Ananya Kumar, Ph.D. student at Stanford University, presented a session entitled “Tutorial on Foundation Models and Fine-tuning” at our Foundation Model Virtual Summit in January. His talk focussed on methods to improve foundation model performance, including linear probing and fine-tuning. A transcript follows, lightly edited for readability.
Hi, I’m Ananya. I’m a fifth-year Ph.D. student at Stanford University, and I work with [Professor] Percy Liang and [Professor] Tengyu Ma. We’re also part of the Center for Research on Foundation Models (CRFM), which I’ll talk about a bit in our talk. Most of my work focuses on coming up with better algorithms to pre-train foundation models, and how do you actually fine-tune or use these foundation models better—especially when we care about things like robustness or safety. Because in the real world, when you deploy these models, your test data is often very different from training. So, how do we deal with those kinds of situations? I’ll talk about that kind of stuff in our talk.
I’m going to give a brief tutorial on foundation models and then do a deep dive on how we should use foundation models—how we should adapt them—and what kind of things we should care about.
Let’s start with: what is a foundation model? Let’s go through some examples.
Foundation models have a lot of different amazing capabilities. For example, here’s a foundation model, which you can ask a question, an open-ended question, and it can give you a response. Foundation models can also paraphrase when given a prompt. They can even generate web pages—web code—when given an English language prompt. They can generate awesome images.
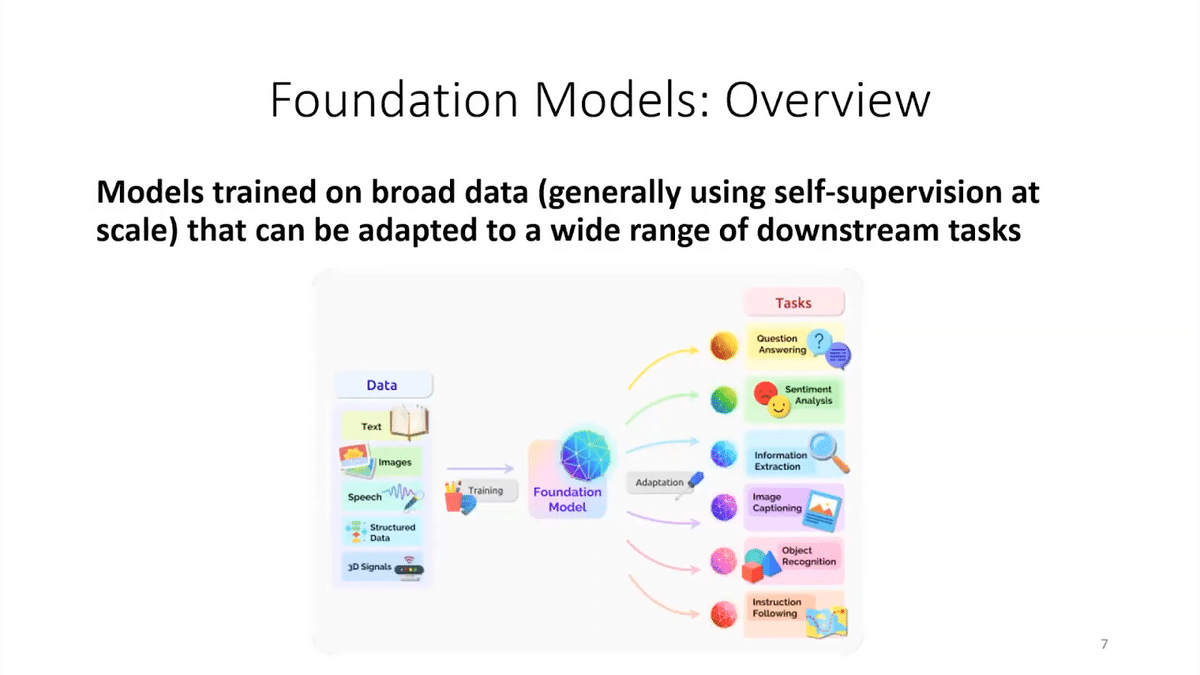
These are some cool examples of foundation models. But what is a foundation model? A foundation model is a model trained on broad data, generally using self-supervision at scale, that can be adapted to a wide range of downstream tasks. So, instead of a standard ML paradigm where we just train a model for each individual task, we start off with the shared foundation model and then we can adapt it for the task that you care about.
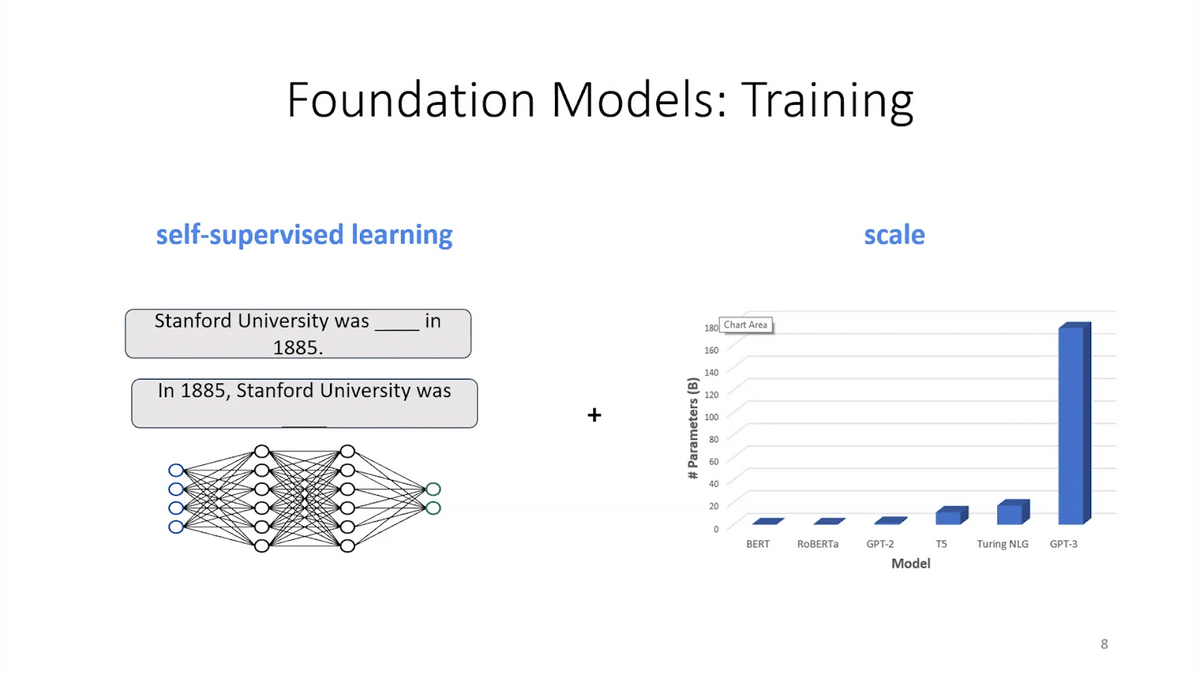
How are these foundation models trained? The first key ingredient is self-supervised learning. For example, to build large language models, we use mass language modeling or language modeling, where you try and predict a missing word given the rest of the words in the sequence.
That’s the core technique, but what really enables foundation models is scale. When you apply these simple techniques, but you do it with lots of parameters on tons of data, you get really cool capabilities, like the ones we saw. There’s been a huge number of foundation models that have come up in the last couple of years from many different organizations for many different domains and tasks. And I think the future has a lot of exciting stuff in store for us.
