Carlo Giovine is a partner at QuantumBlack, the AI practice at McKinsey, where he also leads QuantumBlack Labs. Together with David Harvey, an engagement manager focused on scaling deployments and applied R&D at that same firm, they presented the session “Trends in Enterprise ML and the potential impact of Foundation Models” at Snorkel AI’s 2023 Foundation Model Virtual Summit. A transcript of their talk follows. It has been lightly edited for reading clarity.

Carlo Giovine: Today we’ll be sharing our point of view on what we see as trends in enterprise ML and the potential that we see for foundation models to change the industry. We’ll discuss the trends of AI in the enterprise, and how it is going to be evolving in the future from our point of view. We also want to show you how foundation models can unlock value and provide you with some key examples. Finally, we’ll talk about some of the risks and actual considerations that enterprises and executives should keep in mind as they want to venture into AI and start using models.
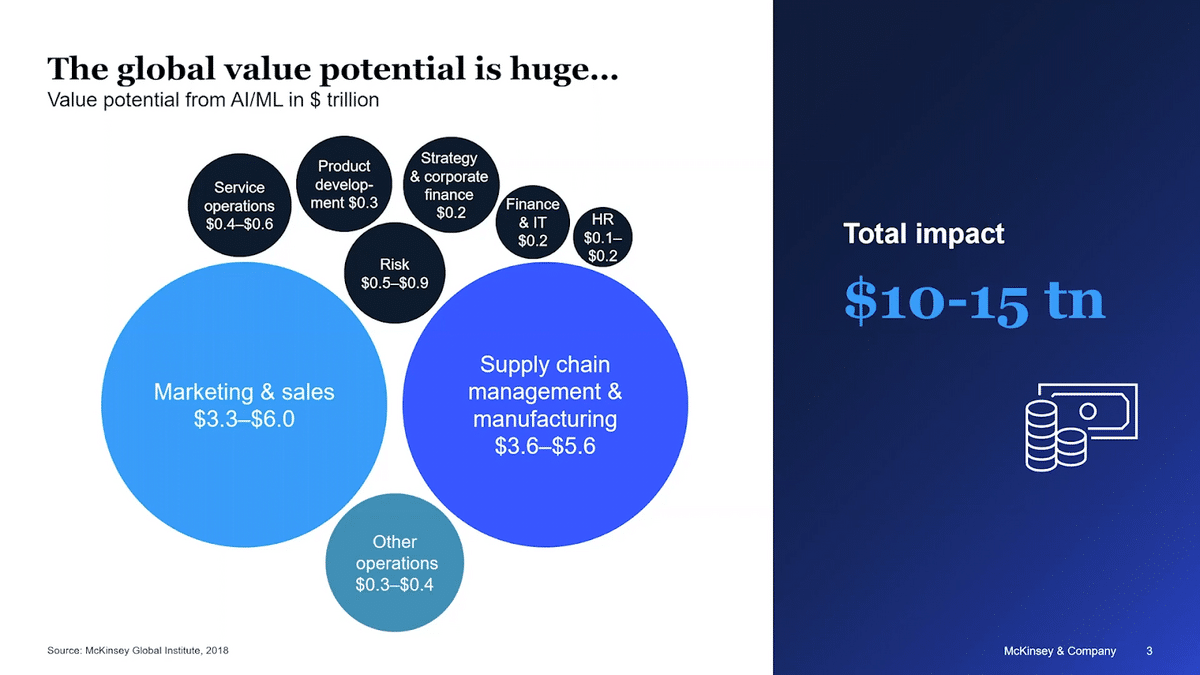
Firstly, what is the state of the industry? In 2018, we did a piece of research where we tried to estimate the value of AI and machine learning across geographies, across use cases, and across sectors. We came up with $10-15 trillion value, which is of course a very sizable potential—with some sectors and business functions capturing a bit more value as compared to others. For example, AI has an outsized value potential on marketing and sales functions, or supply chain management.
Since we published this piece of work in terms of value, we also run a yearly survey with enterprises globally on how they are achieving that value, and how they are scaling their own capabilities. The last survey we ran was at the end of 2022, where we surveyed around 1500 participants. We started to see a few things.
