Vijay Janapa Reddi, professor at Harvard University, gave a presentation entitled “DataPerf: Benchmarks for data” at Snorkel AI’s 2022 Future of Data-Centric AI conference. The following is a transcript of his presentation, lightly edited for readability.
Thanks for everybody’s time and attention. I’m excited today to be talking about DataPerf, which is about building benchmarks for data-centric AI development. The talk primarily focuses on three main goals. First, I want to talk about: why do we need benchmarks? Why are benchmarks critical for accelerating development in any particular space? Then, I’ll talk about why we specifically need to focus on building good benchmarks in order to enable the data-centric AI movement that we’re all excited about. And third, I’ll get around to exactly what DataPerf is and how DataPerf is bringing together various efforts from academia and industry to try and pull together a coherent set of benchmarks for data-centric AI development.
With that said, I’m actually a faculty member at Harvard, and one of my key goals is to help—both academically as well as from an industry perspective—work with MLCommons, which is a nonprofit organization focusing on accelerating benchmarks, datasets, and best practices for ML (machine learning). I’ll be talking about some of the work that we’ve been doing in this space as a collaborative effort across many different organizations on DataPerf.
First and foremost, let me start off by talking about why or what does a benchmark really mean? A benchmark in any given space is fundamentally a standard or a reference point against which we make comparisons. Benchmarks are extremely critical. This spans many different areas.

However, no matter how you look at it, it’s true that benchmarks allow you to fundamentally be able to make comparisons of different solutions. You have a standard reference point, and because everybody’s looking at that standard reference point, we can compare whether system A is better than system B, dataset A is better than dataset B, and so forth. That comparison is actually extremely important because it fundamentally allows us to make informed selection choices, without which it’s really hard to know if A is better than B.
It’s also extremely critical to have good benchmarks because they allow us to measure progress. Without a clear set of agreed-upon benchmarks, it’s hard to say if we are truly making progress in the field, because you might be speaking two different languages, effectively. Saying that, “I’m better than you,” but if we’re not talking about the exact same baseline, then it’s kind of hard to compare. So, measurement is a critical aspect that comes out of building good benchmarks.
Ultimately, what it allows us to really do is to raise the bar, effectively, and make sure that we’re making advancements in the field in a very systematic way.
In order to get good benchmarks, one can’t just go out and build a benchmark independently and toss it out, because one of the issues that comes about when you’re trying to build any kind of standard reference point is that you need to have a very systematic methodology that is both rigorous and fair across industry needs, which often tend to be very diverse and different. In order to be able to do that, what you really need is to pull together the community and be able to work as a community despite having competing interests, for instance. To be able to get that community consensus, or grudging consensus, as we often like to call it with MLCommons, to be able to build that standard benchmark.

If we’re able to do this—despite conflicting answers—if we’re able to get alignment on the benchmark, then it creates a standardization of different use cases and workloads, which is good because that allows fair and effective comparisons. This allows comparability across different hardware and software methods. For instance, I might have a machine-learning system A, versus a machine-learning system B. I can do comparisons against that. I might have dataset A, versus dataset B. I might be able to do comparisons against that. That comparability is critical for making informed choices and driving the innovation forward.
Of course, I talk about things here in the context of system compromises because originally we built benchmarks around machine-learning systems, but increasingly we’re moving toward data and we want to be able to understand: what are the qualities that we have in datasets?
Ultimately, what we want to have is verifiable and reproducible results when we’re comparing.
Now, this at large sort of stands true no matter what you’re talking about. Whether it’s a dataset or whether it’s a machine-learning system or not, it stands true. Benchmarks are fundamental to accelerating the field.
If you look back in history, generally we’ve had very well-established benchmarks that have helped us accelerate the field. For instance, if you’re talking about microprocessors, I don’t know whether Intel’s has a better chip or AMD has a better chip. How do you compare them? We have bodies like Spec, for instance, that create standard reference points that allow us to compare these processors. What do we do? We tend to take a bunch of code, which is traditional C, C++ kind of code. Then, we tend to take a compiler, we say, “okay, we can lock in the compiler. We can lock in the code,” and we say, “okay, this is something that the machine has to run.” And then we run it on the specific processor that allows us to then be able to systematically compare whether silicon A is better than silicon B.
This is actually what has accelerated much of the progress that we take for granted around general-purpose computing systems. This is in fact what Dave Patterson, the Turing Award winner, says accelerated or created the golden age for CPU microarchitectures.
Similarly, over the past four years or so, one of the things that we’ve done was created benchmarks for comparing machine-learning systems. Where we have a complicated machine-learning system stack—system, including the hardware and the software. And what we did there was in order to say if system X was better than system Y while running specific models, we said that: “Okay, we’re going to freeze the dataset, a.k.a., something like ImageNet, for instance, and then we’re going to freeze a model.” We might pick ResNet, for instance, or SSD, or something like that. We pick a network and we pick a data set. We lock those things in, and then everybody takes that specific “benchmark” and then runs it on the system. Then we evaluate how well a specific infrastructure is doing, be it for training or inference.
These kinds of benchmarks have played a very critical role in accelerating the space, especially in ML. For instance, thanks to MLPerf’s training benchmarks, what we have seen over the past couple of years is a remarkable improvement in terms of performance. What the plot here on the X-axis is showing is just, from 2018 up to 2022, relative performance from the best system that we had because of a good benchmark like MLPerf and seeing what the improvement was with respect to “Moore’s Law” (because Moore’s law has been slowing now).
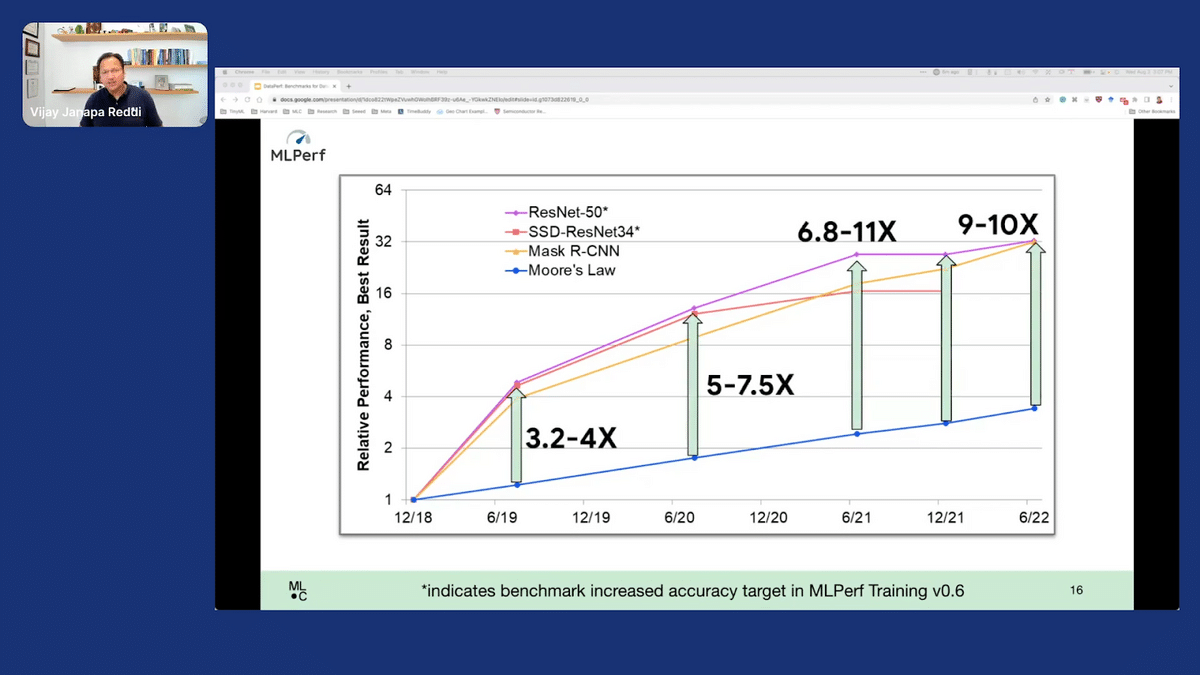
Generally, the point is that if we had good benchmarks, what we can do is: one, make systematic improvements. As we are seeing down here, generationally, we’re seeing improvements from one point in time to another point in time. And [two]: it allows us to push innovation forward.
Another good thing about benchmarks at large is that they allow us to drive progress and transparency. Everybody can effectively look at the data and say, okay, something got better. The key thing behind benchmarks is that what gets measured gets improved. If we don’t measure it, we can’t improve it.
Furthermore, it drives some sort of a community consensus in terms of understanding: what does the industry, at large, value? In the context of machine learning, obviously, it’s a very complicated stack. In order to drive the machine-learning ecosystem forward, there are many different areas, for instance, where we need innovation.