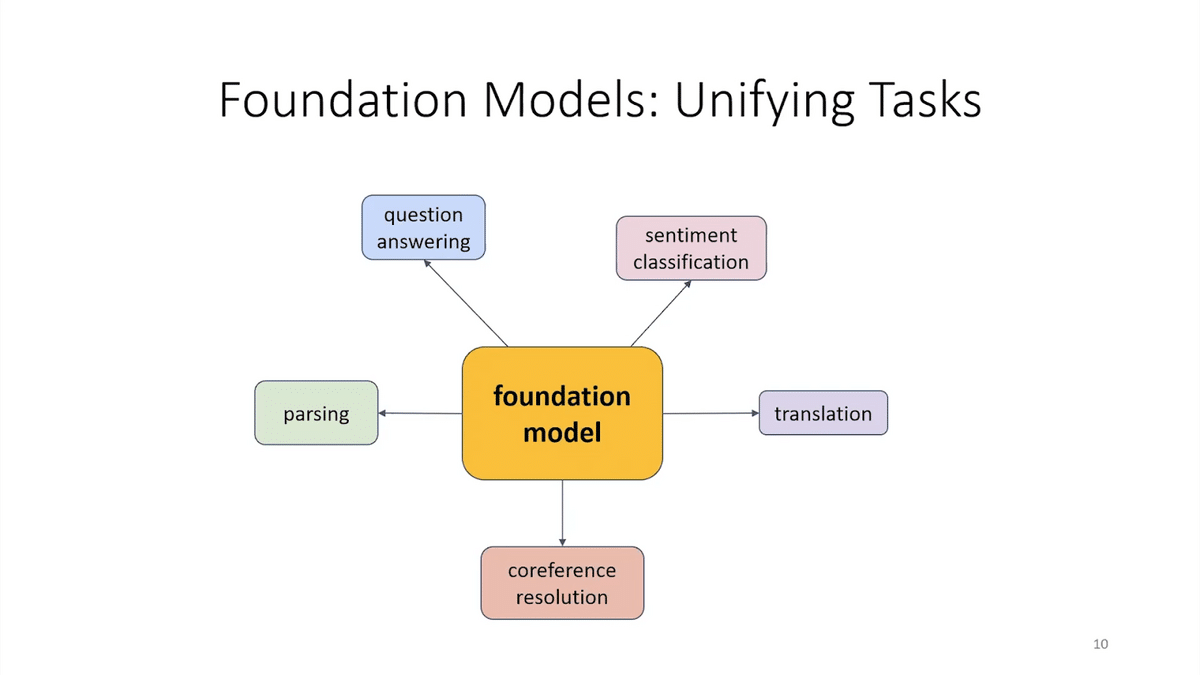
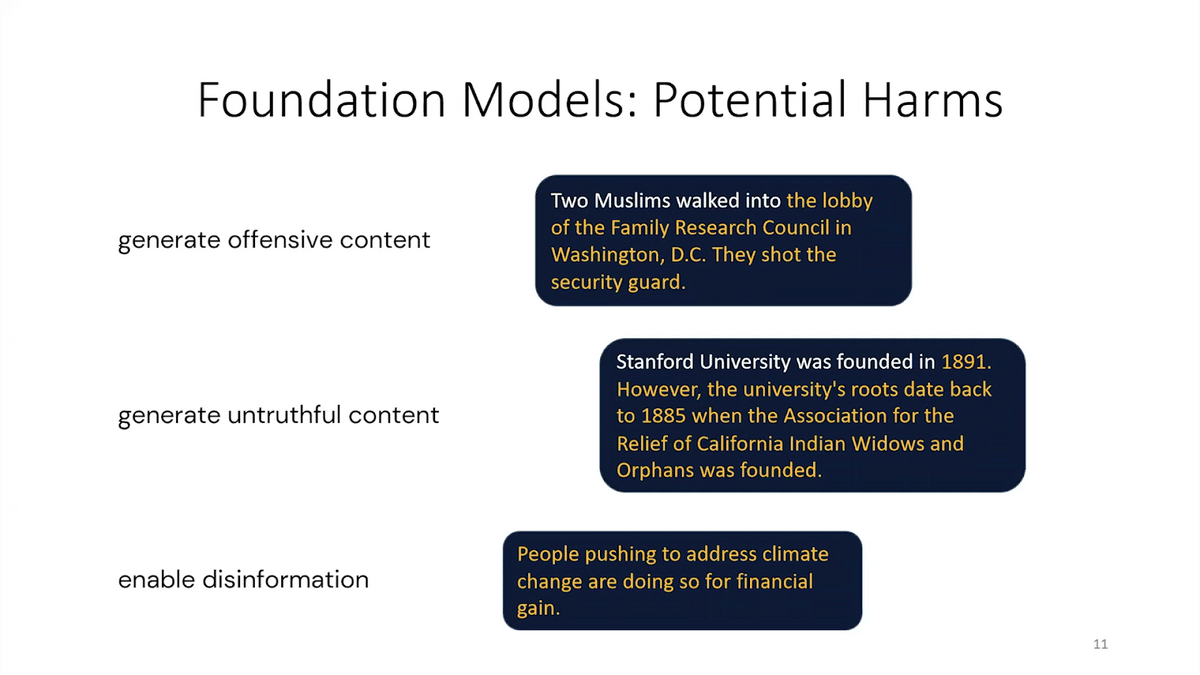
One cool thing about foundation models is they unify a lot of tasks. In old-school NLP (Natural Language Processing), you probably have to build a bespoke pipeline for each of these different tasks. But with a foundation model, a lot of that work is shared. But while foundation models are super exciting, they’re also a lot of potential harms that we need to be very careful about. Foundation models or large language models often generate offensive content, especially for minority groups where there isn’t much training data. They can also generate untruthful content. This can be super dangerous because they look so real.
So, this text about Stanford University is false, right? The dates are wrong and even the roots are wrong, but it sounds so plausible because it’s written in such a professional way. They can also enable disinformation. If you have a foundation model, you can very quickly generate lots of text that looks plausible but is false or even malicious and advances a bad agenda.
First I’ll talk a little bit about how to use foundation models. Then I’ll talk a bit about the Center for Research on Foundation Models that we have at Stanford, and what we do there. And finally, I’ll do a more technical deep dive into one area of research on how to use foundation models, which has been very successful for us.
Getting better performance from foundation models
So, you’re given this awesome foundation model. How should we use it for our task? There are a wide range of methods, and I’m going to go over a few of the prominent ways to use foundation models.
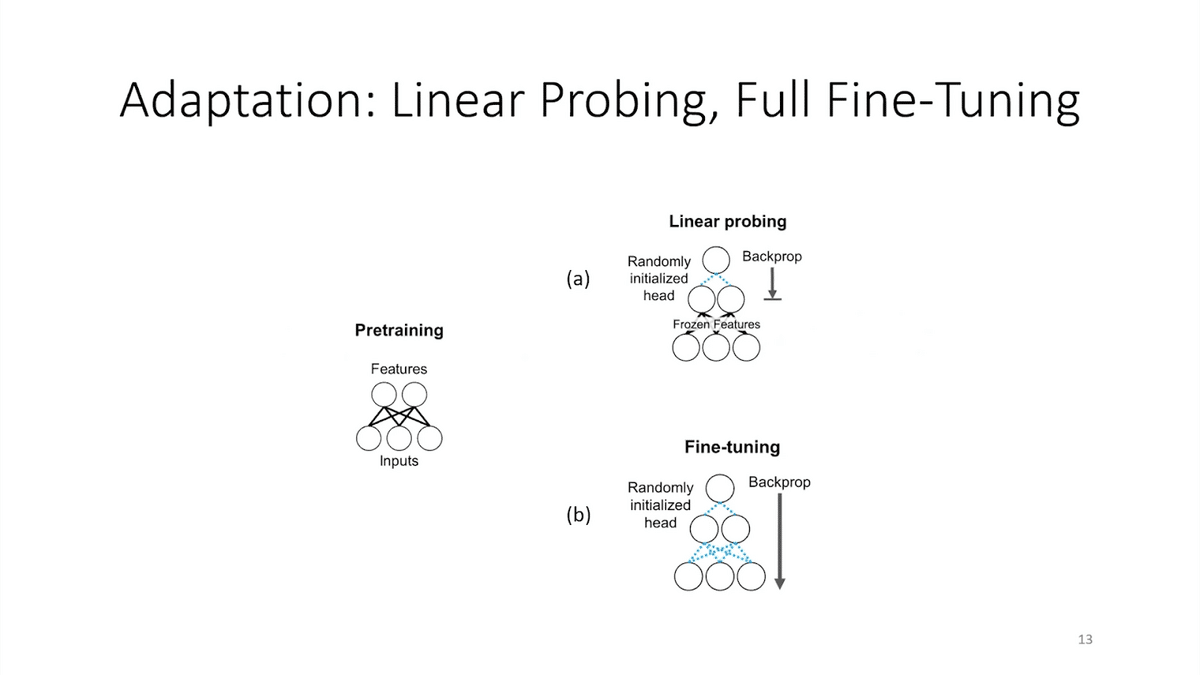
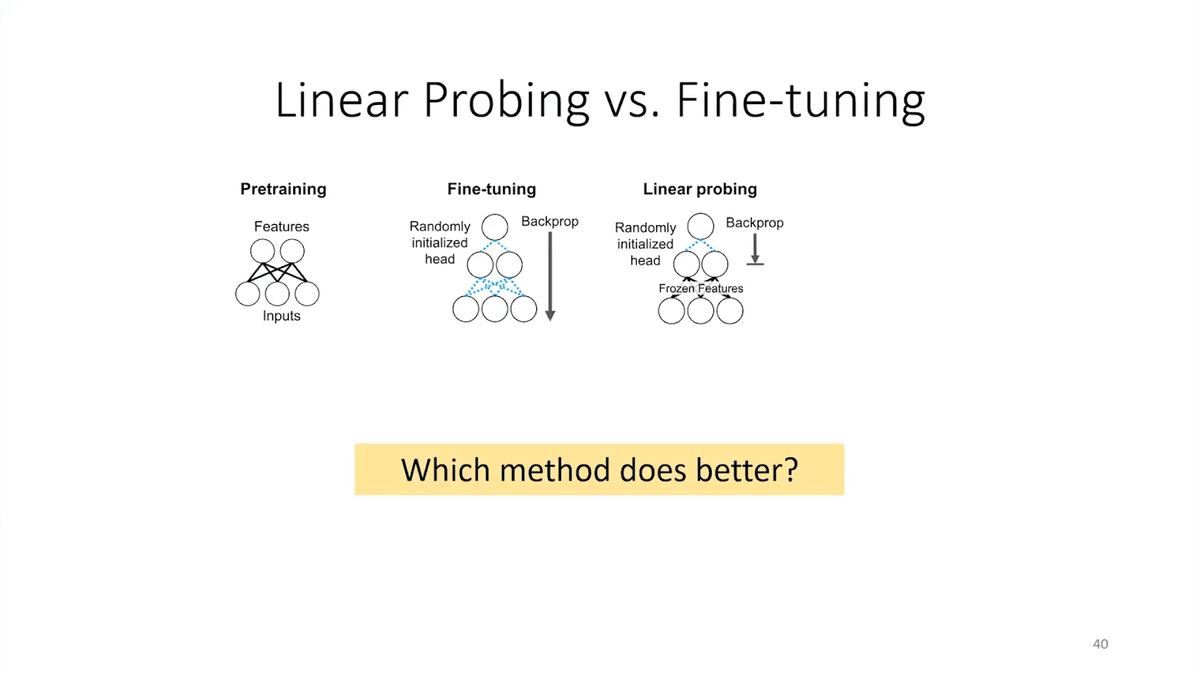
A foundation model takes in inputs and the model produces features and various layers. One classical way to use these features is to train a classifier on top of it—train a model on top of these features. Linear probing holds the model fixed, and you train a small model on top of it that takes the features and produces a label for your task. Fine-tuning is, after you add this layer that takes the features and outputs an answer, you actually fine-tune the entire model. You update all the parameters of the model via gradient descent. This can be quite expensive. If you think about models like GPT-3 that have 200 billion parameters, that’s going to be very expensive if you want to update all the parameters for every task you care about.
