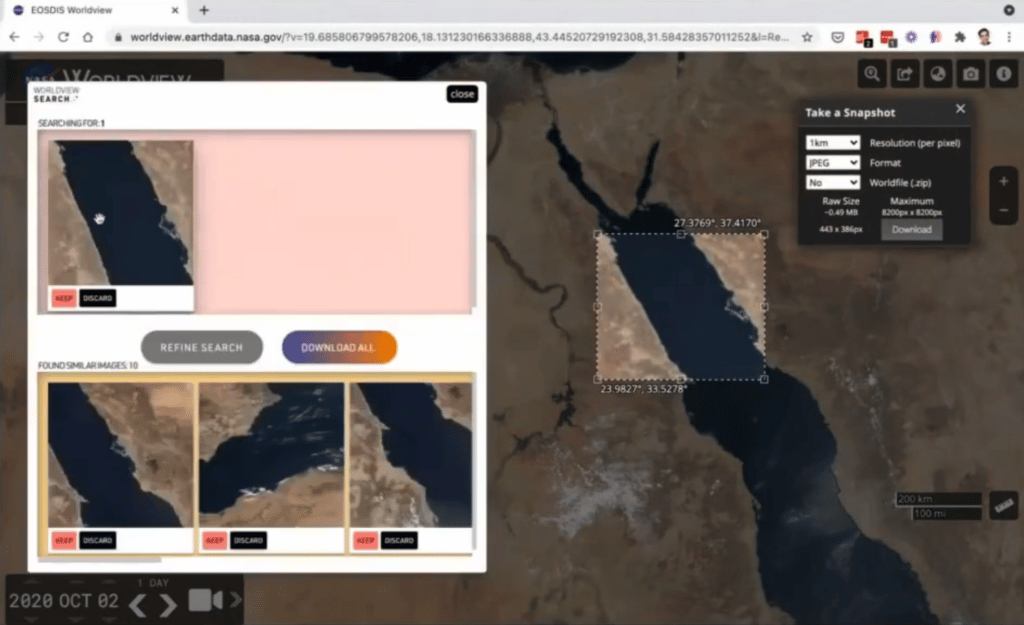
I want to show you another example, which really sells this point across. You know where this Ever Given gets stuck every now and then? This area we are trying to search for, the system returned back similar desert-ocean-desert sandwiches. Even if you had a classifier, a classifier would not have been able to understand the structure, and it would have given you things with an ocean and a desert. But desert, ocean, desert, in this way, I think that’s what the power of self-supervised learning is.
So, now that I’ve shown you the story, let’s go into a little bit of theory. We’ll solve this with self-supervised learning, which is basically the [research] area catching on fire since 2020 onward when Google released the SimCLR.
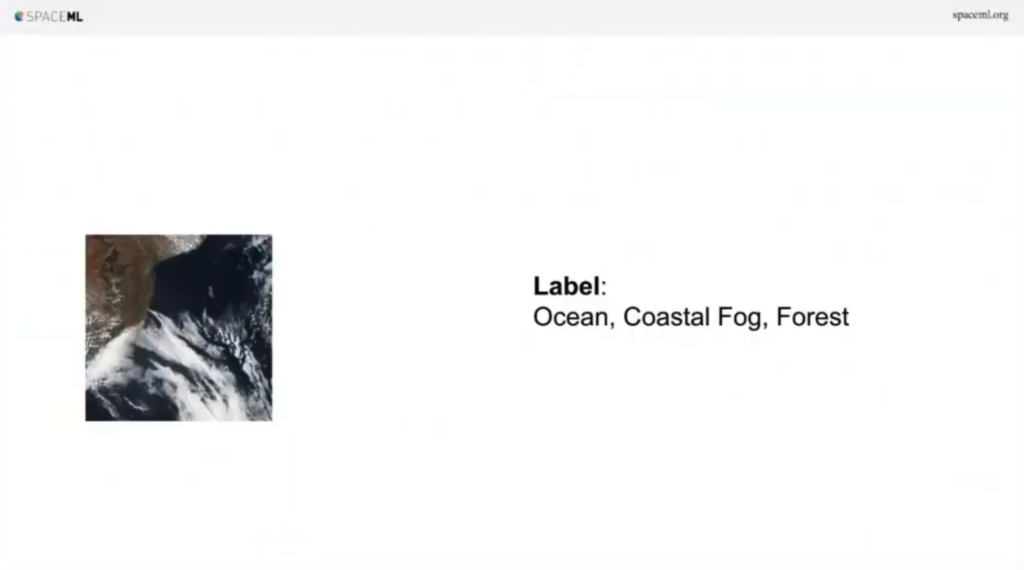
So here’s this example. We have this tile of a satellite. I think you can imagine, this is an ocean, this is coastal fog, and there’s a forest. But we don’t have any labels. So what do we do to train a network when you can’t do it supervised? Well, how about you take this image and then you rotate it randomly between zero to 360 degrees, and you get this new augmented version.
