New Snorkel benchmark leaderboards. See the results.
MLOps: Towards DevOps for data-centric AI with Ce Zhang
The future of data-centric AI talk series

Don’t miss the opportunity to gain an in-depth understanding of data-centric AI and learn best practices from real-world implementations. Connect with fellow data scientists, machine learning engineers, and AI leaders from academia and industry with over 30 virtual sessions. Save your seat at The Future of Data-Centric AI. Happening on August 3-4, 2022.
In this talk, Assistant Professor at ETH Zurich, Ce Zhang, discusses how he and his team developed data systems that will significantly aid the DevOps process of data-centric AI systems. This presentation is summarized below. If you would like to watch Ce’s presentation, we have included it here as well, and you can find the entire event on our YouTube channel.
Over the last couple of years, Ce Zhang’s team has been working to understand how to build data systems to help the DevOps process of data-centric AI systems. Over the years, the team has been looking at how different users build machine learning applications, and two observations govern our research. Machine learning is applied to an increasing number of applications and developed by many individuals—as a result, machine learning models are built by people with less experience in computer science and machine learning but more excellent domain knowledge, which is a good sign. Variables such as diversified hardware and data environments, evolving machine learning algorithms, restrictions, and needs beyond model accuracy contribute to the rising complexity of developing and deploying machine learning systems.
Looking at these two trends and what everyone has today, it has never been easier to build a machine learning model than it is now. On the other hand, it has become difficult to answer critical questions such as whether a model is good or poor and ways to improve a flawed model. The main challenge is how to give users systematic “step-by-step guidance” for the development and operational aspects of machine learning.
“How do we construct ML Systems to help users enforce them even if they are not experts?”
Ease.ML: “Software Eng. 2.0” for “Software 2.0”
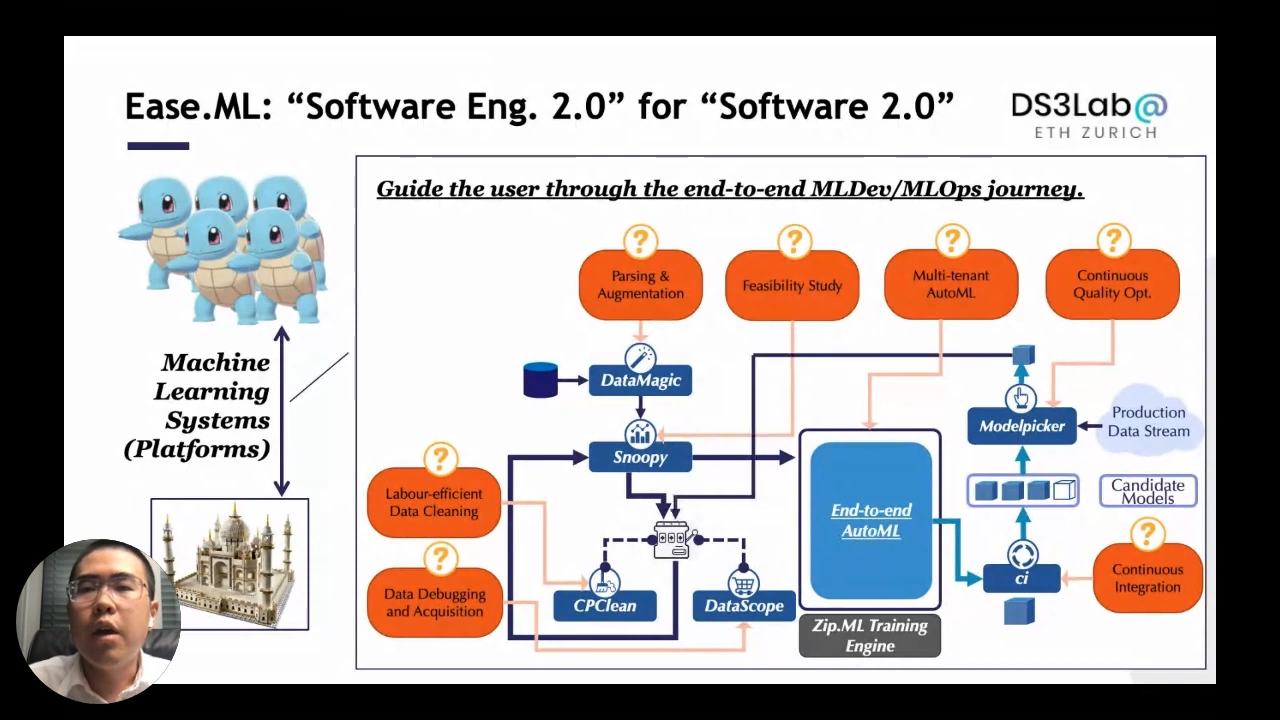
Ease.ML is an end-to-end process of development and operational journey of machine learning applications that starts from the data and goes through multiple stages. One or more solid research projects back up each stage.
