
The future of data-centric AI talk series
Background
Anima Anandkumar holds dual positions in academia and industry. She is a Bren professor at Caltech and the director of machine learning research at NVIDIA. Anima also has a long list of accomplishments ranging from the Alfred P. Sloan scholarship to the prestigious NSF career award and many more. She recently joined Snorkel AI’s Future of Data-Centric AI event, where she presented an insightful talk, sharing some significant ways to design robust AI applications by looking at how imperfections in data and labels can occur in real-world scenarios.If you would like to watch his presentation in full, you can find it below or on Youtube.
Below is a lightly edited transcript of the presentation.
Imperfection in data and labels
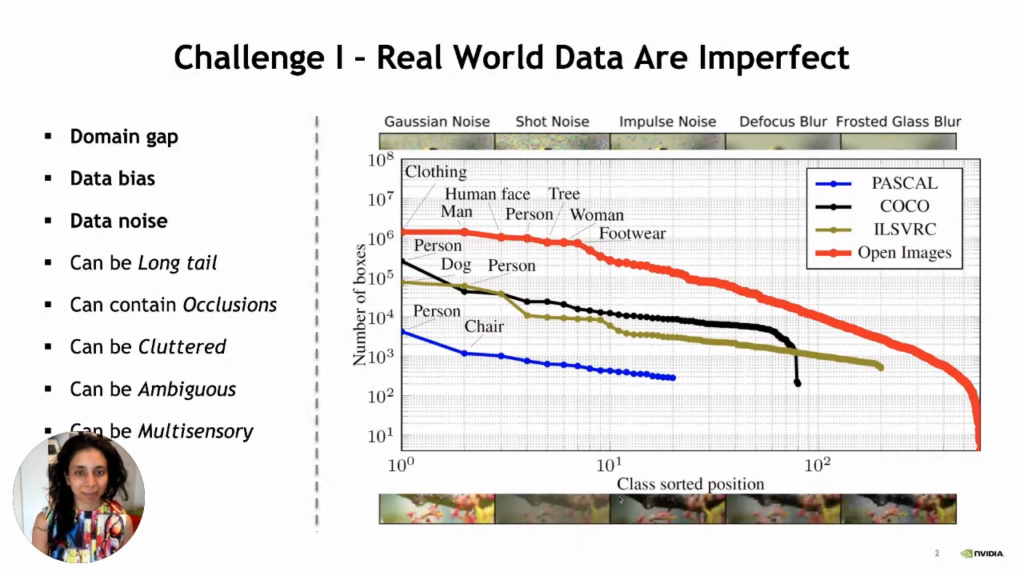
There are many ways in which the data and labels can be flawed. Let us have a look at a few of them.
- Domain gap: We train our machine learning model on a training dataset, but there is much difference between training and testing data in the real world. So, our machine learning model may fail to give results with high accuracy.
- Bias in data: There is more awareness about bias in data than when the world started tinkering with artificial intelligence. The problem with bias is that many underrepresented communities could be subject to societal bias. So, suppose our machine learning models have not seen any data from these underrepresented communities. In that case, there will be a huge problem when we start using such models in real-life scenarios. In addition to that, we must be cautious when dealing with problematic scenarios like law enforcement, where a decision could mean life and death in many situations. So, the question is, if our data has inevitable imbalances, then how are we supposed to overcome this problem?
- Data noise: The data can be noisy for so many reasons like:
- Data may have long tails
- Data may contain occlusions
- Data may be cluttered
- Data may be ambiguous
- Cultural differences
- The laboriousness of manual data labeling
- Carelessness
- Data may be multisensory.