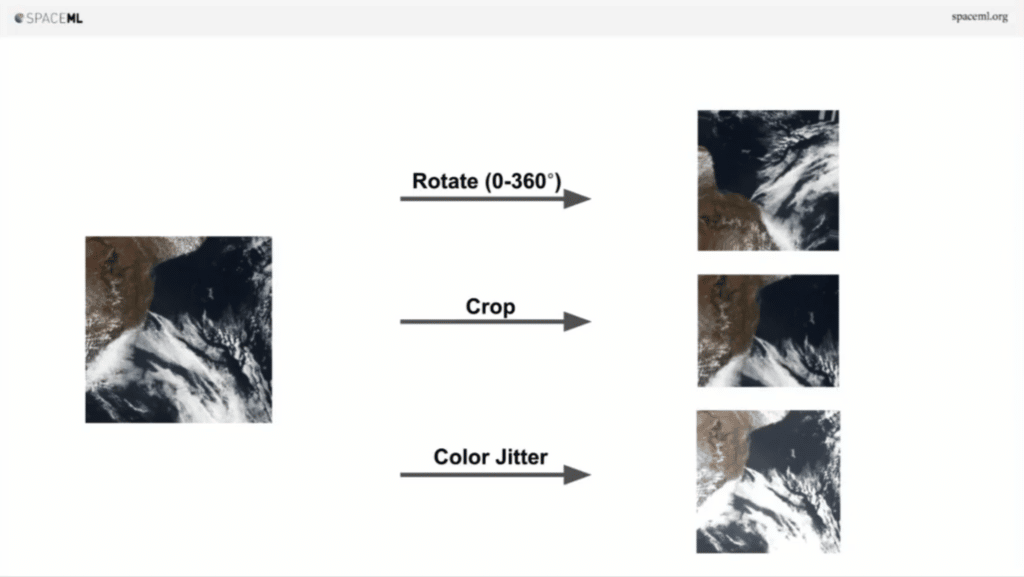
Now the image on the right and the image on the left are essentially the same thing, right? Imagine you take this image on the left and you crop it a little bit. They’re both the same image at the end of the day. As humans we understand that. How about we change a little bit of the brightness, contrast a little bit. Same image at the end of the day.
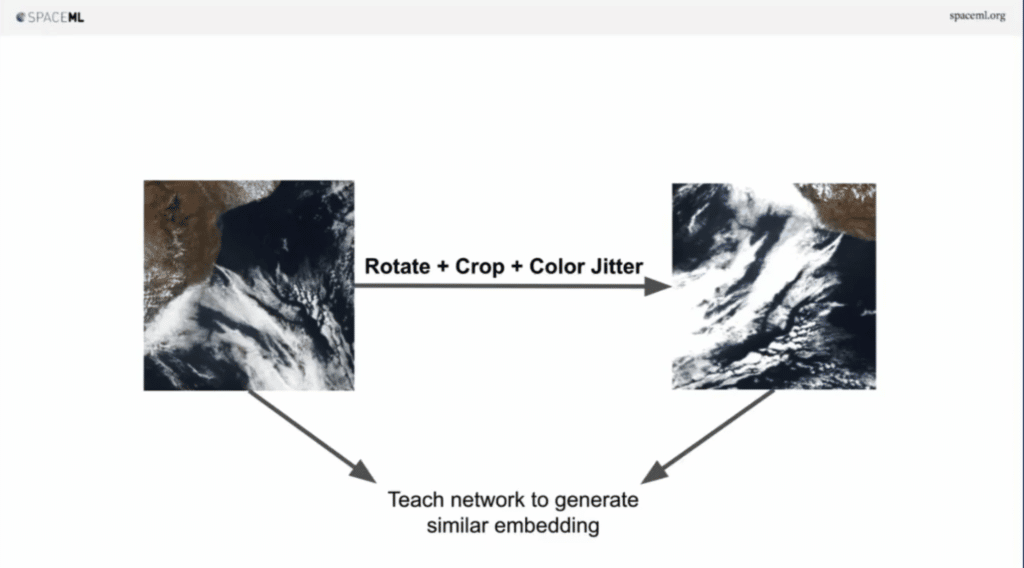
So, the idea is, what if you take an image and do some augmentations, and then you generate a new image and then let a neural network figure out that the image on the left and the image on the right are similar.
Imagine you give it a lot of data, tons of data, millions of examples. The system starts to essentially understand the meaning behind the concepts, even though it doesn’t have any labels. It’s essentially self-supervised learning. The self part here is important. This is essentially SimCLR, but since then many new techniques have come up and have really increased the metrics in this field.