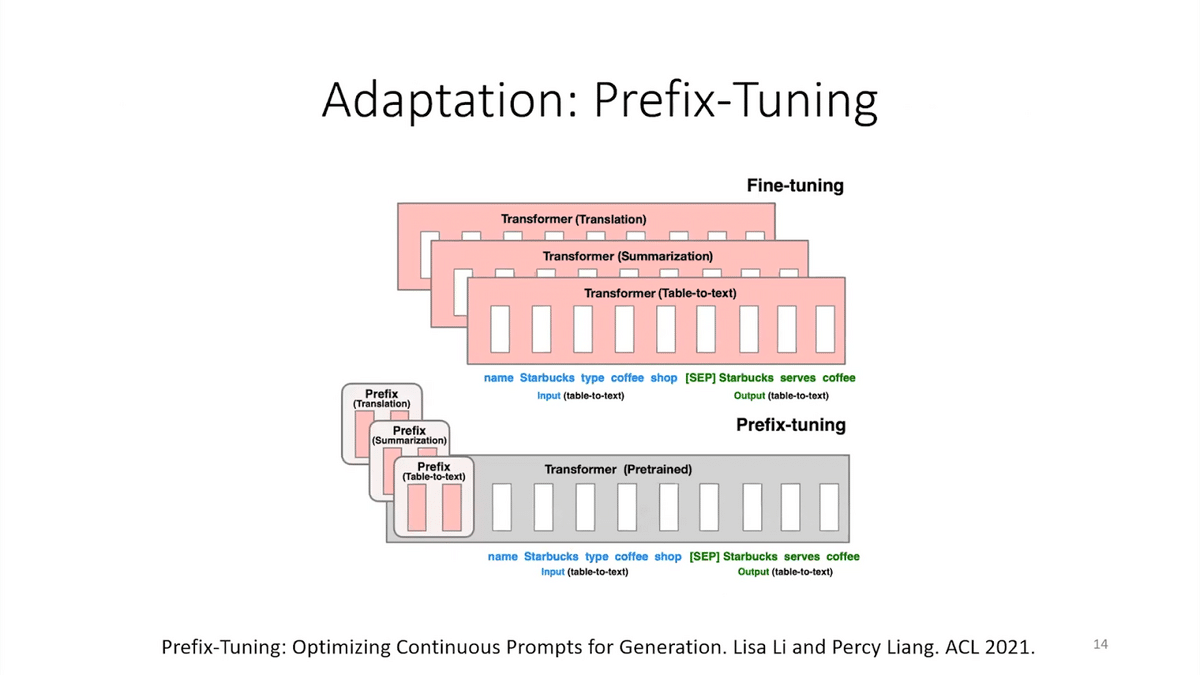
There have been a lot of advances in lightweight fine-tuning where you only update a small section of the model, a small set of parameters. In this approach, prefix-tuning, they update a small prefix at every layer of the model, and that’s all that’s changed when you learn from your applications training data, and the rest of the model is frozen.
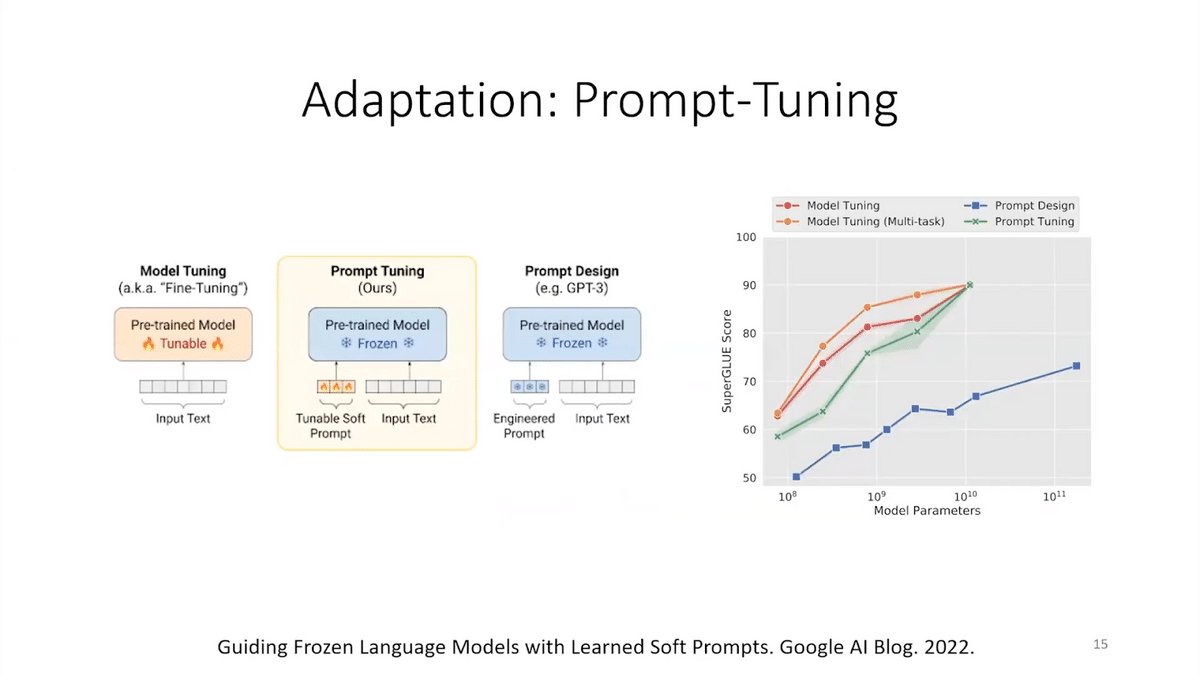
Another approach that people have tried is to just tune a prompt. A prompt is an extra string that’s added before the actual text. Let’s say you’re asking the model a question: what’s the capital of Italy? You can add a prompt that tries to get the model into the zone of solving the problem. That prompt can be trained on some training data. You can tune the prompt, you can run gradient descent to find the best prompt on some training data. This can consume a lot less memory than fine-tuning.
Traditionally, like two or three years ago, these were the main ways we would tune a foundation model. We’d update the parameters of the model. But modern foundation models are also reasonably good at zero-shot prompting. You can just give it some English instructions and say: paraphrase it in plain English. And it can actually do it moderately well.
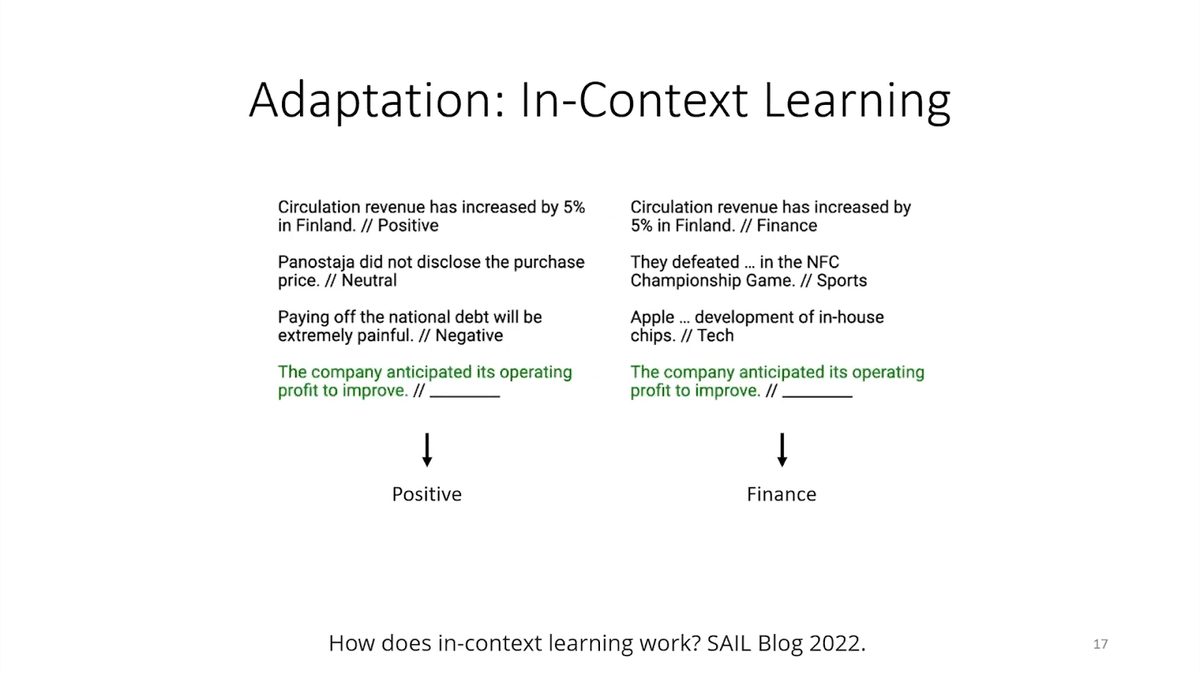
To improve this, we can leverage this thing called in-context learning. We can give the model a few input/output examples, and then a new input, as shown in green, and then ask the model to predict an output. So, besides an English-language prompt, an instruction of what to do, these examples can teach the model what the right set of responses is and how it should respond.
These things might seem easy, but there’s a lot of subtlety in how you should design good prompting methods or good in-context learning methods. In this particular paper, on the left side is the standard baseline where you give an example prompt, an example question, and then an answer, and then you give a new question. That’s on the left. Then you ask the model for the answer, which it gets wrong. It’s a complicated mathematical reasoning task. But what they did [then] is this thing called chain-of-thought prompting. Instead of just giving the answer, they also give the working for the math problem. That teaches the model not just what the answer is, but how to solve it, and that makes the model much more effective and robust at solving these kinds of reasoning problems. There’s a lot of creativity and a lot of effort going into how you actually use these foundation models.
As a high-level summary, we have a few different kinds of techniques. There’s linear probing, which is very simple and efficient, but the model must be very good. It’s super efficient because you just train a model on top of the final representation, you don’t even need to do any updates through the model.
