Prasanna Balaprakash, research and development lead from Argonne National Laboratory gave a presentation entitled “Extracting the Impact of Climate Change from Scientific Literature using Snorkel-Enabled NLP” at Snorkel AI’s Future of Data-Centric AI Workshop in August, 2022. The following is a transcript of his presentation, edited lightly for readability.
Thanks for having me today and allowing me to present our recent work on climate change and Extracting the Impact of Climate Change from Scientific Literature Using Snorkel-enabled NLP. I’m a computer scientist at Argonne National Lab, and I’m here representing a truly collaborative team.

The team is composed of: Tanwi Malik–who did the majority of the technical work, she’s a computer scientist. Duane Verner, Leslie-Ann Levy, Joshua Bergerson, and John Hutchison are infrastructure analysts to Argonne. And Yan Feng, who is an environmental scientist.
So from the title and from the team, you might have already guessed where this talk is heading. I promise that the expectations will be met, and that’s exactly the line of investigation that we were after.
There are many different pictures if you just go and Google “climate change” that you can find. Really depressing, alarming pictures of climate change. And instead of using those pictures, I just went to DALLE mini from Hugging Face (this is called craiyon now) and said, “Okay, climate change, global warming.”

And these are the pictures that DALLE synthesized from the internet and generated a new set of images. And I bet none of these images are positive. Everything’s depressing and I cannot emphasize how much trouble we are in if we don’t make enough of an effort to address this very existential problem, which is a big threat not only to humanity but to the entire planet.
Because of this importance, there is a growing body of scientific literature trying to understand the impact of climate change on the environment, on humans, and every living species on the planet.
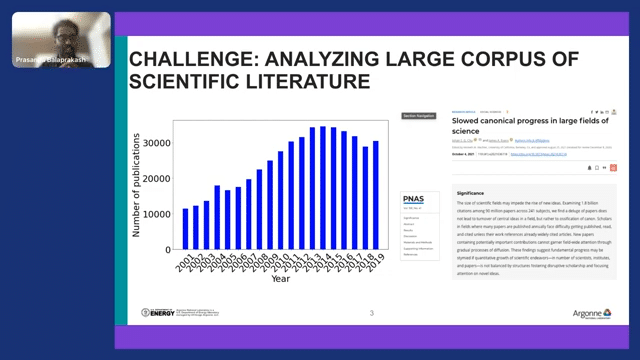
And this can be evidenced from the growing number of publications. You can see, right now, we are at around 30,000 related publications that talk about climate change. This is great because people are looking into this important problem and trying to find solutions.
On the other hand, the growing number of publications also presents its own unique challenges. The scientific field is filled with a lot of publications, which can actually pull back the progress in the field in its entirety because the important work will need time to diffuse and will not be able to come up out of all the noise.
This presents a lot of challenges in understanding the climate risks and the risk mitigation strategies. That’s the sort of overwhelming body, or overwhelming challenge that we are facing to understand climate change.
I have introduced my team members; several of our team members are infrastructure analysts, and this project is especially trying to understand all the different climate change hazards. For that, the teams actually looked into the 2021 IPCC, NASEM, and USGCRP reports.
These are all different reports that talk about various types of climate change and climate change hazards. And then what they did is they came up with 18 different high-level climate change hazards that talk about climate trends–both long-term and short-term–and also extreme events that are indicators and precursors that affect our day-to-day living.
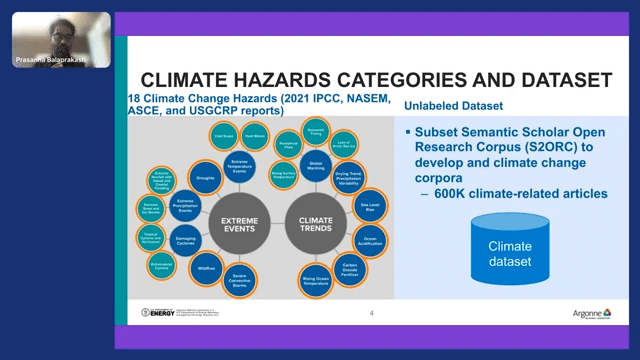
They synthesized this in a different way. They didn’t go and look into the scientific literature, because it’s a lot of papers to look at. Instead, they looked into these reports and came up with descriptions for each of these categories.