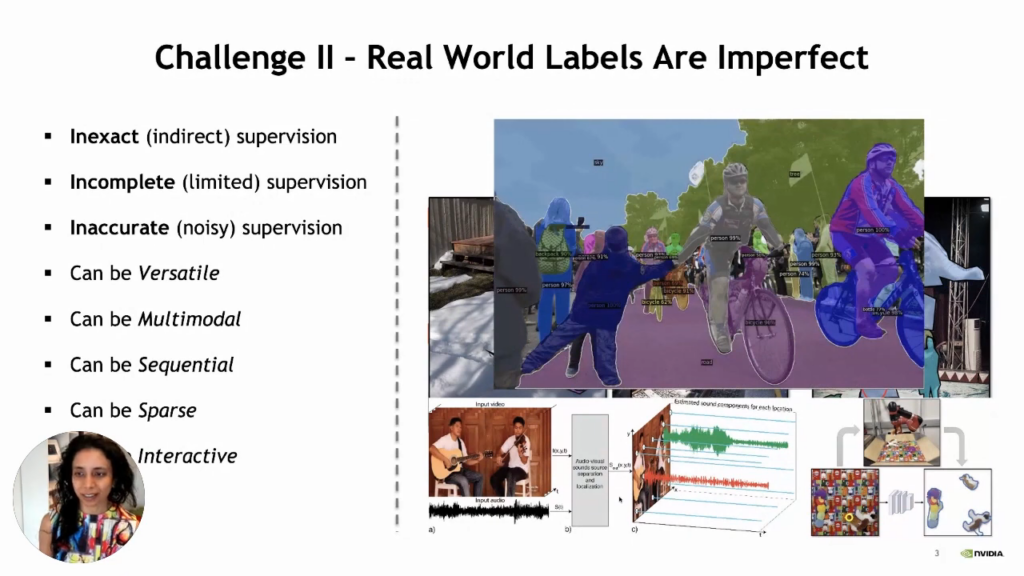
- The real-world labels can be imperfect in the following ways.
- Inexact (Indirect) supervision
- Incomplete (Limited) supervision
- Inaccurate (Noisy) supervision
- Labels can be multimodal
- Labels can be versatile
- Labels can be sequential
- Labels can be sparse
- Labels can be interactive
It is nearly impossible to get the perfect data in this imperfect world. So if we are developing an AI system, we have to find a way to overcome such imperfections in data. We also have to account for the noise in data which can come in many different forms like occlusions, clutters, and ambiguity. When our current labeling technique is not designed to handle a specific type of labeling, we have to use the enormous power of the human brain for such a mundane and laborious task. However, as we know, when humans are assigned a laborious task, it usually leads to some error and can cause ambiguity in our data. Another reason for ambiguity might be the cultural differences between humans. If two persons from different cultures tried to label an image, their answers might differ. Other than that, in some instances like autonomous driving vehicle video, it is nearly impossible for humans to be involved in labeling associated with that. Moreover, it can be expensive too!
Now, we know that it is challenging to label images manually. So, we can say that it will be hugely laborious to label complex segments of videos. It becomes computationally expensive for applications like autonomous driving to label images by humans. So, now the question is, how can we overcome this problem with even no labels? Can we use unsupervised and semi-supervised algorithms to overcome such problems?
We often think about three aspects: how to deal with inexact supervision so that we may have label noise and incomplete data and we do not get supervision of everything. We only have partially labeled data which can also be inaccurate in many ways.
