While many foundation models can be used for zero-shot prediction, they often struggle on all but the most popular tasks. Out-of-the-box usage for specialized tasks—especially for industry applications—often leads to poor performance.
The standard approach is to adopt one of the numerous fine-tuning strategies in order to specialize the model to a particular task. However, this requires access to a labeled data set—and we’re back to the world of supervised learning! What can be done in settings with little or no labeled data?
We’re excited about new strategies we’ve recently developed that tackle such scenarios. Each combines foundation model outputs with weak supervision in order to obtain improved performance while sidestepping label-hungry fine-tuning methods.
We present our findings for these strategies in the following papers:
- In Language Models in The Loop [1], Snorkelers Ryan Smith, Jason Fries, Braden Hancock, and Steve Bach replace crafting traditional labeling functions—often small programs— with prompts in order to produce language model outputs.
- In Ask Me Anything [2], members of HazyResearch demonstrate that question-answering (QA) prompts often lead to better outputs. They show how to use language models to transform inputs into such prompts, then aggregate them with weak supervision.
- In Alfred [3], Steve Bach and students propose a system for prompted weak supervision.
We’ll dive deeper into each in the following sections.
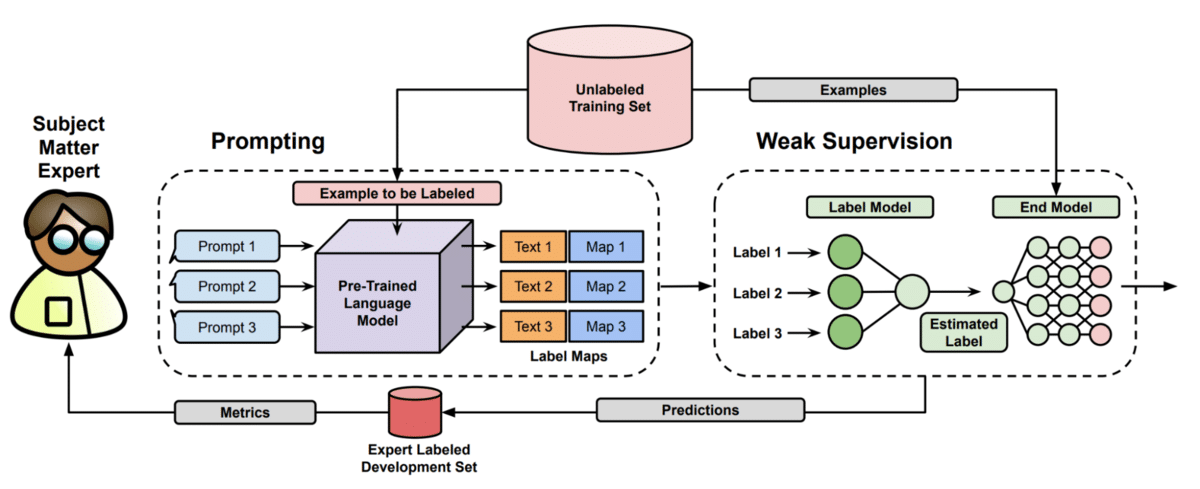
Figure 3 [1]: Pipeline for incorporating language models in weak supervision loops. Users craft prompts to produce language model outputs that are mapped to weak labels. The resulting labels can be used in a weak supervision pipeline like Snorkel.
Language Models in the Loop
Weak supervision typically involves obtaining a variety of sources of signal, including programmatic labeling functions, and aggregating them into a high-quality labeled dataset for downstream training.
This is a powerful paradigm—and our favorite for operating in settings where we don’t have large amounts of labeled data—but we’d like to reduce the burden on users even further by automating the process of crafting labeling functions.
To do this, we can train many tiny models on a handful of labeled points and select a good subset of these to act as labeling functions. Our recent work benchmarks such approaches, termed AutoWS techniques [4]. However, tiny models often struggle with all but the simplest settings.
Large language models sit at the other end of the spectrum, but are rarely trained on data arising in specialized tasks.
In our work Language Models in the Loop [1], we use simple prompts to use language models as labeling functions. This frees users from crafting manually-implemented labeling functions and lets them reach beyond tiny AutoWS models.
The key challenge in building such prompted labeling functions is to accurately map LM outputs into labels that can be used downstream. These labeling maps ensure that models are not restricted to produce a single expression but can instead produce flexible output that is still correctly interpreted as a desired label.”
The system we built outperforms both direct zero-shot prediction (by an average of 20 points on the WRENCH benchmark) and conventional programmatic weak supervision.
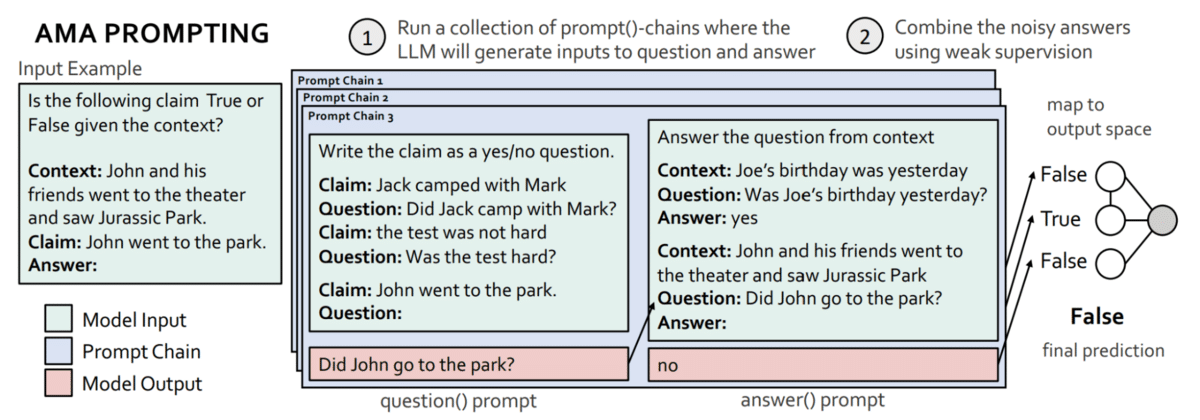
Figure 4 [2]: Ask Me Anything prompting framework. Language models are used to transform task inputs into question-answer prompts. These are used to query the language model, and the outputs can be aggregated and de-noised with weak supervision.
Ask Me Anything