For example, you can say “global warming” and “drying trend” and “sea level rise.” So for each of these high-level climate change hazards, some of these hazards are already reported in the 2021 IPCC report. But they took this high-level thing, and then they came up with a description of the hazard.
That’s something that they can easily do because they can copy and paste the text from the reports and synthesize it, saying “these are the 18 climate change hazards that we are interested in.” Now we want to take these 18 climate change hazards and correlate and extract information about these hazards from a large body of scientific literature.
We started with this Subset Semantic Scholar Open Research Corpus (S2ORC), which consists of 600K climate-related articles. The goal is to figure out how we can extract the scientific articles that talk about different types of climate hazards.
Our infrastructure analysts were very much concerned and very much interested in analyzing the impact of climate change on US infrastructures. If you go and look at all the critical infrastructure sectors for the country, it goes from energy, financial, government facilities, food and agriculture, and so on. These are called critical infrastructure because [if you] knock one of these out of the equation, the country will go down. That’s why they’re so critical.

And climate change has an impact not just on one or two, but on the entire set of critical infrastructures. At the high-level, the national critical functions are defined by the government, and are categorized as connect, distribute, manage, and supply. You group the critical infrastructures into various classes.
What they want to do is to correlate these things. Each of these categories have a description, and now they want to correlate the scientific articles that talk about the impact of climate change on the critical infrastructures as well.
First and foremost, we are faced with this huge corpus of scientific articles. We want to, first and foremost, label these documents. Given a scientific article, we want to say which climate hazard it belongs to, or which national critical function it is actually talking about. So those are all the labeling functions that we are talking about.
Typically, you let the experts read some articles, label them, and then use them as training data and train the supervised learning model. But this is not a scalable approach. In fact, we burned our fingers in a previous project where we relied on domain scientists to label them all.
First of all, they’re busy, and it takes a lot of time to get label data from them. More importantly, the domain experts are not experts in all different climate hazards. They have their own judgments about certain things, and that introduces bias into the labels.
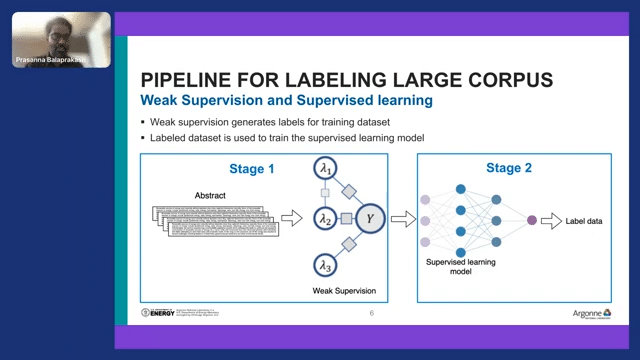
To address all these problems, we looked into weak supervised learning. With weak supervised learning, what we try to do is use Snorkel and programmatic labeling techniques to label a fraction of the corpus. So that’s stage one. Once we label a fraction of documents, we use that as training data to train the supervised learning model.
So this is a fantastic use case for weak supervised learning and a fantastic use case for programmatic labeling. The first thing for most processing in programmatic labeling is to come up with the programmatic labels. We have to write some sort of heuristic rules to say “if these conditions are satisfied, then classify this particular document as a particular climate hazard.”

Again, we don’t want to write those rules explicitly because of the same reason. The computer scientists are not experts in climate hazards. The climate hazard people are not experts in all climate hazards. And the environmental scientists are not experts in critical infrastructure. So to avoid all these issues, what we did is define the labeling function using embedding techniques. So here what we can state is, take the embedding of a document and the embedding of the definition and see how close they are.
And then write a programmatic label or a labeling function rule based on the similarity between the definition and the abstract of the document. There is not a single embedding technique that’s available; there are many different embedding techniques, and they are all trying to run different corpuses of generic data.
In fact, this is a topic that was thought of regularly during the whole conference. How can we adapt these foundational models or the models that were pre-trained for a specific task? One way that we did is using weak supervised learning. And here we use a different set of embedding techniques.
