Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
How data slices transform enterprise LLM evaluation
As enterprises aim to deploy a growing number of generative AI applications, evaluating the performance of large language models has become a gateway to successful production deployment. We at Snorkel AI believe that customized and automated evaluation approaches present the best path to production—especially when paired with data slices.
Data scientists often don’t understand how to judge model performance against business use cases. Subject matter experts typically don’t have the tools to scale their expertise to assess large language models (LLMs). With this dynamic, some companies have deployed armies of human labelers. As an alternative, Snorkel built a platform where data scientists and SMEs can collaborate to build scalable, sustainable solutions.
I spoke about the value of data slices at a recent webinar. You can watch my entire remarks (embedded below), but I have summarized the main points here.
Why is customized and automated LLM evaluation so critical?
Without customized LLM evaluation, enterprises can’t use LLM applications for business-critical tasks. The model must perform according to the standards an organization cares about and on the tasks it needs to complete.
While open source benchmarks and direct human evaluation can be useful, both have drawbacks. Open source benchmarks will not understand your organization’s specific challenges. Human evaluators might, but they can be expensive, and each round of model evaluation requires a fresh round of human annotation.
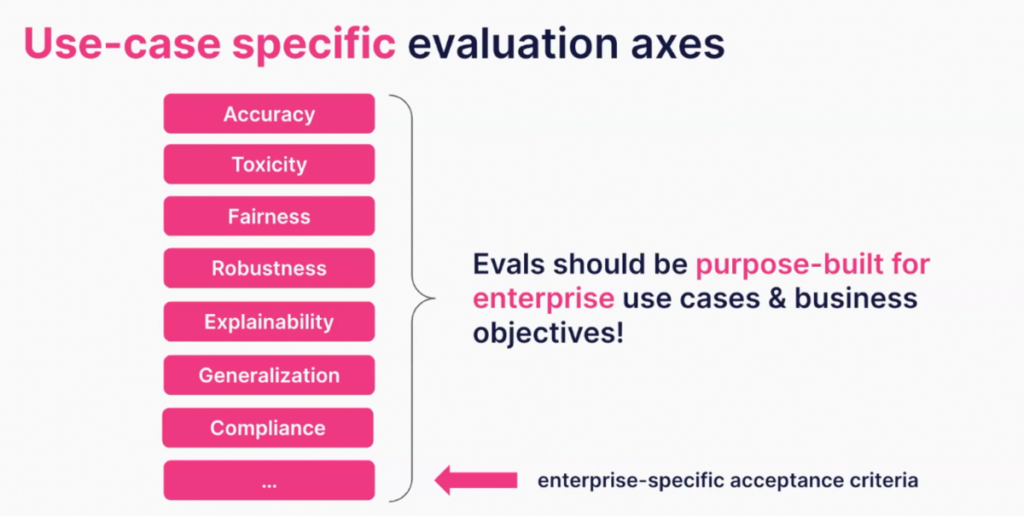
In their place, we recommend building custom evaluation models encoded with your organization’s data and your expert’s knowledge and experience.
This approach:
- Enables continuous improvement: Automated evaluations help track the performance of your LLMs as they undergo updates. They act as a unit test, ensuring no regressions and highlighting areas for improvement.
- They can spot domain-specific nuances: The definition of “correctness” in LLMs is multi-faceted, encompassing factors like toxicity, compliance, relevance, comprehensiveness, or the ability to provide substantiated responses. Properly customized, automated evaluations will account for these nuances.

Introduction to data slices
Data slices are subsets of data that represent meaningful aspects of your business operations. In the context of LLM evaluation, they enable a fine-grained understanding of model performance across different business-critical areas. This granular approach of evaluating LLMs through data slices transforms the evaluation and iteration process.
In the Snorkel Flow AI data development platform, building a data slice works similarly to building a labeling function. Users employ LLM prompts, regular expressions, ontologies, embeddings, or any other of the many tools the platform offers to define slice membership at scale.
Slicing your data allows you to measure performance on precise, enterprise-specific tasks. For instance, an e-commerce company’s LLM evaluation might include slices for customer service queries about shipping issues, product information, or transaction concerns.
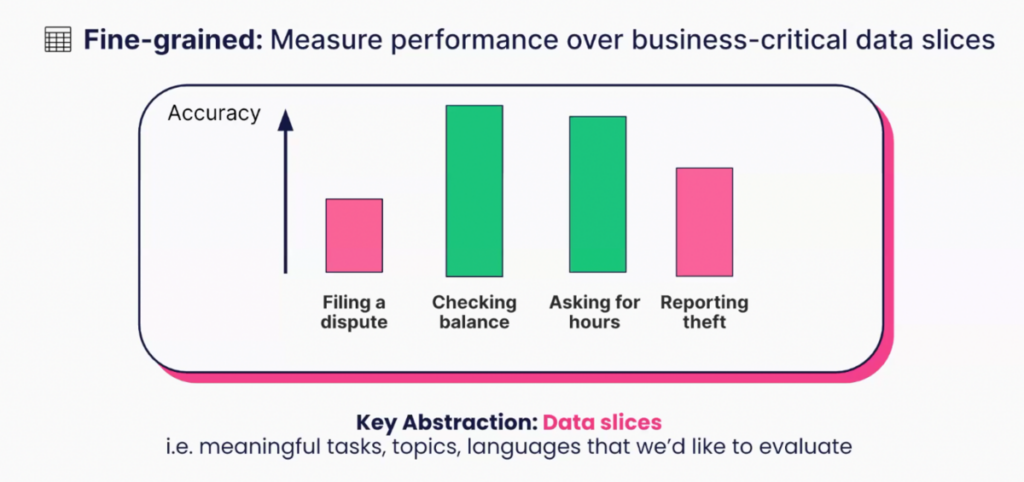
Leveraging programmatic techniques to evaluate data slices enables scalability. Rather than manually analyzing tens of thousands of data points, programmatic data slices allow for automated, robust, and consistent evaluations that can adapt to your changing business needs.