This spans from the scale of the systems—what your backend infrastructure looks like, what your software compilers look like. What kind of algorithms are you using to run your models? What’s the silicon substrate? What’s the microarchitecture substrate for running that machine-learning code? And ultimately, of course, there is data. I would argue that by and large, with the exclusion of building benchmarks of data, all the other things on the left-hand side—the scale, the software, the algorithms, the architecture, the silicon, and so forth—have actually been studied really well in the context of building systems and making sure we can understand what’s better than another. But in the context of data, we have yet to have a very systematic way of improving the datasets that we have in ML.
If you look at NeurIPS, for instance: what have we done over the past decade? This plot, which is effectively looking from 2012 to 2021, is showing that we have invested a huge amount of effort in improving the models in the ML context. We spend billions of dollars, be it in academia and industry. A lot of investment goes in. But, when it comes to the datasets themselves, it’s almost an afterthought. We just take the dataset, we say, “okay, we took this dataset and we ran ahead and we built this new architecture.” And that’s great, but it’s extremely critical that we focus on data because if we’re not careful about data we get into some serious problems, as I’ll talk about.
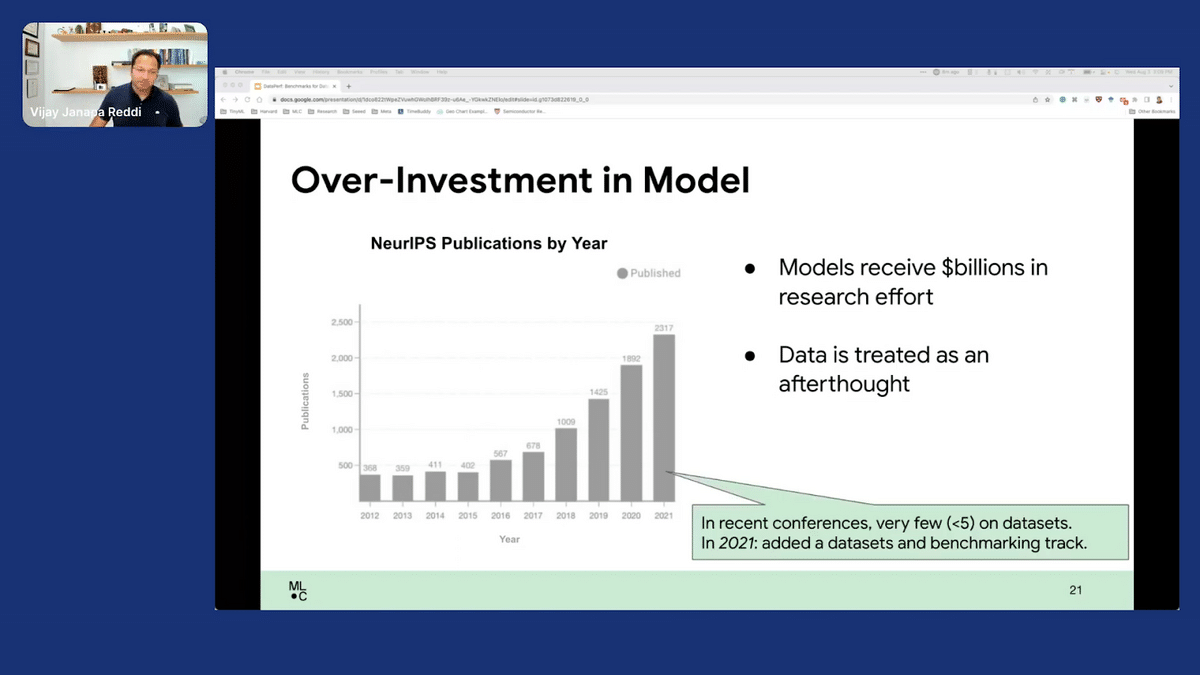
In fact, it’s only last year that NeurIPS had the first focused effort on datasets. They created a datasets and benchmarking track to try and improve the data, effectively trying to go after reproducibility and targeting the other half of the machine-learning ecosystem, which is not just a model and systems, but also the datasets.

If you’re not careful about data, we can get into some serious problems. The Tacoma Narrows Bridge is a good analogy. The Tacoma Narrows Bridge collapsed in 1940. It collapsed because of aerial elastic flutter. This is basically a different approach that they took to actually building the bridge compared to traditional means of doing it. The reason it actually failed, I would argue, is because they didn’t really have good test sets for evaluating how this new approach that they’ve taken to building this bridge would perform once it was completed.
The point that I’m making is that if we don’t have good mechanisms or good litmus tests around data, when data is so critical for machine learning, then we can end up with these catastrophic issues in machine learning.
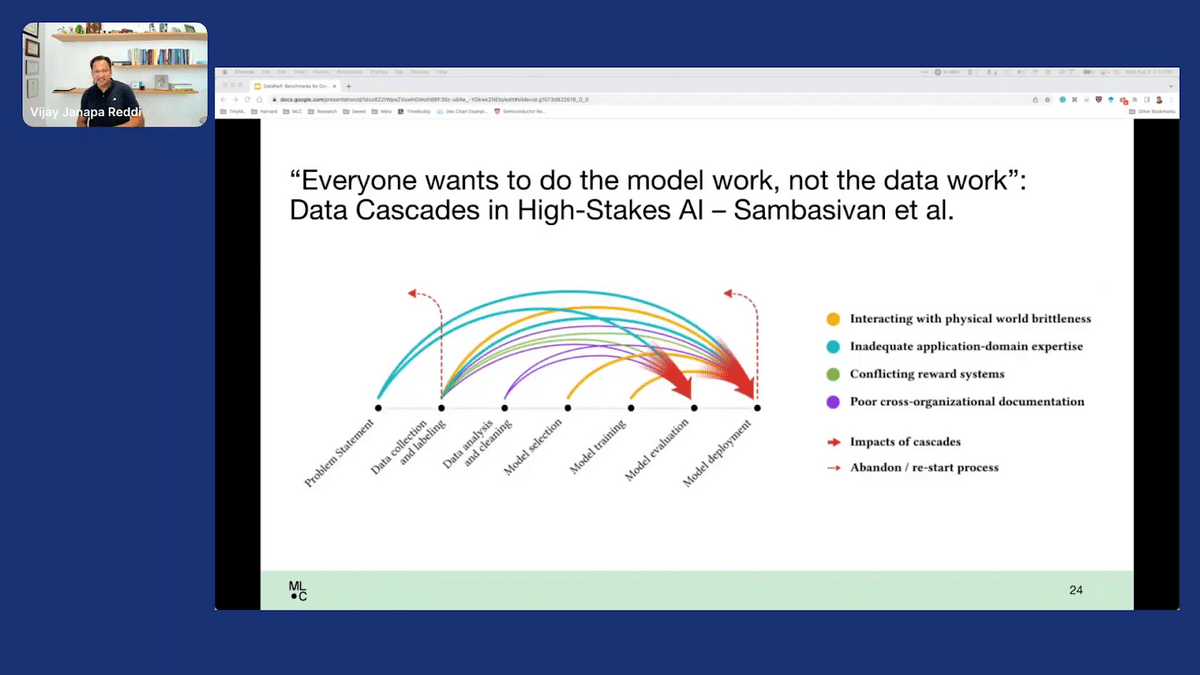
It’s well known that you can actually have data cascades, because often in machine-learning systems (since everything starts with data) as you progress down the pipeline of actually putting things into production, where you’re deploying the models on the right, what you see is the amount of potential failure points that you’re going to have is going to be quite critical. I’d strongly recommend everyone to read the data cascades paper (“Data Cascades in High-Stakes AI,” Sambasivan et al.) because it really lays out the point about why it is so important that we take a very close and hard look at data.