Stages:
- Data parsing, augmentation, and injection
- Feasibility study to understand if the data quality is good enough before running a model
- Data cleaning, debugging, and acquisition to improve the data quality
- Multi-tenant AutoML system giving a stream of machine learning models
- Continuous integration and deliverables like the array of machine learning models
- Constant optimization of model quality and adaptation gave the protection data stream
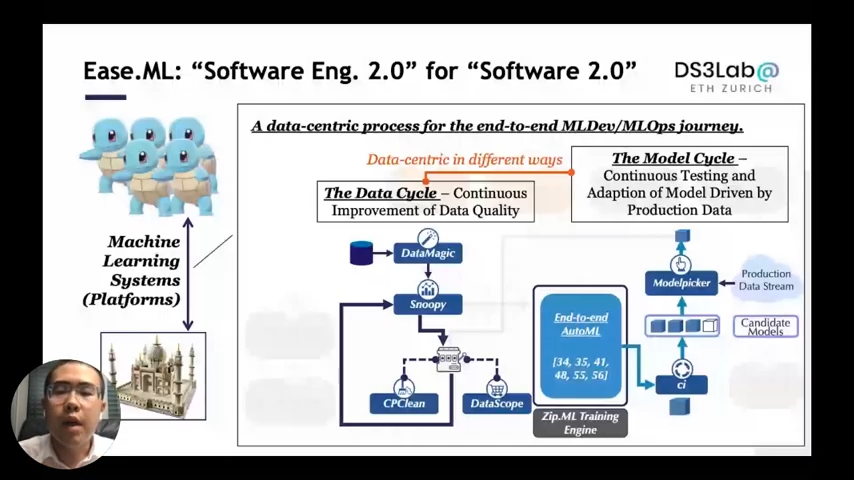
The above end-to-end procedure appears to include two cycles. The first cycle is called “The Data Cycle”; it refers to the continuous process of increasing data quality through data cleansing or data acquisition. The second cycle is known as “The Model Cycle.” The model with an autonomous system generates a stream of models, which are then continuously tested and adapted based on production data. The two cycles are “Data-Centric” but in different ways.
Let’s talk a bit about what “we know” over the last couple of years, the things that we don’t know, i.e., “known unknowns,” and with the students that we didn’t even know that certain kinds of problems existed, i.e., “unknown unknowns.” We are here to ask for help from the community to help us to understand how to do this even better. Each of these components are driven by some questions that we want to help our user to know, so the first question is if you have data artifact training data, and what is the best accuracy that any machine learning model can achieve on this piece of data.
Feasibility Study for ML
Machine learning problems are frequently divided into two components. The first is a data problem, and the second is a model problem. The purpose is to assist the user in pressing the signal to pull them apart, and when the labels are inconsistent, is it possible to build a system to assist the user in detecting that?
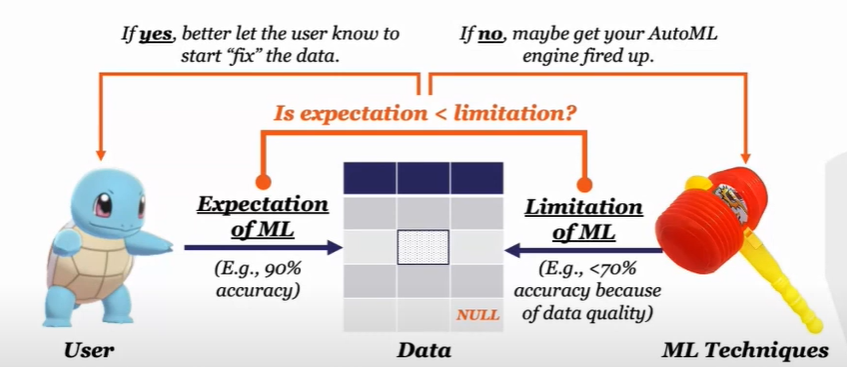
Consider the following: we have a user, a dataset that may contain several issues such as missing values, noise, and machine learning technology; nevertheless, these three components interact in two ways. The user comes in with some expectations, such as getting 90% accuracy on this piece of data; however, machine learning technology also comes in with limitations. There is no way you can gain accuracy higher than 90 due to your data quality issues. To understand this, check whether the expectation is lower than the limitation of machine learning; if the answer is yes, the user should spend time fixing the data; if the answer is no, perhaps it is better to conduct machine learning on this piece of data. So the aim is to figure out how to verify this situation as soon as possible. Let’s talk about two things concerning this situation; what we know and what we don’t know.