Here we have seven different embedding techniques. Then we use the same sort of cosine similarity to measure the distance between the document and the embedding, and then we use that as a programmatic labeling rule. To make it more concrete, shown here, this is for one labeling rule.

So you take the definition, compute the embedding, take the abstract, compute the embedding, compute the percent similarity, and if it is greater than a certain threshold, then we say that this document belongs to this particular climate hazard.
This labeling is done for one labeling function, and we write seven different programmatic labeling rules for seven different embedding functions. So we look at all different labeling functions and try to minimize their conflicts and maximize their overlaps. Eventually, the kind of labels that we will get will be of very high quality.
We also scaled this approach. We have seven different embedding techniques and 18 different climate hazards. This presents a lot of parallelization opportunities and the national labs have really powerful supercomputers at our disposal, many GPUs.
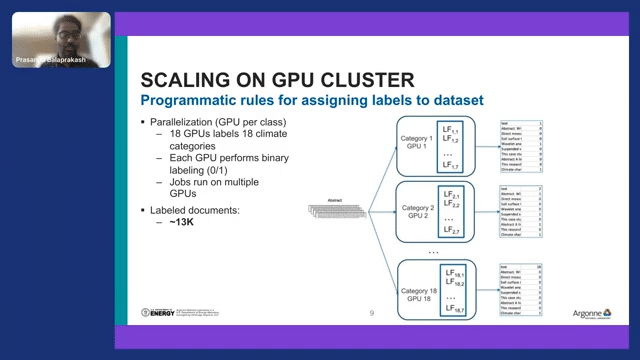
So one thing that we did is assign one GPU for each of the labeling functions. One GPU for each climate hazard. And that climate hazard, we compared across different labeling functions, and then we can label, and then finally we can get multiple labels. So this is a multiclass label, which means that a document can belong to more than one climate hazard.
We are also investigating how to parallelize the labeling function itself since there are similar labeling functions. At the moment we didn’t parallelize this part–different labeling functions within a single GPU. But that’s something that we are pursuing and trying to parallelize to speed up this part. Using this approach, we labeled 13,000 documents using 18 GPUs within 12 hours. We have a very good set of labels from the climate corpus.
So the next step is using those 13,000 labels as training data to train a model. In this case, we trained a multilabel classification using a classifier chain, where each classifier works on a particular embedding technique.
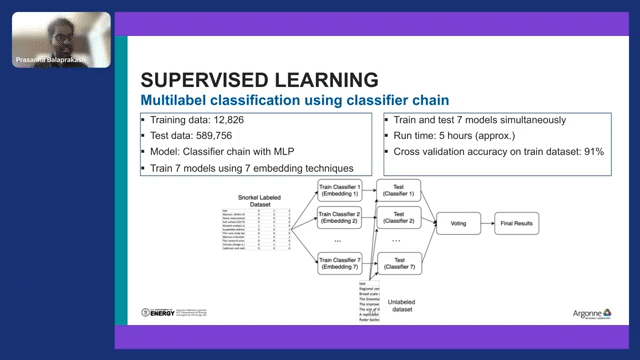
And then we combine all the classifiers and use the wording mechanism to arrive at the final results. So weak supervision generated labels used as training data and trained a classifier chain to finally label the entire 600,000. Out of 600k, 30k were used as training data.
This process took five hours. Essentially, within a day, we managed to label a corpus of 600,000 scientific articles for different climate hazards and national critical functions. That’s a transformational capability that will fundamentally alter the way that these infrastructure analysts and the climate scientists are looking at the scientific articles.
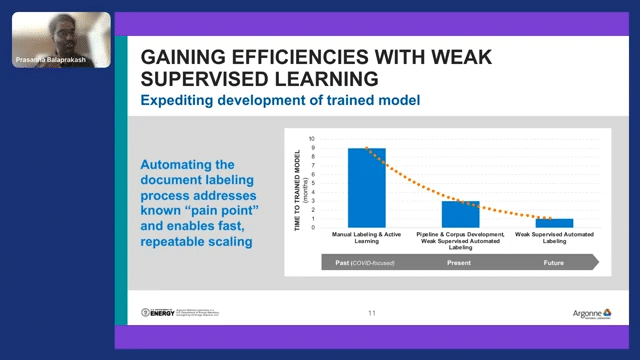
This is a quick summary of how much time we potentially save by adopting the weak supervised learning in the workflow that I mentioned. Previously we used manual labeling, and we even used active learning to identify the documents to label, and use the humans in the loop to come up with good labels for the documents.