In addition to having data cascades, another problem with not looking at our data in a systematic and measurable, quantifiable way is that you can have model quality saturation. In fact, if you look at some of the datasets and you look at how models perform on those datasets, you would see that the models are effectively saturating in terms of what they’re capable of doing. This is not to say that: “Wow, we have somehow cracked the code.” It’s really fundamental in terms of: what datasets are we using? What do our training sets look like? What do our test sets really look like? And if those are not actually good enough to really challenge, then innovation itself is effectively going to stall. This is why it becomes extremely critical to have not only good principal benchmarks but also to actually benchmark data.
If we look at the ecosystem at large, we have awesome things where we have been looking at building models. For example, Kaggle does a good job, where we freeze the dataset; we optimize the model, and the infrastructure is whatever you choose to pick out, and you can go after that.
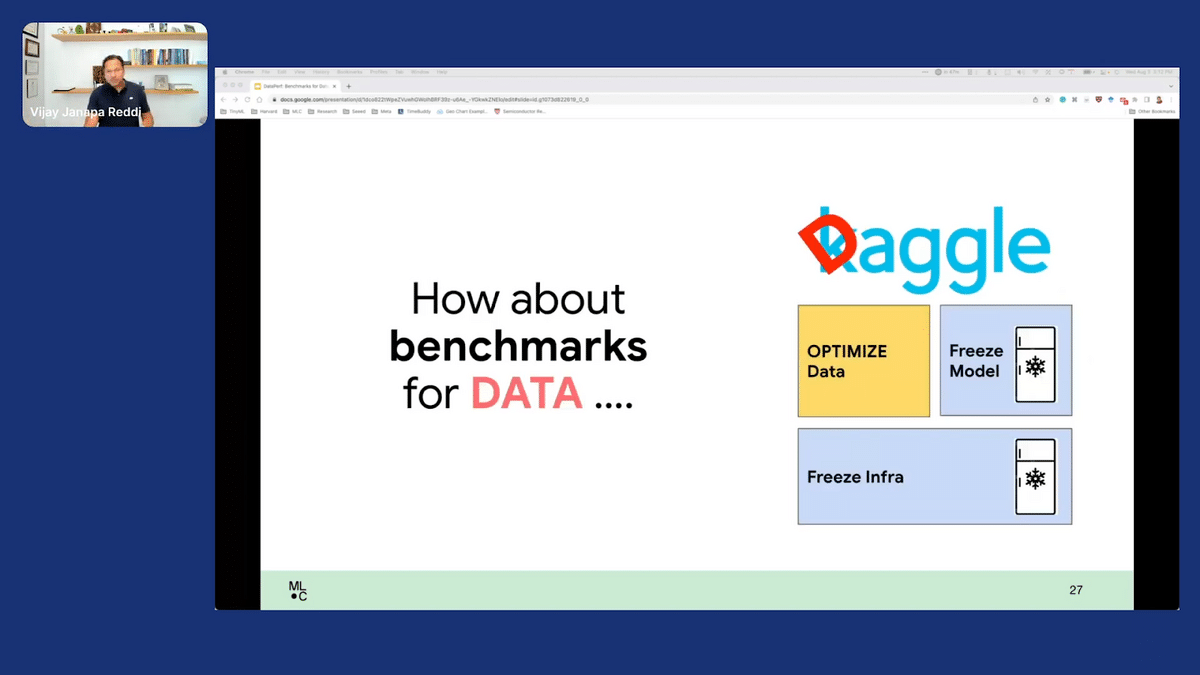
The question that we have in our head is: how do we build benchmarks so we can try and improve or optimize the datasets that we actually are working with? Since data is our rocket fuel, if we don’t optimize that, everything else really is almost not going to work in practice—because data is effectively driving all of that. So, what we wanted to do was build good mechanisms for actually benchmarking machine-learning data.
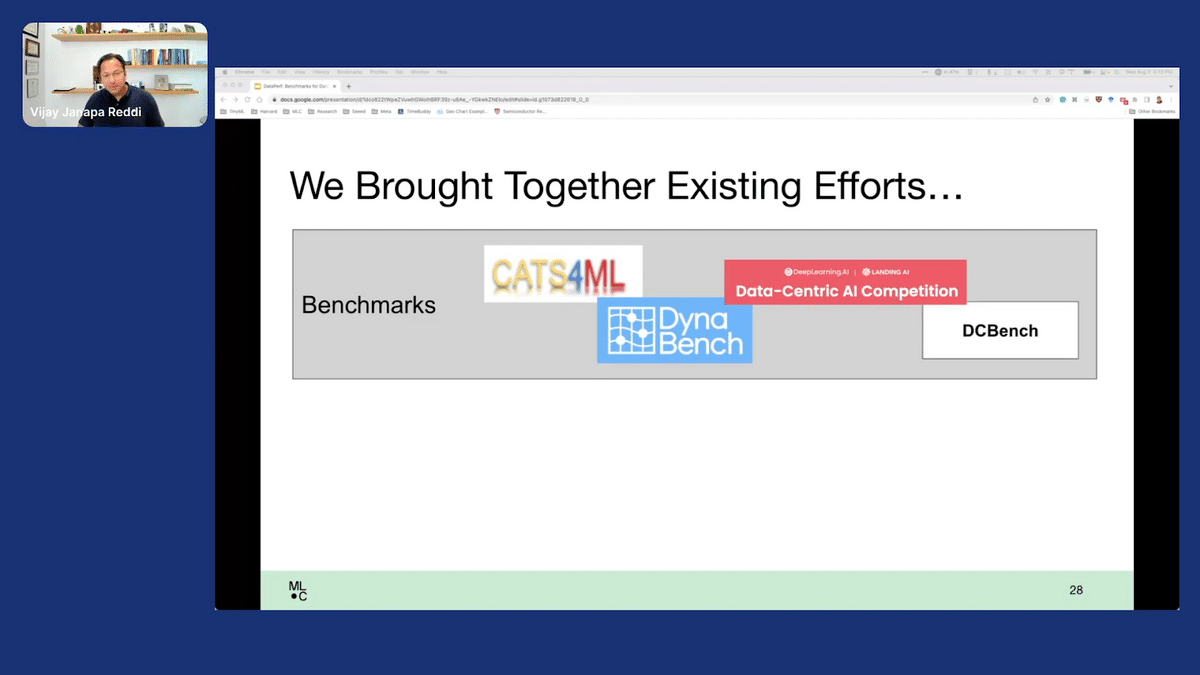
Now, we didn’t try to do this from scratch. One of the things that we’re trying to do is bring in existing efforts that are going on in this space.
People have been building good benchmarks. For example, CATS4ML is an effort from Google that looked at adversarial trainings or mechanisms. There’s Dyna Bench from Meta, which has been looking at various ways of looking at the training and test set evaluation.
Then, of course, Andrew Ng ran the data-centric AI competition. In fact, he’s part of the team that’s actually building DataPerf out at scale, where in a data-centric AI competition, they basically looked at Roman numerals and tried to figure out: what’s the best data augmentation method, or what sort of techniques are able, on the data side, to improve the performance of the model.
There are many other efforts. DCBench is an effort from ETH Zurich and Stanford University. There are lots of different efforts that are going on that are bubbling up all over the space. What we are trying to do here through DataPerf is try and bring all of this collective wisdom that is starting to show up in the industry and try and pull it together in a coherent fashion to drive the industry forward.