Feasibility Study for ML: What do we know?

When training and testing data from the same distribution, we know how to discuss this problem. This goes back to a traditional problem called the “Irreducible error,” which is essentially trying to ask what the base error rate is on this dataset? Assuming we have two definite feature spaces, and then if you look at this small packet, assuming you have a lot of red labels and only a few green labels. Looking at the cell, we have to make the “green many” errors because even the best classifier can only make some deterministic prediction, which is optimal in this case. The integral of the whole space gives the base error that measures what the best motional model can ever present on this data set.
We know that many factors need to be addressed to take the theory and convert it into a practical system. Hence, the first question is which estimator is the best and how can we compare them given all other estimators. This is difficult to grasp since all estimators attempt to predict the Bayes error rate, yet the actual Bayes error rate is unknown for most real-world data. How to compare all of the estimators if the real answer is unknown? The second question is, how can all of those Bayes error estimators be improved? To do so, first, divide the dataset into numerous datasets, then do a Bayes error estimation on each of them and select the minimum. Surprisingly, this is a crucial method for obtaining a superior Bayes error estimate.
Feasibility Study for ML: Known unknowns
We have no idea how to go beyond the view of base error and accuracy. What happens when the training distribution is different from the testing distribution? This could happen whenever we have big supervision, and we have no idea how to model such a problem or go beyond accuracy. It is unclear how to have an F1 score or an AOC and deal with various utility functions such as robustness and fairness. There is a lot of exciting stuff that might happen in the future.
Data debugging with ML
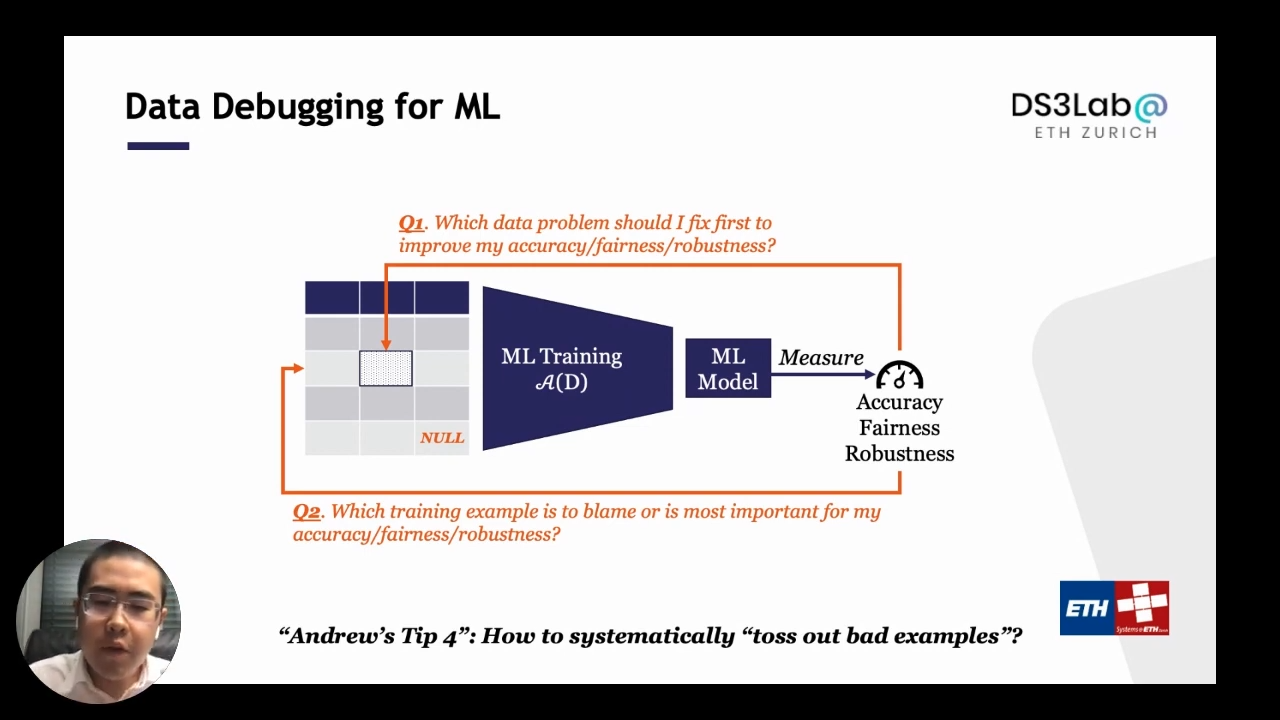
Assume there is a training set with several data issues such as missing values and noise. Train various machine learning models to find the best model, then evaluate with some utilities such as accuracy, fairness, and robustness. Now it turns out that the trained model is not good enough. When there are faulty samples in a dataset, the typical method is to determine the systematic approach to urge the user to look at those terrible instances and eliminate them immediately. Users are unaware of what machine learning is, and the aim is to implement this step as a systematic capability within the system.
