
Representation models significantly impact the performance of AI applications. We’ve seen this working with clients at Snorkel AI. Standard representation models often fell short on our clients’ specialized tasks, leading to poor application performance. While we use many tools to sharpen their applications, representation model fine-tuning sometimes prove the most effective.
I recently had the opportunity to delve into our work on representation models at our Enterprise LLM Summit. I explored the fundamental concepts of representation models and their crucial role in machine learning tasks.
The discussion centered on the importance of data quality and the role of data augmentation techniques in improving the robustness and effectiveness of representation models. We also ventured into the strategic use of these models in retrieval augmented generation (RAG), an AI process designed to optimize the outputs of large language models (LLMs).
I recommend you watch the whole presentation, embedded below, but I have summarized the main points here.
Understanding Representation Models
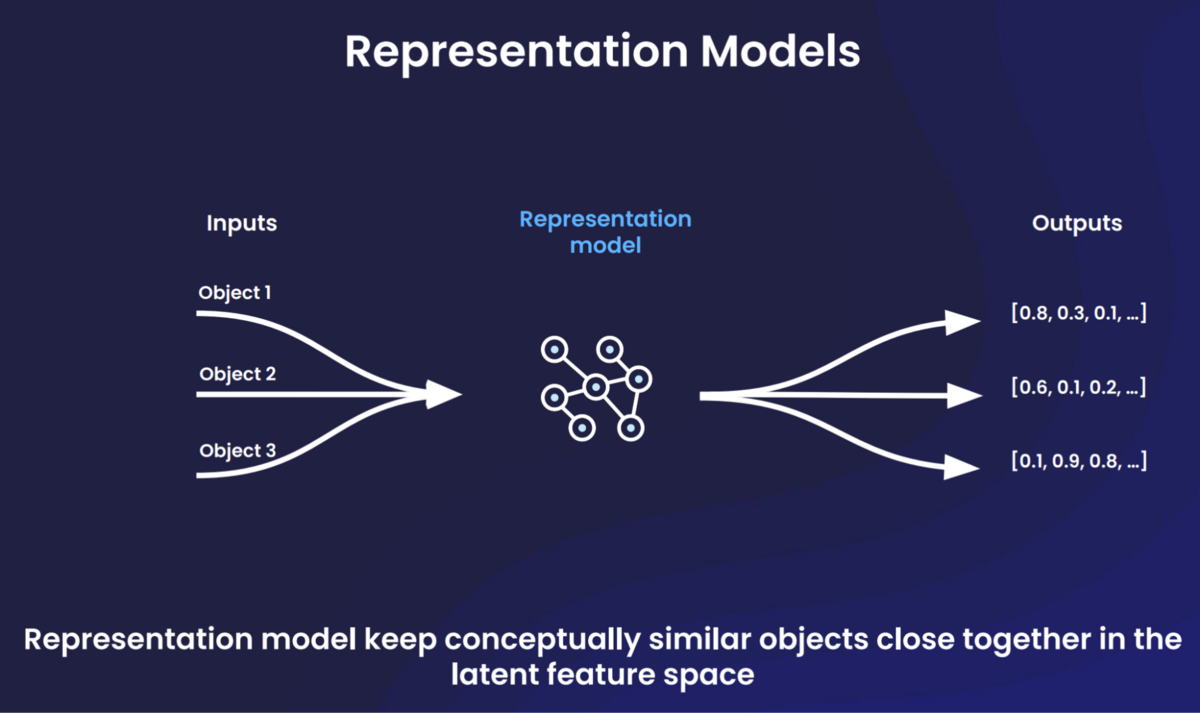
Let’s start with the basics. Representation models are a class of machine learning models designed to capture and encode meaningful features from raw data. These models enable classification, clustering, similarity calculations, information retrieval, and other tasks.
Representation models often serve as part of a broader machine learning system, and their outputs feed downstream uses. The models’ training teaches them to keep conceptually similar objects closer together in the latent feature space.
In the context of RAG pipelines, representation models can play multiple crucial roles. They fuel the indexing process where the model encodes the corpus of data into a dense vector space. The same model also encodes the user’s query for retrieval. After retrieval, another class of representation models, known as cross-encoders, takes in pairs of inputs and learns their joint representation for the re-ranking process which often improves performance. Thus, representation models are integral to the effective functioning of RAG pipelines.
What is retrieval augmented generation (RAG)?
RAG attempts to improve LLM outputs by incorporating an additional information retrieval step—and generally succeeds in doing so. This retrieval step augments the prompt sent to the model by adding context. For example, injecting one or more paragraphs about football if someone asks a question about the National Football League.
Fine-tuning these models can help ensure the retrieval stage identifies all the documents relevant to a user’s query, and then ensures that it accurately ranks the documents in order of importance.
Fine tuning representation models
Pre-trained representation models typically learn their feature space on large and diverse datasets. While these models easily separate documents about moon landings and moon pies, they can struggle with nuance on narrow topics—which is what enterprises typically need.
This is where fine-tuning comes in. By adapting these pre-trained models to a specific task, dataset or intent, we can leverage the knowledge they gained from the pre-training phase and further optimize them for our unique needs. This results in models that better understand and encode the nuances of your specific data or domain, leading to improved performance.
Data scientists most frequently fine tune representation models through two approaches: task adaptation and full model fine tuning. Task adaptation fine tunes a portion of a network’s layer, which requires a smaller amount of data. This adapts the model to the new task efficiently and reduces the risk of overfitting. Full model fine-tuning trains the entire network on your task-specific data set. While this typically requires more data, it allows for a more comprehensive adaptation to the specific task, often leading to superior performance.

The role of data quality and augmentation
The success of fine tuned representation models heavily relies on the quality of the data used in the llm fine tuning process. Data that lacks diversity or does not capture certain edge cases may create a model that underperforms when faced with real-world scenarios. In such cases, data scientists may consider data augmentation or synthesis techniques.
Data augmentation increases the diversity and quantity of training data without collecting new examples. It applies transformations to the existing data to create new data points. This helps create a more robust and comprehensive dataset, thereby improving performance.
Our Snorkel Flow AI data development platform allows users to apply scalable and effective data augmentation techniques. It facilitates methods such as embedding and clustering techniques to determine similar or dissimilar points. This can help create “hard negatives,” which are data points that are very similar to the positive examples but not relevant. These hard negatives help fine tune the model’s ability to distinguish between similar concepts that it initially struggled to disambiguate between.
Snorkel Flow also enables users to easily slice and filter their data. This helps users identify the source of errors and allows them to focus their augmentation techniques efficiently. For instance, it can allow a user to identify that a certain subset lacks sufficient representative data, and augment it.
Data + representation mode fine tuning = better RAG
Training data quality and the use of data augmentation techniques play a crucial role in the success of fine-tuning representation models. By ensuring your data is representative and diverse, and by effectively leveraging data augmentation methods, you can significantly enhance the performance and robustness of your models.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.

Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