Of course, that’s just the data side. Often you also need platforms and infrastructure to be able to do this, because benchmarking data, training models, evaluating, and so forth ends up being costly. We’re basically pulling in some of the existing best efforts that we have here in the community to try and benchmark data.

So far, what I’ve said is we want to do benchmarking. It’s extremely key because it allows us to measure progress and, in fact, make progress. Then I said, we want to specifically benchmark data because if we don’t do that, we can have model quality saturation issues, we can have downstream data cascade issues, and so forth.
If we believe that, yes, we want to actually benchmark the data, the next question becomes: what exactly do we want to do?
Fundamentally, there are only three really primary pillars in the context of measuring data quality. First is how good is your training data? Second is how good is your test set data? Because test set data is really the litmus test that allows you to make a decision as to whether the model’s good enough or not good enough. If you get a poor test set, that’s going to be catastrophic. Then of course, the third piece is not really just the datasets themselves on the training and tests, but it’s also the algorithms that are actually used to construct the data. That’s what we’re actually going after here when we’re talking about DataPerf.

This is the third portion of the talk where I’m actually going to get into what the specifics are around DataPerf.
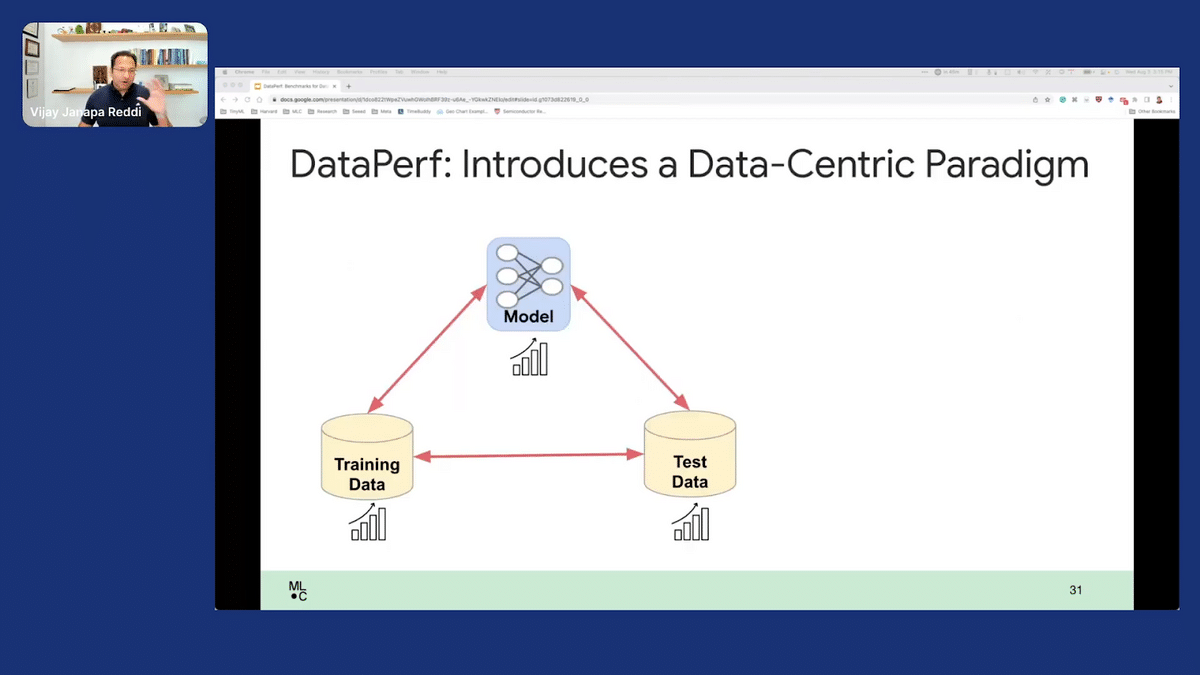
As I’ve said before, what we want to do in the data-centric AI paradigm is to ultimately improve all three core pillars. We want to continue to improve model performance, so we do want to drive that. But we also want to improve—or focus more—on the data. And we want to measure all three things, because if you really want to accelerate anything around ML, you have to tackle all three, fundamentally. We’re trying to shift the over-emphasis that’s in the model space, down into the bottom rows around training and test data.
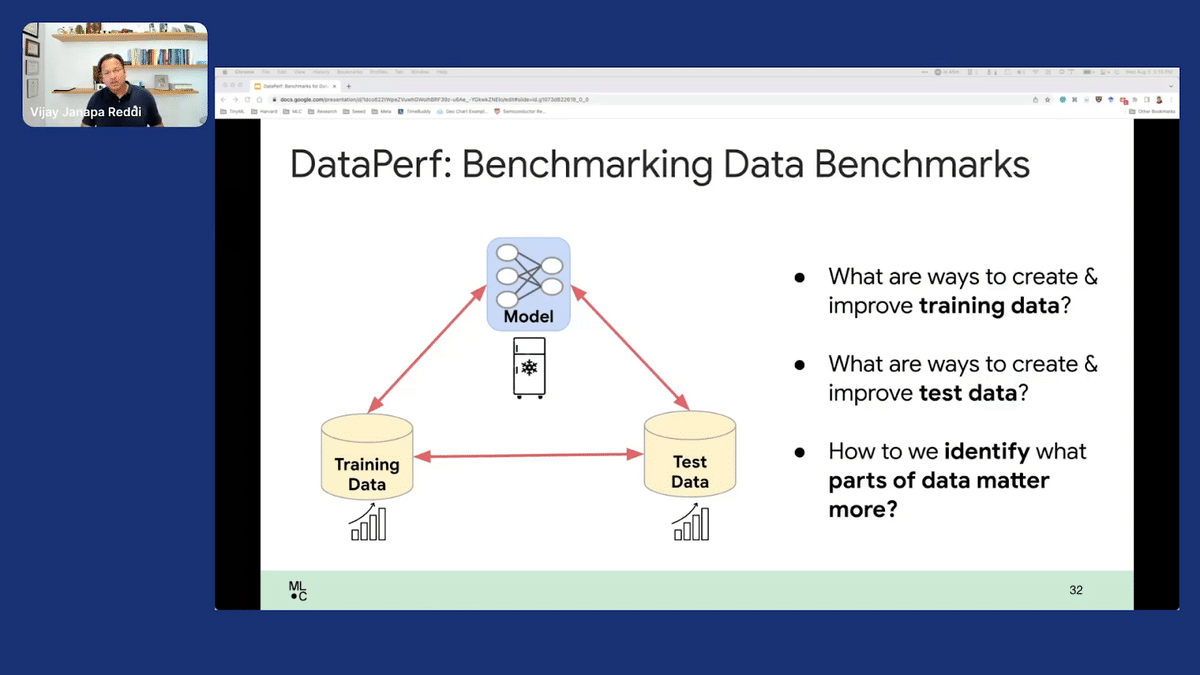
This means what we want to understand: how do we improve the training data? How do we improve the test data? When you’re talking about slices of data that are critical, which parts are more important than another? How do you slice that and whatnot? There are lots of different things that are to be done in this space. To answer these three questions: it’s not like you just have three “benchmarks” and that’s it, you’re done. You have to systematically think about it.
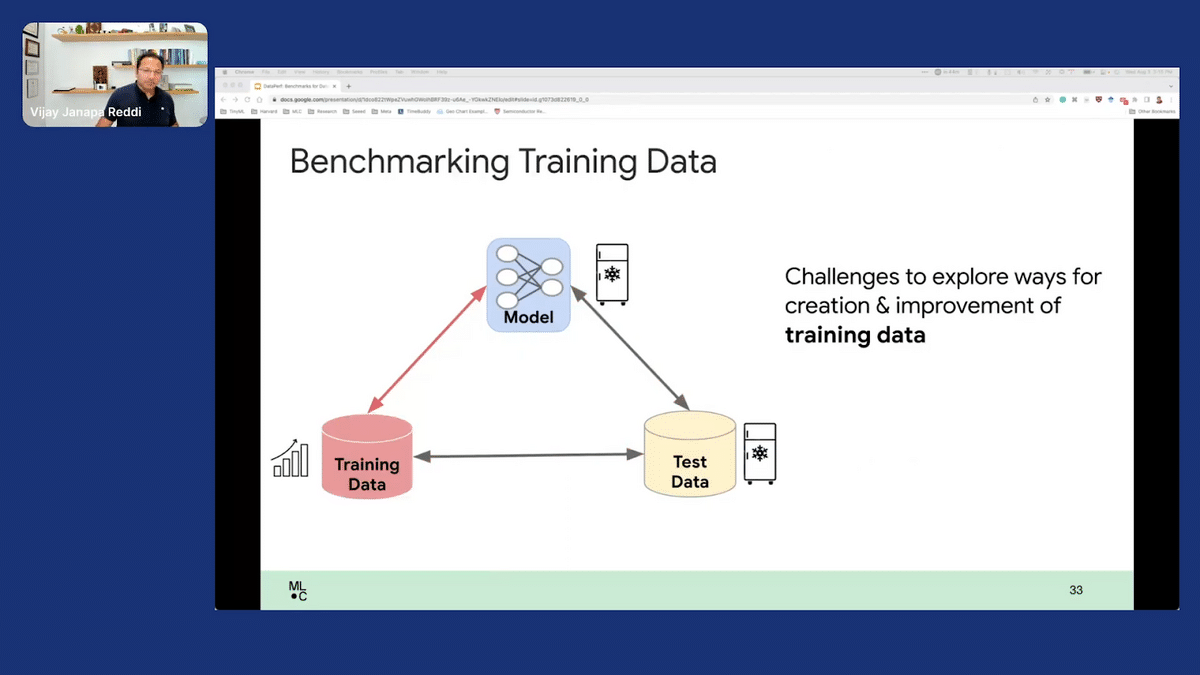
Let’s talk a little bit about the training side. If you want to improve the training, what you want to do is two things. One, you might want to focus on: how do you effectively create a good training dataset? How do we measure how we do that? Another is, you might have a very noisy, large dataset, something that’s been accumulated. I think increasingly, if we plot the historical trend over the past couple of years, what you will see is that our dataset sizes have been getting bigger because we’ve been binging on the fact that “more data is better,” as a general theme. Even though it’s becoming apparent that is obviously not the right mindset to have. It’s the data quality.