What’s the most important data problem that I should fix in my training data?
There are two significant issues to consider. The first issue is that there is a lot of data noise in the data example, and not all of them are equally relevant if cleaning is necessary, i.e., which one should we pick to clean? The second issue is determining which training example of blaming or a poor example for final utility. How to answer these two questions systematically? There is much research done to answer these questions. For question number one, there is a lot of research about how to measure the entropy or expectation, and also there is some greedy-based method that tries to figure out which example to clean. For the second question, there is a lot of work about expecting marginal improvement and the gradient-based view of how to do infinite functions. However, they are not relevant in real-world applications.
Looking at a real-world machine learning pipeline, they are not simply straightforward. There are only tiny components that the user is trying to train a model, and the majority of the program is about data processing. It is a data transformation pipeline on the features. If we want to reason about a bad example, we have to reason about it jointly. This is something we have no idea about, we lack a fundamental understanding of how to connect two different communities. The data management people and the data science people try to understand how to talk about those pipelines. On the other hand, we have been thinking about reasoning data in person to analyze an end-to-end machine learning pipeline in the machine learning community. We have no idea what’s the answer, but we have been trying to do a little bit of work to understand a pipeline. Essentially, a “feature extraction pipeline” between data and model training is introduced, and then the above two questions are attempted to be answered. The challenge is how to compute these essential quantities as quickly as possible. Again, Let’s talk about what we know and don’t know.
Data debugging with ML: What do we know?
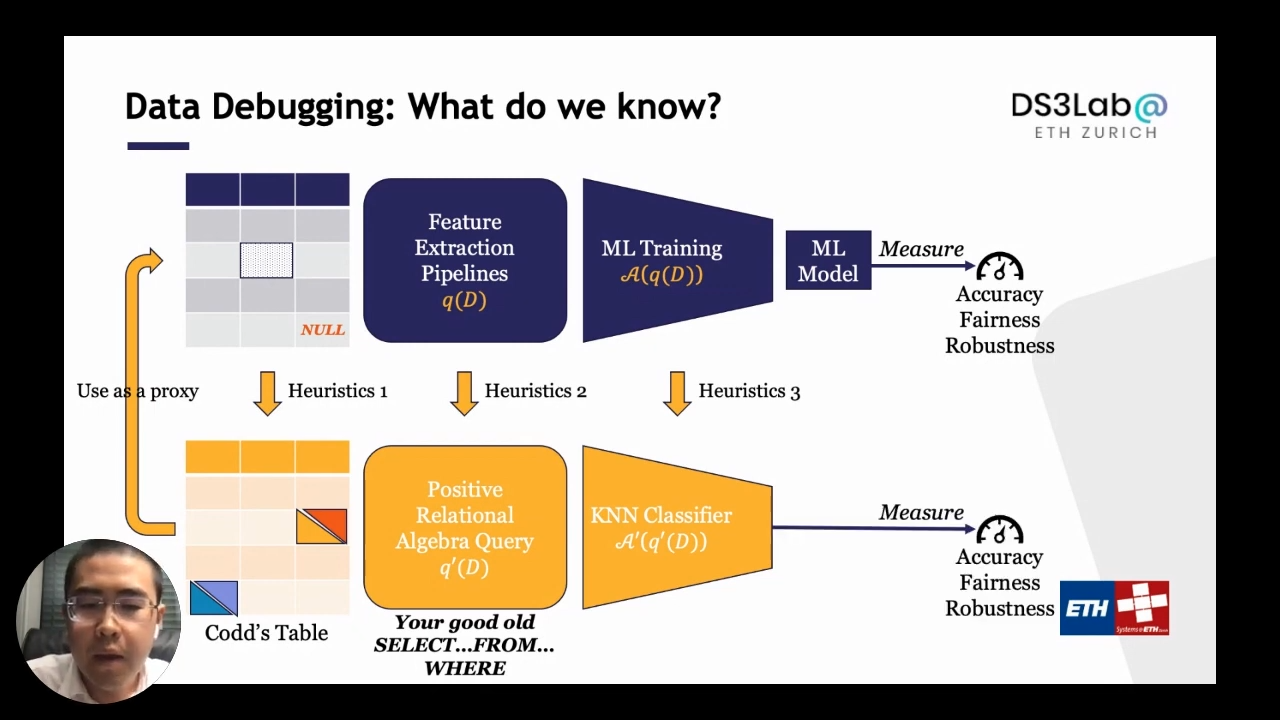
Analyzing the pipeline is tricky, especially when computing fundamental metrics such as entropy. Therefore, considering a “proxy pipeline” with many heuristics such as approximating noise model into a cell dependant model and approximating feature extraction pipeline while just maintaining the prominence can be used. A positive relational algebra query is an excellent old “select … from … where” query. Use the complete proportions to describe the feature extraction pipeline, and approximate the machine learning training process as a simple classifier, for example, the k-neighbor classifier. Then a p time algorithm for many of the fundamental quantities for the proxy pipeline.
