
The Center for Security and Emerging Technology (CSET) is a policy research organization within Georgetown University’s Walsh School of Foreign Service. It produces data-driven research on security and technology and provides non-partisan analysis to the policy community. CSET is building next-generation NLP applications using Snorkel Flow to classify complex research documents. Snorkel Flow drastically reduced labeling, model training, and iteration time and better equipped CSET’s data science team to collaborate closely with analysts to gather, process, and interpret data at scale.
Using AI to support data-driven research to inform policymaking
CSET’s mission is to provide non-partisan analysis to the policy community and prepare a new generation of decision-makers to address the challenges and opportunities of emerging technologies such as artificial intelligence, advanced computing, and biotechnology. It provides unprecedented coverage of the emerging technology ecosystem and its security implications, bolstered by novel methods to classify and analyze research and technical outputs from diverse sources, including foreign-language materials. CSET was looking to accelerate its development of high-quality models to inform CSET’s data-driven policy recommendations.
Challenge
CSET’s data science team wanted to build NLP applications to surface scientific articles of analytic interest. The team determined that a large-scale manual labeling effort would be impractical. Early on, CSET experimented with the Snorkel Research Project, code open-sourced by the Snorkel AI team for applying programmatic labeling and weak supervision techniques. CSET programmatically labeled 90K data points within weeks and achieved 77% precision. Yet collaboration between data scientists and subject-matter experts was time-consuming, requiring a combination of spreadsheets, Slack channels, and Python scripts.
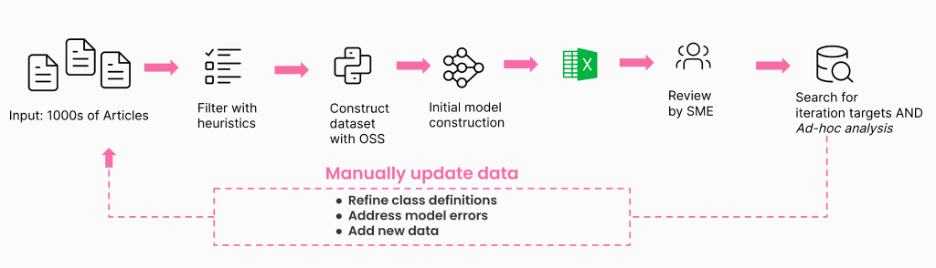
Aspects of this workflow made systematically improving data and model quality a slow process:
- Constrained collaboration between domain experts and data scientists due to cumbersome, manual data transfer back and forth between spreadsheets, with the data scientist writing code for labeling functions.
- Inefficient tooling to auto-label, gain visibility into data and improve training data and model quality.
- Limited adaptability without an integrated feedback loop from model training and analysis to labeling. Data scientists and subject matter experts would have to spend long cycles re-labeling data to match evolving business criteria.
These challenges limited the CSET team’s capacity to deliver production-grade models, shorten project timelines, and take on more projects.
Goal
Accelerate the development of ML solutions with efficient collaboration between teams, producing high-quality models to inform CSET’s data-driven policy recommendations. Increase the number of research projects CSET can deliver.
Solution
CSET’s data scientists attended Snorkel’s The Future of Data-centric AI conference in August 2022. They decided to explore whether Snorkel Flow, a data-centric AI platform, would be a good solution to accelerate programmatic labeling and build high-quality NLP applications with weak supervision. With Snorkel Flow, the CSET team delivered a final model with 85% precision on positive class, resulting in an eight percentage-point improvement over the solution using Snorkel’s original research code in just a few days.
CSET’s team created 60+ labeling functions (LF) to programmatically label 107K data points using advanced features such as keyword LFs, auto-suggest LFs, cluster LFs, and more. They also used embedding similarity and negative sampling to improve the representation of the negative class. Snorkel Flow provided the ability to pinpoint data slices for domain expert spot-checks and troubleshooting to improve accuracy, powering an active learning workflow.
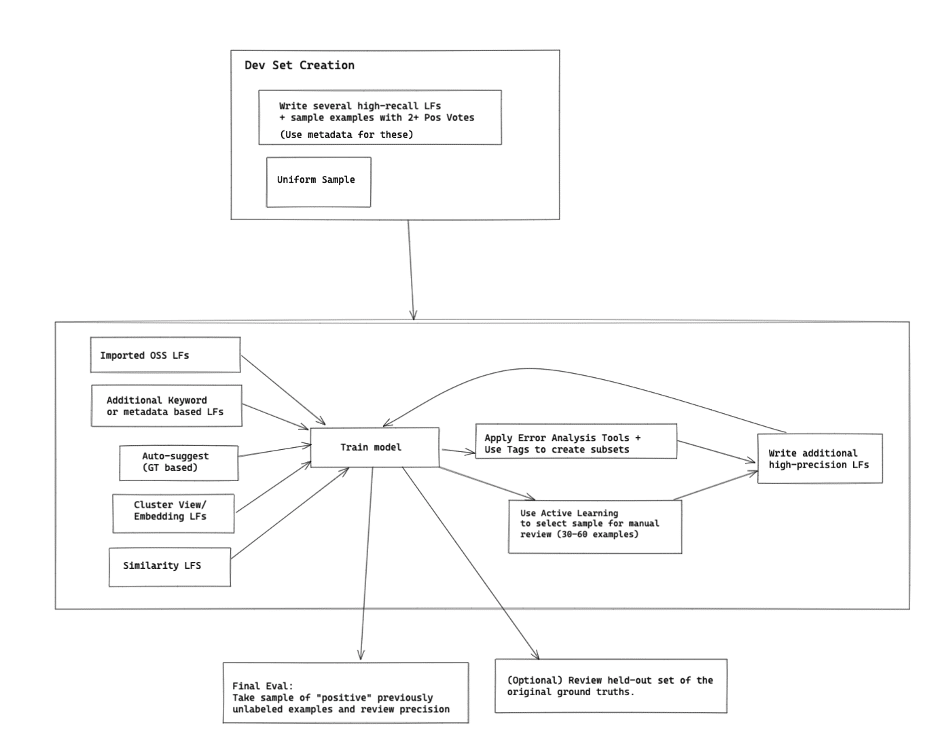
- Improved collaboration between domain experts and data scientists with an easy-to-use GUI to author LFs and used comments and tags to discuss and resolve complex cases efficiently.
- Increased productivity with advanced LFs based on foundation-model embedding distances and clustering.
- Reduced time to adapt with guided error analysis and prioritized examples for targeted manual review using active learning.
Snorkel Flow eliminated a lot of friction in data science and domain expert collaboration. The CSET team brought domain experts into the loop during the model development process, significantly improving project buy-in, knowledge transfer, and productivity.
CSET Director of Data Science and Research Catherine Aiken pointed out, “With Snorkel Flow, we cut labeling time and significantly accelerated model development when delivering NLP solutions.”
LF suggestions in Snorkel Flow are powerful—they delivered what was a full day’s work with open source in a few minutes.
James Dunham, NLP engineer, CSET
We are excited to partner with CSET and bring together top researchers and technologists to make significant strides in advancing policymaking.
Results
107K
programmatic labels created with advanced features: autosuggest and cluster LFs
Significant
reduction in labeling time with improved productivity
85%
accuracy on a classification model within days

Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