In three or four months, we had 300 to 400 documents of labels. And again, those labelings have problems–they were unsure, it has its own bias issue, it’s a personal judgment, and so on and so forth. Then with this pipeline, we drastically reduce the time to label the documents. And with this weak supervised learning, we even further reduce this.
This is a process that, once we build it, we can then generalize it to medical science literature or to quantum materials, and so on and so forth. There are multiple areas where we could take this and repeat the same process to analyze multiple corpuses related to particular domains.
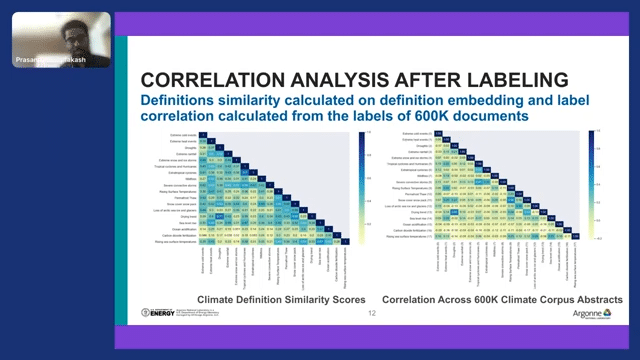
Now, labeling is a very important process in our whole pipeline, and you can see what else we have done on top of labeling. Once we had the label, we looked at the correlation between different climate hazards. So this is a definition, this is another definition, we compute the embedding, and then compute the similarity between the embedding.
And this is the correlation mappings that you can see. The darker color indicates the higher correlation, lighter color indicates less correlation. And the second plot is actually correlation across 600,000 documents. So here we took the labels that belong to that particular document, and then we looked at the correlation between the labels.
There are several interesting trends. In fact, the climate definition similarity score on the right trend, which is most blue, the drying trend and drought is still a recurring thing, even if you look at the articles. But the overall correlation is reduced–so is it really the case? Are the definitions and the articles that are talking about those definitions entirely different or not? So this is like a 10,000ft view of 600,000 documents, and gives you the trend between correlations of the climate hazards and the related concepts.
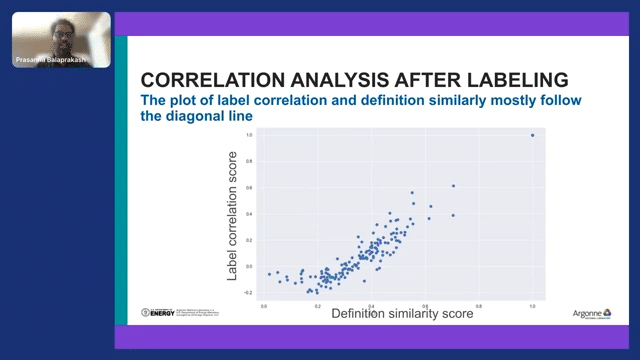
This is another way to look at the correlation model. We can see the document definition similarity score correlation, and along the level correlation score. If you do a correlation plot of these correlation values, there is still a strong correlation that was exhibited in the corpus.
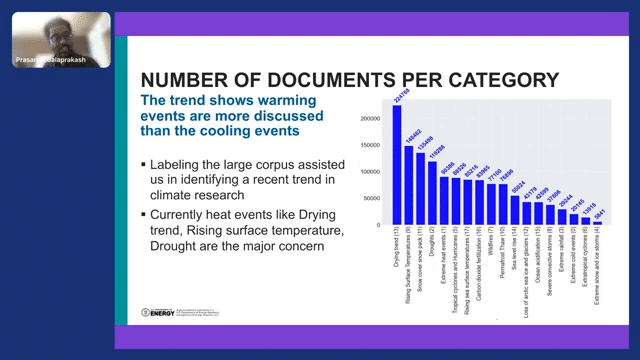
This is another high level overview analyzing the trend. You have 600,000 documents and you have the labels on all 600k documents. Now you can go and do the histogram of those things. And you can see the trend. There are a lot of articles talking about the drying trend, the rising surface temperature, the snow cover, snowpack, droughts, and so on and so forth.