When we tried to do this for NASA, we basically thought about three principles that we want to employ. First, we want to make sure this is open source. We want to ensure this is modularized, so that instead of one gigantic system, we have these tiny modules for computer vision and they could be combined for many different problems beyond the problem NASA was trying to solve. And we want it to be high performance. And lastly, we want it to be useful by anybody who does not know AI and they don’t know coding. So as long as you can use a command line, you can use this.
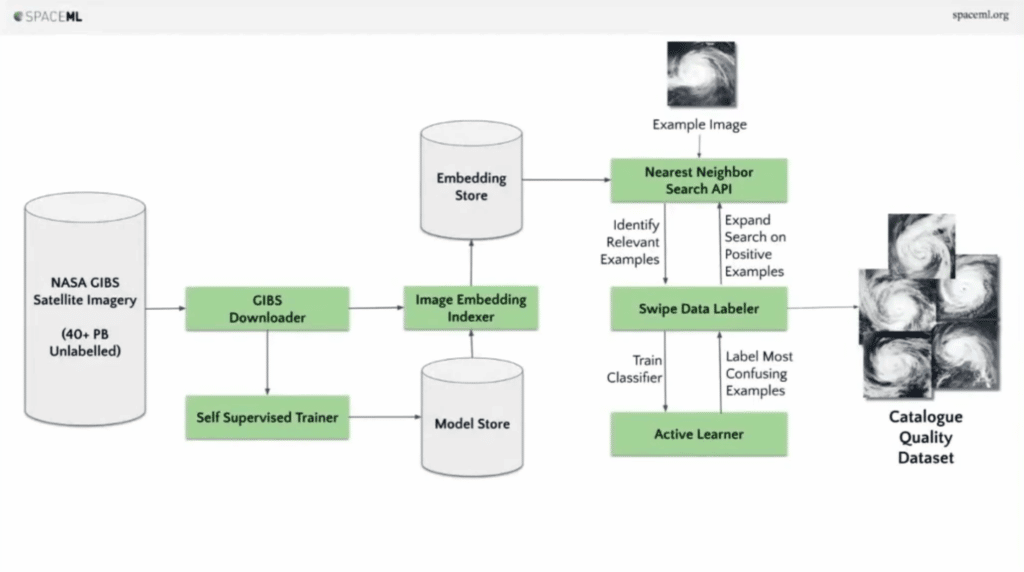
The way we lifted this is with this flow chart of this large system, where you go from the left side—from data collection—all the way to the end. We are given one example. We are able to generate an exhaustive set of all examples.
Alright, I’ll take you through this. Don’t worry [that the] flow charts are too big. TLDR, all those unique modules are available online and you can mix and match them for any computer vision problem. That’s how it goes.

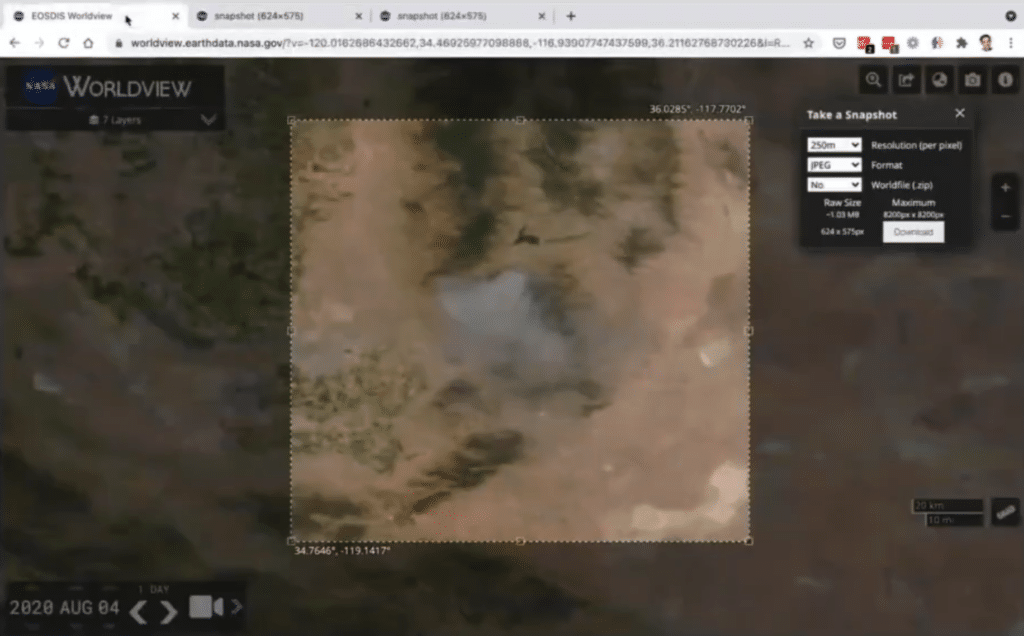
Let’s say when we started, it turns out that downloading data from NASA is work. So we built a simple tool to access any of the satellite imagery. All you do is you go on a command line and essentially write one line telling the starting and the end date, the coordinates, and it just downloads it on your machine.