Manually specifying prompts can still be challenging—to such an extent that “prompt engineer” is an already viable career path! Indeed, prompts are often brittle and require repeated iteration in order to find a “good” prompt.
How can we address this pain point and reduce the amount of time spent on prompt engineering?
One of the most exciting aspects of language models is that they can be used to rephrase questions. Ask me anything prompting, developed by Chris Re’s group at Stanford, shows that using LMs to rephrase tasks into question-answering prompts (Figure 4) produces higher-quality output.
Better yet, it is possible to repeatedly do so—obtaining a variety of prompts and outputs. These can then be combined and de-noised with weak supervision. This simple but effective strategy enables substantial improvements; it allowed a much smaller open-source language model (6-billion parameter GPT-J) to outperform GPT-3 with 175 billion parameters on 15 out of 20 popular benchmarks.
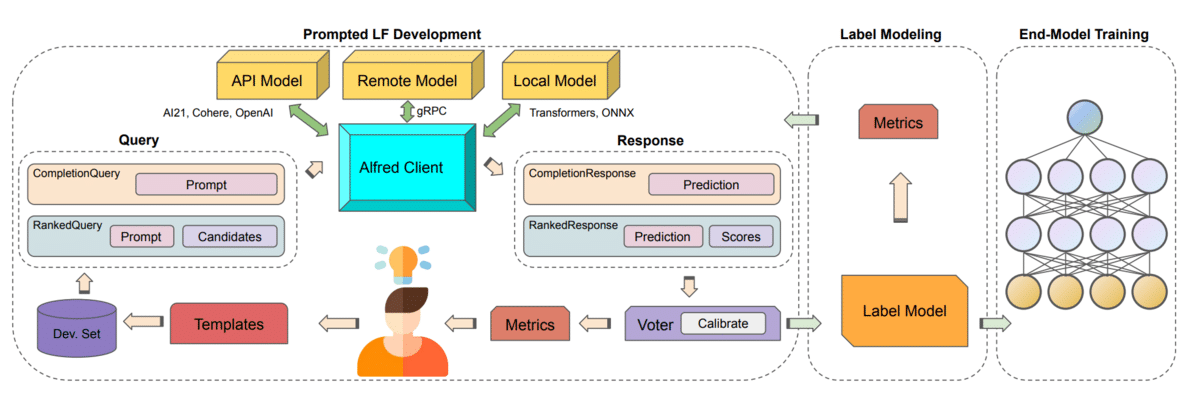
Figure 5 [3]: Alfred, a system for prompted weak supervision.
Alfred
Snorkeler Steve Bach and students propose a system to efficiently build labeled datasets via prompted weak supervision [3].
Building on the idea of replacing programmatic labeling functions with prompted versions, Alfred allows practitioners to use a simple Python interface to quickly create, evaluate, and refine their prompt-based labeling functions (Figure 5). Prompt execution is optimized via automated batching mechanisms, dramatically improving query throughput.
Snorkelers continue to find efficiency
Snorkelers continue to push forward the state of the art in AI and machine learning. In the three papers outlined above, they’ve found new ways to get more efficiency out of large language models and other foundation models, letting data scientists build useful and valuable models even faster than before.
Keep watching this space to see what Snorkel researchers do next!
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!
Bibliography
- R. Smith et al, “Language models in the loop: Incorporating prompting into weak supervision”, 2022.
- S. Arora et al, “Ask Me Anything: A simple strategy for prompting language models”, ICLR 2023.
- Peilin Yu and Stephen H. Bach, “Alfred: A System for Prompted Weak Supervision”, ACL System Demonstration Track, 2023.
- N. Roberts et al, “AutoWS-Bench-101: Benchmarking Automated Weak Supervision with 100 Labels”, NeurIPS 2022.

Fred Sala
Chief Scientist
Frederic Sala is Chief Scientist at Snorkel AI and an assistant professor in the Computer Sciences Department at the University of Wisconsin-Madison. His research studies the fundamentals of data-driven systems and machine learning, with a focus on data-centric AI, foundation models, and automated machine learning. He and his group received the 2024 DARPA Young Faculty Award, a best student paper runner-up award at UAI ’22, the outstanding Ph.D. dissertation award from the UCLA Department of Electrical Engineering, the NSF Graduate Research Fellowship.
Recommended articles
View all articles

Agentic AI evaluation: Closing the gap with better benchmarks and data
Alex Ratner, co-founder and CEO of Snorkel AI, spoke at @Scale: Systems & Reliability about one of the most underappreciated problems in AI deployment: our ability to measure agents has been outpaced — arguably for the first time in the history of the field — by our ability to build them. The talk digs into what it actually takes to close that
June 23, 2026
•
Snorkel Team

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•
Snorkel Team

The Art and Science of Building AI Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build AI benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents with
June 16, 2026
•
Snorkel Team

