Nyla Worker, product manager at NVIDIA gave a presentation entitled “Leveraging Synthetic Data to Train Perception Models Using NVIDIA Omniverse Replicator” at Snorkel AI’s The Future of Data-Centric AI virtual conference in August 2022. The following is a transcript of her presentation, edited lightly for readability.
I am a product manager at NVIDIA and I will be talking today about Omniverse Replicator, which is a synthetic data generation tool in order for you to augment a dataset or just create on from scratch. So without further ado, let’s get it started.
Today we’re going to be talking about leveraging synthetic data to train perception models using NVIDIA Omniverse Replicator. I specifically say perception models because today we are going to be talking about RGB, depth, or potentially other sensors that are used for perception for use cases such as object detection, segmentation, or for instance, in Lidar that could be used in autonomous vehicles, for instance.
The reason I became familiar with this topic is because I was a solution architect/data scientist supporting customers in utilizing deep learning in the Edge. And I saw countless projects that were stalled due to the lack of data, or bad data, or simply because of how long it took to get good data.
Projects would start, and we would have to decide on the camera, the type of network, and who we were going to collect data with. Then finally, we would get the data and we would realize that it didn’t meet some of our performance metrics.
And what do you do then? You go back and regather data or maybe the project is over. However, there is a really easy way of avoiding this by using synthetic data that enables you to then troubleshoot and test things out before you even have to develop. So let’s go ahead and get it started.
First, we’ll talk about what synthetic data is. Synthetic data in the way that I will be speaking today is data that is generated from the digital world that you can create using some graphics tools. And from there, you’re able to get realistic data that looks like the one in the picture. So here is a warehouse generated in Omniverse.

And here you can see all of the data that we are able to get from that one scene. We are able to get semantic segmentation, instance segmentation, depth, 3D bounding boxes, and so on. This in conjunction with real data can lead to awesome AI models and even without it, you can at least bootstrap your applications. Omniverse is a platform that is meant to be used in multiple industries. And with that, all of the synthetic data that you can get out of Omniverse can be used. So for instance, one project that I worked on was utilizing BIM files, which are construction files that a company like Trimble has before even constructing anything.
So there are multiple industries in which synthetic data is useful, but I was speaking in particular about the architecture and engineering side, based on a project where we got these cross-beam files from construction.

Then with Replicator, we modified them a bit, and then we were able to use that data to train a perception algorithm to identify doors. You can read more about that in blogs, but overall, this can be used in multiple industries.
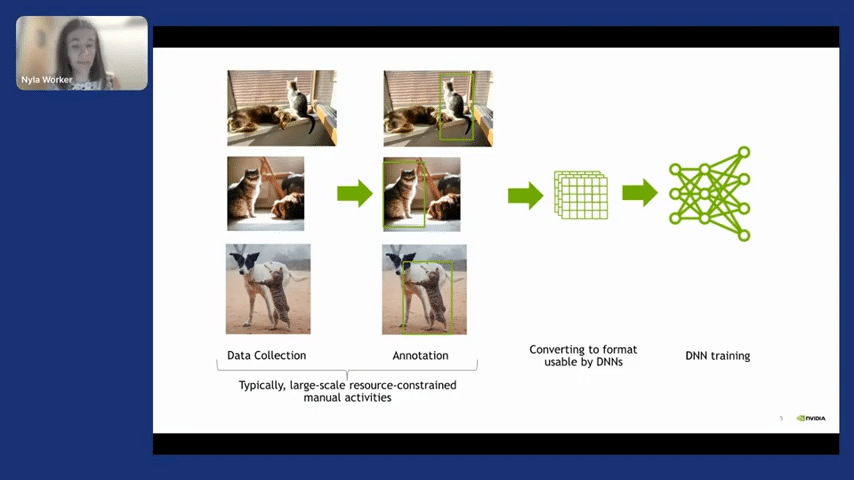
One thing that I want to emphasize is how it is traditionally done to train a deep neural network. Because this differs fundamentally from training with synthetic data. So training with real data has a large amount of time in which it is spent collecting data, annotating it, then converting it to the right format, and then training. This process of collecting data and annotation is time-consuming, but on top of that, it might not be the right data that you want.

