Timo Mertens is the Head of ML and NLP Products at Grammarly. He presented “Toward Superhuman Communication Assistance” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. His talk was followed by an audience Q&A moderated by SnorkelAI’s Priyal Aggarwal. A transcript of the talk follows. It has been lightly edited for reading clarity.
I’m very excited to be here today to talk about Grammarly’s journey toward superhuman communication assistance.
First, I’ll give a quick intro to how we think about communication assistance and what it actually means in our minds. Then, we’ll jump into some technical details of how we approach building the product to solve some aspects of communication assistance. Then, we’ll take a sneak peek at some of the other things we’ve been working on.
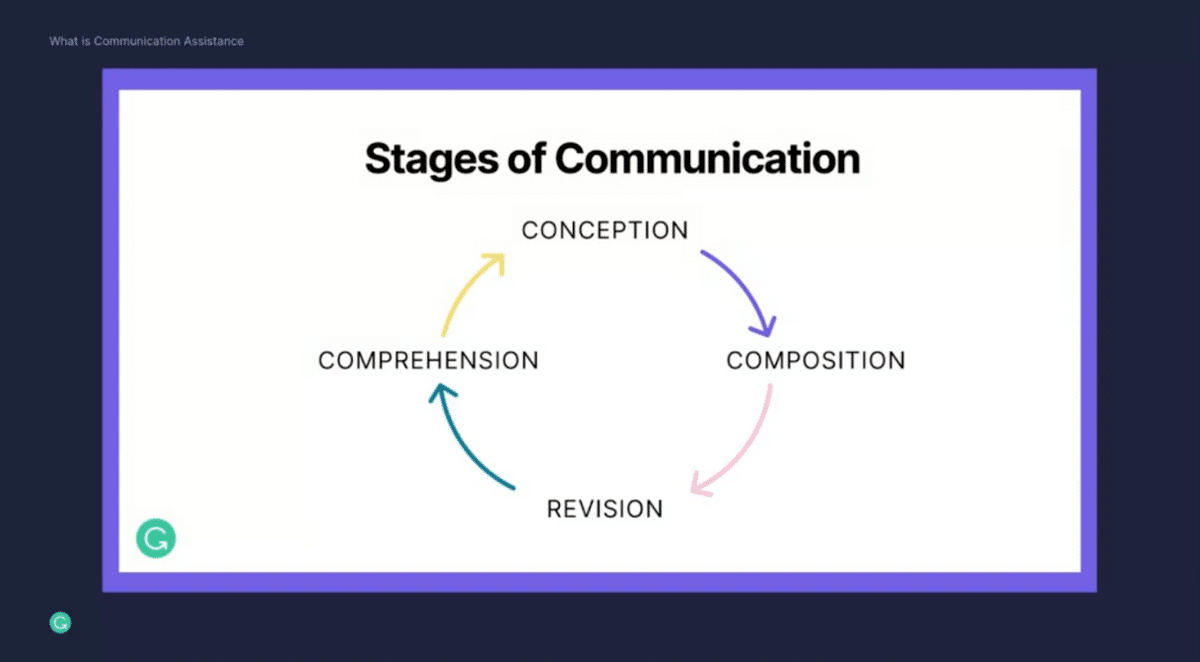
Let’s jump in and talk about communication assistance. When we think about communication assistance, we try to break it down into actual human processes and try to frame it in actual user problems.
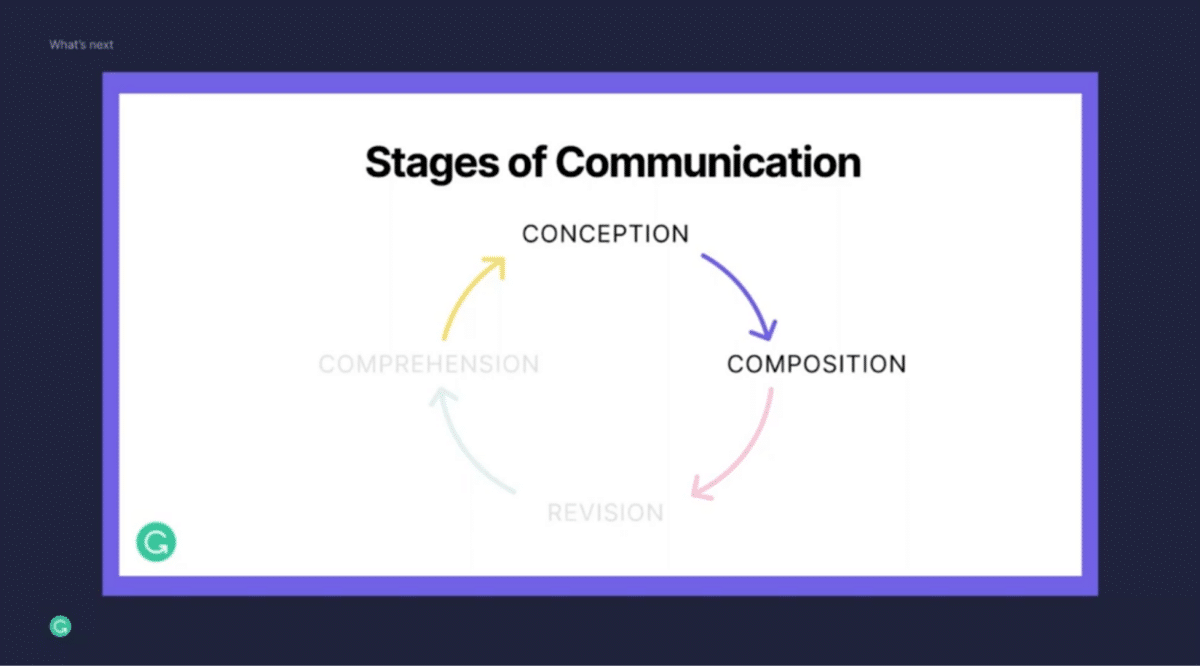
Imagine you are at work and you’re writing a very important project proposal. First, you have to conceptualize what you’re trying to express. That’s the conception phase here at the top. How do you best structure your proposal? What information do you want to include? How do you make the most convincing arguments in the best possible way?