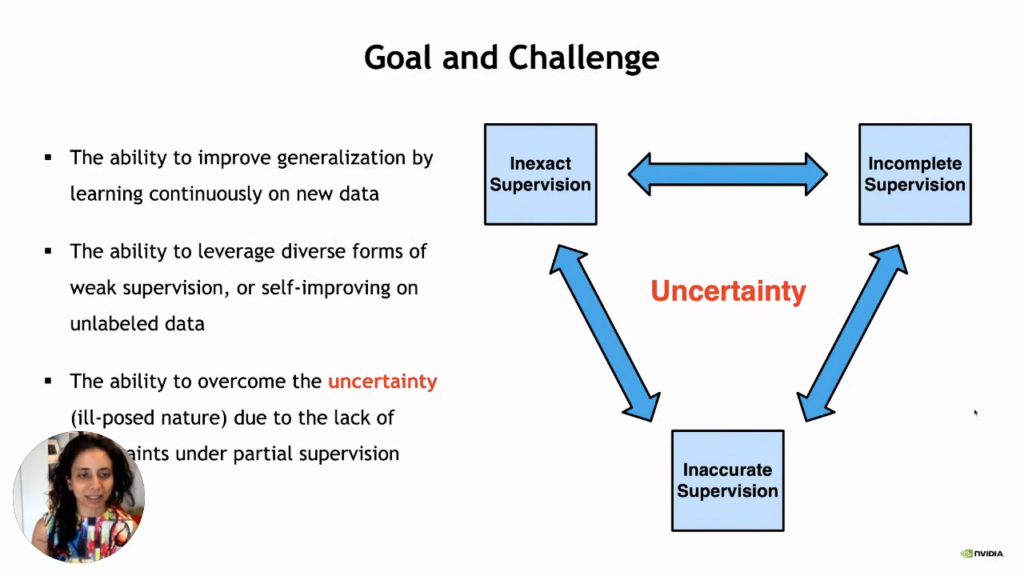
So, here we have the following goals:
- The ability to improve generalization by learning continuously on new data.
- The ability to leverage diverse forms of weak supervision or self-improving on unlabeled data.
- The ability to overcome uncertainty due to the lack of constraints under partial supervision.
Overcoming uncertainties from imperfect labels
There are many techniques designed to get around the problem of imperfect labels and lack of enough labeled data. Self-supervision has been very popular over the last few years, where we are creating supervision based on invariances in data. Using this, we can do different kinds of essential data augmentations like crop the image, add different kinds of noise, and transform the image differently. Next, if we know that the label is invariant to these transformations, we can say that we have created supervision based on these invariances. This aspect has been beneficial in many scenarios. Moreover, self-supervised learning has even beaten supervised learning in classification tasks.
Other than that, there has been much work on what kind of structure in neural networks we should design, and we will see some of the latest transformer architectures that make a big difference in being robust. Even though transformers are data-hungry, having the right design can overcome some issues and provide better inherent robustness. In addition to that, we can provide explicit regularization to overcome the issue of noise. In some scenarios, we have also seen that using angular distances instead of the usual cross-entropy loss can be much more robust.
Moreover, even though synthetic data is still in its infancy, it will be hugely influential in the future. We already see its importance for testing systems such as autonomous vehicles or robot learning. We cannot possibly create billions of runs on the physical robot, so synthetic data becomes essential in these extremely data-limited scenarios. So, we can say that methods that can do synthetic to real adaptation will be critical because there is a huge domain gap.
DiscoBox

DiscoBox is an example of using weak and self-supervision to reduce the labeling effort. The below image is an example of the output generated by DiscoBox. The reason why we call it DiscoBox is because it only uses box supervision. We do not have supervision of any of the instance segmentations. The critical thing to note is that the model was not even trained on this particular video for the output below. It is just directly evaluated by our trained model. However, still, we can see an excellent quality of segmentation.
So, the main idea here is to create self-supervision based on positive and negative bags. We can create positive bags within the box and negative bags outside the supervised box. We can do multiple instances of learning for instant segmentation based on this.
For correspondence, we can have a self-ensembling with a structured teacher. The main idea behind this is that we can look at multiple images through the memory bank and have a refined instant segmentation based on our trained model. We can then create differentiable Hungarian matching laws to create correspondences across images. Now, we can have dense correspondences of how objects in one image correspond to objects in the other. So, this mechanism helps us get richer information with just a box supervision.