We want data to be great for … as one of those ways to format the data. So the training speed, [the] performance of the system, in the later part.
And maybe, you are somebody who uses TikTok a lot, and you really want to talk about climate change. So you say minus-minus-animate, and it just starts animating the earth around us. This is the example from California from 2020. Easy to … … that can be used by anybody in the command line.
So now that we have the data, we now do what we’ve talked about, the theory: self-supervised learning. And to do that, you literally write this single line.
Python train.py, and give it the path to all your images. And it just starts doing what it does best: training a network. On the command line, really high performance, and behind the scenes it can even scale to multiple GPUs. And, in case now you happen to have a few examples, which are labeled, you could then use another command to train a supervised classifier. So, take a bunch of images, hundreds of thousands or millions of images, to train a self-supervised model, and then you can, with a few labeled examples, train a supervised classifier.

This is an example. We gave it one day of earth data, 128 into 128 kilometer tiles. And it started to make some sense. Like, when you go from the bottom to the top, the “wetness” increases, because it’s the ocean at the top and the deserts at the bottom. And when you go from left to right, the cloudiness increases, as you can pretty much see.

But if you were smarter than I am, you could use more pre-processing in it and essentially remove the clouds. And when you remove the clouds, we get a finer-grained understanding, basically, of the system. That’s nice.
We also need the system to be very high performance. We don’t want… if you are not a deep-learning performance guru, don’t worry, the system automatically tries to be high performance. Essentially, we are able to train a bunch of this stuff on Google Colab free notebooks. Thanks Google. And this shows the power of having efficient systems.
So now that we have downloaded the data and trained a model, you want to keep it in the model store. Makes sense.
Once you have the model store, you want to then pass all the data through this model to generate these meaningful embeddings. So each image, which is a big image, is essentially now stored as a tiny embedding. Makes sense.
And then finally, we use … there are many open source approximate nearest neighbor search libraries. ANNbenchmark.com, I think, has a whole bunch of testing done on many open source libraries. Scan from Google is currently the leader in the number of queries it can handle and add the speed. As well you have from Facebook, FAISS. You have NI from Spotify. So you can use any number of those libraries. The trick is, divide and conquer. What you do is, you take your data, depending on the resolution, depending on the date, and depending on the product—if it’s an infrared product or if it’s a product which is RGB—you divide and conquer and create embedding indexes of each one of those.
During search time, depending on the image that’s passed in on the user’s parameters from first date to the last date, you can then load those indexes quickly and serve the user. So, divide and conquer is a way to scale on the cloud.
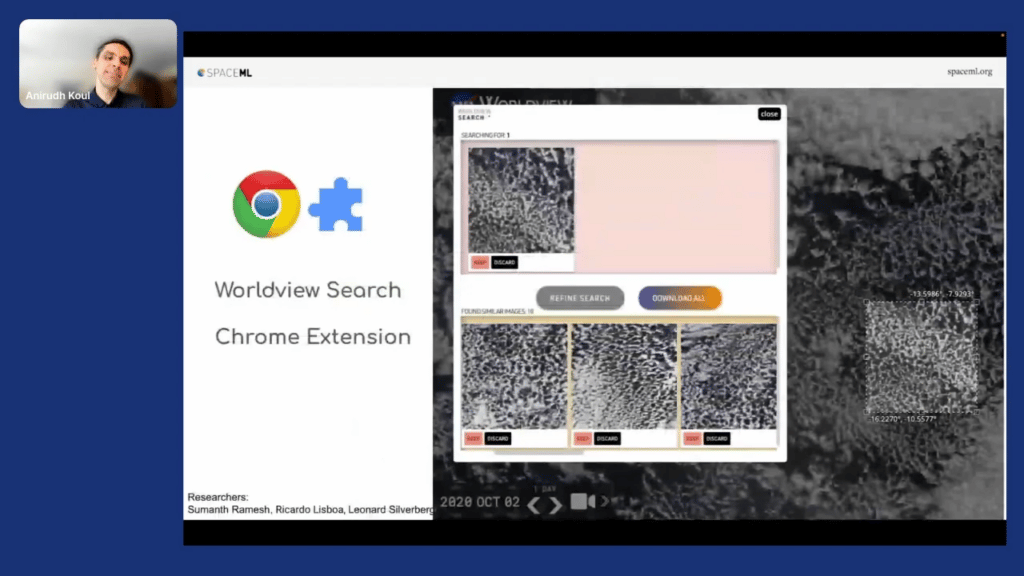
And then, finally, you want the user to have a great experience. So the way we did this is we built a Chrome extension so that most of our users could download it and try this out. By the way, you might be noticing the names of the researchers who did the work are at the bottom of my slide, so thanks to them.