As you’ve got that figured out, you move over to the composition phase. Now you’re trying to get your thoughts down on virtual paper. This takes many forms and everybody has a different approach to this. Sometimes you might spend hours just perfecting that one paragraph. Sometimes you crank out multiple pages in one go.
Once you’re done with this, now you spend a lot of time really fine-tuning your writing. You want to make it as perfect as possible. That’s what we call the revision stage. You want to make sure that your writing is grammatically perfect and has no spelling mistakes. You also want to make sure that it fits into the right length constraints. You want to make sure people read whatever you’ve written. If it’s 25 pages, chances are quite low that everybody will go through everything.
More importantly, you want to make sure that it’s coming across in an authentic way. You want to hit the right tone but also want to make sure it’s clear and it’s resonating with your audience.
Now that’s all done, you’re ready to share your writing—great! Your team, for example, might take a look at it and they’re trying to understand your points, they’re trying to understand the arguments you’re trying to make, and how to best provide feedback. Once they’re done with that, you receive that feedback, and now you go into another round of this communication iteration.
This cycle keeps continuing on because communication is inherently a multiplayer activity. You never just communicate in a silo. It’s important for you to express your ideas, convince others, and make sure others are getting your key points. Ultimately, you learn from them as well. You take their feedback into consideration. You adapt what you’re writing, you revise it and you improve it. It keeps this wheel spinning.
What we’ve found is that this is especially true now, where more and more work is fully remote. It’s especially important to make sure that these communication cycles work effectively, no matter whether you’re writing this very important project proposal or whether you are writing an important email to your whole organization, or whether you’re just responding to a Slack message.
Our vision at Grammarly is to provide assistance across this entire communication journey for tens of millions of users every single day.

Let’s double-click into one specific phase, which we call the revision phase, to illustrate what types of problems users face.
There’s no denying that misspellings, grammar issues, and rogue punctuation undercuts your message and otherwise brilliant writing. We think of correctness as the foundation of the revision stage and make sure that there are no mistakes in your writing. I personally oftentimes struggle to absorb and make sense of sentences or paragraphs, and that’s especially true in fairly technical and complex writing. Hitting the right clarity is a really important aspect to make sure that your readers are connecting with and understanding your writing, and taking away the key points.

Dull, unengaging writing does a disservice to both you as a writer and, more importantly, to the reader. Even if you have an amazing idea, you have great grammar and it’s really tight, it doesn’t help you if the reader gets bored after just two paragraphs. Choosing vivid words and varying the rhythm of your writing helps to keep the reader interested and get them through the whole content, all the way from beginning to end.
Last, and maybe not so least, delivery is important in writing. It’s not just the literal meaning of the work, but how it’s being delivered. In writing, it’s especially important to focus on this delivery because you can’t rely on your voice or your facial expressions to project dimensions like sincerity, confidence, politeness, or whatever else you’re trying to convey.
These are the four dimensions we think about as we think about this revision stage as part of the communication journey. By now you’re wondering, “How do you actually solve for some of those STEM engines?”