Synthetic to real adaptation
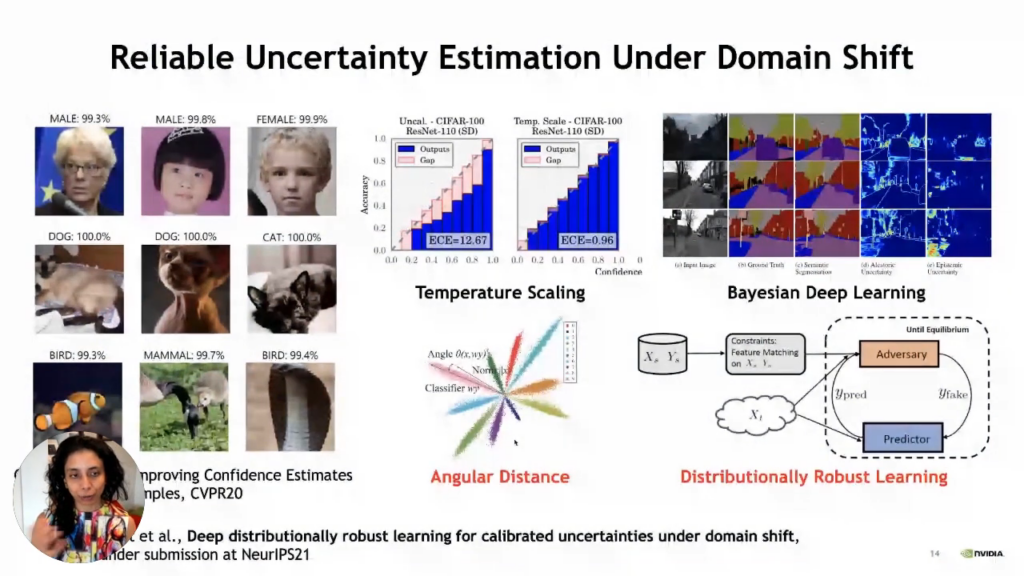
So, now let us see how we can use all the synthetic data and adapt to the real world. First of all, we need to talk about uncertainty estimation because when we are going through such a big domain shift, we have to worry that it should fail gracefully if it fails. It means that we should give the right uncertainty of failure, which is a problem with standard deep learning methods. So, it fails with very high confidence and that is a big problem. There have been several measures proposed to overcome this problem. The most straightforward approach is temperature scaling, but the problem with temperature scaling is that it is not very effective when we have a domain gap. Other than that, we have also explored angular distances as a more robust way to get reliable estimates. Moreover, there are also Bayesian deep learning methods, but they tend to be heavy and expensive.
Distributionally robust learning method
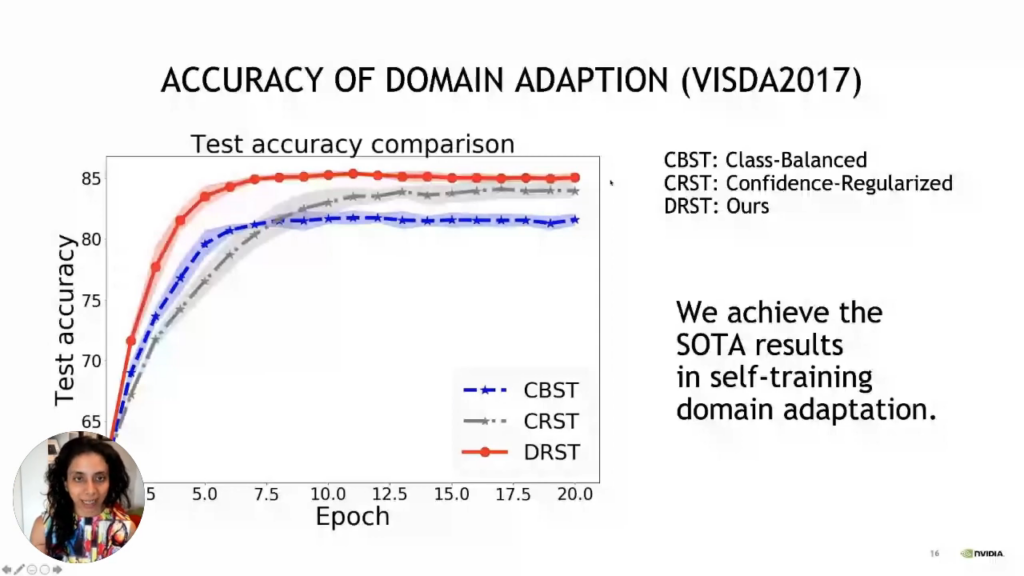
The distributionally robust learning method has its foundations in statistics. Nevertheless, the vital thing to note is that it is just a standard classifier with a density ratio. We measure how different the likelihood of a particular data point under the source distribution versus the target distribution is. In our example, the source distribution is synthetic data, and the target distribution is real data. we now have another network looking at a particular image of how likely it is to have come from the source distribution and how likely it is to have come from the target distribution. We are measuring the ratio of densities. To do that, all we require is a binary classifier, and we are classifying each image whether it belongs to the training set or test set, which is the source set or the target set. By doing so, we can determine how far this image is from the training data, so images far from training data will be down-weighted here because their density ratio will be small; hence, we will have lower confidence. So this now becomes end-to-end training here. If we are doing a classification task, we can train jointly with a binary classifier to assess how far the current test data point is from the source training distribution. So, having this jointly trained means we can also get good uncertainty calibration and a good classification. So, we use this to make domain adaptation of synthetic to real. Basically, what we did was combine it with self-training. So, in self-training, we are looking at uncertainties of our classified labels from our task network at test time, and we are only looking at the confident labels and retraining our network. This is being self-trained on the pseudo labels generated by