In this episode of Snorkel ScienceTalks, Sebastian Ruder, Research Scientist at DeepMind, shares his thoughts on making AI practical with Snorkel AI’s Braden Hancock. This conversation covers progress made in the NLP domain with emerging research, new benchmarks like SuperGLUE, rich repositories and news sources that keep you in the loop and on top of what’s new in NLP, and more.You can watch the episode here:
Below are highlights from the conversation, lightly edited for clarity:
Can you describe your path into machine learning?
Sebastian: Throughout high school, I was generally interested in languages – learning and understanding different things about both my native language, German, and other foreign languages. At the same time, I also enjoyed math and, more generally, analytical subjects. I wasn’t sure what to pursue between these two paths for a while.Through sheer luck, I came across a small bachelor’s program in Computational Linguistics at the University of Heidelberg. The degree’s focus was on understanding the formal linguistic theories of syntax and semantics. We also combined that theoretical work with programming on the side. Towards the end of the degree, while looking around future options, I came across the increasing interest in machine learning at the time. The emergence of deep learning and its practical applications sparked my interest initially.Like many people deciding what to do after undergrad, I faced the choice of going into industry or doing a Ph.D. down the line. I initially planned to accept a role with a startup doing Natural Language Processing to get hands-on experience. But by serendipity again, I came across an industry-based Ph.D. program that combined industry and academia. In the end, I decided to go for that option, which has led me to where I am now.
You run one of the most popular newsletters on NLP. Tell us about NLP News.

Sebastian: I wanted to create a medium that fills the gap between the rapid, anecdotal communication on Twitter and the rigorous, scientific communication in conference publications. I also wanted to make that information accessible in a regular cadence. That turned into the NLP News newsletter, which has been going on for almost two years. It is a compilation of trends or highlights from machine learning in broad and NLP in particular. The number one source of information for the newsletter has been Twitter, which is an accessible forum where you can have 1-on-1 conversations with leaders in the field.
“Twitter is a great venue, particularly for people new to the field, to get your feet wet and connect with people. It feels like the ultimate, ongoing 24/7 poster session.”
Sebastian Ruder
Research Scientist at Deepmind
What progress has been made on the NLP front that has been most fruitful for the ML community?
Sebastian: It depends on your measure of fruitfulness. Looking objectively in terms of the number of citations and general interest accumulated, I favor general-purpose benchmarks like GLUE and SuperGLUE. They essentially test general natural language understanding by evaluating models on multiple existing benchmarks and looking at the scores’ averages. They can be credited with driving the recent progress in unsupervised learning and representation learning in NLP.Additionally, I would also point out any datasets that:
- attempt to test interesting model capabilities, or
- identify settings where current models under-perform and collect high-quality data for such settings.