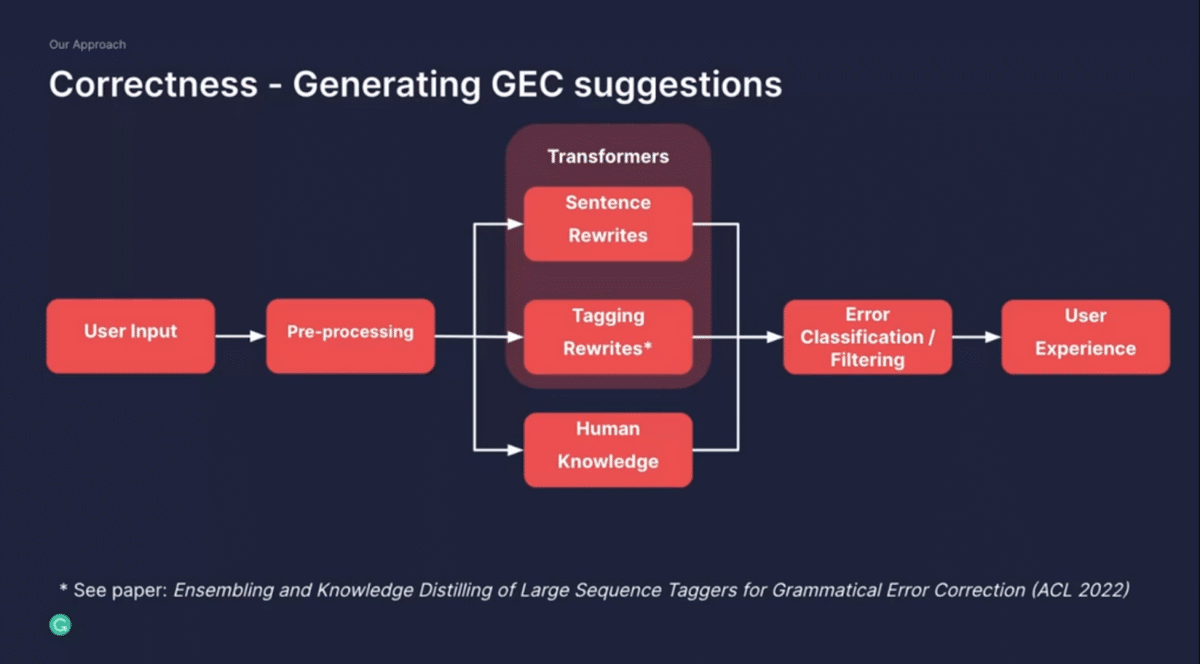
Let’s double-click into correctness to describe our approach on how technology, and specifically machine learning and natural language processing, can come together in a very user-centric way to solve real problems that our users face every single day.
Imagine there’s some user input—that might be a sentence that you’re writing. We’re thinking about solving the problem of correctness, which we call grammatical error correction, also known as GEC. We take that writing and pre-process that. That is a surprisingly big task because you have to apply all kinds of natural language processing as well as machine learning technologies to get the text ready for any subsequent modeling, or any subsequent decision-making.
That ranges all the way from language detection, tokenization, or syntactic parsing. From there, this process sentence goes into two different systems. At the bottom, we have a box called Human Knowledge. That really reflects a human interpretation of language and, in this case, grammar and spelling theory that gives us a very precise experience.
That can be pretty simple—yes, this word probably should be capitalized— but it can also get really complex in disambiguating ambiguous prepositions, for example. In addition to this, we use large machine learning models for different reasons. Specifically, we approach this in two ways. One is to rewrite the entire sentence—think of it as the sentence that you wrote might be incorrect, and we want to translate this into a correct sentence. The other one focuses a little bit on a tagging model, both of which are transformer-based models and state-of-the-art. These two systems come together, and ultimately we classify the sets of transformations and explain them to the user.
This is a really important dimension of the product. We want to augment our users. We never want to replace them. We always give our users choices, and for them to make a choice they have to understand why we’re making certain suggestions. It’s important to clarify why they are receiving our suggestions. It all comes together in the user experience.
http://www.giphy.com/gifs/retGcminitlQFvjMD3
Our approach has been to focus on ubiquity. Anywhere where users write, we want to be able to provide assistance. We exist in the desktop app, in the browser extension, with a web editor, as well as a mobile keyboard. It’s critical to make sure that users can rely on us no matter where they do their writing.
This is our approach toward correctness. We utilize both human knowledge and form of rules and augment this with machine learning. It’s quite obvious oftentimes why we actually need to rely on this human knowledge to overcome some of the surprising mistakes or inefficiencies that a model might make. Here’s just one of those examples that’s quite interesting to unpack.

Let me talk a bit more about our approach of humans-in-the-loop to generate a degree of user-centricity. Putting the human in the center is not only our principle within the product that we want to augment our users, but it’s also a very important paradigm for us as we build our product, as we develop new capabilities.
At Grammarly, a cross-functional team comes together to build our capabilities. That ranges all the way from analytical and computational linguists to applied research scientists, machine learning engineers, data scientists, product managers, designers, UX researchers, and so on. It’s a very broad spectrum of people, and everybody is bringing a different degree of user-centricity to our development process. This is important as we think about these fundamental communication problems that our users face every single day. Especially our linguists help us translate this human knowledge into code and into rules that we can apply to our product.