our current model. So, we need to be very conservative and train only those pseudo labels with a high confidence level. Using a distributionally robust method where we are training for uncertainty through this density ratio estimator is simply a binary classifier of training and test data. We can get good accuracy estimates of domain adaptation, so uncertainty estimation is an essential step in this self-training, and having good uncertainty estimation ultimately helps in domain adaptation. The other important aspect is interpretability. So, we need to ensure that the images with lower confidence are also something humans think is more complex.
So, we talked about self-training as a way to make domain adaptation. So ultimately, what we want is good representation learning. Suppose we are only training on synthetic data that tends to fail. In that case, we tend to have collapsed representations because there is not the natural diversity we see in real images. We have proposed methods like contrastive knowledge distillation that balances training on the synthetic source data and the frozen ImageNet. So that way, we are making sure that we keep the rich representation and a domain shift balancing the two becomes essential.
This rich representation and other aspects of representation learning are very challenging when we do reinforcement learning. So, visual reinforcement learning is complex because it is high-dimensional.
For the self-driving car example, we can have unseen weather conditions at the test time and unseen road conditions. So, to be able to handle this, we require data augmentation. However, this is very popular in self-supervised learning. So we can put all kinds of data augmentation into the model; the model makes it very robust. However, with reinforcement learning, it is not possible because optimization will be untenable. So, essentially we will not have our agent make improvements if the augmentations are too strong. So, instead, what we do is a student-teacher model, so the teacher or the expert learns the policy but only on weak augmentations because with strong augmentations, we cannot learn the policy from scratch, but if it is only trained on weak augmentation, then it will not be robust. On the other hand, we imitate learning with the student, and the student now has strong data augmentations. However, it is getting supervision of the action from the teacher, and this becomes very useful for it to now also learn the strong augmentations, so this kind of two-stage approach helps us beat the optimization problem that arises in reinforcement learning and still get robust representations that can handle all kinds of visual issues that are unseen during training and still be able to do good in test time.