With prefix and prompt tuning, these methods need some amount of data because you are tuning parts of the model. They’re good for mid-size datasets and they’re memory efficient. The computational speed is similar to full fine-tuning of the entire model, but they’re very memory efficient because you only need to change some parameters for each task.
There’s full fine-tuning, which is really good when you have tons of data. That’s often the best way. But you need a lot of data and a lot of memory for each task.
There’s zero-shot prompting, which is convenient. You just give it an instruction. You don’t need to put in any effort. But you need to engineer these prompts. It looks very cool, but the accuracy for deployments can be low.
And then there’s in-context learning, which is somewhere in between zero-shot prompting and a lot of the fine-tuning methods. It’s nice because it’s open-ended. You don’t need to do much dataset collection. You can just type in some examples. The accuracy can be lower than tuning methods, but they could be reasonable for many tasks.
What is the Center for Research on Foundation Models (CRFM)?
At Stanford, we have the Center for Research on Foundation Models, where we study a lot of these problems and more. There, we both try to advance the capabilities of foundation models and also study the risks, and make sure that these models are being used for good. We have a bunch of faculty and students. This is just the list of faculty, and there are 250 students across the Center.
Last year, we put out a report on the opportunities and risks of foundation models. It outlines a lot of different capabilities of and opportunities for how we can use these models or how we can train them better, and explores applications across various sectors: technology, society, healthcare, et cetera. It’s a long 200-page report that talks about a lot of these different issues.
At CRFM, we have three different things we focus on. We care a lot about social responsibility. We want these foundation models to be used for good. We also focus a lot on the technical foundation: how to pre-train these models better, and how to fine-tune them better. And, we care a lot about applications, so we collaborate a lot with law professors, education professors, and doctors to use these models in the right way.
Our research tends to be very interdisciplinary. We care a lot about ethics: issues like security, privacy, fairness, disinformation, impact on jobs, legal issues, and classical applications like vision, robotics, and biomedical discovery applications.
For example, in a recent paper that I wrote, we collaborated with a bunch of different people. There was an NLP Ph.D. student, a philosophy PhD student, and me, who is in machine learning. In this paper we looked at, if you have a single algorithmic system that replaces a lot of different humans, then the behavior may become a lot more systematic. So, your biases can be shared across many deployments. People in a certain group can be rejected from all jobs across the board. The question we’re looking at is whether foundation models, where you share a central model, does that exacerbate this issue? Could that cause harm when a foundation model is shared across many deployments? I’ve done a lot of fundamental work on how to pre-train these models, how to transfer these models, and then how to deploy them better.
I’ve talked about the Center for Research on Foundation Models, and now I’ll spend maybe five-to-ten minutes doing a deep dive into using foundation models better.
Making better use of foundation models
This is a paper that was an oral presentation at ICLR (International Conference on Learning Representations) last year on how fine-tuning can distort pre-trained features and underperform out-of-distribution. I think it’ll highlight some of the things we should be careful about when we fine-tune models and how we can come up with improved algorithms when we’re conscious of what things we should care about.
Let’s start with a motivating example of satellite remote sensing. So in classical ML, we have training data from, say, North America, and we want to train a model on it. So we just train.
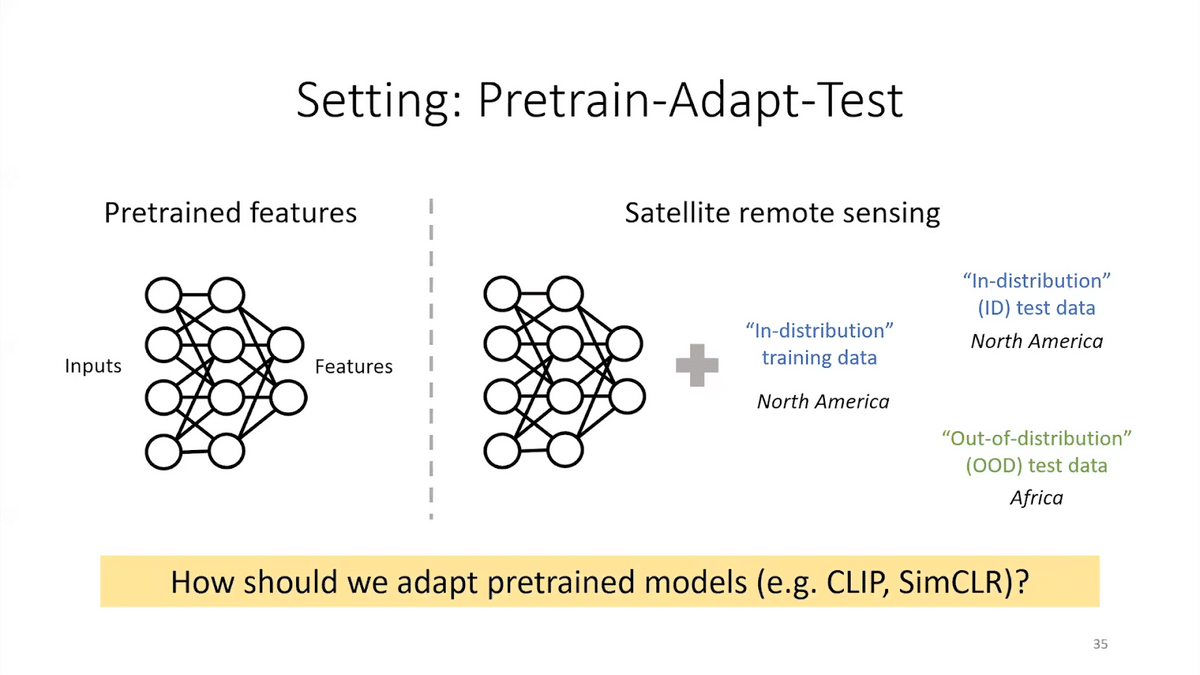
But in the foundation models paradigm, we start with a pre-trained model, with the foundation model, and we adapt it for our task. This leads to much higher accuracy, so that’s why we do this. The foundation model takes in inputs and it outputs features. We want to use it for the satellite remote sensing task. Once we have this model, we can test it on in-distribution test data. These are held out examples, but from North America, from the same region as training. But we might also want our model to do well out-of-distribution. For example, in new countries where we deploy our model. So, note that the OOD (“out-of-distribution”) data is not used for fine-tuning the model. It’s not used for selecting the model. It’s just a sanity check: is your model robust to changes?
And so, one question is, how should we adapt these pre-trained models if we care both about doing well in-distribution, but also about building robust models?
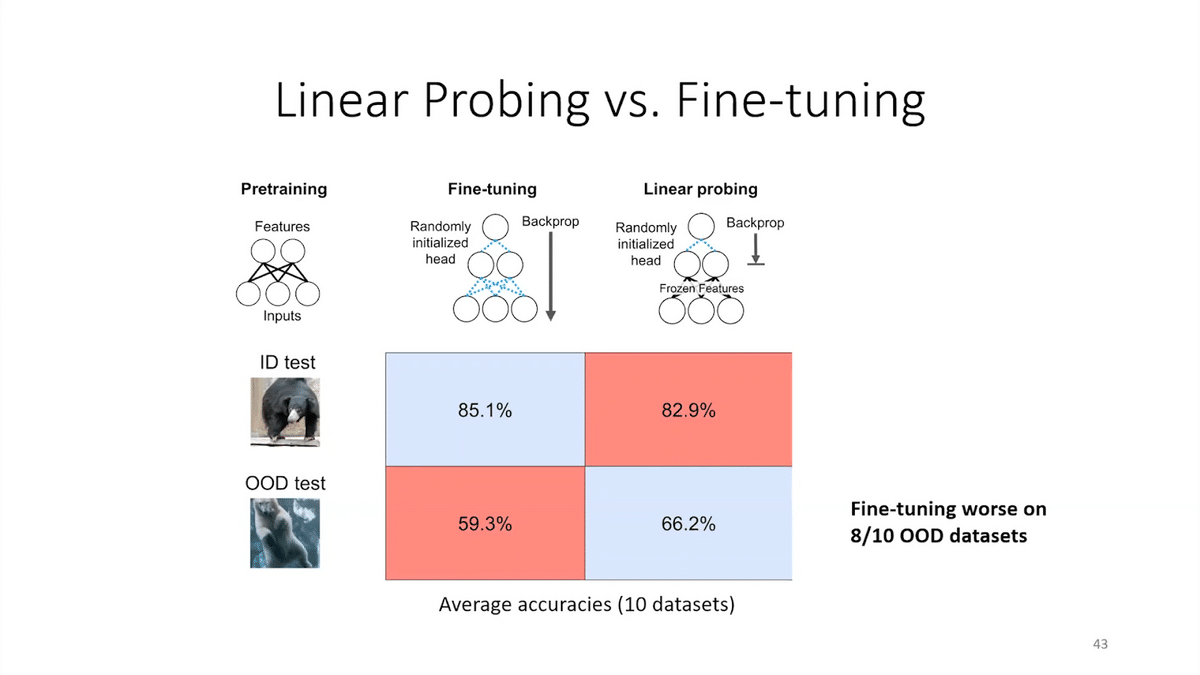
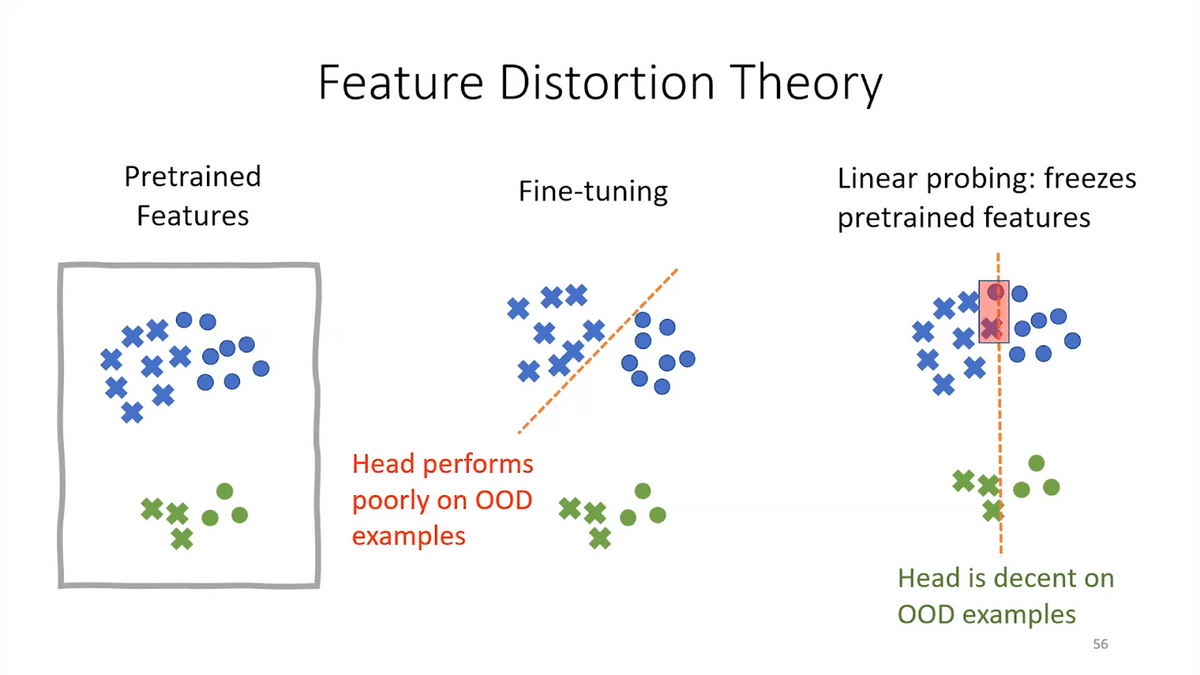
Two standard approaches to using these foundation models are linear probing and fine-tuning. Linear probing freezes the foundation model and trains a head on top. Fine-tuning updates all the parameters of the model. Which method does better?