I maintain a repository for datasets and ML state-of-the-art called NLP Progress. The good thing about NLP Progress and similar repositories, like Papers With Code, is that they help you explore and surface datasets that you might not have been aware of before. This whole space of modeling and understanding language is so vast that it enables so many tasks and applications–from standard ones like recognizing text entities to more esoteric ones like classifying different content on forums in the dark web, extracting information from tables, or generating languages based on football reports.It’s cool that there’s a wide space of possible tasks for people interested in settings that have not been studied before and who want to improve that niche. That has a lot of value in and of itself, even though it might only be of interest to a smaller subset of the NLP community.
What have you seen that works well in NLP for low-resource languages?
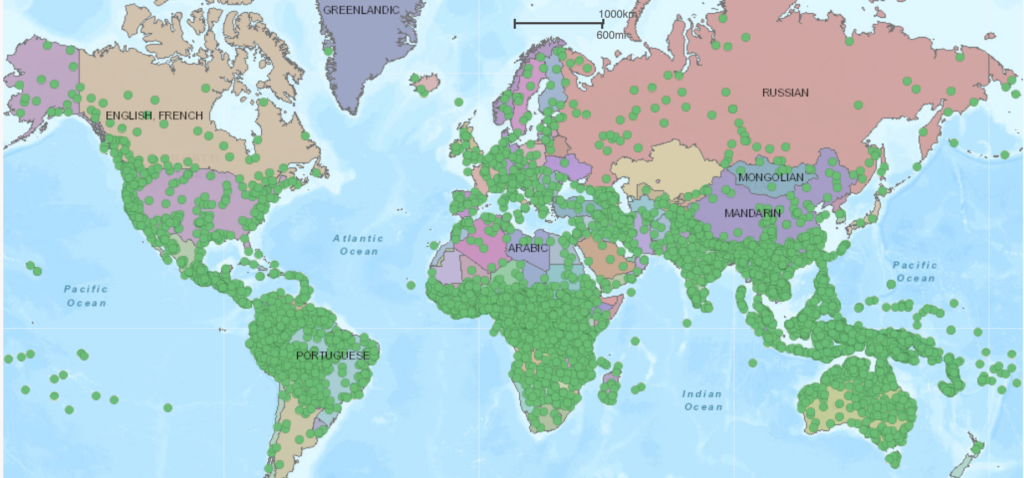
Sebastian: It’s surprising how existing large, pre-trained Transformer models, trained on large amounts of texts from the web, can perform well in a zero-shot setting, even though most of the training data is in English.Recently, people have trained models not only in English but also in many different languages. They don’t explicitly tell the models the correspondence between these languages. Still, the models can capture the language understanding to some extent reasonably well when they are trained on one language and transferred to a different language at test time.There is another reason why I think working on multilingual NLP or cross-link learning is exciting. The space of human languages is so vast, and you encounter many different phenomena – making it hard to capture them all. In a recent paper, we focus on a challenging language transfer setting. First, the model has not seen the language during pre-training. Second, the model has not seen the script of that language.
“Generally, a lot of languages in the world are written in Latin script. Even if a model has never seen that language before, it might still be able to infer some knowledge based on its understanding of cognates – words with similar meanings.”
Sebastian Ruder
Research Scientist at Deepmind
If you have completely disjoint different scripts, however, you can’t simply do this kind of lexical transfer. For these under-studied languages in NLP, if you apply a multi-lingual BERT model, you will get random performance because the model won’t be able to decode anything. Thus, you need other strategies to deal with this issue.
What are the emerging trends in NLP?
Sebastian: I am excited about improvements in the evaluation of NLP methods – moving beyond a single evaluation metric like accuracy to fine-grained analyses of model behaviors. This would be very relevant in the multilingual setting, where we have a lot of languages and can’t do error analysis properly. Therefore, having a more fine-grained objective or general measure to diagnose model performance is crucial.In addition, it’s very hard to collect data in general. Approaches such as weak supervision that require little human effort are valuable. As NLP scales to more tasks and applications, evaluation paradigms become crucial for these approaches.
What have you been reading lately?
Ian Banks’ “Culture Series” and Steven Erikson’s “Malazan Book of The Fallen”
What would your alternative career be?
Sebastian: Being a journalist or being a lawyer.Writing the newsletter satisfies the journalistic tendency a bit. On the other hand, I’m glad that I did not choose to be a lawyer. I’m averse to conflicts and disputes, and enjoy way more collaborative community efforts. Being a researcher is a much better fit.
Where To Follow Sebastian: Twitter | Website | NLP News Newsletter
And don’t forget to subscribe to our YouTube channel for future ScienceTalks or follow us on Twitter.

Recommended articles
View all articles

Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration
June 25, 2026
•

Agentic AI evaluation: Closing the gap with better benchmarks and data
Alex Ratner, co-founder and CEO of Snorkel AI, spoke at @Scale: Systems & Reliability about one of the most underappreciated problems in AI deployment: our ability to measure agents has been outpaced — arguably for the first time in the history of the field — by our ability to build them. The talk digs into what it actually takes to close that
June 23, 2026
•
Snorkel Team

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•
Snorkel Team