What this gives us is, first, a strong focus on precision. We can focus on high-quality, high-confidence rewriting experiences and suggestions that augment our users in very powerful ways. It also allows us to react to certain situations fairly quickly. We are able to come in and relatively quickly address it because we can operate in a very precise way in this rule.
Ultimately, explainability is key. We want our users not only to understand in the moment why they’re seeing certain suggestions, but over time hopefully they can learn a little bit about why. They are seeing these suggestions repeatedly and hopefully learn something about this aspect of correctness that they might incorporate into their own writing style. Augmentation really is the key here. It’s never the goal for us to replace the user, but just to give them these superpowers to communicate more effectively.
Now, all of that sounds great, but we all know also that large-scale machine learning is critical. We have the ability to augment these high-precision experiences with large-scale models. As we have tens of millions of users engaged with our product every day, we realized that they all have very different needs and face all kinds of different writing challenges every single day.
With machine learning, we can scale to all of these edge cases fairly elegantly over time. Furthermore, we can go beyond just this notion of operating at a word level or a small phrase level, but take in much more context as we are producing suggestions. We can look at sentence-level rewrites. We can even operate at a paragraph level. The only way of doing this is to use machine learning at scale. Something that is really important to me is the ability to adapt to different contexts.
I’ve talked about how this actually looks like in the system. But how do we know it’s working? How do we know we’ve produced a high-quality set of technologies and a high-quality user experience?
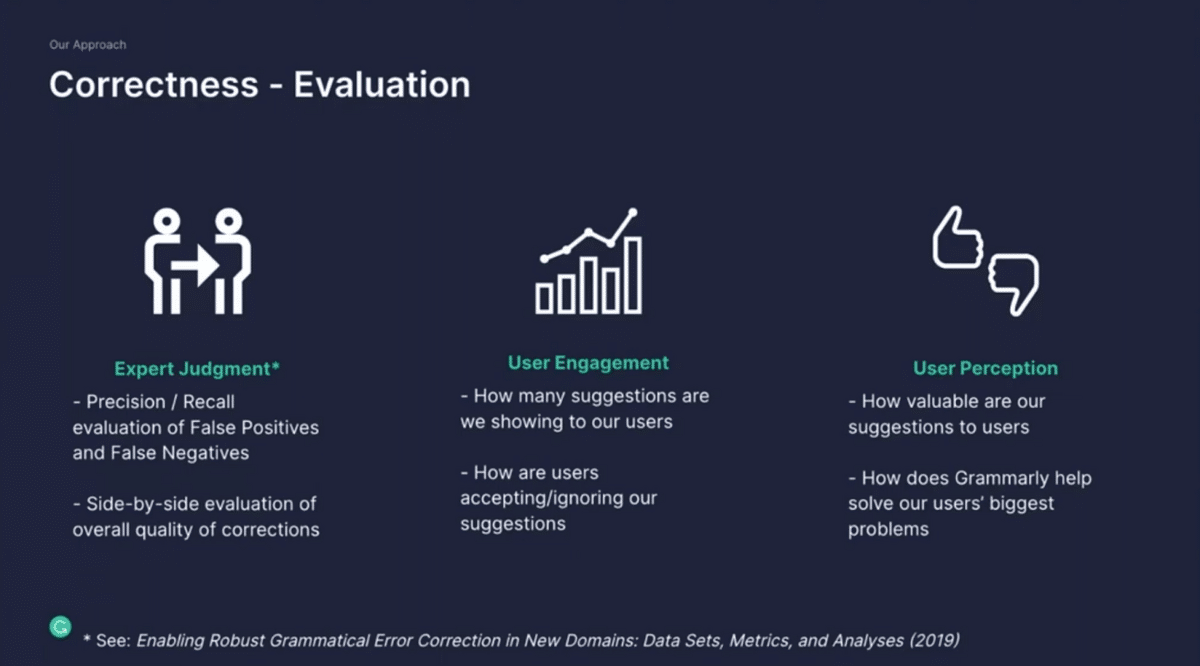
Let’s talk about evaluation a little bit. We came up with a framework that captures three buckets of signals that we utilize to evaluate the quality of our overarching system. The first is expert judgment, and I’m sure many of you are familiar with your traditional precision and recall measures that operate over expert annotated sentences or data. We can measure where we get it right and where we get it wrong. That’s quite helpful, but something we’ve found as an augmentation to that type of signal is to use side-by-side evaluation. The idea here is to look at the output of our system and compare that with the output of a human. Then we take those pairs and show them to other raters. Without them knowing which came from a human or from the machine, they have to tell us which one they find better. This is our methodology to figure out whether we can beat a human on the task—whether we can be truly superhuman.