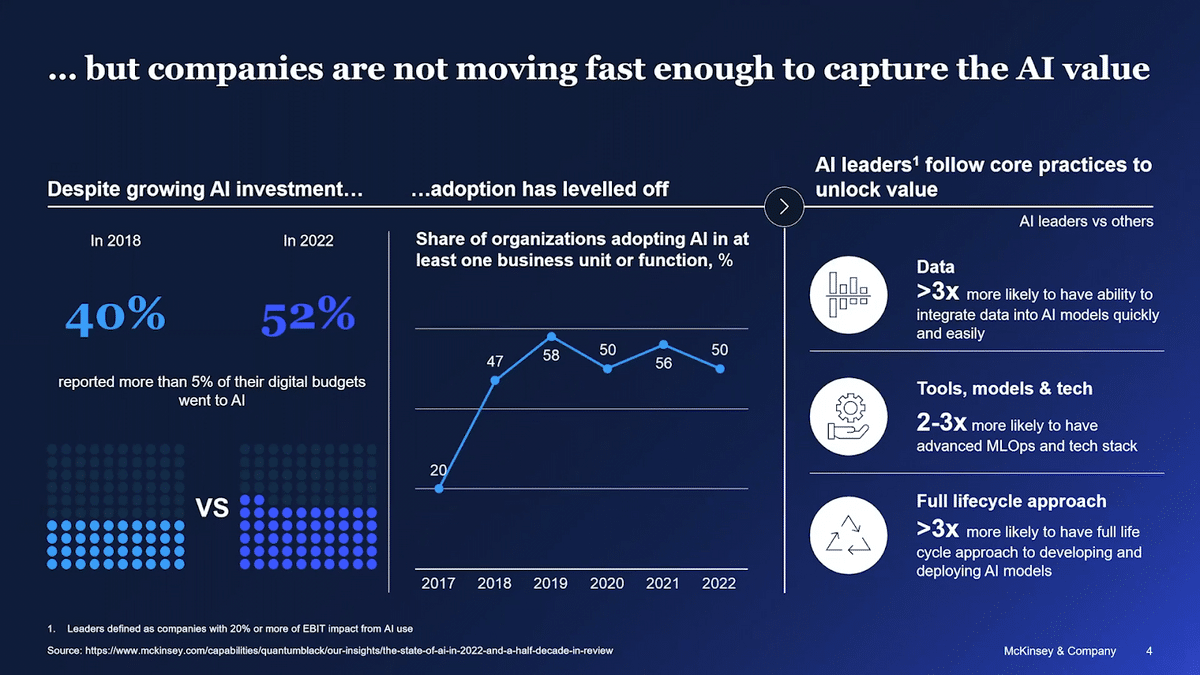
One is compared to our first survey conducted in 2018, we see more enterprises investing in AI capability. Despite this, the business functions where AI has been used haven’t really increased, and it’s leveled off. When we look at the AI leaders, the subset of enterprises that can really unlock more than 20% of their EBITDA with AI, and compare them with the other enterprises, we see gaps and quite a few things that they do differently.
First, they have the ability to integrate data into models much, much quicker, and much easier. The second difference we see is on the platforms. They use more modern MLOps stacks, and some of them have embraced the cloud quite extensively. The final difference, which I think is as important, is they have a full cycle approach. They don’t think about building POCs or small deployments, they think about “how do we build, deploy, and maintain models in production, and how do we embed those models into business processes?”

As we see the gaps, we have also been reflecting on the three things that we see as the industry moves forward and the biggest trends.
One is data-centric AI and the shifts from the model-centric to the data-centric development and deployment life cycles. This is the idea that data becomes the place where companies or enterprises need to invest more and more, and they are.
The second is the actual maturing of the MLOps, or the ML tech stack and ecosystems. We still see the industry developing newer and newer technology in some places, but mostly they’ve been stable. With cloud infrastructure really moving up the stack and creating more and more platforms for enterprises, some platforms scaling and taking more share of the industries, we can see this piece of technology actually maturing quite nicely. Lastly, LiveOps is where we can see enterprises building capabilities not only in the development but also in the maintenance of the models they build and create.