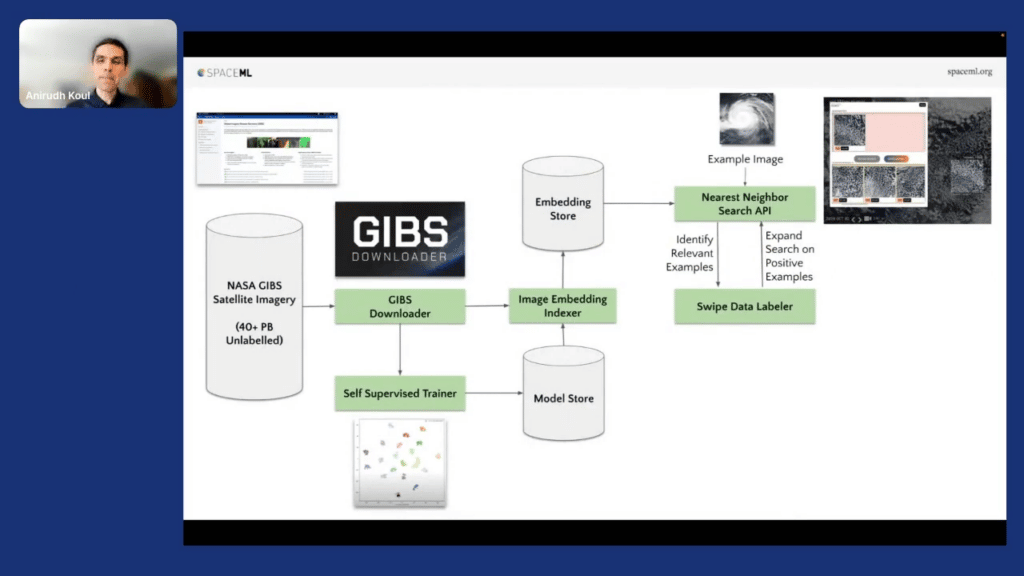
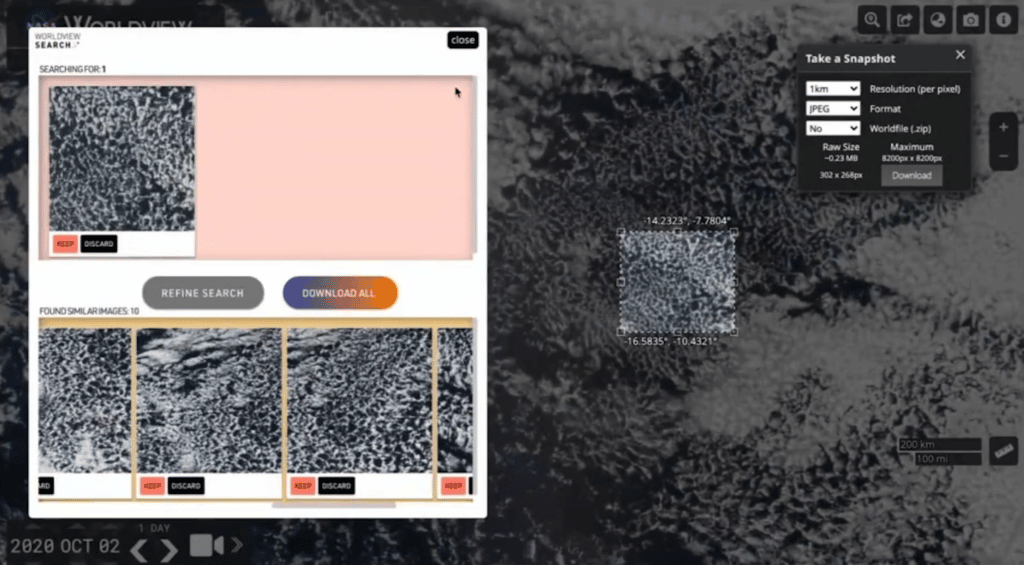
So this is great. So far what happened is …. Nearest neighbor search API, we are able to return many similar examples of the same kind. That’s great. So you go from one image to maybe 50, 60 images—again, unlabeled.