In cases like segmentation, it is extremely time-consuming. When we’re talking about segmenting Lidar point clouds, that can not be easily done. Additionally, even if you’re able to gather that data and pay for labeling, you might have issues with long tail anomalies.

For instance, if you’re unable to detect deer in the road, which would be very bad for autonomous vehicles, you cannot have non-visual sensors. So for instance, as I said, labeling for Lidar is very hard and radar would also come with velocities, which would also be very difficult. And then we have occlusions and so on. So for these challenges, it’s just simply very hard, very impossible to get real data.

And there are other applications in which case you are not really sure how to get that real data. That would be for six degrees of freedom–here on the left we have a robot whose perception was trained using entirely synthetic data. And it’s linked to detect this piece. And then it uses a combination of control algorithms to effectively place it in the right position. On this other side, we have reinforcement learning, in which case it’s also impossible to get real data.

If we are talking about how expensive things can be, we will have a problem with things that require constant labeling. For instance, grocery stores constantly get new packages, constantly get new products, and labeling that continuously would be very challenging.

Replicator is a highly extensible framework built on top of the Omniverse platform that enables physically accurate 3D synthetic data generation to accelerate the performance of AI perception networks. So we are creating a framework on top of which you can build whatever you want to generate. And you’ll be able to bootstrap your AI applications.
I’m particularly excited about bootstrapping because it’s so cool that you can now be like, “I have an idea, but I don’t know if it’s going to work. Let’s just generate some data quickly, test it out, and if it works, I can ask for a larger investment and get real data labeled to double-check.” So that to me is very exciting. And that also could lead to more developments in 3D deep learning, which has been primarily stalled due to a lack of data. So this is very exciting, about potentially using 3D virtual worlds to generate synthetic data to then train DNN.
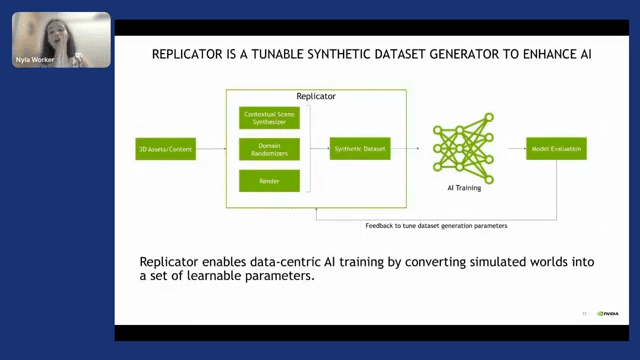
Okay, so I’ve been talking about all the great things about why you need synthetic data. However, things are not all that rosy. You need to reframe the way that you train DNN if you are going to use synthetic data. So the way that it would work is you ingest 3D assets. If you don’t have any content, NVIDIA provides you with a couple of assets for you to get started, but on top of that, you can go ahead and buy 3D assets on multiple platforms. And then once you bring them into the Replicator universe, you can use the domain randomizers, which randomize the scene and create a dataset. And then with that dataset, you can train an AI model.
But here is where it gets interesting. With real data, you have your dataset, and that’s it–it’s fixed. Maybe you’re doing a couple of augmentations, but that’s it. With synthetic data, you evaluate, and if a model doesn’t perform, you regenerate. And sometimes these have shocked people.
I was working with architects who did a blog on door detection, and the first time we ran this model with synthetic data, it gave 10% accuracy. Then we tweaked it and we generated a new dataset that looked very realistic, and then we got 60%. And then we utilized a couple of other techniques and we got all the way up to 85%.
So I just want to say those numbers so that you understand this is a very iterative process, but it’s awesome that you don’t really need to use real data for some tasks. For other tasks, you will for sure need some real data, but it is really awesome that you can get started with it.