When we started to think about what is happening with what are essentially foundation models, we saw that the shift they introduce accelerates each one of those trends. For example, in terms of data-centric AI, we need less data for training and a small set of human-annotated data can actually increase the performance of the model. Companies are really rethinking data as their own competitive advantage. They understand now that it’s not about hiring the best scientist possible to build the best models, but that data is what is going to differentiate them from the competitors, which leads to wanting to protect this data even more in the future.
In terms of the tech stack, foundation models will help enterprises access larger models. There is a revolution of industry between models that you can access via APIs versus models you can access openly or via open source. We continue to see enterprises wanting options and APIs still hold some complexity, which Dave will actually correlate later in this talk. Additionally, the idea of the MLOps ecosystem and being able to facilitate some of the fine-tuning and prompting approaches that foundation models need for task-tailoring and increased accuracy.
Lastly, I think foundation models will bring simplicity in LiveOps. We need, for example, less models for a number of NLP (natural language processing) tasks in the enterprise. At the same time, we’ll also complicate them because we can all imagine that monitoring accuracy or the actual performance of foundation models may be more complicated because you don’t have a single output metric that you are monitoring.
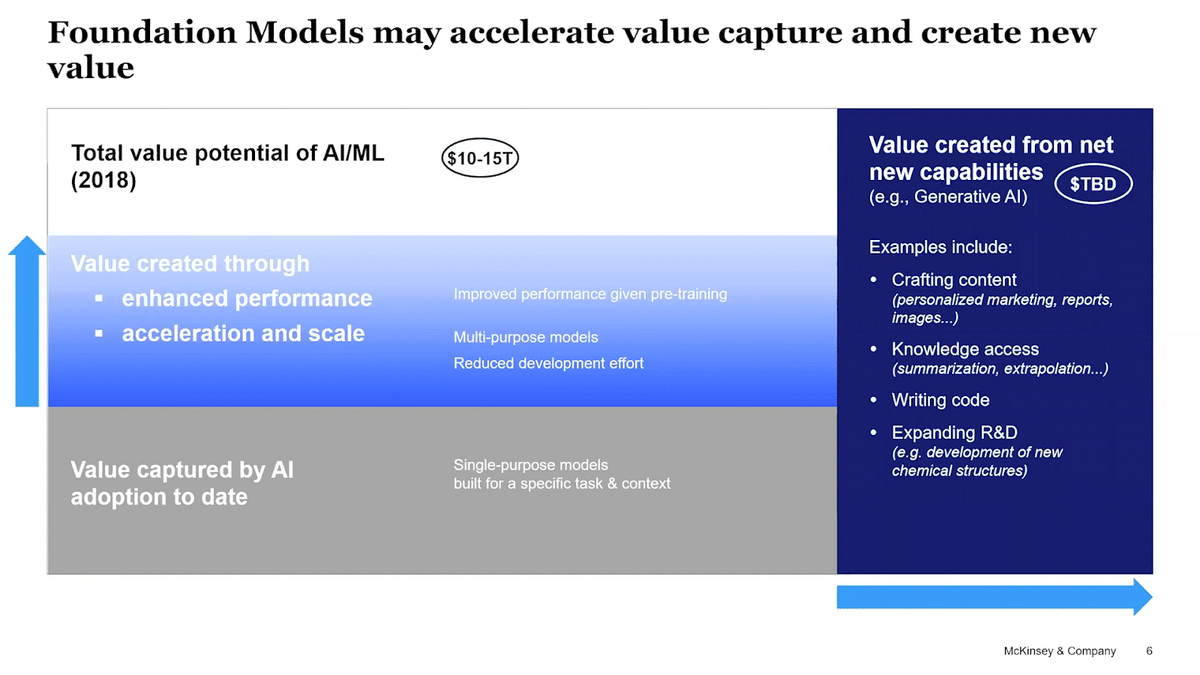
When we start reflecting back to the idea of “value”, we see there is already a portion of value which is captured by single-purpose models that have been built in the enterprise world. These models have been trained to solve a very specific problem, and they’ve been fine-tuned to get the most accuracy out of them so that they are valuable for their business to achieve the outcomes that they need. Foundation models will essentially accelerate the capture of the total value by enhancing the performance of the models that have been already deployed, as well as expanding the reach of models within the enterprise, becoming multi-models that can cover more. More importantly, we could also already imagine a new set of problems that before were not possible and the foundation models can solve. At this moment we’re thinking, “what are the additional value pools? What additional value that we now can unlock that we couldn’t really imagine four years ago?”