It is known that using these fundamental quantities computed on the proxy pipeline can be useful and often work well in many scenarios. This is one application scenario that we have. If you have a data set with many wrong labels on your example, then you train a machine learning model over it. We want to understand how we can find those training examples with the wrong label. In this case, the idea is, if you look at the Shapley value of those examples, they have a minimal Shapley value of a negative shaft. Looking at the proxy pipelines, we can often give you an unclogging algorithm to compute exactly the Shapley value, which can return the Shapley value for all those examples in less than one second for a reasonable data set. This can give you a compelling way to do data debugging.
Data debugging with ML: Known unknowns
We can learn from this proxy pipeline that it does not perform well in all application contexts. For example, if we have two separate populations, one of them is underrepresented; the question is if we can identify those who are already representing the instances to eliminate them and rebalance the collection. The high-level concept may be that cases with very low Shapley values are highly likely to be overrepresented. This is one of the instances where the concept of employing Shapley value works quite well. However, the proxy model that employs the KNN classifier fails. We have no notion of how to respond to how to discuss the machine learning pipeline properly. The correct solution is in the middle, but no one knows what that item exactly is. The second thing we don’t know is how to compute four essential quantities and move beyond the sensitivity style matrix, that is, how to assess diverse group effects.
DataScope is an open-source tool, part of Ease.ML for inspecting ML pipelines by measuring how important each training data point is, in just seconds you will be able to obtain the importance score for each of your training examples and get your data-centric cleaning and debugging iterations started.Bio: Ce is an Assistant Professor in Computer Science at ETH Zurich. The mission of his research is to make machine learning techniques widely accessible---while being cost-efficient and trustworthy---to everyone who wants to use them to make our world a better place. He believes in a system approach to enabling this goal, and his current research focuses on building next-generation machine learning platforms and systems that are data-centric, human-centric, and declaratively scalable. Before joining ETH, Ce finished his PhD at the University of Wisconsin-Madison and spent another year as a postdoctoral researcher at Stanford, both advised by Christopher Ré. His work has received recognitions such as the SIGMOD Best Paper Award, SIGMOD Research Highlight Award, Google Focused Research Award, an ERC Starting Grant, and has been featured and reported by Science, Nature, the Communications of the ACM, and a various media outlets such as Atlantic, WIRED, Quanta Magazine, etc.
Where to connect with Ce: Website, Linkedin
If you’d like to watch Ce’s full presentation, you can find it on YouTube. We encourage you to subscribe to receive updates or follow us on Twitter or Linkedin.

Team Snorkel