But that in and of itself is not enough. We also have to reason about how our users actually engage with the product. That’s not only how many suggestions are we sending to them, but also how are they accepting or ignoring them. If we realize that they tend to ignore certain types of suggestions, that’s a very strong signal for us to think about the underlying quality.
The third bucket is what we call user perception. It’s a measure of how our users value these suggestions. Oftentimes as you optimize your models, you increase the quality incrementally, but that might not translate to users realizing that the product actually has improved and has gotten better. That’s something we are measuring.
Fundamentally, we want to understand whether Grammarly truly helps our users with their most important communication and writing challenges.

To tie this back to the title of the talk, we know that we will have achieved superhuman communication assistance when our assistant produces suggestions that are measurably better than what a human would produce, but not at the expense of the user engaging with the product and them perceiving the product and the value of the product. That’s our vision of creating this superhuman communication assistant.
Let me talk briefly also about these other stages of communication in this journey. In the comprehension phase, we have already built a couple of powerful capabilities in this space.
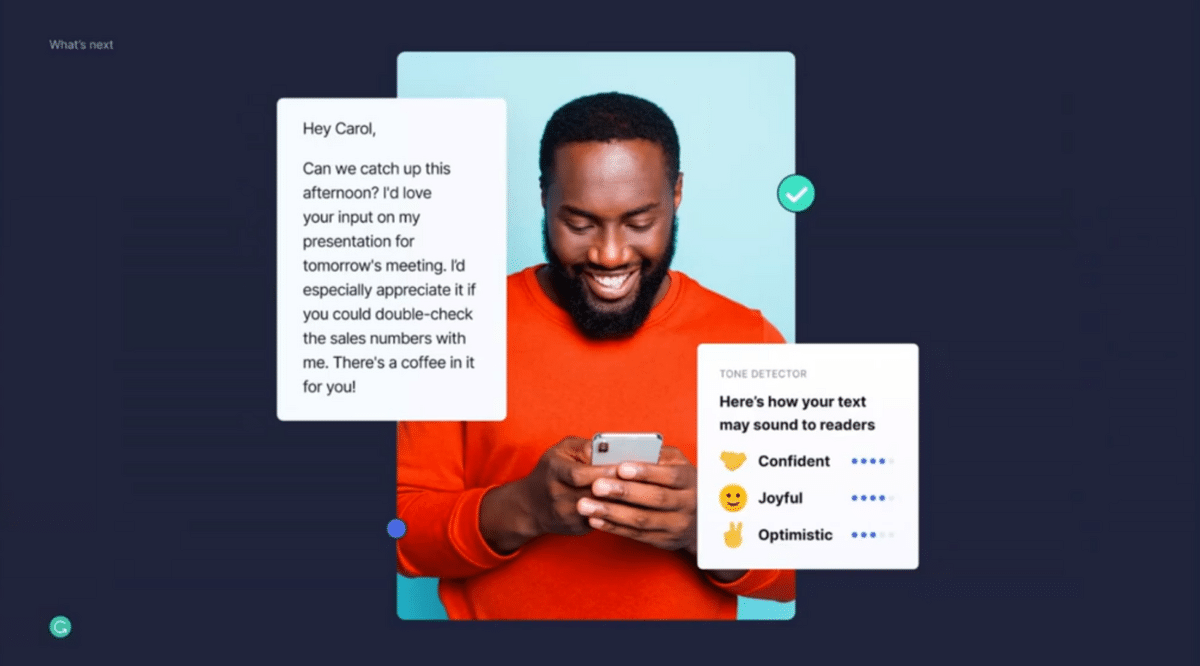
The first one is our tone detector. This one tries to help you understand how you might come across, and specifically how your tone might come across to the reader. We might give you these emojis that might tell you whether you are coming across as confident, joyful, or maybe neutral, or perhaps a little reserved. I think this gives our users a ton of confidence in figuring out how to best hit that tone depending on who you’re writing to.