Some use cases are crafting content and marketing enablement. AI knowledge access and writing code are changing the way engineers work, which we see with the numbers of Copilot adoption. Also, AI is expanding R&D and the ability to explore a much broader space, for example, a new chemical structure.
So, what are concrete examples of companies already using foundation models today, and what are the risks and complexities we see when we think about enterprises moving toward those models? I’ll pass it on to you, Dave, so you can bring us forward.
David Harvey: We’ve looked at these broader trends happening in the industry right now, so let me zoom in to look at how this plays out within an enterprise context. There’s a big promise of value from foundation models. People often ask us, do we see enterprises really capturing that value today? Whilst the answer is that this is early and emerging, there are examples of some very powerful deployments that we see.
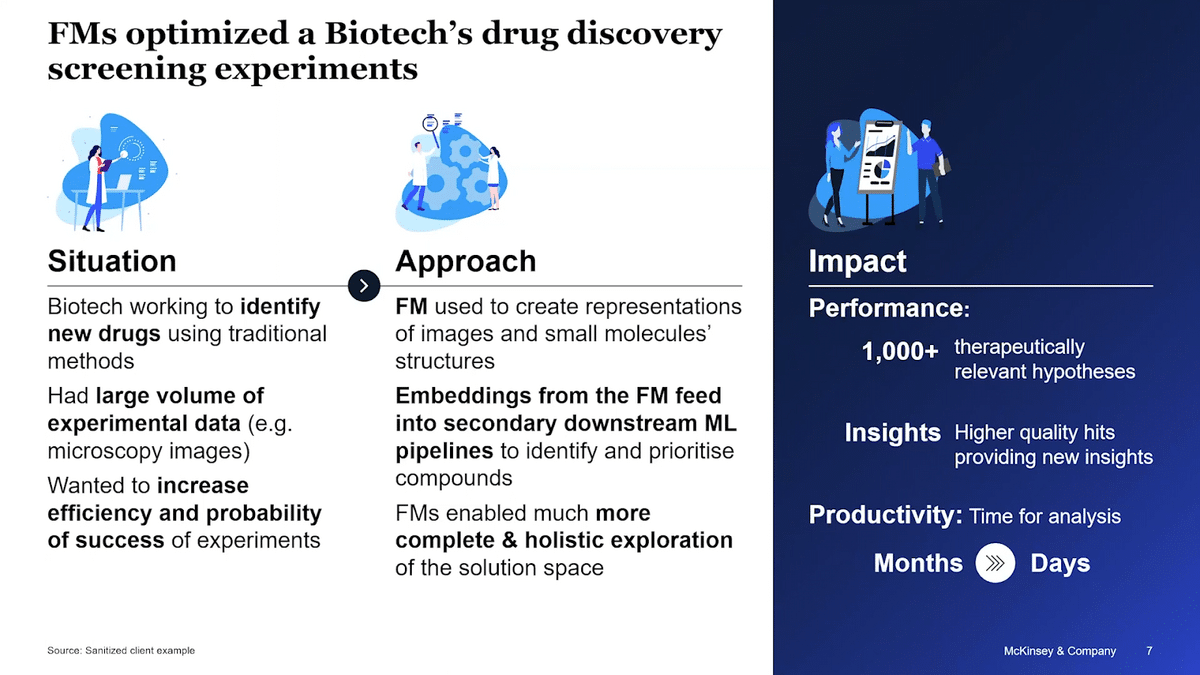
From the biotech space, there was an organization working to accelerate the identification of new drugs. They had millions of microscopy images and small molecule compounds, and they were using traditional feature extraction methods to identify potential therapeutic compounds. These were highly iterative and manual processes which were limited in their capability. They were looking to innovate, primarily looking to increase efficiency and to improve the probabilities of success of experiments.