SegFormer: Semantic segmentation with vision transformers
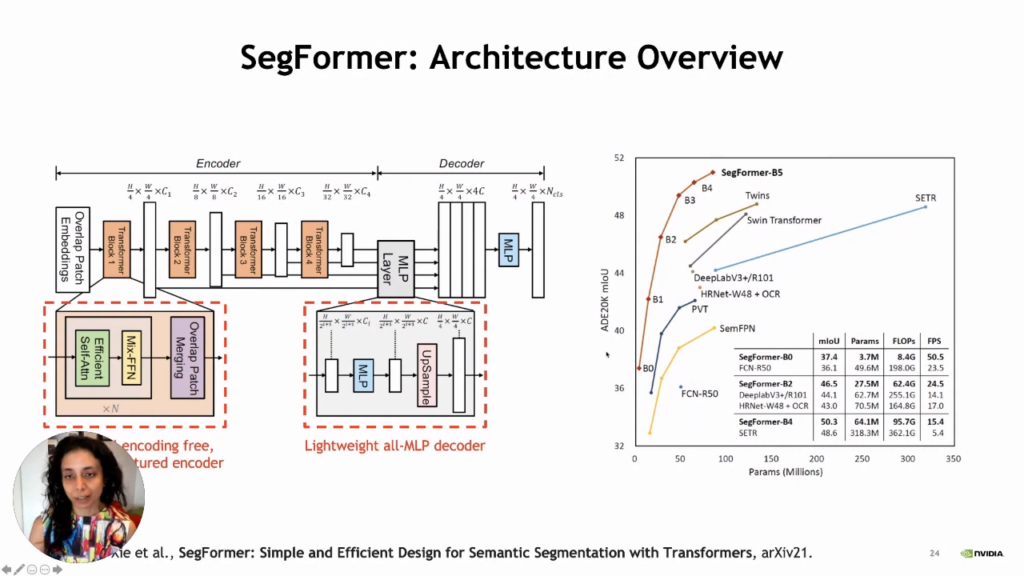
SegFormer stands for semantic and efficient design for semantic segmentation with transformers. SegFormer can give us a very rich semantic representation for segmentation. In addition to that, it is robust to all kinds of corruption that are not seen during training. SegFormer not only gives us a very rich semantic representation for segmentation, but it is also robust to all kinds of corruptions that are not seen during training. What makes this possible is the lightweight decoder architecture and the encoder that has a hierarchical transformer in a pyramidal structure. Here the decoder is just all MLP, but the encoder has this hierarchical transformer in a pyramidal structure, and as we do not have any particular encoding, it is lightweight. So, overall, these lightweight and principled approaches to architectural design provide us with state-of-the-art results and are immune to all kinds of corruption.
Conclusion
So, today we learned about DiscoBox, which shows that we can translate simple box supervision into refined instant segmentation and dense correspondences by performing self-supervised learning. We learned about different ways to adapt from synthetic to real data. We also found that the role of uncertainty calibration is hugely important. Other than that, it is essential to interpret how likely these methods are to fail. We also saw a state-of-the-art transformer design that enables zero-shot robustness to all kinds of corruptions on challenging segmentation tasks. We can say that, in the future, we will be able to eliminate mask information, for instance, segmentation problems entirely. Other than that, auto-labeling is promising for many dense prediction tasks. Moreover, we can adapt synthetic data to real-world applications. We can also say that the emergence of transformers is going to add a lot more to this domain.
Q & A
Q: Temperature scaling does not work well with a domain gap. What is an example of such a domain gap
A: It is like a synthetic to real-world data gap. For example, we train our model on ImageNet and use that classifier for real-world images.
Q: Does calibrating uncertainties deteriorate the model’s performance on the target task?
A: No, it does not. The reason behind it is that we get state-of-the-art adaptation because uncertainty calibration is a step in performing domain adaptation in many techniques.
Q: For uncertainty estimation, are we relying on the domain classifier confidence as a measure of the uncertainty?
A: Yes, but the main idea is that when we have a big difference between our target and training data, we care about extremes where we know there is a big shift and should also lower the confidence. So, in that sense, we can still trust the domain classifier.
Q: It seems it is easier to make label invariant transformations in the image over text. If you agree, what are your thoughts on the future of synthetic data or data augmentation on text data or text tasks like summarization, paraphrasing, natural language understanding?
A: I guess with text, we have tons of data. However, the problem here is again the curation of that data. Moreover, we are not sure what kind of biases are in the raw text data. However, we also need to determine if this is factual as some gender buyers could be factual like women are paid less than men. So basically, we need to find a way that determines whether the bias is due to facts or it is just discriminatory.
Follow Anima Anandkumar: Twitter, Linkedin, Youtube, Instagram, Website
If you’d like to watch Anima’s full presentation you can find it on the Snorkel AI Youtube channel. We encourage you to subscribe to receive updates or follow us on Twitter, Linkedin, or Youtube.

Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