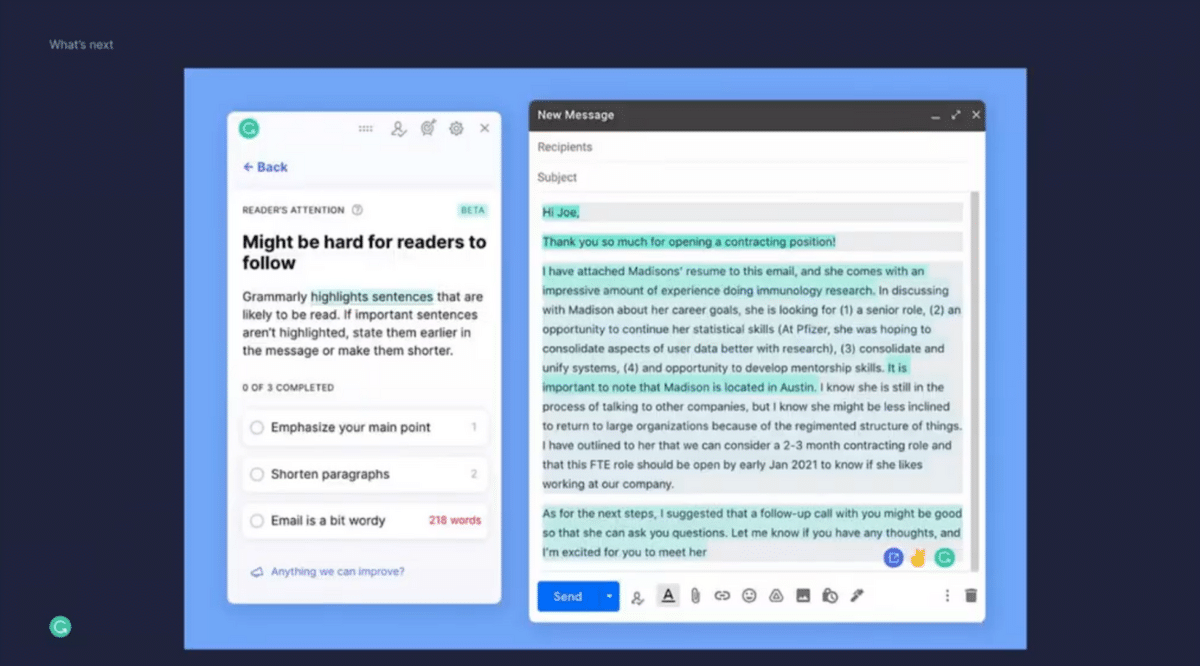
Another set of capabilities that we’ve built is to tackle making sure that you’re hitting the most important points in your writing and elevate them—make sure that they stand out. We have built a capability that highlights to you as the writer which section in an email might be a little buried, and which ones the reader might engage with more actively. Based on that, you can now decide whether you want to take a section that was previously buried in a paragraph and pull it out in different ways. Beyond this, we’ve also built capabilities that shorten your text a little bit and make sure that only the key information is present and make sure that it pops.
It’s quite clear that this is not the end for us. We are going in so many different directions that aim to bridge that gap between creating communication and for others to consume and comprehend that communication. It’s the same coin, just different sides. I’m pretty excited about some of the products that we have in the pipeline in this space.
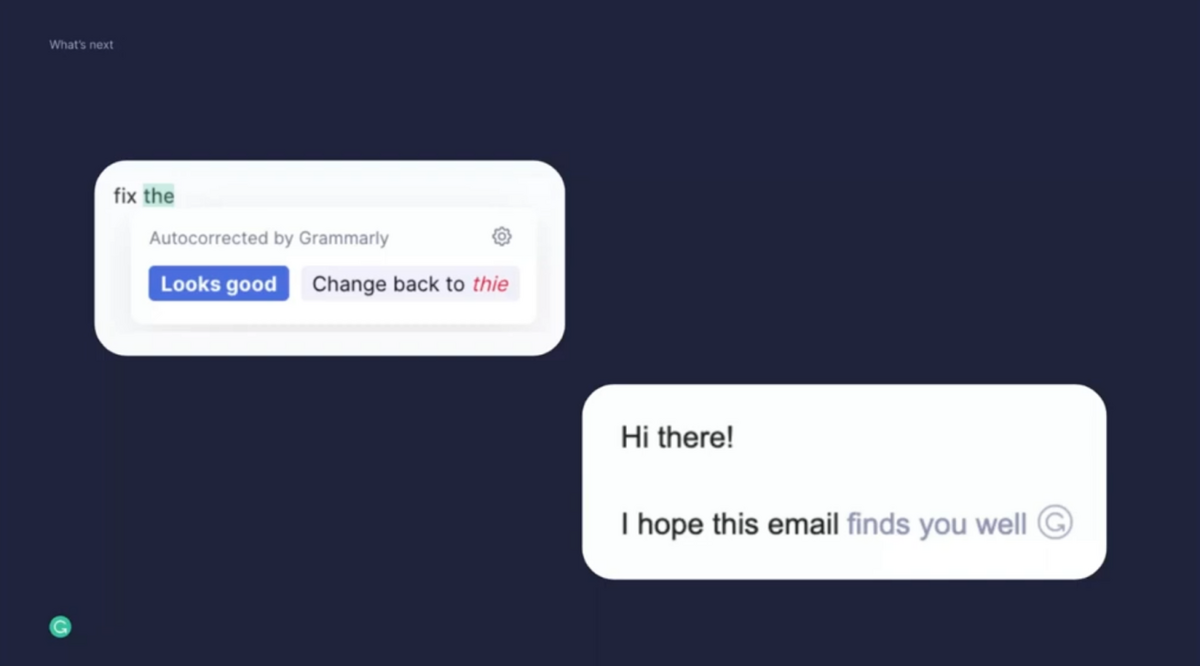
Let’s talk about composition. We have built awesome utility capabilities that focus on helping our users remain productive and in a flow state. The first has to do with autocorrect. We autocorrect many of the important spelling mistakes that you might make. We also went beyond this, and we’ve built a phrase autocomplete feature, which you can see at the bottom. The goal here is to complete your sentences just based on the first few words that you’ve written.