What did they do? They used image and chemistry foundation models to do the first analysis and create multi-dimensional embedding vector representations of images and small molecules structure. These embeddings then fell downstream through traditional ML pipelines for clustering, for identification, and then prioritization of compounds that may be therapeutically relevant.
FMs are much more powerful than the traditional approach. They were able to do a much more complete and holistic exploration of the solution space. Because of this, they can create far more hits and higher-quality hits. The overall impact shows out in improved performance and improved productivity.
In performance, they were getting over a thousand therapeutically relevant lead hypotheses. These were higher-quality hits with more information, a more informative definition of the phenotypes. These were much more useful for designing successful experiments. In terms of productivity, the automation in this process meant that they went from analysis time of months, a highly iterative manual effort, down to days, plus knock-on benefits downstream in the actual delivery of experiments.
So if the opportunity is big and players are already leveraging these, is this the opening of the floodgates? Will we see foundation models transforming most enterprises by the end of the year?
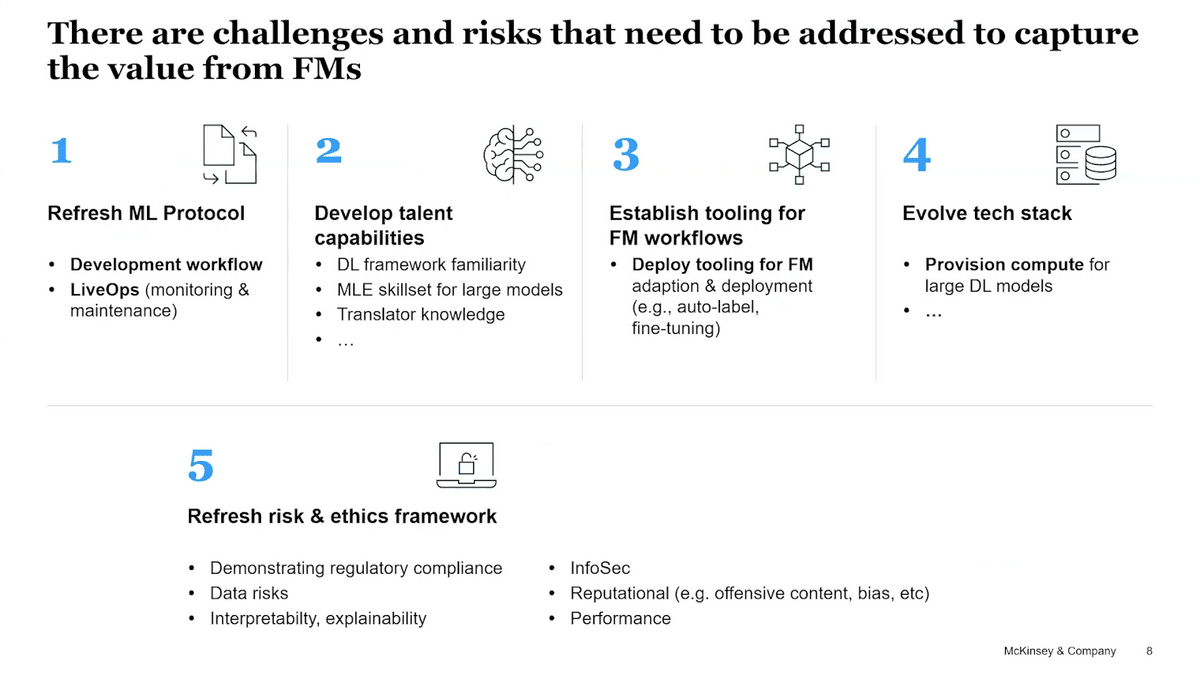
It’s not a simple overnight transition for most enterprises. If they want to leverage foundation models at scale, there are a number of capabilities that need developing as well as a number of policies and risk frameworks that need updating. Policies and risk is probably the most significant piece.