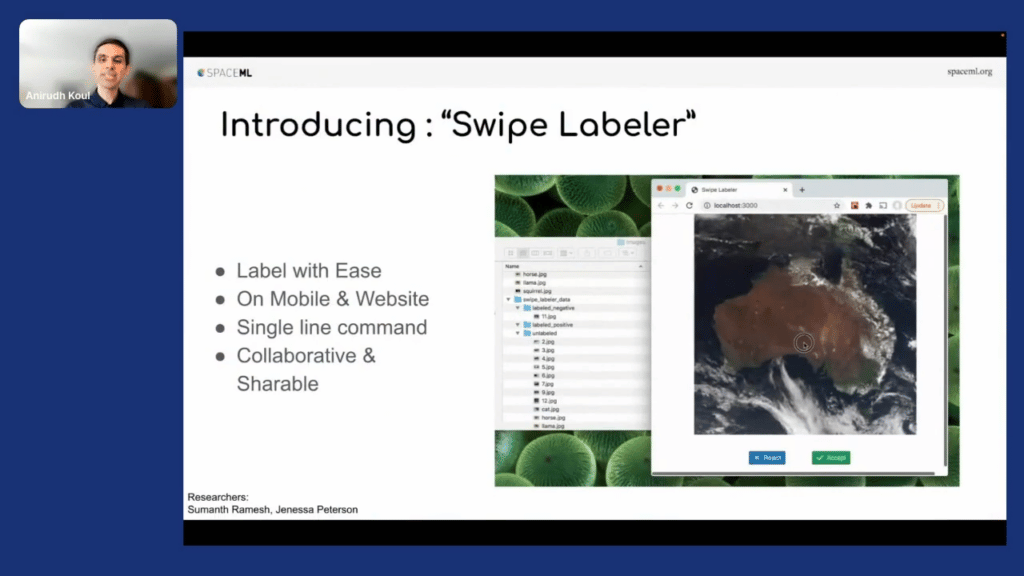
But maybe it’s a good time to label data. So for that, what we did is we built “Swipe Labeler.” Think of this as “Tinder for NASA,” because essentially a researcher can take this on their laptop, put the images in the “unlabeled” folder and start swiping right or swiping left to indicate whether this is what they cared about or what they didn’t care about. And even better, we realize researchers are not networking experts. So, essentially you can run it on a mobile [device]. More importantly, it gives you a link that you can share with your friends and colleagues. Now you can get a party of people labeling the data in front of you remotely.
Alright, that sounds like a great idea. So we are able to take an image, search similar images—say 50, 60—and then take those images and label them “left” or “right” to know: is it what the scientists wanted or not? Now, let’s say we had 30 positive images [and] 30 negative images—you can guess you can create a classifier here. And that’s where I’m getting at. Could we improve the performance? Because we haven’t found the exhaustive set, we have just found a few images.
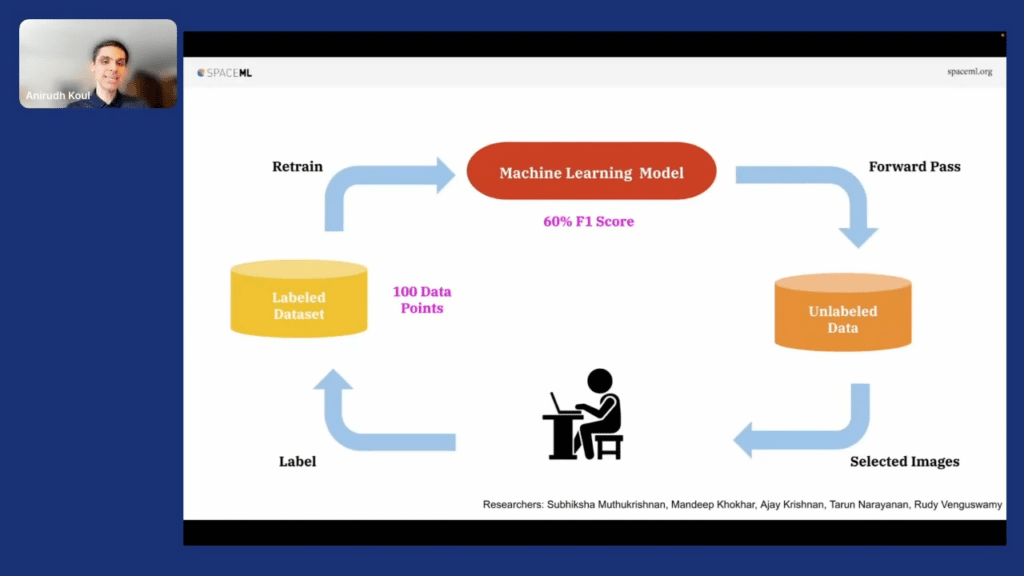
What if we were able to train a classifier first—a supervised classifier—and that supervised classifier could then go over the entire billion-image set and is able to find all the exhaustive images? And that’s what we are going to do.
How do we do this? Firstly, we have 30 positive and 30 negative images. We use a technique called active learning where a few images are labeled, like in the seed. We [then] train a classifier. That model then runs on the unlabeled data and finds all examples that it’s uncertain about and gives them to a human to label. Then these human-labeled images then go back to our label dataset. So, let’s say we have a hundred data points now. We have a 60-percent F1 score. We do another forward pass on the entire dataset, find more images that are confusing, and as you keep going like this round and round, using active labeling with a few labeled examples, we are able to reach high F1 scores.