Okay, so I said to you that we do some randomizations. What do I mean and why do we need that? You might be thinking, “Nyla, those 3D worlds are great for video games, but they don’t look realistic enough.” And you’re right, there is this thing called the appearance gap, which is pixel-level differences due to object details and materials in the real world.
And there is this other thing called the content gap. No matter how many hours you spend creating a synthetic world, you’re never going to have the variety of the real world. Those are two gaps that we have, and those two gaps make it so that the network sometimes doesn’t perform well when trained on synthetic data.
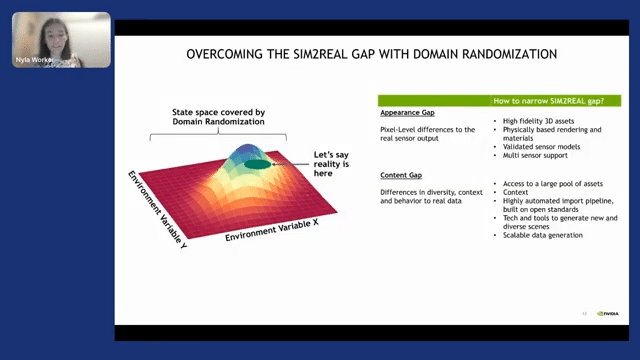
But there is a way of addressing that, and that is with domain randomization. So with domain randomization, you randomize the synthetic world so much–you randomize, for instance, the pose of an object and on the other side, the lighting conditions and you generate a very large distribution. And that very wide distribution encapsulates that reality. And with that, you’re able to get a performant DNN.
On top of that, what we’ve done to address the appearance gap is we’ve created high-fidelity 3D assets and physically based rendering and materials. And then on top of the appearance gap, for the content gap, what we’ve done is we’ve given you access to a larger pool of assets from NVIDIA. But on top of that, Omniverse is designed to bring in assets from other platforms. So that will be very helpful to you.
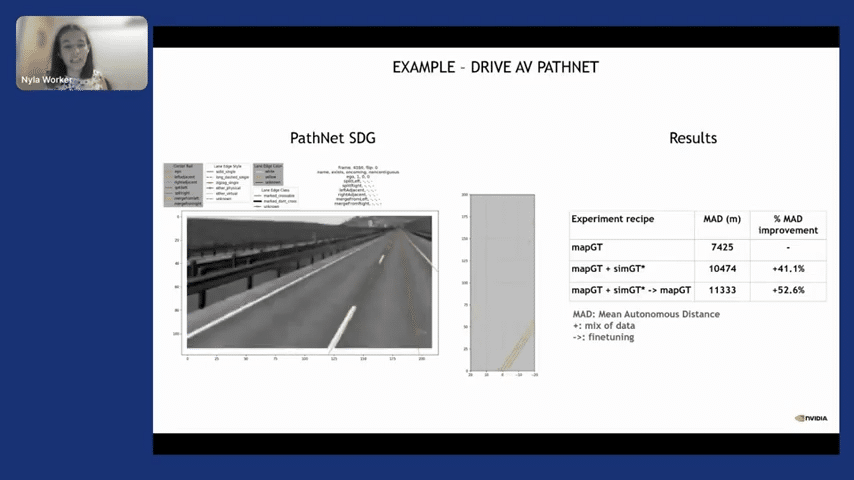
Here is an example where we trained PathNet, which detects lanes with synthetic data–I’m going to skip this due to time. Also for manipulation and reinforcement learning. And then this is the project I spoke about, which is utilizing synthetic Lidar point clouds to train a DNN. Again, there is a talk on this topic; it’s at the end of this talk, so you can go ahead and check it out later on.
But with that in mind, let’s jump in and talk about what Omniverse Replicator provides to you. So Omniverse Replicator is built on top of Omniverse. And why is Omniverse useful to you? So Omniverse is useful to you because it’s built on top of open standards.
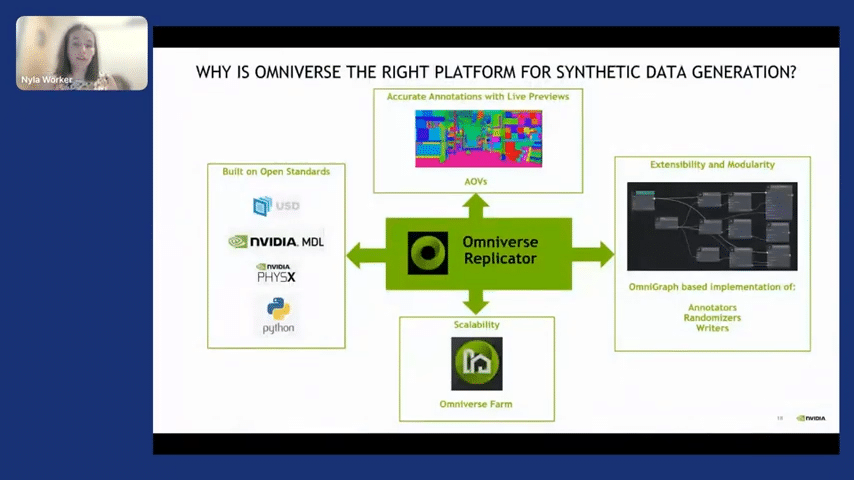
USD is becoming the standard in the graphics world, which means that there are more and more 3D assets coming into it. So that would mean that you would have to invest less time making content. Or you can just pull in content from other tools. It’s built on NVIDIA MDL, which is a material library, and we provide you with multiple materials off the shelf.
It also uses PhysX, which is our physics library. And the way that you interact with it is only in Python. So this should simplify a lot of what you are building. And we are heavily targeting the machine learning engineer, such that we bridge the gap between graphics and machine learning so that you can leverage the best of graphics without needing to know that much about graphics.
We give you previews of the AOVs, which are arbitrary output variables, which basically just means ground truth. We give you a graph-based way of implementing functions with Replicator, and on top of that, we’re able to scale across multiple GPUs to generate a lot of data. So that’s why Omniverse is the right platform for Replicator.

