New Snorkel benchmark leaderboards. See the results.
Named entity extraction and recognition with Snorkel Flow
If you were ever amazed at how Google accurately finds the answer to your question just by a few keywords, you’ve witnessed the power of named entity recognition (NER). By quickly and accurately identifying different entities in a sea of unstructured articles, like names of people, places, and organizations, the search engine can figure out each article’s main topics and entities and recommend the most relevant one. NER also has some other practical, real-world applications. For example, the ability to quickly identify and extract key elements from a loan agreement, like the borrower’s name, amount, and repayment date, helps financial institutions sort swiftly and index many complex documents. Without this, a significant amount of manual processing would be needed to navigate these documents. Despite the large volume of research papers and open-source models for this use case, data science, and machine learning teams often struggle to find the best solution for NER tasks because of the sheer complexity and variety of the documents that need to be processed. Snorkel Flow’s data-centric AI approach to application development offers a much easier and scalable pathway to building high-quality AI applications to extract named entities from various types of documents.
My journey building named entity recognition applications
Since the beginning of my career as a data scientist, I’ve been focusing on Natural Language Processing (NLP). I’ve often come across the need for information retrieval tasks focused on named entities. In the beginning, I was encouraged by the fact that a large number of pre-trained open-source models were available for NER. I hoped to use these models and get a satisfying score with minimal development. After a few iterations, I quickly realized these models didn’t “transfer” that well to the complex real-world dataset that I often had to deal with. For example, a large language model trained on Wikipedia articles usually doesn’t perform that well on a financial dataset with many domain-specific vocabularies or on a poor-quality dataset with many spelling errors. In these cases, I’d have to complement these pre-trained models with other custom models, regex rules, or even hard-coding modifications that are often hard to manage. Another challenge that I always had to face was handling different subject matter experts’ input. When I encountered domain-specific data, such as public 10-k filings, I often had to rely on accounting experts to do many hand annotations to make my models more robust. But when I had a single Jupyter Notebook instance, there was no way to manage all these inputs and get my model deployed efficiently.Given this experience, I was excited when I found out there’s a solution to manage all these resources, get my data labeled, and model trained without a mess. Snorkel Flow, a data-centric AI platform, can bring all the signals from these different data sources together in one platform (pretrained models, regex rules, crowdsourcing annotations, and more). It allows data scientists and subject matter experts to collaborate and develop an AI application that is more adaptable to business needs.
Labeling functions to replace manual labeling
The Snorkel AI team has spent over half a decade researching novel techniques such as weak supervision and programmatic labeling to automate training data creation at Stanford AI Lab. Snorkel’s core research has been published in over 60 academic papers and deployed by organizations like Apple, Google, Intel, Stanford Medicine, and many more. It is part of the data science curriculum at several leading universities. Snorkel Flow productionizes the concept of programmatic labeling around a data-centric AI workflow. Users author Labeling Functions (LF) to label named entities programmatically instead of annotating them one by one. These Labeling Functions, designed to help Subject Matter Experts (SMEs) express positive or directional signals of what a named entity might be, can be simple or as complex as needed. They can be simple regex rules that encode the pattern of a named entity or results from pre-trained models or open-source tools like NLTK or Spacy. These different supervision sources are combined to predict a labeling decision. Underneath the hood, Snorkel Flow’s Label Model denoises these labeling functions and creates a probabilistic and versioned set of labeled data.