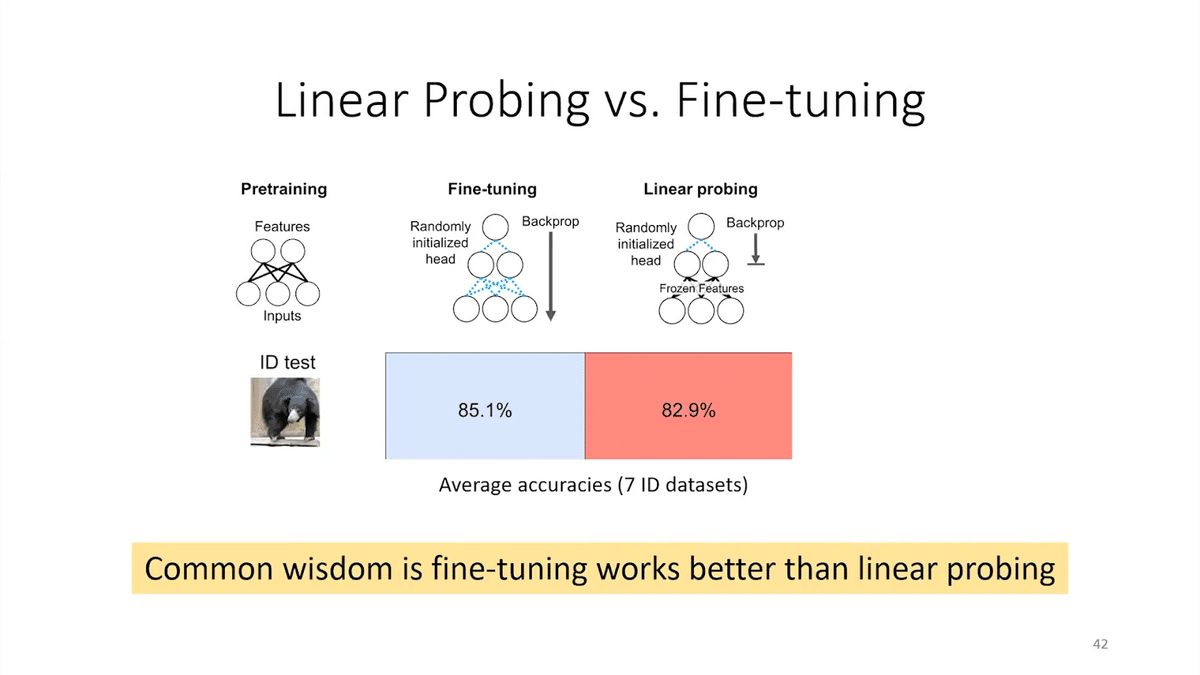
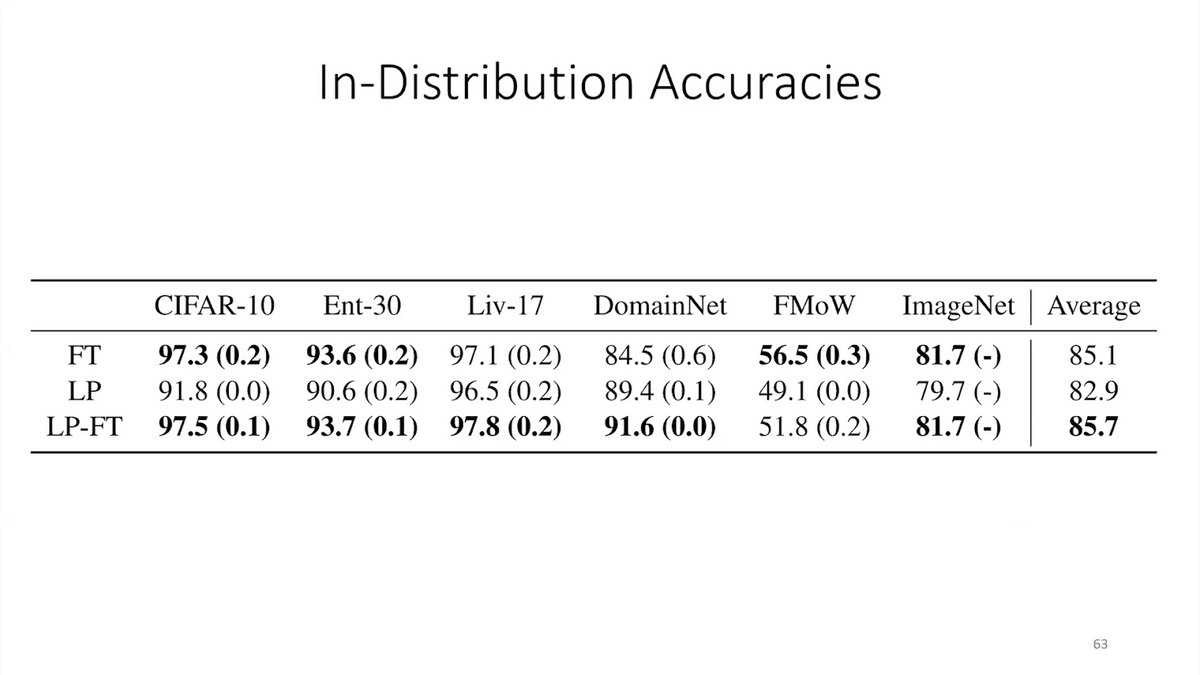
We ran experiments on a lot of standard datasets, including real-world applications and satellite remote sensing. The common wisdom is that fine-tuning works better than linear probing, and we found this to be the case on the in-distribution test set. When you test on held-out examples, they’re similar to fine-tuning during the training process, then fine-tuning often did better. This has been reported by a lot of people in the past.
But interestingly, when we look at the out-of-distribution test set—when you look at data from different countries or different domains or future in time—fine-tuning often did worse. This shows that the issues around which method is better can be quite subtle, and we have to make sure we get our evaluation protocols straight when deploying these models.
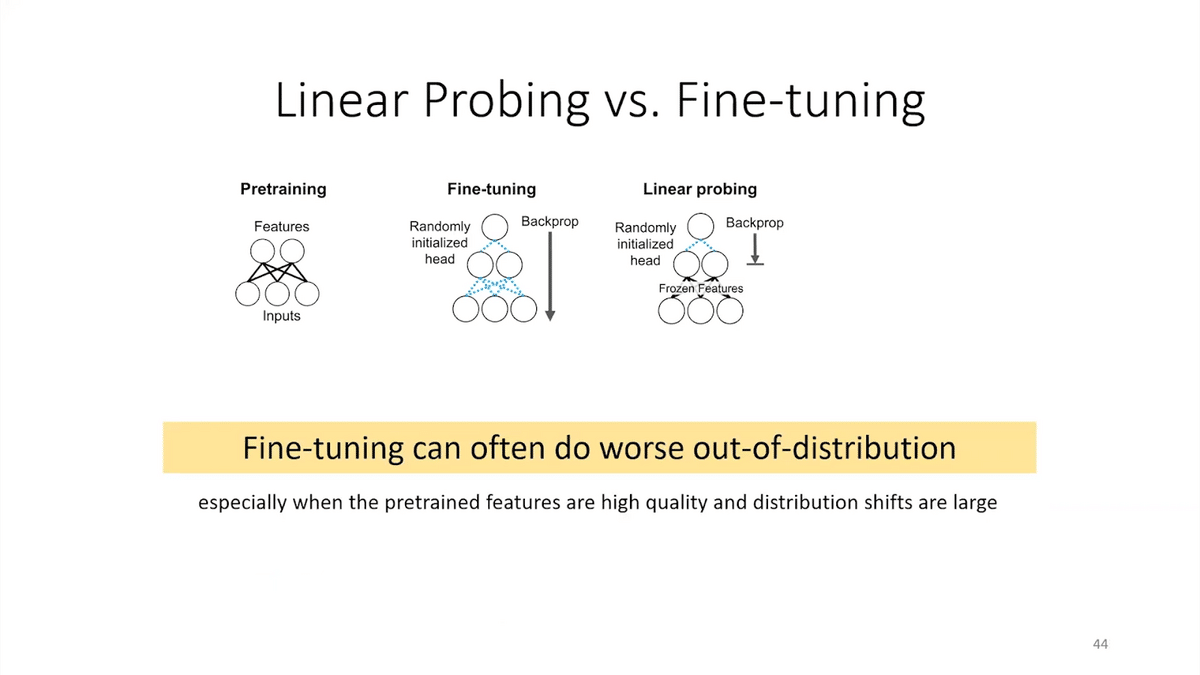
The takeaway here is that fine-tuning can do worse out-of-distribution than some of the other methods, especially when the pre-trained features are high quality and the distribution shift is large.