So the general trend shows that there are more articles talking about warming events than cooling events. So the cooling events are fewer in this corpus compared to the warming trends, which makes a lot of sense because there’s a large amount of literature talking about drying trends and droughts.
This highlights another thing about programmatic labeling. If we have labeled this document with this distribution, then we have to worry about the class imbalance, right? And the class imbalance opens up several other problems. But here, we don’t have to worry about it because the programmatic labels are independent of the number of labels in the government. So it’s all about the document similarity and the cosine distance. So we remove the bias due to the class imbalance using programmatic labeling techniques in Snorkel as well.
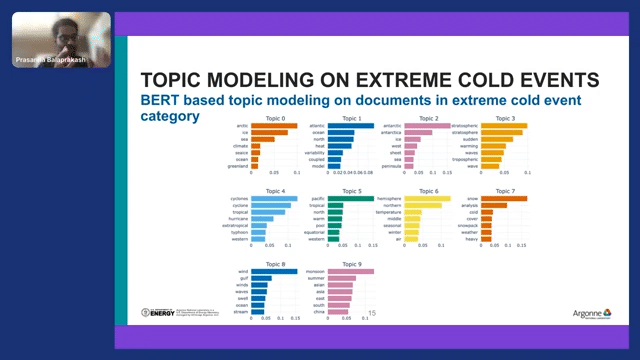
Once we have labeled the documents, now we take all the documents in the extreme cold events—”extreme cold event” is one climate hazard label—and extract all the documents from that particular label, which we can do because we have labels.
Then we can apply topic modeling on those documents that talk about extreme cold events. Here is the BERT-based topic modeling that we could extract from things like “Arctic Sea ice,” “Atlantic Ocean,” “heat variability,” “Antarctica,” articles talking about extreme cold events in Antarctica, “stratospheric sudden warming wave,” and so on and so forth. The ability to do that within seconds—the climate scientists are blown away with this capability. They were pretty excited looking at these results. Even for NLP folks, this is a pretty remarkable thing. But for climate scientists, this is a big thing.
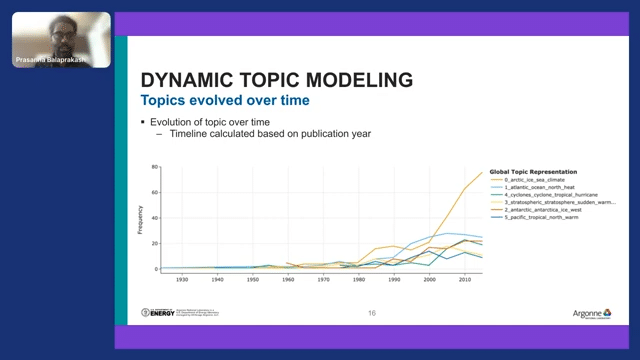
We can also plot that topics evolve over time. For example, the “Arctic Sea ice” climate topic is growing in trend. So the climate scientists went back and asked “Okay, why is there an increase in the trend?” Then they went into some other analysis. So you can pick a topic and pick a category and then perform this kind of analysis.
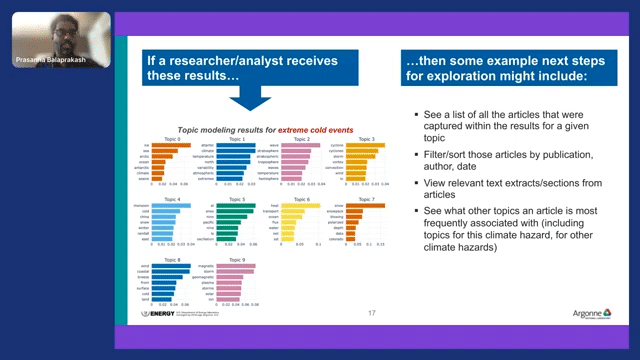
The ability to label a large corpus of documents in a very short period of time allows us to do many other things as well. For example, here is the topic modeling from the “extreme cold events.” What other things could we do? One could subset the article, one could subset a set of articles from certain days, you could do text extracts, you could do text summarization on those and provide a much more synthesized view of hundreds of articles to climate scientists.