By evaluating each slice independently, you can easily identify which ones need further work. You can then address the training data in that slice by generating new “golden” examples or writing additional labeling functions to better label your training data.
As you make these adjustments, you can see how changes to the model have improved performance in each slice.
Building customized evaluations using data slices
Snorkel researchers and engineers have already used scalable evaluation and data slices to improve performance on customers’ LLM applications. We’re now moving this capability into the platform.
Here’s how the process works.
Step 1: Create a golden data set
Begin by using your subject matter experts (SMEs) to create a golden data set. This involves labeling a subset of data points and specifying acceptance criteria for what constitutes a good response.
Step 2: Encode expert criteria
Capture the rationale behind SMEs’ judgments programmatically. Use these criteria to develop a custom quality model that can scale your experts’ insights across the entire dataset.
Step 3: Slice and dice your data
Identify and define the data slices that matter most to your business. This might involve categorizing queries into different types of user interactions or product lines.
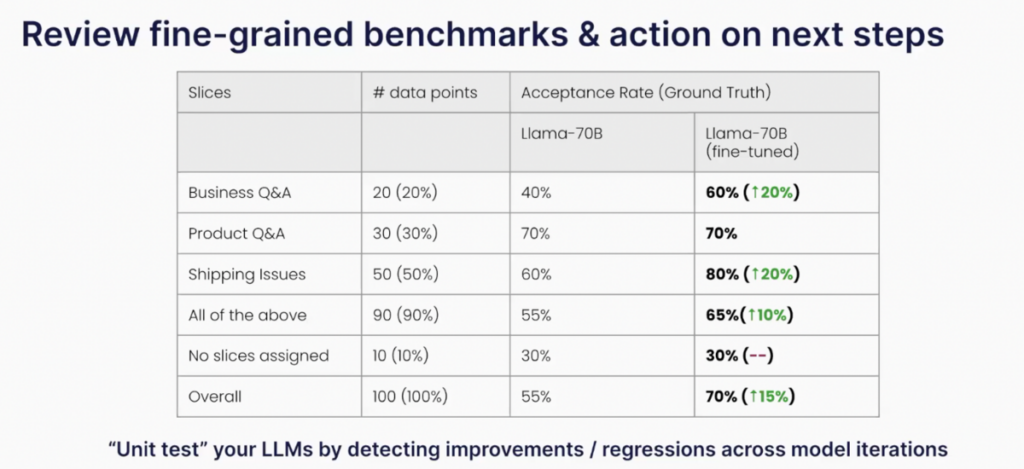
Step 4: Generate detailed evaluation reports
Combine your manual ground truth, programmatic quality model, metrics and data slices to produce a comprehensive evaluation report. This report should detail performance across different slices, allowing for an actionable understanding of where improvements are necessary.
Practical applications of data slices
To illustrate how data slices and quality models can help in real-world settings, here are two examples.
Consider an e-commerce platform using an LLM-powered chatbot. By slicing data into categories such as “Shipping Issues” and “Product Information,” the platform can track which specific types of queries the model handles well and where it needs improvement. This ensures that critical areas like transaction concerns, which have higher stakes, receive focused attention for optimization.
In the financial sector, data slices can be used to evaluate LLM performance in areas with strict compliance requirements such as transaction inquiries, fraud detection, and customer service. Each slice represents a different type of customer interaction, enabling the company to maintain high standards of accuracy and customer support.
Data slices + custom, automated evaluation: a powerful pair
Data slices provide a powerful method for fine-grained, domain-specific LLM evaluation. They ensure that your models meet the unique needs and critical operations of your enterprise. By adopting a systematic approach to slicing and evaluating your data according to your custom, organization-specific standards, you can build robust, scalable evaluations that keep your LLM deployments on track and your business operations smooth.
At Snorkel, we understand the importance of fine-grained evaluations. Our approach of leveraging programmatic data development techniques helps enterprises build custom, scalable, and efficient LLM evaluations that ensure their models are production-ready and aligned with business goals.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Vincent Sunn Chen
Vincent Sunn Chen is on the founding team at Snorkel, where he drives new product development and applied research initiatives. He joined Snorkel as a founding engineer and built the ML engineering team from the ground up. Prior to joining Snorkel AI, Vincent conducted research on data-centric machine learning systems as a graduate student at the Stanford AI Lab. He holds both a master’s and bachelor’s degree in computer science from Stanford University.