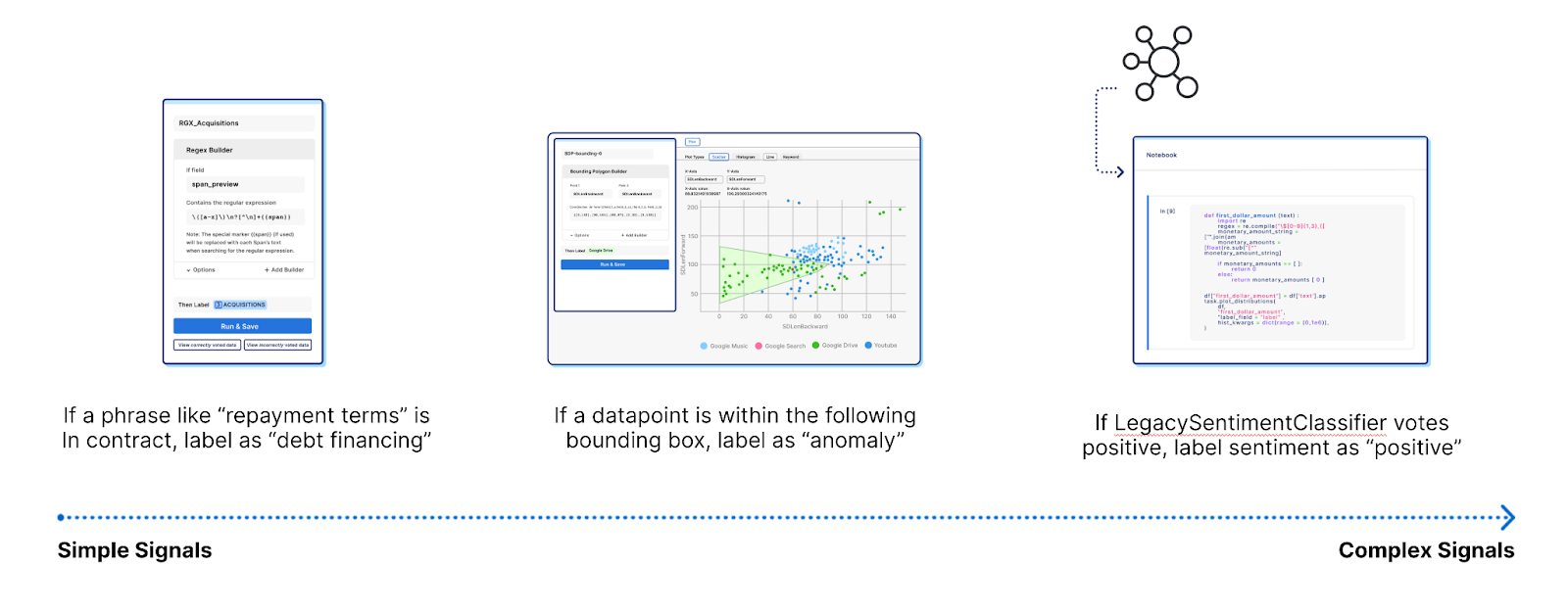
Model training with flexible options
After the labels are created, a machine learning model can be trained either in or outside of Snorkel Flow to generalize beyond the named entities already labeled. Snorkel Flow provides various model options such as Scikit-learn, Transformers, PyTorch, and custom models that can be brought in via the Python SDK.

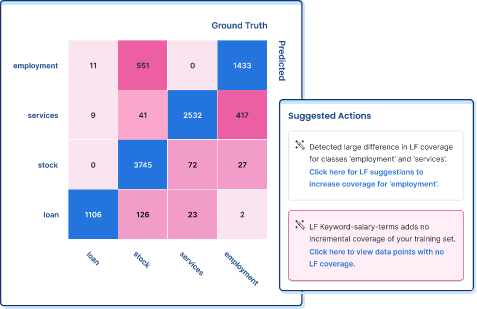
Error analysis to audit data quality and model performance
Snorkel Flow’s error-analysis tools provide greater visibility into data quality and model performance upon training. It provides unique next-step recommended actions for both model and data iterations. Should the model be iterated or the data? If it’s the data, which Labeling Function should be changed? When named entities are labeled by hand, there’s no way to trace back the annotator’s thought process behind each label they provide. This is especially hard when labels are ambiguous (e.g., “Paris” can be either a city or a person’s name). With Labeling Functions, every training label can be traced back to the auditable functions, which provides greater auditability into data quality.