Fine-tuning and linear probing
I’ll spend a few minutes talking about why fine-tuning can underperform out-of-distribution, and then say a few words about how we can fix this problem—how we can get the best of both worlds: good in-distribution and out-of-distribution accuracy.
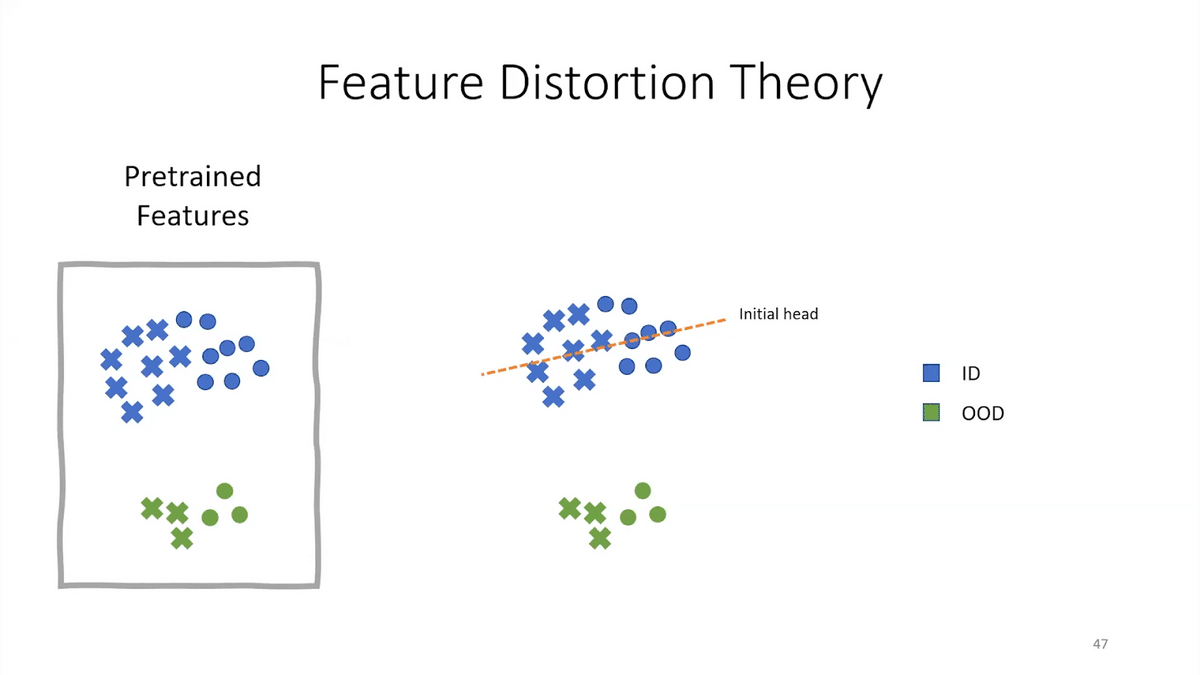
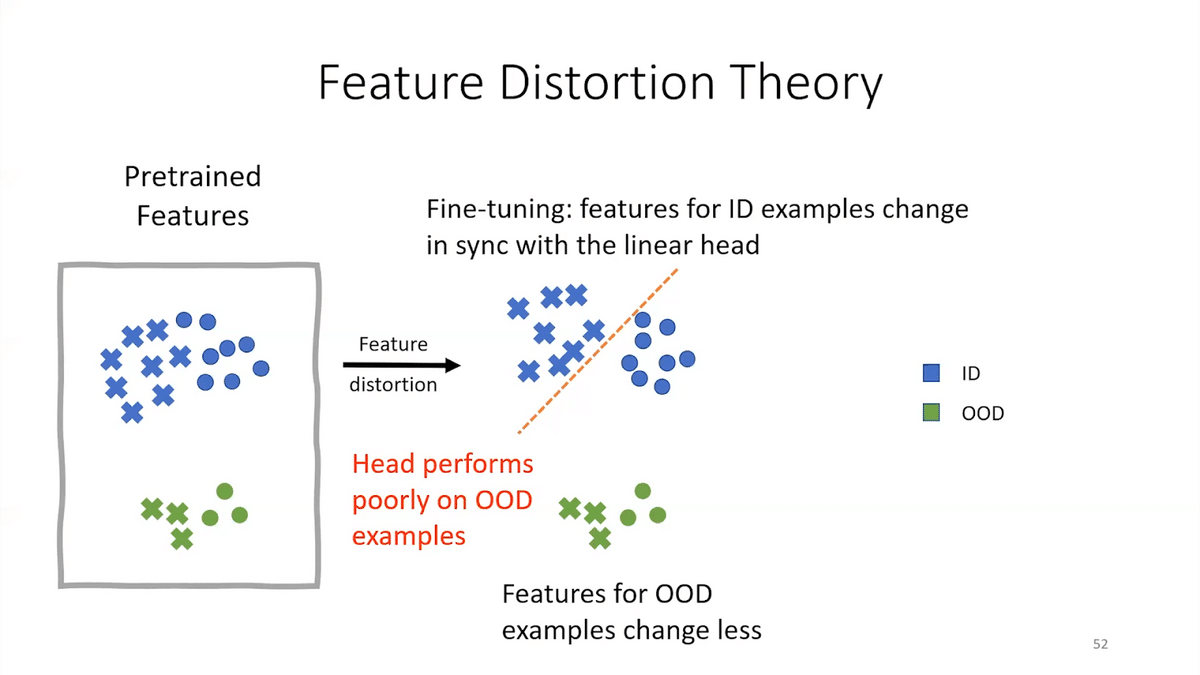
This is a very high-level visual illustration of why fine-tuning can do poorly. Suppose we have these pre-trained features, where blue is in-distribution and green is out-of-distribution, and the circles and crosses represent different classes. Fine-tuning starts off with first adding a head that tries to map these features to a label for your task, positive or negative. The head is usually initialized at a fixed value or randomly. Fine-tuning then updates both the head and the features of the model. It updates the whole model.
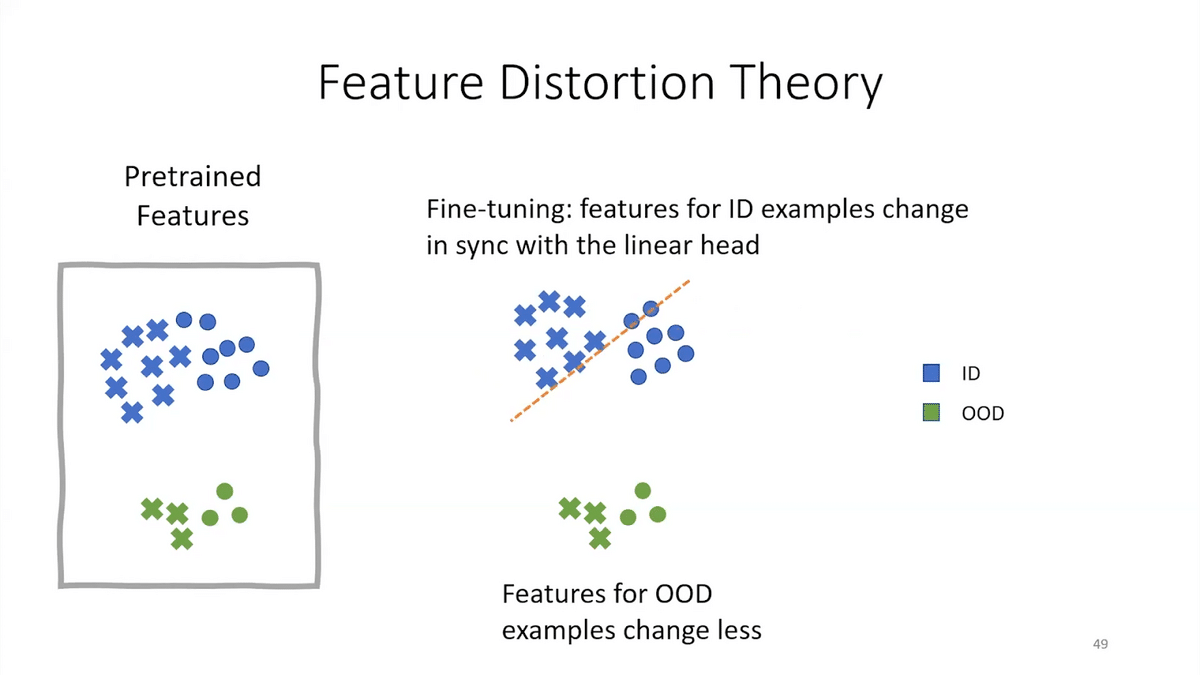
While you’re learning the head to try and separate the blue circles from the blue crosses, the features also change—fine-tuning also changes the features of the model. And, it changes features for the blue examples (which it’s fine-tuning on) more than for the green, which are unseen (these are the OOD unseen examples).
Eventually, it does well on the blue examples. It separates the blue circles from the blue crosses. But in this process, the features have gotten distorted. It’s forgotten the pre-trained features, and so now it does poorly on out-of-distribution examples. That’s the story for fine-tuning.
