Regulators and compliance officers face a constantly evolving landscape of financial markets. An increasingly complex and fast-moving financial ecosystem demands that they modernize how they surveil market and trading activity.
Trade surveillance aims to spot:
- Market manipulation
- Fraud
- Collusion
- Insider trading
Historically, trade surveillance systems identified suspicious trading activity based on pre-defined rules. These rule-based systems can struggle to detect emerging forms of market abuse under the complexity and volume of today’s markets.
How AI augments trade surveillance
Artificial intelligence (AI) is increasingly necessary in trade surveillance. AI helps compliance officers and financial regulators process an ever-growing stream of data and use that data to identify and predict patterns of suspicious activity using machine learning (ML).
AI can expedite:
- Data collection and analysis. AI can process large amounts of data quickly, freeing up compliance officers to reallocate their expertise. Natural language processing (NLP) can analyze trader communications, such as emails and chat messages, to identify potential insider trading.
- Pattern recognition. Specialized models can identify and predict suspicious trading activity, such as unusual price movements or large-volume trades.
- Network analysis. Collusion is difficult to detect from market outcomes alone, but AI can uncover relationships between traders or trading activity to identify potential scheming.
AI-powered surveillance systems boast higher accuracy than traditional rule-based systems when detecting suspicious trading activity, and can also reduce the number of false positives.
While AI offers benefits for trade surveillance, it also presents challenges, such as:
- Data availability. AI-powered surveillance systems require large amounts of data to train and operate, which can be difficult and expensive to obtain and label.
- Interpretability. AI models can be complex and difficult to interpret, making it difficult for users to understand why the model flagged a trade as suspicious.
- Bias. AI models can be biased by the data they are trained on. If training data is insufficient, unrepresentative, or full of errors, AI will reflect those shortcomings.
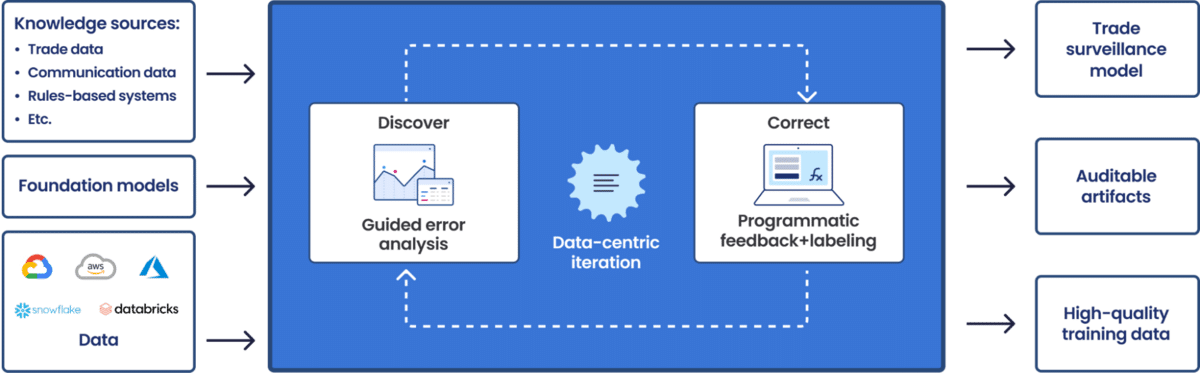
How Snorkel AI is builds better AI trade surveillance
Snorkel AI offers a data-centric AI platform to help businesses build and deploy custom AI applications quickly and efficiently.
The platform enables increased accuracy, scalability, and security with:
- Labeling functions and weak supervision: Snorkel helps users create large training datasets quickly and programmatically to accelerate AI training. By combining labeling schemas with human expertise, users can rapidly transform large unlabeled datasets into accurate and useful training sets.
- Cross-team collaboration: Technical and non-technical users can collaborate on Snorkel’s platform to create labeling schemas, train foundation models, and encode domain-specific knowledge to ensure that functions are accurate and relevant.
- Guided iteration and explainability: Snorkel provides artifacts that help users understand how a model operates and why it produces certain results. This allows users to tweak, iterate, and refine data labeling rules to drive the resulting model to production readiness and keep pace with changing priorities and challenges.
Snorkel allows users to deploy their custom-trained models on-premises or in the cloud. Snorkel has SOC2 Type 2 certification, providing enterprise-grade security in the Snorkel Cloud as well as partnerships with Google Cloud, Microsoft Azure, and other leading cloud providers.
Leveraging foundation models to improve trade surveillance
Foundation models (FMs) and large language models (LLMs) represent a new frontier in AI-powered trade surveillance, and can rapidly accelerate their development and output of AI applications.
The generative capacity of foundation models makes them uniquely suited to tasks like:
- Dataset labeling. AI models must be trained on high-quality and representative datasets, but labeling datasets has traditionally needed significant human input. FMs can help programmatically label large training sets, minimizing strain on subject matter experts.
- Use case customization. FMs and LLMs can be adapted to address domain-specific problems through pre-training and fine-tuning. A pre-trained FM like FinBERT can provide a strong basis for a domain-specific application to tackle business problems like trade surveillance, saving time without sacrificing accuracy.
Multi-billion parameter FMs can also be distilled into smaller iterations, making them more relevant to their assigned tasks, easier to deploy, and less costly to manage. These sophisticated models can be trained to address challenges inherent to trade surveillance and protect the financial markets from fraud and manipulation.
Snorkel natively integrates with both open-source and closed API models so users can securely harness the power of these AI instruments.
Accessible AI for trade surveillance with Snorkel AI
Today’s lightning-fast financial marketplaces call for AI-powered monitoring tools. AI accelerates market and trade surveillance by processing high-volume data streams efficiently, uncovering patterns, and identifying and predicting fraud, collusion, and other forms of market manipulation.
Snorkel AI gives regulators and compliance officers a data-centric edge to power trade surveillance applications. Users can leverage Snorkel’s programmatic labeling functions and weak supervision to quickly and accurately label data from a variety of sources and build high-quality training sets.
FMs and LLMs can significantly jumpstart the creation of AI tools. These massive models can accelerate training set development and be fine-tuned to address specific business use cases and distilled into deployable custom models.
Ready to discover how Snorkel can advance your trade surveillance efforts? Contact us today to learn more.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.

Recommended articles
View all articles

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 29, 2026
•

Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration
June 25, 2026
•