We’re not stopping there. What is quite unique, and I think interesting, is to think about these phases, these stages of the communication journey, and see how we might bridge those and how we might utilize technology to make them just a little bit easier to get through.
For example, you have this idea, you roughly know what you want to say, and now you start to get your thoughts on paper, but you might all of a sudden realize you had another idea. Now you go back into the conception phase. How can technology make these iterations, these micro-loops within this larger loop, a little bit more effortless? How can we make this a little bit easier and more delightful, such that you can focus more on the creative aspect of communication and worry less about the fmechanical aspects of typing words and formatting your writing?
Those are some of the general areas that we are exploring. It’s clear how technology can help us in the advent of generative large language models. These are all fundamental tasks that these models could help us with. We just have to figure out how to do this in a very user-centric way.
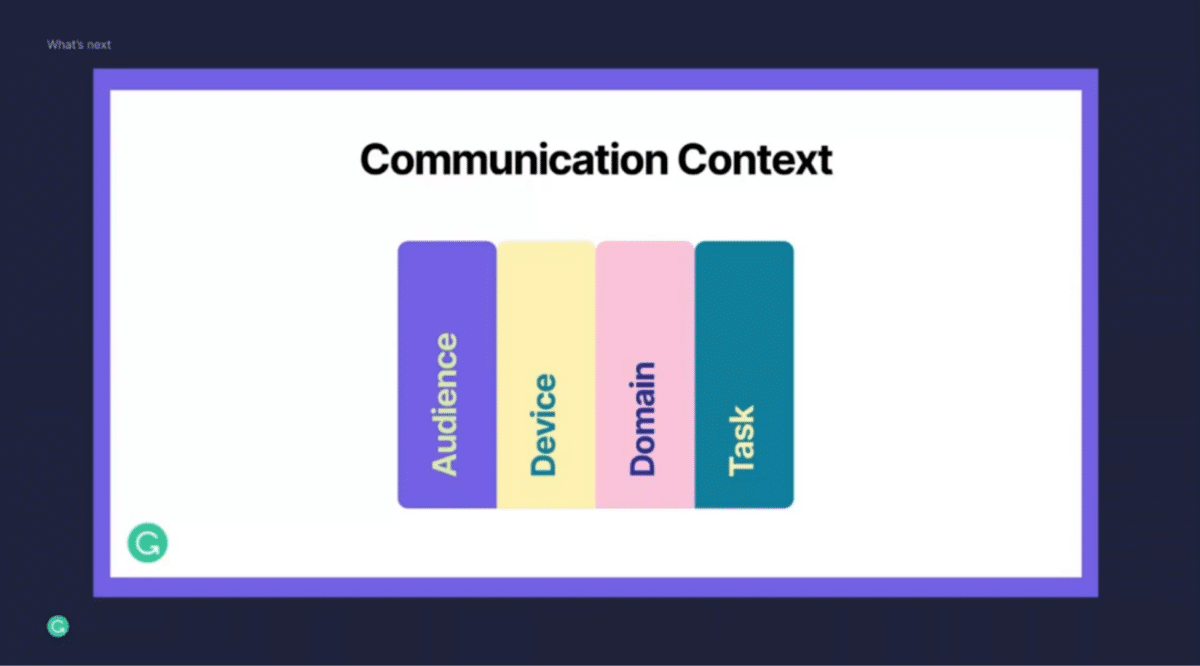
Communication is a very subjective task. Everybody has a slightly different approach and personal preferences, and everybody behaves differently depending on the context that they’re in. A one-size-fits-all approach is just not going to cut it.
That’s where context really comes in. To truly build a communication assistant that helps tens of millions of users every day, these contextual signals actually matter. That includes who you are writing to. If I’m writing a message to my boss, I probably behave differently than if I’m writing a message to my best friend. When I’m on the go on my mobile phone, I probably approach communication differently than when I’m standing at my desk writing on my desktop. What domain am I writing in? Am I writing an academic paper or is this a business communication or is this something else? This matters when we think about what types of assistance you might need.
Ultimately, what’s critical is to figure out what task you’re on. What are you actually trying to accomplish? Are you trying to convince somebody? Are you trying to land this job and get the recruiter to respond to you? Everybody, when they communicate, has a task in mind. We need to reason about this to truly provide superhuman communication assistance. I’m very excited to see how machine learning and NLP can come together at Grammarly to help our users with those foundational and fundamental tasks.