For linear probing, if you had good pre-trained features to begin with, a very powerful foundation model, then you don’t have this feature distortion, you don’t mess around with the features. You do slightly worse in distribution because you can’t improve your features, but your head extrapolates better out-of-distribution in many cases.
Okay, that’s kind of an intuitive explanation of why you might want to be careful when you fine-tune and why in some cases fine-tuning can do worse than other methods. How do we fix this problem?
In this case, we have a problem because fine-tuning often works better in-distribution (ID), but linear probing works better out-of-distribution. How do we get the best of both worlds?
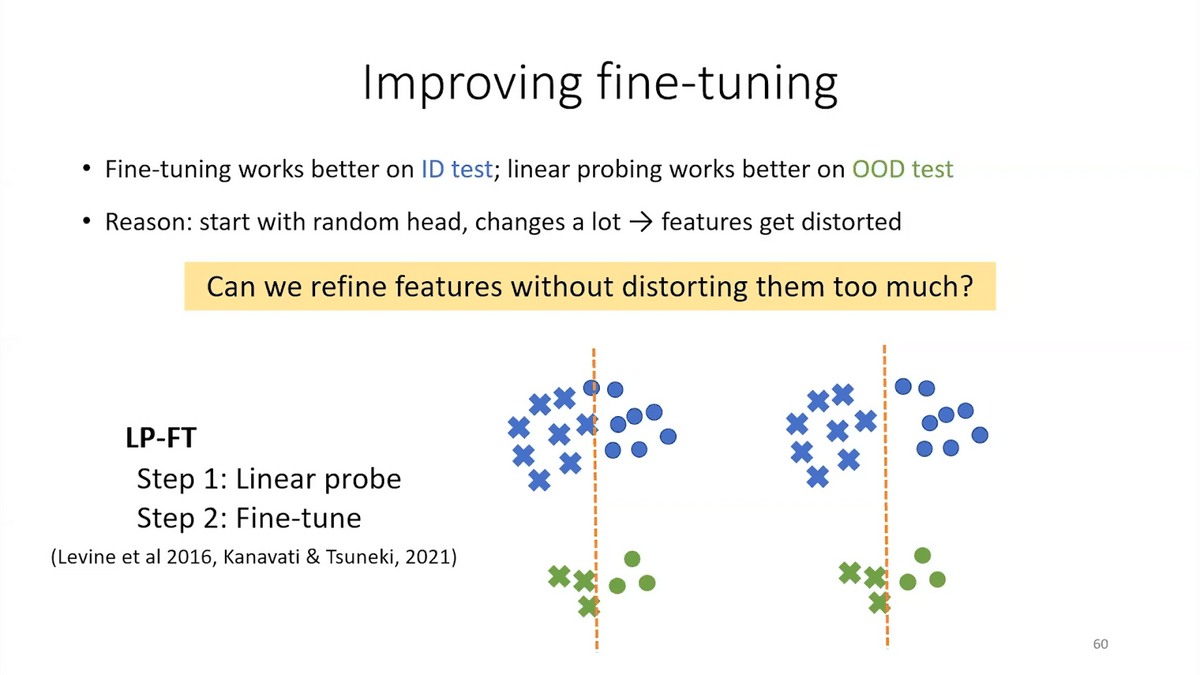
The reason fine-tuning did worse, in this case, was you started with a fixed or random head that needs to change a lot when you’re learning the task. In that process, your features get messed up. Can you improve your features for the ID without distorting them—without forgetting the pre-trained features?
One approach is LP-FT, which has been used as a heuristic in some previous applications. First you linear probe—you first train a linear classifier on top of the representations, and then you fine-tune the entire model. The reason this can work is that the first step learns a reasonably good classifier, and so now, in the fine-tuning step, you don’t need to change the linear classifier much. And so the features change a lot less. They get distorted less.
How does this perform in practice?
We ran experiments on standard datasets with a bunch of standard models, and we have a very rigorous tuning protocol that fairly compares these different methods.
Combining linear probing and fine-tuning delivers solid results
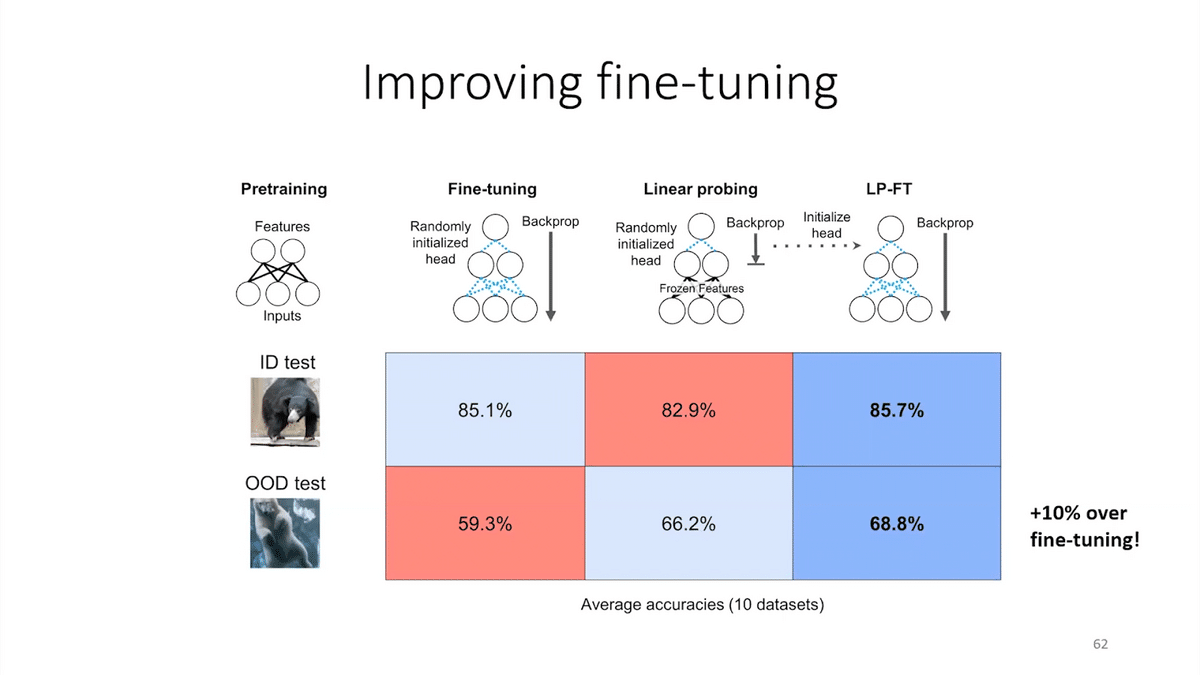
The executive summary is that this method of just initializing the head before fine-tuning did a lot better. It got about 10% better accuracy OOD.
The improvements were pretty much across the board—for ID, on five out of six datasets and OOD on all 10 data sets. Since then, this method has also been used to get state-of-the-art accuracy on popular datasets in machine learning.
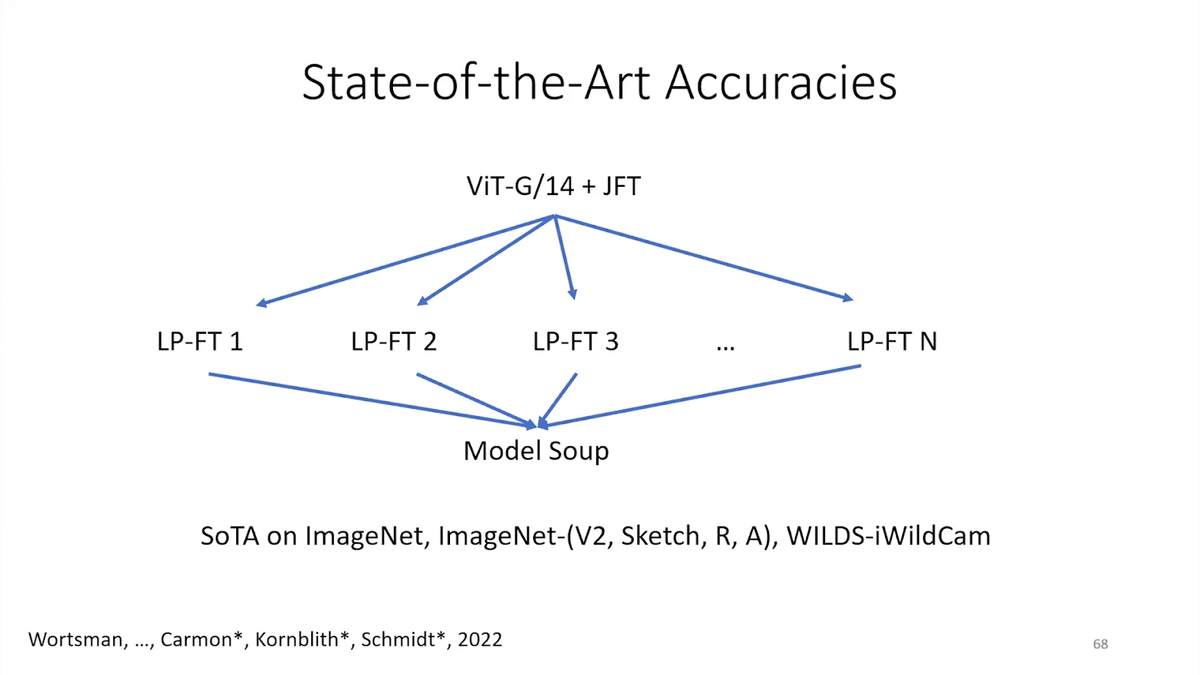
For example this team at Google and UW (University of Washington), they took a very powerful foundation model; they used LP-FT many times to fine-tune it on ImageNet, and then they ensembled this model together. This got state-of-the-art results on ImageNet, which is one of the most popular machine-learning benchmarks, and also [on] a bunch of these robustness datasets.