Replicator is built on top of these characteristics, which are physically based. So we have very realistic materials with reflections. We make it so that it has deterministic behavior. It is scalable. You have access to large pieces of content. It’s programmable. As I said, it works with Python and it’s very easy for you to get ground truth data. It’s modular and it’s built on top of open standards.

So what do we provide you with Replicator? We provide you with a randomizer. So as you’ll see here, the randomizer here is moving the poses of objects everywhere in a plane. So that is one of the randomizers. But there are many more that you can use. And what this will do is immediately give you tons of variety in your datasets.

And below that we have omni.syntheticdata. omni.syntheticdata is a lower-level API, which basically gives you control over the render to give you access to the AOVs. The arbitrary output variables—basically, I would characterize them as just a ground truth. Those AOVs are taken in by the annotator, so this is what you have immediate access to. And with those annotators, you’ll be able to write down the data, like the semantic segmentation or the bounding boxes.
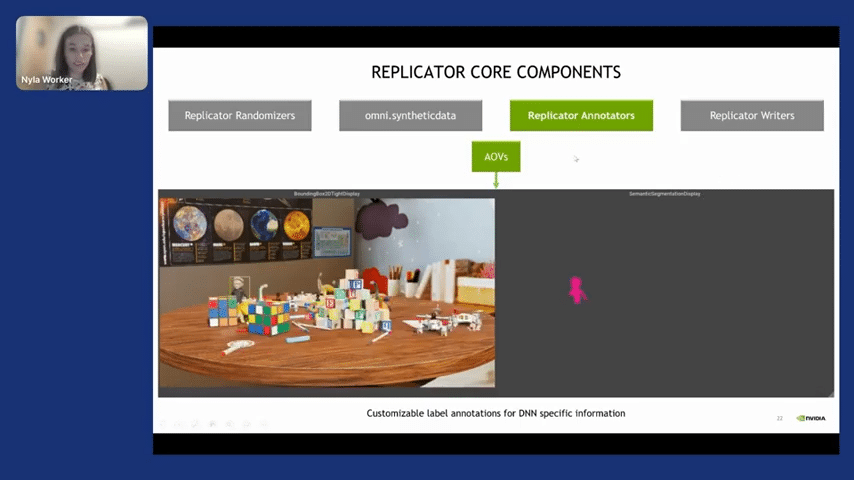
So as you can see here, you are immediately getting the data. If anyone is thinking, “Okay, great, Nyla, you are getting all of these images that are labeled, but how do you even get the first label?” The thing is, with synthetic data, you only label once. So I only label TJ, the character here once, and then as many frames as I generate, it will already be labeled. So all of these frames come from one time when you created the asset and you gave it a label.