Needless to say though, we are going to continue creating large corpuses of data. The key question then becomes: which parts of that data are critical for us? That’s important because, as a bang for the buck, if for instance, instead of having you train on a dataset that is, let’s say, hypothetically, just like 10 terabytes of data, instead if I have you just train on five terabytes of data, and I help you still get a very good model at the end of it, which is getting very good accuracy. I think that’s awesome because now you might have potentially cut down your training times by 50 percent. So, not only are you shrinking the data down to its core set, but you are also effectively having a system-side benefit because it’ll cost you less to train the models. That’s one way to think about the training data.
Similarly, we also want to understand the test set itself because that is, as I’ve said, a litmus test that allows you to determine whether the trained model is good enough for you to release.
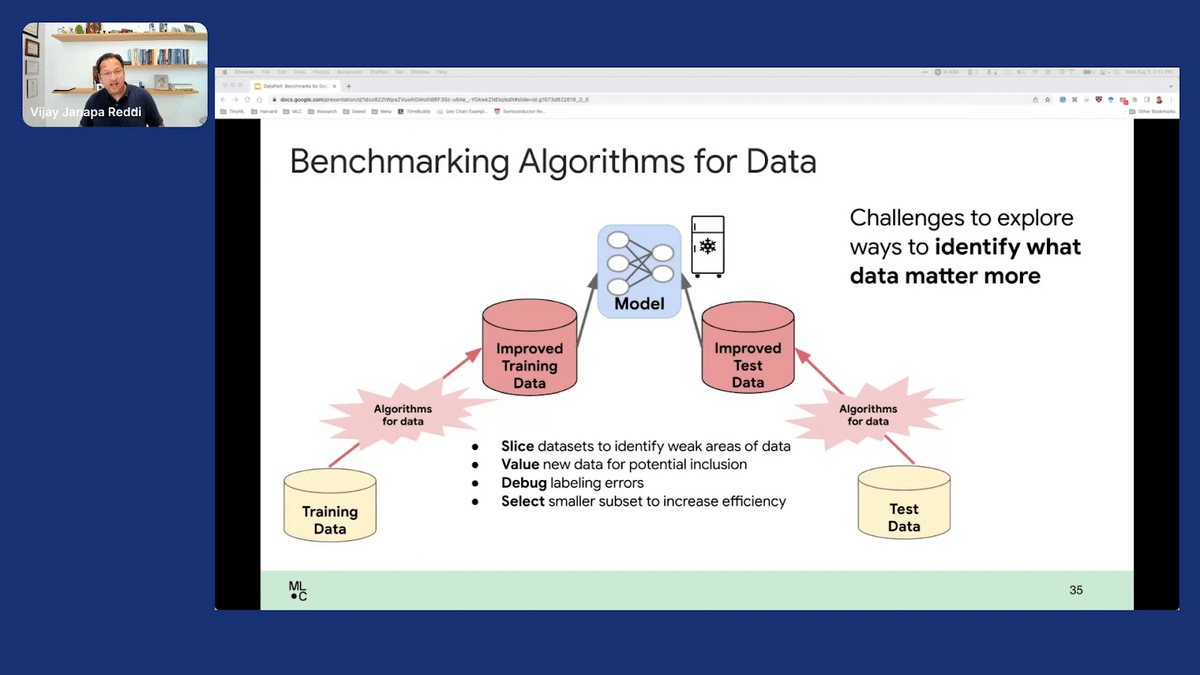
And algorithms. When we talk about algorithms, there are many different ways to slice this. Often when you’re trying to improve your model’s performance, you want to understand: where is the model really struggling? You want to understand those particular slices, and you want to create compliments for your existing dataset to focus on those weak points in order to supplement. You want to have mechanisms or algorithms that’ll help you identify those slices of data that you need.
As I also mentioned, you might need algorithms in order to shrink that large dataset down to the core aspect so you can actually improve efficiency. Then, of course, you might have to debug the datasets themselves. So, what are some mechanisms where we can debug our datasets, specifically in the context of labeling, for instance?
I already mentioned selection.
The last one that I failed to mention is run value, like data valuation. How do you say: “hey, dataset X is better than dataset y.” How do you know that? There’s a data marketplace out there in the wild, where people want to sell you data, but they don’t want to give you the dataset and they don’t want you to train your models and then figure out if the dataset is actually valuable for you. That kind of defeats the purpose. But if you can’t get the data, then how do you convince someone that: “Hey, this dataset that I have is very good for you”? We need to have some ways of comparing the data, and that’s what data valuation is all about.
So, you kind of get an idea that there are many different ways of slicing and looking at this. In order to convert this into an actionable item, what we are trying to do in DataPerf is effectively create data competitions.
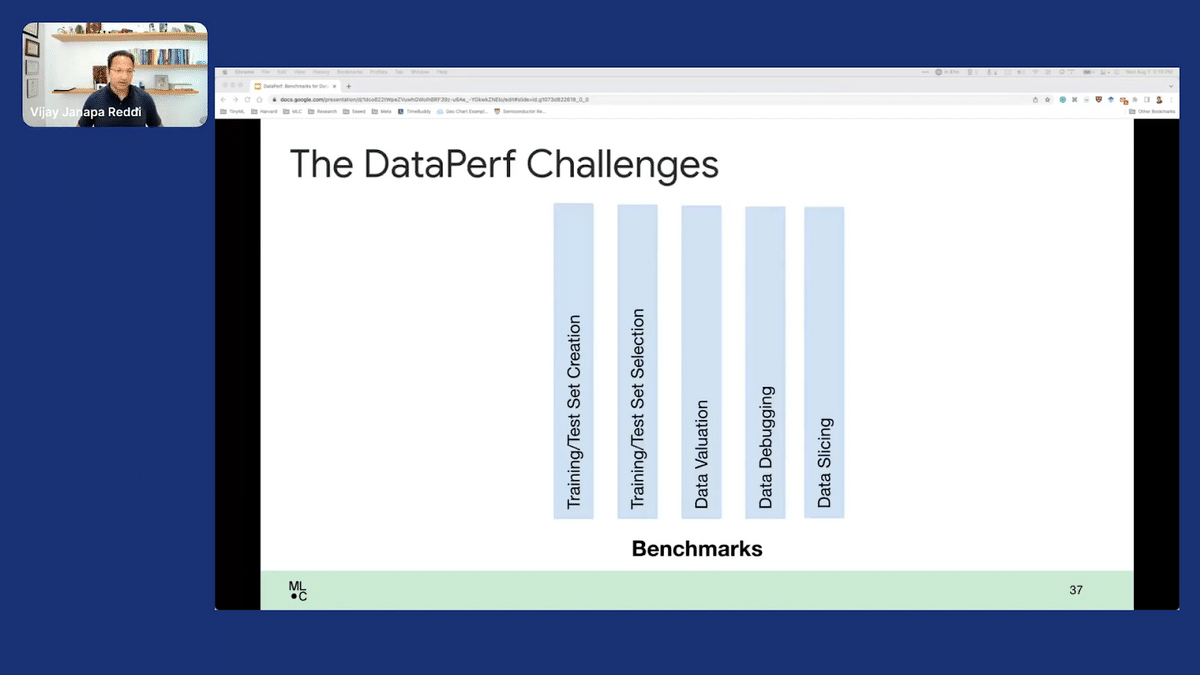
The key thing here is that we want to look at different aspects of building better datasets. For example, as I mentioned, the first one being the training and test set creation. How do you create that? The second one being training and test set selection, where you might have a large dataset and you want to select a sub-piece. Data evaluation, which I just talked about, Data debugging, and I just also mentioned data slicing, all of which I just mentioned in the previous slide. Now, these are the “fundamental benchmarks.”