Q&A With Grammarly’s Timo Mertens
Priya Aggarwal: That was amazing. Thank you so much for sharing your insights, Timo. It was such a fascinating talk. We’ve all used Grammarly at some point, and it was great to have you shed some light on how it works behind the scenes. For me, when I saw the sentence completion prompts on the screen, that’s when I realized we are on the right track.
We have a few questions from the audience. The first one is “Does Grammarly’s ML model keep improving itself, or learn with users either accepting or declining the changes suggested by Grammarly?”
Timo Mertens: That’s a great question. We have a pretty complex development cycle where we want to understand deeply what users engage with and what they don’t engage with. At this point, we focus less on background automation and more on these fundamental moments where users might not be getting all the value that they should be getting from the product.
We look at certain types of signals of how they’re engaging to help us fine-tune, but that’s not the only signal. We also look at their more qualitative interpretation of quality as well as our expert judgment. It’s all of the signals that come together. It’s important that we have very strong opinions of why we would want to release an update, let’s say, to the model. It needs to be grounded in a strong articulation of quality across those dimensions.
PA: That makes a lot of sense, and I believe that also ties to your human-in-the-loop process where if the humans say that the what model is producing is correct, only then do you push an update.
The next question is from Paul, they ask, “Do you have any advice on how to start a human-in-the-middle exploration?
TM: That’s an open-ended question. I think the way to go about this is to start with the user problem. What fundamental problem are you trying to solve for the end user?
From there, oftentimes you can start pretty small in a very opinionated way. You might build some very simple solution that focuses on high precision, just to validate that you can use technology to solve this problem. Now from there, you observe your user, you see what they do or what they don’t do with the product. From there you can start to scale it out.
We utilize a rule-based system alongside a large machine learning system, and I think that’s the way to go. As you are exploring new capabilities, you start with a very easy-to-understand and very opinionated product experience based on rules or heuristics, or very simple technologies. Once you feel like you are solving these problems, now we can scale it out. Now we can utilize larger models. That doesn’t apply to every single problem out there. Sometimes you might have to start with machine learning from day one, but more often than not, I think it’s helpful to understand whether you’re solving a real user problem first.
PA: Roshni asks, “How do these models work across different languages? How does the correctness model adapt as the language changes?”
TM: We are focused on providing English communication assistance. So far, we haven’t had the need to expand beyond. You can select the type of dialect of English that you’re communicating in and there we adapt the system to some extent. But at this point, our models have focused on English communication.
If you unpack English communication, this is such a broad space. The workplace, business communication, personal communication on your mobile phone—that is enough opportunity space for us at this point. But it’s also quite clear that these types of models are quite powerful in how they scale and how they can be adapted. At this point, it’s more about adapting to the different types of user needs and different contexts that they might be in rather than languages.
PA: That leads me to a question of my own. How does the model generalize over say, different domains? If I work in a healthcare space and I am using my Slack to talk to my coworkers about some healthcare stuff, how does the model generalize across domains?
TM: Correctness is actually a little bit easier to reason about because a spelling mistake is probably a spelling mistake no matter what context you’re in—unless we are now realizing you are actually talking about a specific entity, that it’s not a spelling mistake of another word but it’s actually a proper name of a product or in medical of a drug. There, we have to start to adapt to it, and we try to be fairly surgical in that the user can supply their own dictionary or these types of approaches.
Some of the capabilities around clarity, engagement, and delivery get more interesting and quite a bit more subjective in terms of, what type of assistant is relevant depending on where you are. We’re in the early days of figuring out how to do this well at a large scale. These vectors of information are where you do your writing, the audience that you’re communicating with, and the task that you’re on—this will all flow into a scalable system. It’s quite clear we won’t really get to a large scale if we have to pre-assign behaviors in the product depending on what you do.
PA: Makes a lot of sense. Thank you so much for answering all those questions, Timo. We really enjoyed your talk and thank you so much for that great presentation.
TM: My pleasure. Thank you so much for having me.
Catch the sessions you missed!
The Future of Data-Centric AI 2023, our two-day free virtual conference, brought together thousands of data scientists, AI/ML practitioners, researchers, and the AI community at large to hear about and discuss the latest trends and research in data-centric AI. If you registered for the event but didn't see all the sessions you wanted, you can now catch up. The recorded sessions are available for registrants at the same Zoom portal as the live sessions.

Recommended articles
View all articles

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•

The Art and Science of Building AI Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build AI benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents with
June 16, 2026
•
Snorkel Team

Cua-Bench: benchmarking computer-use agents on professional software
TL;DR We built a benchmark of 25 expert-authored KiCad schematic-editing tasks and ran a frontier computer-use agent against them. The headline numbers: 1. Why build a computer-use benchmark for electrical engineering? Most computer-use benchmarks today live in the same handful of apps: web browsers, file managers, generic productivity suites. Those evaluations are useful, but they share a structural weakness —
June 15, 2026
•
,