And that’s great, because our underlying model was already trained. It’s the few dense layers that need to be now trained to be able to build a great model. That’s great.

We did some examples where we took large datasets, which would have taken 38 hours to label and using this, we are able to label that in 2.9 hours. What we interestingly realized is the bigger the dataset gets, the better the performance value that you can get for labeling comes out.
And this is one of the problems with images. Images are slightly less structured. I wish it was text because we could have done much better with a lot of discussion that we had today in the [other FDCAI conference] sessions today.
Now, one last thing. I think the real innovation we found was, if you’re doing this on a 10-billion image set, each forward pass of the classifier takes $30,000 and 21,000 hours. I don’t got that kind of money! I don’t know who has. If you had to do 10 forward passes of active learning to do that, it would’ve taken $300,000. Very expensive.

The idea we essentially came up with was, what if you take this 10-billion image set and you had a small representative sample of, let’s say, 100,000 images. Doing a forward pass on those 100,000 images takes about 13 minutes. And what we do is we keep on finding what we are bad at on those 100,000 images. Once we know what those images are that we are bad at, you then use our nearest-neighbor API to actually find another 100 similar examples. Essentially, you have access to those billions of images while you’re still training on 100,000 because you can use the nearest-neighbor API. I call this access to billions and cost of pennies, and that’s really nice.
We use this example of this one simple image out of 5 million potential images, and we had the job of finding every island on Earth.
So we took this image, and we are able to identify 1,000 islands on Earth in about 52 minutes. Keep in mind, we had literally done nothing 52 minutes ago.

The point here was, if you had manually done this it would’ve taken $105,000. But with citizen-science, we are able to get it done “pricelessly.”

Researchers saw this presentation and without us knowing, they started applying this on Hubble Space Telescope data, on Voyager, and other space missions. And that showed the power of having things available in open source, so anybody can use it, and lowering the bar to entry in AI.
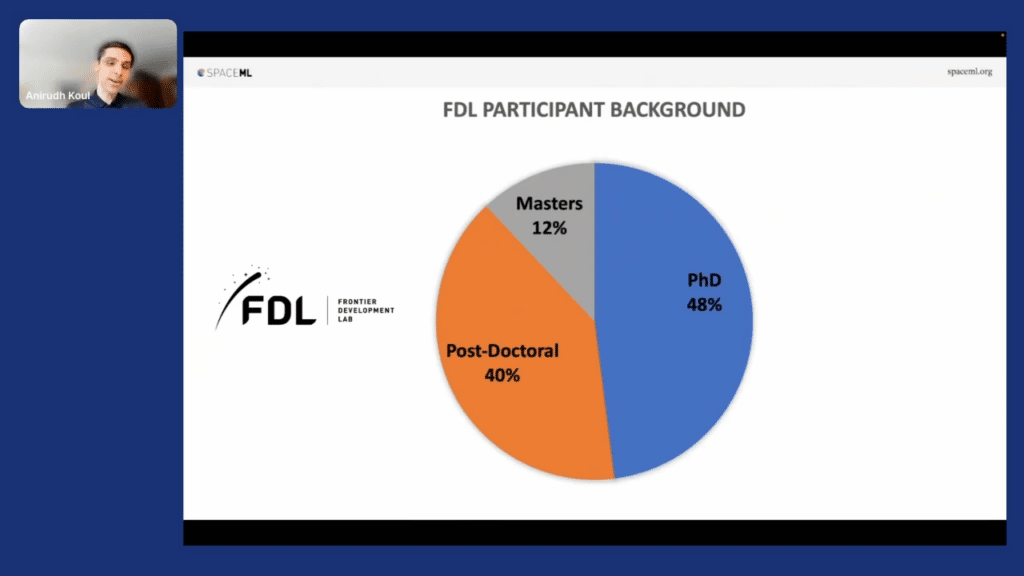
So as I end this, I want to introduce our scientists. NASA has an AI accelerator called Frontier Development Lab. Usually 50 percent of the folks who enter there are PhDs, 40 percent are postdocs. You can see the area here.

All this work actually was done by majority high school students. And this shows the power of being able to devise systems where you lower the bar to entry for people and give them the motivation to do crazy things. You got people from six to seven different countries around the world, and we had people who had never coded in their life, like an English teacher who went on this mission and today teaches data science one-and-a-half years later.
So that’s the power of citizen-science and thank you for listening to me today.
Q & A section
Aarti Bagul: Amazing! Thanks so much, Koul. That was a very “cool” presentation. (Sorry, had to do it.) And, I mean there’s a lot of excited comments in the chat as well, but with people saying that it’s been incredible work. Very interesting as well. So thank you so much.