Where do you apply them? That’s where the tasks come into play. There are many different tasks. You can imagine something like image classification, natural language processing is something for speech processing, and so forth. These are all different tasks you might have, and what we want ultimately is intersection between the two, tasks and benchmarks.

We want to create this matrix of different competitions that we have that span different tasks, but with some core fundamental areas that we really want to tackle—the things in yellow, for instance. That’s what the DataPerf suite of challenges is really trying to shoot for.
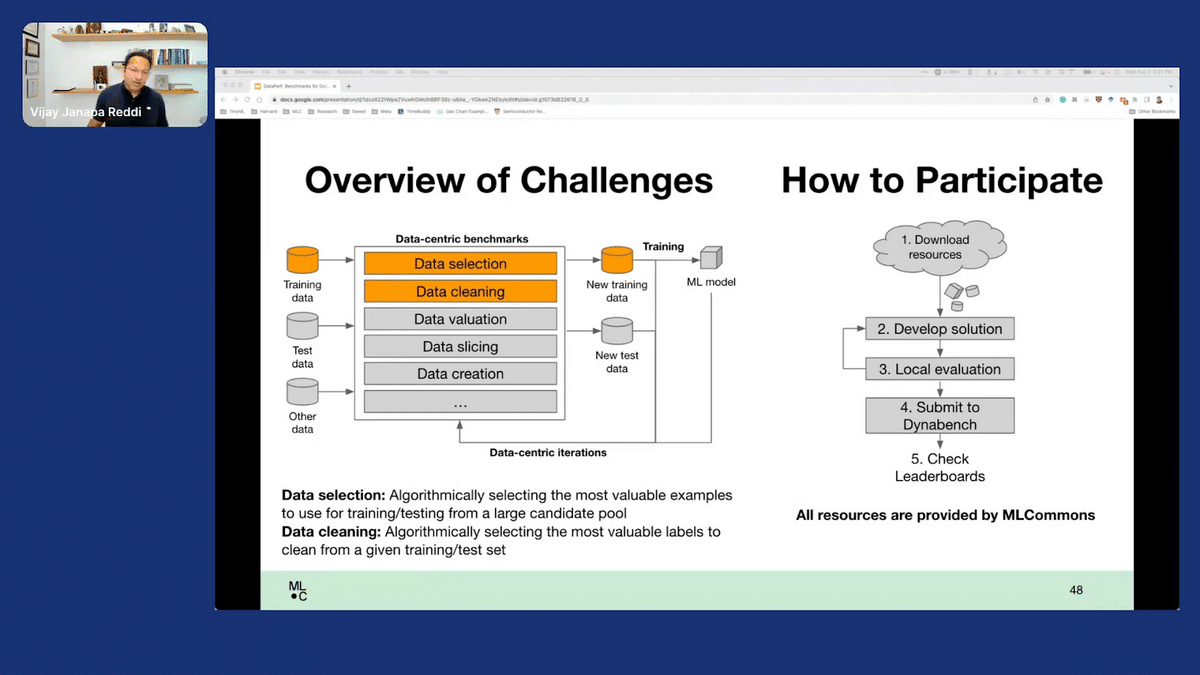
At large, this is how it works. I’ll talk about three examples over this slide.
What we have are, there’s a set of benchmarks that we want to have, as I alluded to. There’s a whole collection of them in there. What we want to do, for instance if we take data selection, is automatically selecting the most valuable examples.
Data cleaning would be automatically selecting the most valuable labels to clean, given a certain dataset. And the way one would participate, for instance, in these two challenges would be, they download the resources. MLCommons provides these “benchmark resources.” You would develop a solution locally. Then you would evaluate and you would iterate it and try to get a good solution, and then you would upload it onto one of the MLCommon servers, which is like the Dyna Bench platform that we’ve adopted from Meta.
Ultimately, the goal is to create a leaderboard where we’re able to showcase this. One of the key things that we’re going after here is that we want to have artifacts that come out as a result of having these leaderboards, which people can readily adopt. Because if we do that, what we end up doing is that we end up creating a vast ecosystem where people are not just competing for the sake of competing. What people are really doing is they’re competing, but they’re leading to artifacts that can actually be adopted. And, voila, that kind of jumpstarts this whole cycle. That’s what we are trying to do in order to accelerate data-centric AI development.