Our ML protocols need updating in several ways. Our development workflows dramatically change from iterative model developments and lots of feature engineering through to prompting and fine-tuning massive models. LiveOps, that monitoring and maintenance of solutions, will change a lot as we move from many small models that we’ve built ourselves to fewer, larger models that we have received.
As our protocol changes, correspondingly our talent capabilities have to update. We need data scientists familiar with deep learning frameworks. We need MLEs who are comfortable navigating and managing the size of models. Our translators, who we’ve spent the last years upskilling and updating, suddenly need to reskill and upskill again for foundation models to be able to identify opportunities and lead projects.
We described earlier the evolution in the ML tooling ecosystem, and that’s only going to accelerate around the foundation model space. Tools to optimize auto labeling, fine-tuning, optimizing model selection—we need to make sure that our people have the right tools to optimize their workflows. Finally, we need to be able to provision sufficient computing power for these large models, both for the training and for serving.
These are capabilities that need work to build and develop, but there are also risks and policies that need updating. This is probably the biggest barrier for enterprise adoption at scale in the near term. The question list is long. “How do I demonstrate regulatory compliance when I didn’t build a model?” “What are the IP and legal considerations?” “How do I manage my data risks?” “How can I fulfill my obligation to explain ability?” “Can I assure performance?” “Can I avoid bias?” The list goes on and on, and it is a daunting list as people start to wrap their heads around it.

There’s a big promise of value and disruption, yet there is much work that needs to be done before most enterprises are ready to deploy these at scale. What should businesses be doing in the coming months as they look to get going? On caveat, of course, this list here is not prescriptive or true for all businesses. But as we talk to our clients, we hear many of them exploring at least these five common questions.
First of all they’re considering where the value is and what this emerging capability means for their value chain for their sector. How big a disruption could this be? How significant could this be for them?
Secondly, they think through their policies and postures to this emerging tech. Is it critical that you are a fast mover and ahead of this curve, or can you afford to be a little bit more cautious and be a follower?
Third, what capabilities and partnerships will I need for the longer term, and how do I start exploring and developing those now?
Fourth, how do I set guardrails and controls that need to be in place to protect trust as I start out and as I move towards scale? Should I start experimenting now, and if so, where do you experiment and what do you learn, want to learn and demonstrate from those?
Now, we were conscious as we put this slide in, there is a danger that this could imply that it is straightforward, clear-cut steps that everybody should be taking. As we draw towards a close, we did want to acknowledge and recognize that this is an emerging and a rapidly evolving space, and that therefore there is much uncertainty.

This is our initial list of big open questions to watch for in the coming months. There are clearly many more on top of this, but there are some that we are gonna be watching and actively working and researching with various partners.
Where will foundation models truly displace traditional models? Where will the performance cost trade-off tip in favor of foundation models? Where will explainability requirements allow foundation model use?
What guardrails will emerge for foundation model use in this rapidly evolving space? What will happen in regulation? What industry standards will be emerging?
We will invariably see many new players emerge, but where will most of them be? Who will the winners be? Will there be many moving in to develop new foundation models? We already see an explosion of startups building applications on top of foundation models, so what will be the changes in the enabling inflow and tooling?
What would be the impact on our workforce, both on our technical practitioners, but also on the whole workforce writ large across the enterprise, if the deployment of these models truly scaled?
This list goes on and on, and we’d love to hear your thoughts on other things that should be shared and added onto this.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.

Recommended articles
View all articles

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•

The Art and Science of Building AI Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build AI benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents with
June 16, 2026
•
Snorkel Team

Cua-Bench: benchmarking computer-use agents on professional software
TL;DR We built a benchmark of 25 expert-authored KiCad schematic-editing tasks and ran a frontier computer-use agent against them. The headline numbers: 1. Why build a computer-use benchmark for electrical engineering? Most computer-use benchmarks today live in the same handful of apps: web browsers, file managers, generic productivity suites. Those evaluations are useful, but they share a structural weakness —
June 15, 2026
•
,