Okay, so that is annotators. The types of annotators that we give you within Replicator are RGB, normals, motion vectors, distance from the camera or the image plane, instance segmentation, and so on. I’m particularly excited by what will happen with the 3D deep learning field. I really think it’s been blocked because of a lack of data. I’m excited to hear what people are working on. But you can build your custom annotator.
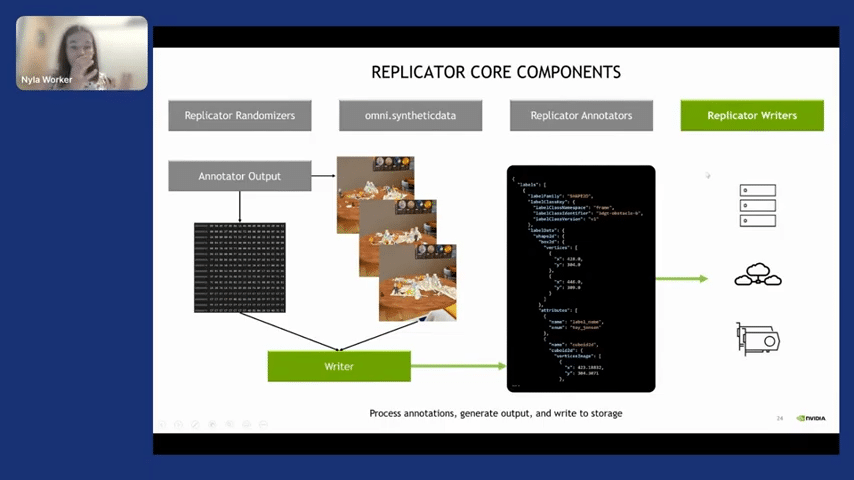
And once you’ve got the data that you want, you need to write it. Replicator provides you with a custom writer such that you can write it in your own format. These are the tools. Just to summarize, we have scene generation with materials, and backgrounds like the ground truth, which is the annotators, which give you the data, and then the writers.
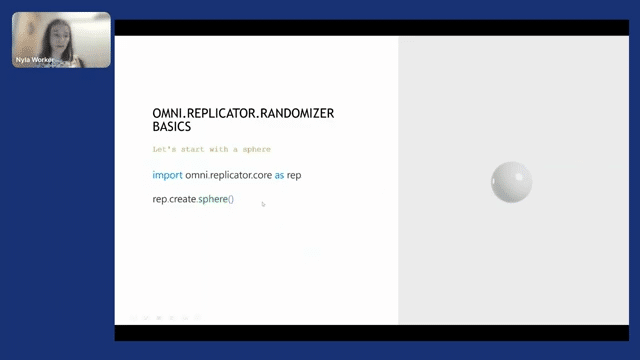
Very quickly, the Replicator API is very easy to use. You download the Omniverse Launcher, then you can simply write import omni.replicator.core as rep. You create a sphere. Then with a sphere created, you can use modified poses with a uniform distribution, you can change the color with the randomizer color function with, again, uniform distribution. And you can basically build in from that. You can add physics there with very simple functions. And then you can get other USDs from other people to get the assets and table, for instance, and create a scene that’s much more complex, such as this one, but with a very little amount of code.


Awesome. So how do you get started? There are tutorials that you can go ahead and read. There is a landing page that has blogs. There is a code forum, which we recommend for you to ask questions, and there is the Omniverse documentation. Plus, there are multiple FAQs on synthetic data generation. And I was one minute over, but I think we are ready for the Q&A.
Q&A on NVIDIA Omniverse
Aarti Bagul: Amazing. Thank you so much, Nyla. That was a very exciting talk on synthetic data and the technology that you’ve built. When a new team comes to you with a different use case, what are use cases or applications that are a very good fit for Omniverse versus things that are maybe not a good fit? So how do you assess, when this would be most applicable for a team that’s considering using it?
Nyla Worker: I think that would depend on the team and what they are trying to accomplish. We know that there are certain applications that have worked perfectly with synthetic data. For instance, object detection and segmentation train really well, depending on how many classes you want. But then it also depends. How much custom content does the team need? And in that case, is that custom content in some kind of 3D partner? So for instance, there are multiple websites that sell 3D content that you can go and download. And if most of your content is there, then it’ll be much quicker. If not, we have to assess whether you need to make that content in-house or go through a partner and then get content from that way. But once you have that content, and you have a machine learning engineer, I think we’ve seen awesome results for object detection, segmentation, and six degrees of freedom. With Lidar, we got pretty good results too. I think these areas feel very fresh in that we are still experimenting with their limits, but the results are very encouraging. And it does depend on the team and the extent of how difficult the use case is.