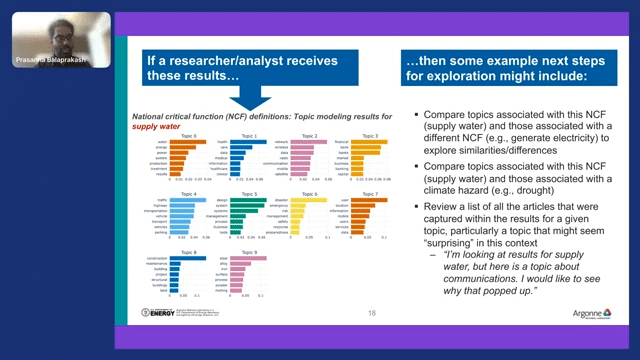
Now we are looking at categories from national critical functions, and here is a “supply water” label. So “supply water” is a label, and we extracted all the documents within supply water, a national critical function, from the same corpus.
If supply water is a national critical function that we are interested in, what are all the potential climate hazard labels that are associated with supply water? Is there a trend we can extract? What are all the major climate hazards that are going to impact the water supply of the country? Those are potentially interesting analyses one can do.

This is another example where we can now take “snow cover” and “snowpack”—we can combine two topics. And then we can look at another climate hazard, which is droughts, and now we have three different groups of articles. Now we can merge all of them and see the common trend that emerged from “snow cover,” “snowpack,” and “droughts,” which are completely different climate hazards. But is there any commonality between these?

Because we are all working at the semantic level, this kind of analysis is possible because it’s not just based on the keyword. This is another functionality that we could build on top of the labeling function. Another thing is, given a single paper in the corpus, we can say which climate hazard or critical function this particular document is related to, and which of the topics is most frequently associated with the climate hazard that this particular paper is talking about. We can provide that sort of instant feedback for a paper that a scientist is interested in.
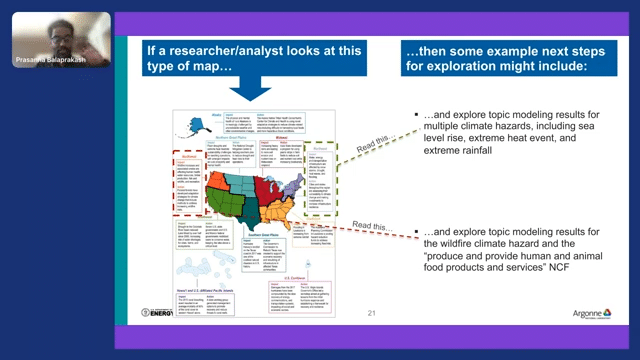
This is something very interesting that we are doing on top of all this—identifying mitigation strategies that are adaptation strategies which are geographically specific. For example, we can take all the labeled documents and then we can do named-entity recognition to identify the places that are mentioned in the documents, and then we can cluster the documents based on the geography. Then once we have both this geographical cluster and also the temporal cluster, then we can use both these broad sets of documents to identify if you’re talking about the Pacific Northwest. What are all the climate changes that are particular to the Pacific Northwest? Which may be different from, let’s say, Texas. If that’s the case, what are the mitigation strategies that these articles are talking about, that are specific to the Pacific Northwest? We can do this kind of analysis on top of labeling documents.
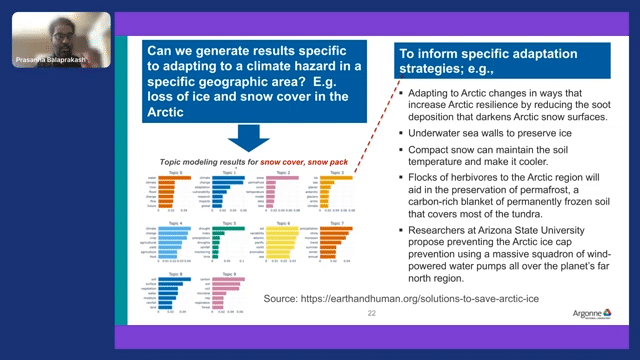
This is an extension where we can ask, “What are all the specific adaptation strategies for the Arctic ice?” And one could potentially extract different articles that talk about climate adaptation strategies for addressing the snow melt in the Arctic region.
