New Snorkel benchmark leaderboards. See the results.
Debugging AI Applications Pipeline
At Snorkel, we are strong believers in iterative development for AI applications. A big part of the workflow is in debugging and improving the existing pipeline. However, for many ML engineers, debugging is still done ad-hoc instead of as a process.In this blog post, we’ll analyze major sources of errors at the four steps of building AI applications: data labeling, feature engineering, model training, and model evaluation. For each source of errors, we’ll also go over their solutions.
Why Debugging the AI Apps Pipeline is Hard
Debugging machine learning is hard to the point that the community has made a sport out of complaining about how hard it is [1, 2, 3]. Here are a few reasons why.
1. Cross-functional Complexity
There are many components in an AI application — data, labels, features, machine learning algorithms, code, infrastructure, etc.. These different components might be owned by different teams. For example, data is managed by the data science team, labels by subject matter experts, ML algorithms by the ML engineers, and infrastructure by the DevOps engineers.
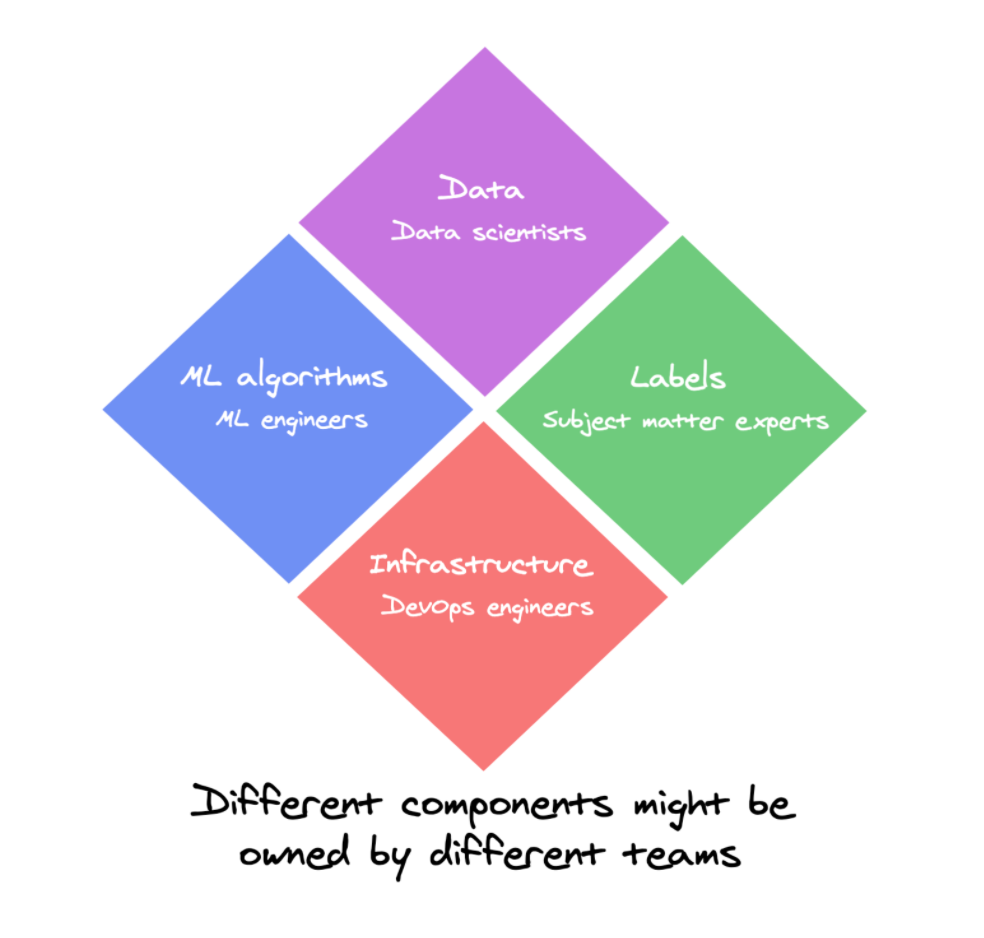
When an error occurs, it could be because of any of these components or a combination of them, making it hard to know where to look or who should be looking into it.