Just to touch on some examples, to be a bit more specific, here’s one challenge that you can imagine that we’re actually working on right now. This is in the context of vision, for instance, which is focusing on the training dataset selection. The goal here is effectively to have submissions that are scored on mean average precision—a very typical metric, right? But the idea is that we want to have a selection strategy that chooses the best training set from a large set of candidate images.
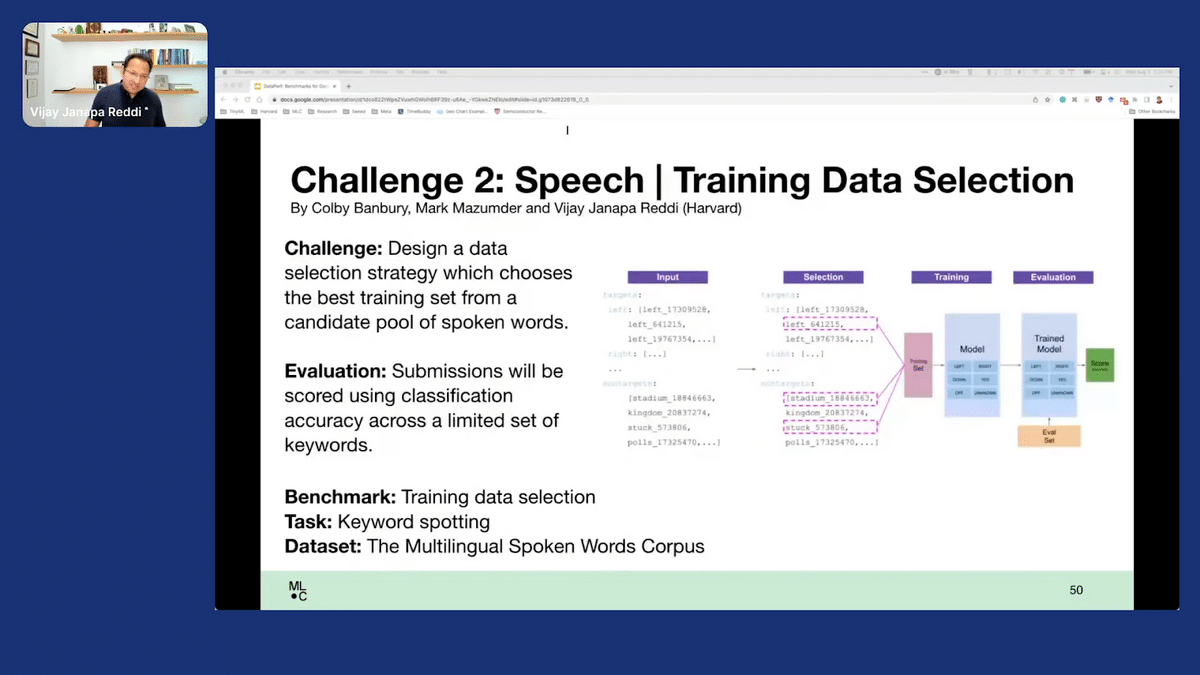
Similarly, we have something that’s in the context of speech. In speech, for instance, we’re focusing on keyword spotting, which is, shipping on billions of devices. What we want to do is, you might have a really noisy, large dataset, like the multilingual spoken words corpus, which has over 300,000 different keywords and it supports 50 different languages. And one of the things that we’re trying to do is, in multiple different languages, you’ll have to choose the best training set from this large, messy pool of potentially noisy data. Then ultimately you’re going to get scored on what those selected keywords do in terms of model evaluation.
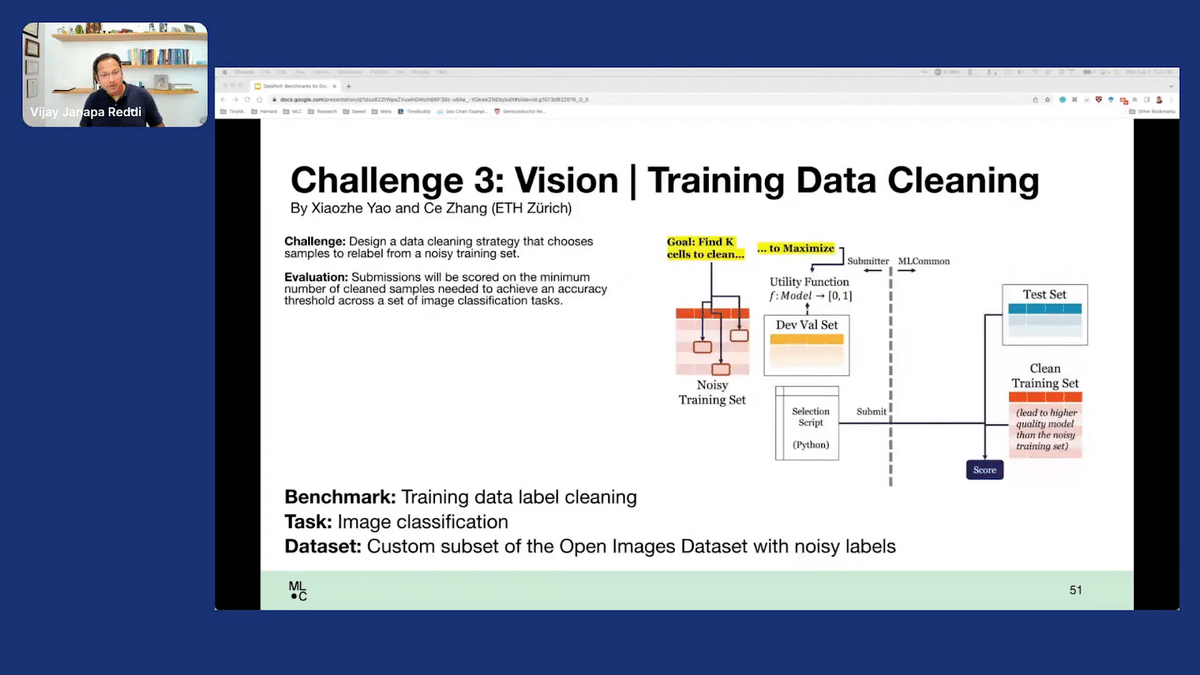
Finally, on talking about data cleaning/debugging, the goal here is to choose a good cleaning strategy that helps you identify what you have to fix.
These are the three initial challenges that we’re launching. I’ll talk about how you can get involved later on.
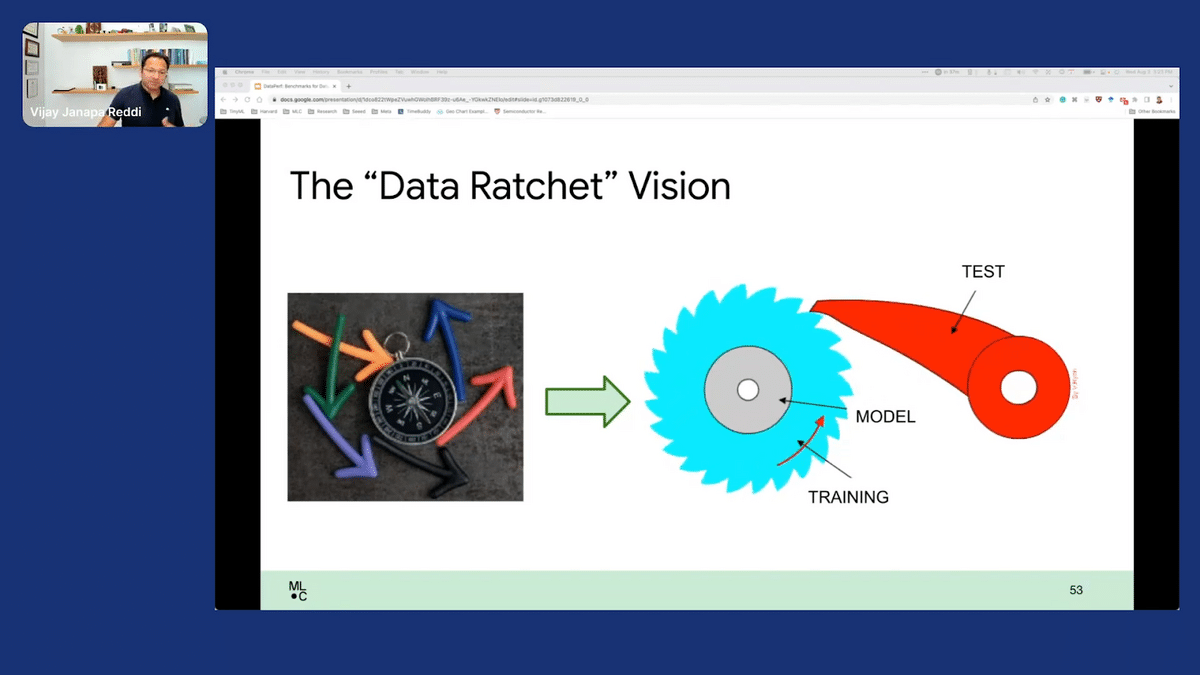
Our vision is, if we start with those three, and then you can expand that into that matrix that I showed you, where you have different tasks and you have different benchmarks. Our vision is to be able to create what we call the “data ratchet.”
The goal is this: first you want to try and improve, let’s say, the training set. Once you’ve improved the training set, then you can use that good training set in order to drive the evaluation of the test set. When you have a good test set, then you can take that next level test set and then try and improve the training set. And this effectively…the ratchet idea is that you constantly continue to improve, you improve one which then pushes the other to be improved, and so forth.
Now, the way to get into all this. I encourage people to just check out DataPerf.org, where we have effectively laid out the vision that I just presented, and what we have there are some links down here you can check out which talk about the specifics of the challenges. You can go to the GitHub and check out the challenges that we have. Things are still cooking toward the beta stage right now. But we’re looking for interested parties who actually want to take part in this, not only in just competing in the space, but actually defining new data-centric AI benchmarks like the ones that I hinted at.