AB: Makes sense. Do you support tabular data as opposed to video or audio, more natural data?
NW: I think there is a team within NVIDIA that does tabular data, but my team in particular is focused strictly on perception data.
AB: Got it. And in terms of even just images, do you have support for generating non-rigid or organic objects as part of the tool?
NW: So this is the beauty of Omniverse. We have a whole physics team that also works with soft body physics. So that is something that you definitely can use as your assets within Omniverse.
AB: Amazing. Is it possible to change sort of the camera, weather conditions, all of those aspects when you’re trying to iterate on the images that you’re trying to generate?
NW: Yes, the camera can move around. You can also have different camera parameters that you want to have within your camera. You can also have multiple cameras producing data concurrently. With regard to weather conditions, you can change the time of day very easily. Weather conditions become a little more tricky, but you should be able to do some changes there.
AB: How close to the reality of photorealism do you get? And in general, what has been the importance of photorealism within synthetic data?
NW: Yeah, that’s a great question and I answer that question with asking, “What is the objective of producing this synthetic data?” And the objective of producing the synthetic data is to create a network that learns characteristics that are transferable to reality. And I emphasize that because sometimes it might mean that you might do crazy textures because you don’t want the deep neural network to learn the textures. You want it to learn the shapes and the dimensions of the shapes. And if you generate a synthetic world with crazy textures, you will force the DNN to learn patterns that are not textures. And this is actually really interesting because there was research published, I forget by who, but it shows that especially CNNs are really good texture learners. And you might not want to learn textures. You definitely want to learn the shapes or potentially the deformability and things like that, and you wouldn’t get to learn if you just learned texture.
So creating a very fake-looking world, quote-unquote by using different textures but realistic lighting and reflections and shapes might be the way to go. That’s why I’m very careful when we speak about photorealism because you do need proper lighting, but you might need to trick the network to not learn certain things.
AB: That makes sense. That is a very good point that I had not considered, where when you think of synthetic data, you immediately consider what’s that gap between the synthetic data and the real-world data. But your networks do pick up—like for example, in the healthcare setting, a lot of times, you have datasets from different hospitals, they might just pick up on the fact that this dataset is from this hospital instead of like actual characteristics. So eliminating the variables in terms of what your model can pick up on is very interesting.
NW: Yeah, like there was this Huskey/wolf dataset, and turned out that the data had only learned to detect that snow, so if a house was in the snow, it was a wolf. These are things that, even with real data we face. The network will learn things that you might not want to learn. Making sure that you choose the things that would transfer to reality and would represent your real dataset are very important. As much as I’m in favor of reducing as much as we can real data, I think you need to have a good test set at the end to make sure that you’re verifying that your DNNs are working well.
AB: Amazing. Makes sense. Thank you so much, Nyla. That was very informative.
Catch the sessions you missed!
The Future of Data-Centric AI 2023, our two-day free virtual conference, brought together thousands of data scientists, AI/ML practitioners, researchers, and the AI community at large to hear about and discuss the latest trends and research in data-centric AI. If you registered for the event but didn't see all the sessions you wanted, you can now catch up. The recorded sessions are available for registrants at the same Zoom portal as the live sessions.

Recommended articles
View all articles

Agentic AI evaluation: Closing the gap with better benchmarks and data
Alex Ratner, co-founder and CEO of Snorkel AI, spoke at @Scale: Systems & Reliability about one of the most underappreciated problems in AI deployment: our ability to measure agents has been outpaced — arguably for the first time in the history of the field — by our ability to build them. The talk digs into what it actually takes to close that
June 23, 2026
•
Snorkel Team

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•
Snorkel Team

The Art and Science of Building AI Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build AI benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents with
June 16, 2026
•
Snorkel Team