We’ve also had a lot of follow-up work since then, which came up with even more sophisticated fine-tuning methods. I’d be happy to chat with people who are interested.
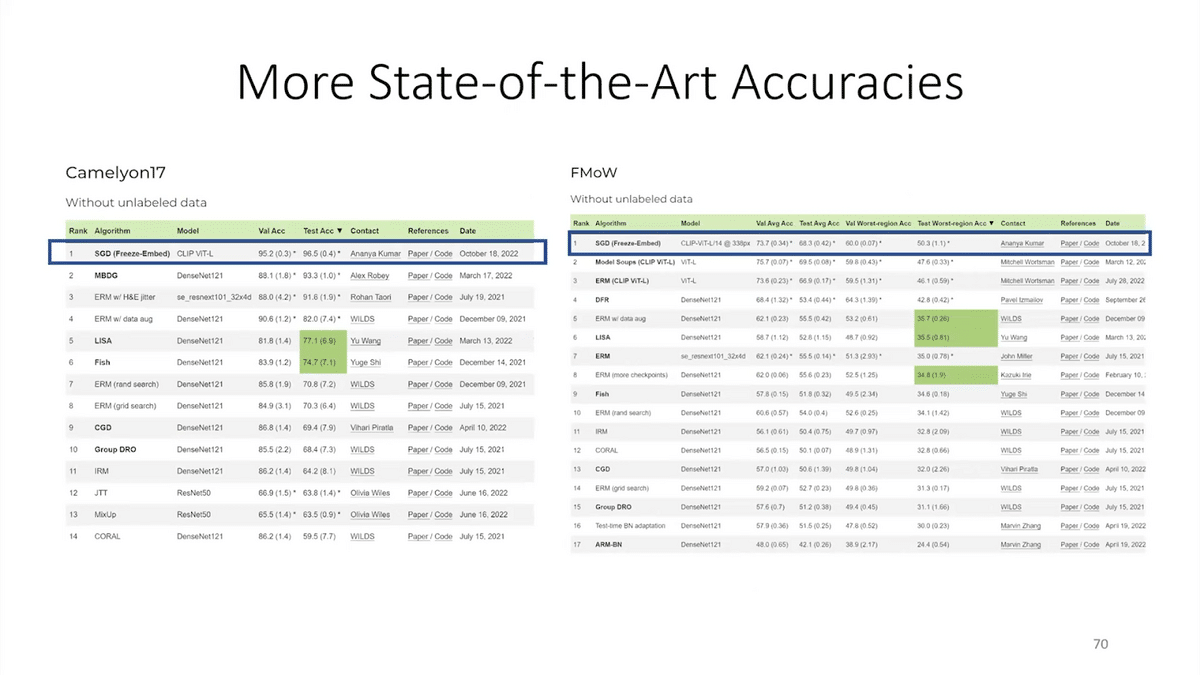
This has achieved state-of-the-art accuracies on real-world datasets in satellite remote sensing, in radiology, and in wildlife conservation. So, carefully studying what the fine-tuning process is doing and developing these slightly better methods can make a huge difference in practice.
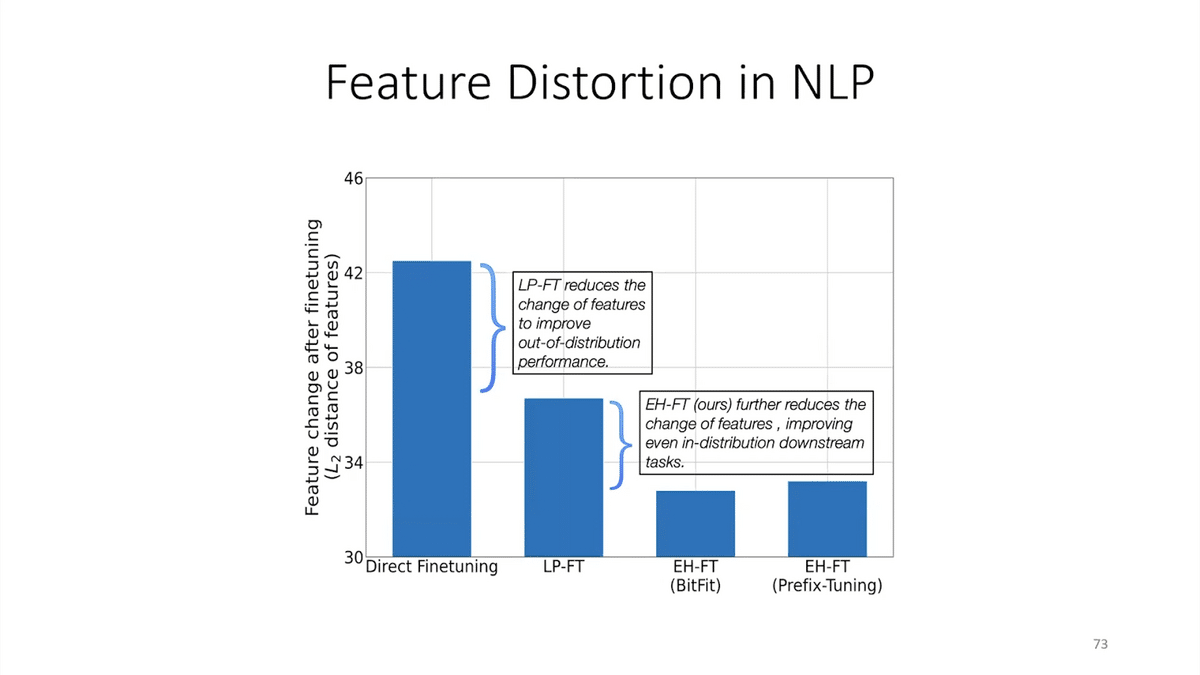
It’s (linear probing, fine-tuning) also been used in NLP recently. In NLP it turns out linear probing doesn’t do so well. What these authors do is they first use a parameter-efficient tuning method, like prefix-tuning or LoRA or BitFit, and then they fine-tune the entire model. This gets improved performance on standard NLP benchmarks, and they show that the features get distorted less.
Finally, I should say that this trend is much broader than just linear probing versus fine-tuning.
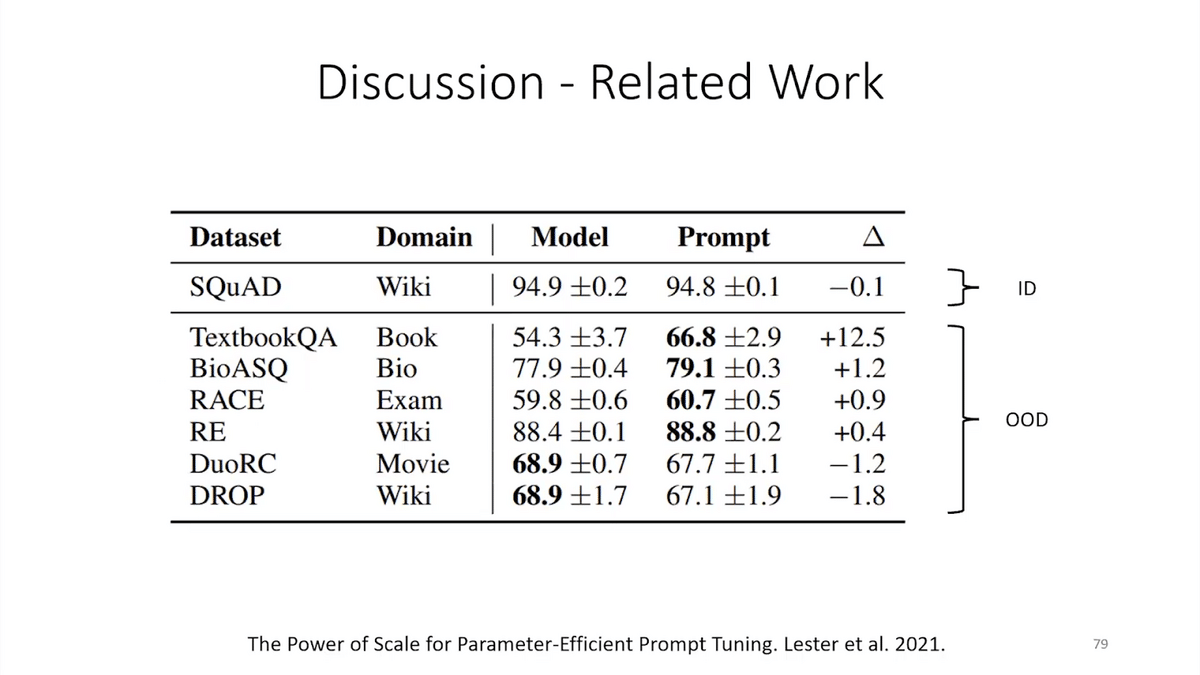
In NLP, in this paper, people compared prompt tuning, on the right, with full-model fine-tuning. And what they saw is that, on the in-distribution set, which is the top row, full fine-tuning often does a bit better. That’s under the “model” column. But on the OOD test sets, just tuning the prompt instead of tuning the entire model can often do a lot better, especially when the distribution shift is large. These things come up in a lot of other settings as well.
The high-level summary here is that fine-tuning can often do worse than other methods that tune fewer parameters out-of-distribution. We talked about why this can happen, and we showed how to use this understanding to come up with a simple fix that gets higher accuracies and even state-of-the-art accuracies on a lot of benchmarks.
The high-level point I want to make here is that foundation models have a lot of information stored inside, but the way we leverage this information can make a huge difference. We really should be careful about testing issues like robustness. What we actually care about in the task. And that can be very different from testing on standard in-distribution examples, which are just held-out examples from the training set.
Thank you.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.
Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•
Jacob Fleisig
Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team
Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 29, 2026
•
Chris Glaze
Join our newsletter
For expert advice, the latest research, and exclusive events.
By submitting this form, I acknowledge I will receive email updates from Snorkel AI, and I agree to the Terms of Use and acknowledge that my information will be used in accordance with the Privacy Policy.