Now we’ll take on some questions. We have a question from Nick that says: very impressive imagery work coming out of NASA. Maybe you touched on this, but are you using an approach like SIMCSE for semantic text similarities?
Anirudh Koul: I think there are groups who are trying to use similarity-for-text and even combining image and text for matching things. Just an interesting fact, there’s a collection of papers—over 100,000 papers—that are presented by these scientists and they actually mentioned the dataset and sometimes the image we associated with it.
So if you knew that, could we have joined them together to learn concepts and make it available for people? There are people who are doing that good work. I’m not that person.
AB: Amazing. But that’s good to know that maybe there are techniques that are transferrable or people are doing that work and the datasets at least exist. Opportunity there.
Another question: one of the PowerPoint images had clouds on one of the sides, and the right-hand side had a cloudless image. How did you determine that the area below was a water body and, like, a desert, let’s say.
AK: Yeah. So keep in mind, with self-supervised learning we don’t know what this image really means. It’s for the human to interpret at the end of the day. It just happened that when the system started clustering the images, it started to make some sort of a sense. And that kind of shows that the model actually makes sense, that it has started to pick up the concepts of how to transition from small sites to the other sites. We had some really great examples, that if we were able to zoom-in 5X inside these [images]—which even I can’t do here—those little examples of different kinds of forests, as they were transitioning towards the more “ocean” side of things, that we are able to essentially get out of this.
So I think I’ll take this as, the system is smart enough to be able to get that once you have enough numbers of images.
AB: Got it. A related question, somebody’s asking about, what about mountains? Because the top in square feet is too high and then that’s covered by clouds. So I guess in general, maybe how weather conditions and the time of the day that the photo was taken affect this system?
AK: Certainly. So here’s a great example, and this is a really good point. You could take the image of a piece of land today, and the next month, and say that this is essentially the same. You know, “Hey, self-supervised gods, figure out why.” So that’s one example that you could also use for training a system like this.
So you’re spot-on, the system has to become robust. We actually provided both kinds of examples. And in case I was breaking up while I was presenting, it might be because I’m actually at the top of a hill at 10,000 feet. That might be the reason.
AB: Got it. Got it. Amazing. I just wanted to double click on some of the points that you touched on just to make sure I understood.
You’re doing this self-supervised approach to figure out, basically, if two images are similar, learning the same embeddings, et cetera. Just wanted to make sure I understand. When you then query or do inference, you have so many images to search from to get that embedding that is similar. Is that the nearest-neighbor search API that we’re talking about? How do you even know which images to compare to and make that be as efficient as possible?
AK: This is why we say beg, borrow, steal. If somebody has done the work, why don’t you just reuse that? So the whole area of approximate nearest-neighbor search is built for, not being, like, a 100-percent-accurate method to find similar things, but generally things with some level of guarantee, like 80, 90 percent. Finding those examples in sub-millisecond latency. In our example, we actually made it in two different ways. One way was, if you have a million images or under, a researcher could run this on their own laptop and be able to do this.
But if you have deeper pockets, you could use one of the templates we have on the cloud to be able to essentially run this with a much bigger thing. And the whole point is that you don’t even need to know, behind the scenes, what AR programming is .
AB: Oh, cool. I think you may be cutting up slightly. Oh, okay. Now you’re back. Okay. Yeah, got it. So it’s sort of reusing that work.
I guess one related question, but tangential, something that Dylan was talking about too. The dimensions of that image do matter sometimes, because, if the image is too small, everything would look similar. If it’s too large, then obviously, then there’s compute implications. So how do you make that trade-off between image size and then also just the speed, and how did you land on the optimal level there?
AK: Excellent, excellent question. I’m so glad I’m in the room where people are thinking about exactly the real problem!
I can go two angles, right? So the one was an excellent way of doing it, and that’s how you do face recognition or face detection. You usually use some sort of a pyramid network because in an image the face could be small or big, right? So that’s one way of doing that. But the amount of time it will take to debug and really make it work would be like a stretch goal.
So maybe let’s take the world and actually divide it into tiles which are 1,000 kilometers, 500 kilometers, 256 kilometers, 128 kilometers, and build multiple resolutions of it and just label it. It will cost more. But, usually people who are searching might have some idea of how big things will be. So hurricanes, for example, are usually not going to be 500 kilometers, 500 miles or bigger. So we know which area to like, click it in.
AB: Got it. So it depends on what you are trying to detect as well as, it does help to experiment a little bit to see what the optimal size could be, maybe is what I’m hearing.
AK: Exactly.
AB: Okay, perfect. So, unfortunately that’s all we have time for. If people do have more questions, I know you had your email up at the end, if you could just flash that up so that people can reach out if they have more questions. Really interesting work. So, thank you so much for sharing that with us.
AK: Thank you, and hope you all have a great day!
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Team Snorkel