2. Silent Errors
When traditional software systems fail, you might get some warnings such as crashes, runtime errors, 404. However, AI applications can fail silently. The code compiles. The loss decreases as it should. The correct functions are called. The predictions are made, but the predictions are wrong.
AI applications can fail silently.
The developers don’t notice the errors. And worse, users don’t either and use the predictions as if the application was functioning as it should. For example, machine translation’s silent errors have caused many incidents from funny to unfortunate.

3. Slow Updating Cycle
When debugging a traditional software program, you might be able to make changes to the buggy code and see immediately whether the changes fix the bug. However, when making changes to an ML model, you might have to retrain the model and wait until it converges to see whether the bug is fixed, which can take hours if not days. In some cases, you can’t even be sure whether the bugs are fixed until the application is deployed to the users.
Four Major Sources of Errors and Solutions
1. Labeling: Label Multiplicity and Ambiguity
Despite the promise of unsupervised ML, most ML models in production today still need labels to learn. The performance of an ML model depends heavily on the quality and quantity of labels it’s trained on.To obtain a large quantity of high-quality labels, companies often have to use data from multiple sources and rely on multiple annotators. These different data sources and annotators might have different levels of accuracy. Without knowing the levels of accuracy of different data sources, it might be risky to use them.Consider a case when you’ve trained a moderately good model with 100,000 data samples. Your ML engineers are confident that more data will improve the model performance, so you spend a lot of money obtaining 1 million data samples. However, the model performance actually decreases after being trained on the new data. The reason is that the new million samples were crowdsourced to annotators who labeled data with much less accuracy than the original data. It can be especially difficult to remedy this if you’ve already mixed your data and can’t differentiate new data from old data.
Another problem with multiple annotators with different levels of expertise is label ambiguity.
Consider this simple task of entity recognition. You give three annotators the following sample to annotate and receive back three different solutions.Darth Sidious, known simply as the Emperor, was a Dark Lord of the Sith who reigned over the galaxy as Galactic Emperor of the First Galactic Empire.
| Annotator | # entities | Annotation |
| 1 | 3 | [Darth Sidious], known simply as the Emperor, was a [Dark Lord of the Sith] who reigned over the galaxy as [Galactic Emperor of the First Galactic Empire] |
| 2 | 6 | [Darth Sidious], known simply as the [Emperor], was a [Dark Lord] of the [Sith] who reigned over the galaxy as [Galactic Emperor] of the [First Galactic Empire]. |
| 3 | 4 | [Darth Sidious], known simply as the [Emperor], was a [Dark Lord of the Sith] who reigned over the galaxy as [Galactic Emperor of the First Galactic Empire]. |
Annotating disagreement can be especially common among tasks that require a high level of domain expertise. One human-expert thinks the label should be A while another believes it should be B — how do we resolve this conflict to obtain one single ground truth?
Solution
One solution is data lineage: always keep track of where each of your data samples comes from. For example, in the example above, you might see that your new trained model fails mostly on the recently acquired data samples, and when you look into the wrong predictions, you might see that it’s because the recently acquired data samples have wrong labels.Another solution is to find a way to encode and share domain expertise to ensure that everyone has access to the same level of domain expertise to have consistent labels. Solutions like Snorkel allow you to encode heuristics — originated from domain expertise — as labeling functions which can then be shared with other people and reused on new data.
2. Feature Engineering: Data Leakage
Although many ML engineers like to focus on models and training techniques, an AI application’s success still hinges on its sets of features. A large part of many machine learning engineering and data science jobs is to come up with new useful features. Fancy models can still perform poorly if they don’t use a good set of features.More features don’t always mean good. One common bug with feature engineering is data leakage — labels somehow “leak” into features. Suppose you want to build an ML model to predict whether a CT scan of a lung shows signs of cancer. You obtained the data from hospital A, removed the doctors’ diagnosis from the data, and trained your model. It did really well on the test data from hospital A, but poorly on the data from hospital B.After extensive investigation, you learned that at hospital A, when doctors think that a patient has lung cancer, they send that patient to a more advanced scan machine. Hospital B doesn’t do that. Information on the scan machines was used as part of your model’s features. So the labels (whether or not a patient has cancer) are leaked into the features (types of scanning machines).