If you want to learn more, I also encourage you all to check out the DataPerf white paper, which talks about some of the lessons that we learned from running the initial data-centric AI challenge that Andrew Ng championed, which we are now maturing into a much more complex space with many different challenges, as I alluded to.
Our hope is that as the community gets involved, we can try and systematically build benchmarks because if we build a robust set of benchmarks in this space, what we’ll be able to do is progressively get the community involved in driving innovation in the training set and the test set. So, over the next five years or so, the way the models have progressively improved, we will hopefully be able to systematically quantify, measure, and improve machine-learning datasets.
I’ll leave you with these links if you are interested in joining. I’m happy to take any questions you may have now.
___________
Question and Answer section
Aarti Bagul (session moderator): Thank you so much Vijay for that very enlightening talk. I know I’m certainly very curious about all the benchmarks and was opening up the paper on the side.
So, a quick question. I am curious how you’re developing evaluation strategies for a lot of these tasks, like, “Is this the right slice of data to pick on?” I know you touched on it briefly, but for example, I think one problem that I personally think is very interesting is how do you make sure your test set is actually representative of all the variety that you’re seeing such that when you’re evaluating on it, you know that you will do well in the wild? How do you design an evaluation system, for example, that works on that? Do you hand-label various examples and see if the algorithm picks those up? Just curious.
Vijay Janapa Reddi: There was a really tough challenge on the test set because, obviously, it is the critical piece, right? And of course, when you think of the test set, it really is a subjective thing because it really depends on what question you’re specifically going after, because that’s what the test set has to have.
So, one way we’re thinking about this is: Yes, we have some sort of golden ground truth kind of thing that we’ve validated. So think about it three years from now. We’re going to have some agency, maybe MLCommons or whoever, that effectively creates these standardized or certification ML test cases. Because the training set is hard to create and say “Oh yeah, this is the perfect mode.” That really depends on what you’re trying to go after. But we could say, for instance, if you’re going after (I’m just making this up) a security camera, for instance. What are the good characteristics a test set should have for a particular use case within, say for example, a security application? That’s the way we’re approaching it because then we feel like we can constrain the space a bit. Otherwise, it becomes almost impossible to be able to do this.
Short answer though: in order to directly get to your point, is that we haven’t quite figured it out in terms of what the properties need to be and so forth. One of the key things that we’re doing is asking for people who are actually working with this to come in and say: “This is the kind of test that I would want.” The hope is that ultimately we will have bits and pieces that we collect as a community-driven consensus that everybody would say, for example: “Ah, this test set indeed captures all of the different kinds of scenarios that you expect to see,” and everybody has had a say in it.
AB: Got it. Makes sense. So, the goal is at least to start some benchmarks, start a working group, get these groups together, and then even kickstart this process, which is I think a very important step toward this process.
I know we have a bunch of other questions from the audience, but we are also running out of time. If they wanted to contact you, what would be the best way to do that?
VJR: Best way would basically be to simply look me up. You can just type in my name and then shoot me an email. Another thing would be just to check out the DataPerf.org website, which has the mailing list for all the members in the group who can answer questions.
Catch the sessions you missed!
The Future of Data-Centric AI 2023, our two-day free virtual conference, brought together thousands of data scientists, AI/ML practitioners, researchers, and the AI community at large to hear about and discuss the latest trends and research in data-centric AI. If you registered for the event but didn't see all the sessions you wanted, you can now catch up. The recorded sessions are available for registrants at the same Zoom portal as the live sessions.

Recommended articles
View all articles

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•

The Art and Science of Building AI Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build AI benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents with
June 16, 2026
•
Snorkel Team

Cua-Bench: benchmarking computer-use agents on professional software
TL;DR We built a benchmark of 25 expert-authored KiCad schematic-editing tasks and ran a frontier computer-use agent against them. The headline numbers: 1. Why build a computer-use benchmark for electrical engineering? Most computer-use benchmarks today live in the same handful of apps: web browsers, file managers, generic productivity suites. Those evaluations are useful, but they share a structural weakness —
June 15, 2026
•
,