I’m almost done–send out acknowledgments to the lab, the internal funding from the Argonne National Lab, Argonne Leadership Computing Facility, who provided the computing resources, and Hugging Face, for providing us with all the pre-trained models, and more importantly, the open source version of Snorkel—without which we wouldn’t have been progressed this much. So thank you to the open source community, and open source software.
Climate change impact with Snorkel-enabled NLP: Q&A
Piyush Puri: Thank you, Prasanna, that was awesome. Thank you so much for the presentation, but more broadly, thank you for all the important work that you’re doing in regard to climate change. We’re truly humbled by what you’ve shared with us today. There are a few questions. I think we have about two minutes to get to them if you don’t mind. One of them is, how can people learn more? How can they see this presentation or get in contact with you if they want to learn more about what you’re doing here?
Prasanna Balaprakash: Absolutely. So the research that we do is open science, open research at Argonne. I’m happy to provide more information. We are working on trying to make this workflow open source as well, because we built on open source, it’s time for us to give it back.
PP: Should we just look up Argonne National Laboratory and your name?
PB: Yeah and my name. Please feel free to reach out and I’m happy to provide more info.
PP: That’s awesome. I’ll just pick one question here: “it seems like the same embedding methods were used for both the label generation and the final classifier. Were you worried about this being circular? Did you do any spot check of either the weakly supervised labels or the classifier output with some human experts?”
PB: Okay, so we didn’t do a spot check. That’s something that we are still trying to understand—if there is a bias because of this. The way that we built this classifier and tried to combine them, we are hoping to understand that bias issue. And related to that, on the modeling side, we are trying to see if we can build in samples and try to get some sort of uncertainty, and use that information to gather a little bit more information. But this is a fantastic question. If you have ideas how to do that, I’m happy to chat. Please let me know how to do that. We don’t know.
PP: Cool. And we have one more that I’ll throw your way before we wrap up here. What was the advantage of using seven different embeddings versus the two-to-three best?
PB: So that’s an interesting question. Because the embeddings are all trained in a different way, right? So apriori, we don’t know the right embedding for the corpus that we are interested in. Let’s say we have a foundation model that is trained only on the scientific literature or only on the climate scientific literature, we’re good to go, right? We can reduce this and use that one. At the moment, we don’t know the right embedding technique because it’s very data-dependent, right? On which corpus, this particular embedding is trained, and how we trained it. We don’t have a metric to assess how good the embedding is for the climate corpus, and more importantly for the climate hazard definition descriptions that we have. So that’s why I said, “Okay, can we use all of this and let Snorkel take care of it?” So Snorkel’s weak supervised learning will look at all the differences and all the commonalities and minimize the conflict and maximize the intersections and come up with a strategy to do this.
Catch the sessions you missed!
The Future of Data-Centric AI 2023, our two-day free virtual conference, brought together thousands of data scientists, AI/ML practitioners, researchers, and the AI community at large to hear about and discuss the latest trends and research in data-centric AI. If you registered for the event but didn't see all the sessions you wanted, you can now catch up. The recorded sessions are available for registrants at the same Zoom portal as the live sessions.

Recommended articles
View all articles

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•

The Art and Science of Building AI Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build AI benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents with
June 16, 2026
•
Snorkel Team

Cua-Bench: benchmarking computer-use agents on professional software
TL;DR We built a benchmark of 25 expert-authored KiCad schematic-editing tasks and ran a frontier computer-use agent against them. The headline numbers: 1. Why build a computer-use benchmark for electrical engineering? Most computer-use benchmarks today live in the same handful of apps: web browsers, file managers, generic productivity suites. Those evaluations are useful, but they share a structural weakness —
June 15, 2026
•
,