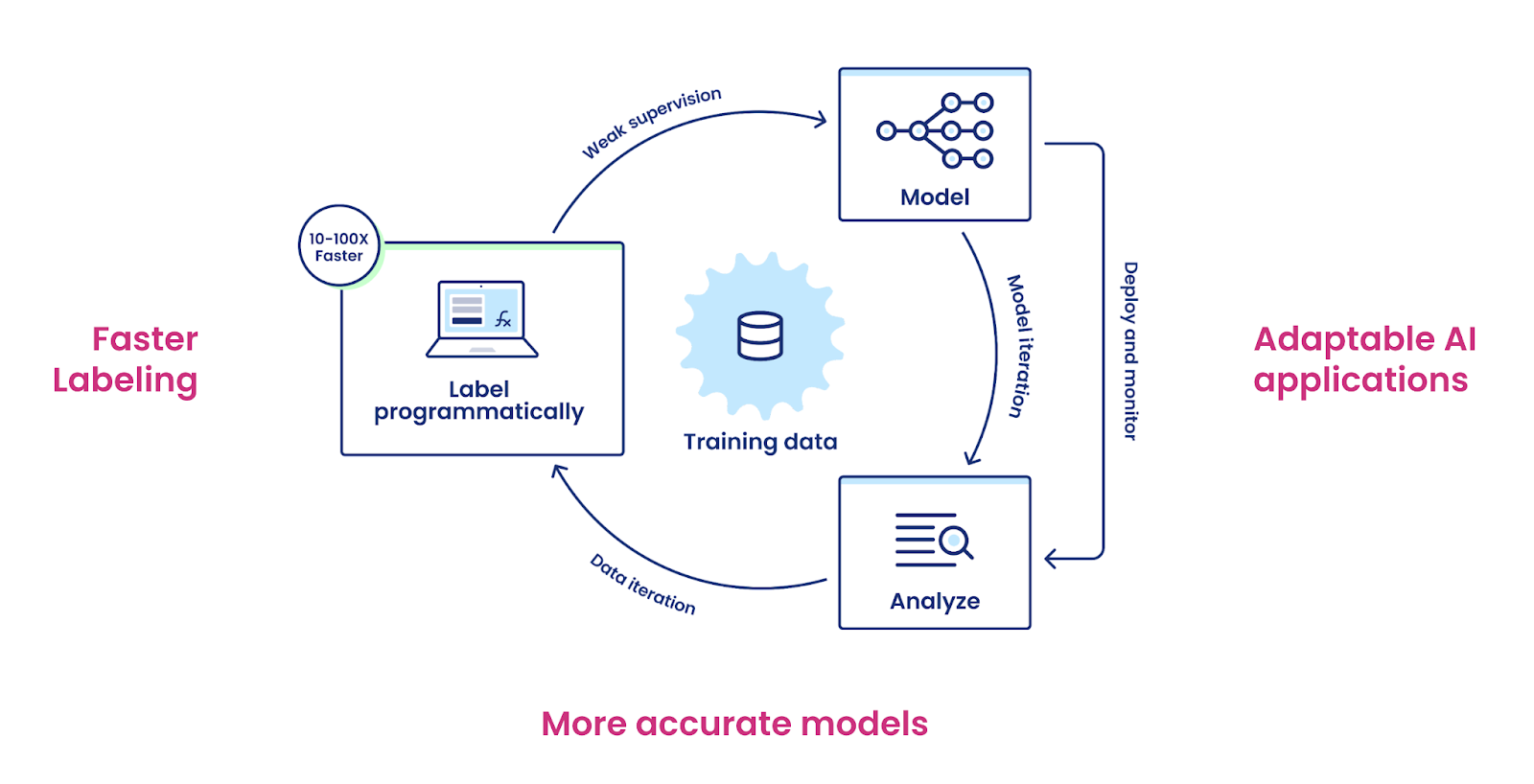
Iterations to drive adaptation
In contrast to the traditional waterfall machine learning development cycle (data collection → data processing → model training → deployment), Snorkel Flow allows iterations through the entire process to make sure models adapt to data drifts or new business needs. Instead of manually reviewing each affected data point, Snorkel Flow allows businesses to recreate training labels programmatically by modifying a few labeling functions and kickstart a new model in a drastically shorter amount of time.
Final thoughts
As a data scientist who has struggled with data labeling, I wanted to provide some insights into how I used Snorkel Flow to do NER. To be able to quickly extract named entities from long, complex, and/or private documents with programmatic labeling replaces a lot of wasted manual time and provides a valuable foundation for other tasks downstream. To be able to help companies get the most out of their unstructured text data and free people of many hours sitting in front of a computer, debating if Paris is a city or a name, is probably one of the most rewarding parts of introducing Snorkel Flow to these types of use cases for me.
Interested to learn more about Snorkel Flow? Sign up for a demo and follow Snorkel AI on Linkedin, Twitter, and Youtube.

April Guo