Solution
To know whether your set of features is good or bad, it’s important to understand your features. Find the correlation between each feature and labels. A strong correlation might mean that the feature is either really good or that the labels are leaked into it somehow. Data leakage doesn’t just happen to individual features — a set of features might cause leakage too. Watch out for a sudden increase in performance after you’ve added new features — this might mean that there’s a leak somewhere in the new set of features.Feature engineering is a step in the AI workflow that tends to require subject matter expertise. However, subject matter experts might not have engineering or ML expertise. It’s important to design your workflow in such a way that facilitates collaboration between SMEs and engineers. The lung cancer example above could have been avoided if the ML engineers understood the doctors’ workflows at hospital A.No code/low code AI platforms like Snorkel Flow can also be a solution as they allow SMEs to get involved with the development of AI applications without writing any code or with only a minimal amount of code. Snorkel Flow also offers many visualization and data exploration tools to help engineers understand the data and features they use for their models.
3. Model Selection & Training: Starting with Complex Models
When starting an ML project, it’s tempting to start with models that claim to be state of the art on the task you want to solve. Why use an old solution when a superior one exists?One problem with these state-of-the-art models is that they tend to be complex. Debugging ML models is hard. Debugging complex ML is much more so. When something goes wrong with a complex ML model, it might be impossible to figure out what’s wrong.A model that does well on benchmark datasets doesn’t necessarily do well on your data. And state-of-the-art performance isn’t everything.
You might want to trade off accuracy performance for other qualities such as low inference latency and interpretability.
Solution
One superstar ML engineer once said: “Start small. Smaller. Still too big.” Starting with a small model has three benefits:
- It helps you validate that your data can do something useful.
- It helps you validate your pipeline to make sure that your training pipeline and inference pipeline do the same things.
- Simple models can act as baselines to which you can compare your more complex models. Your complex models should do significantly better than simple models to justify their complexity.
4. Evaluation: Focusing on Overall Metrics Instead of Critical Data Slices
Not all subsets of data are equal. Some slices of data are more critical. For example, when you build an object detection system for self-driving cars, making correct detection on images of road surfaces with cyclists is far more critical than making correct detection on images on road surfaces without cyclists. A model’s poor performance on critical slices can prevent it from being used in the real world.However, many teams are still focused only on coarse-grained metrics like overall F1 or accuracy. Optimizing for models to perform well on the entire test set can make them perform poorly on critical slices, causing catastrophic failures in deployment.
Solution
To track your model’s performance on critical slices, you’d first need to know what your critical slices are. Defining slices precisely can be challenging, e.g. how would you describe road surfaces with cyclists to machines?The ad-hoc approach is manually tagging critical data samples as we come across them, typically through data exploration and data analysis. A better approach is slicing functions — encoding heuristics as functions that map data samples to different slices, as noted in this paper.
Snorkel Flow Approaches
We’ve built many of these considerations into our platform, Snorkel Flow. We designed our platform not only to enable users to develop AI applications but also make it harder for them to make mistakes. We offer extension utilities for:
- Visualization and data exploration for understanding your data.
- Slice tagging and data lineage to track and monitor your models’ performance on critical data slices
- Experiment versioning and comparison to compare models of different complexity
- Error analysis that helps you figure out how to improve your models
Our E2E platform with both the no-code option and SDK makes it easier to iteratively iterate on and debug pipelines in one place. This speeds up the AI development process for DS/MLEs and SMEs alike. Our customers have been able to label data and develop models that exceed their existing baselines in hours, not days.If you’re interested in the topic, here are some other great resources by the community.
- OpML ’20 – How ML Breaks: A Decade of Outages for One Large ML Pipeline (Daniel Papasian and Todd Underwood, 2020)
- Debugging Training Data for Software 2.0 (Paroma Varma et al., 2018)
- A Practical Guide to Maintaining Machine Learning in Production (Eugene Yan, 2020)
Topics

Team Snorkel