Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Stanford professor on data-centric AI for healthcare and medicine
James Zou, assistant professor at Stanford University, gave a presentation entitled “Responsible Data-Centric AI for Healthcare and Medicine” at Snorkel AI’s Future of Data-Centric AI Virtual Conference in August 2022. The following is a transcript of his presentation, edited lightly for readability.
Hi, I’m excited to tell you about some of our work on responsible data-centric AI and applications in healthcare and medicine. So my group here at Stanford develops machine learning algorithms for biomedical and healthcare applications. We’re very interested in both developing these algorithms and also in deploying them into practice. So here are a couple of examples of things we’ve done recently. We’ve developed computer vision systems for looking at cardiac ultrasound videos and assessing heart functions and cardiac diseases from these ultrasound videos. We’ve also developed algorithms using machine learning to improve the clinical trial design process. These are now being used by some of the largest biopharma companies.

So one interesting challenge is that, as we’re thinking about deploying healthcare AI systems in a medical context, it becomes really important to think about how to carefully audit and evaluate these machine learning models. So I want to give you a concrete example, which actually comes from a sort of detective story that we had to recently solve here at Stanford.
So the context of this is that there’s been a ton of interest in developing AI systems, especially for dermatology applications. So you have algorithms, like the one shown here, that can take input photos of someone’s skin lesion, and then try to predict from that photo, how likely is this image to have skin cancer.
In this case, it’s likely to be melanoma, and the recommendation is to visit a dermatologist as soon as possible. The reason why this is very compelling from a healthcare perspective is that these kinds of photos of skin lesions are relatively easy to collect, so anyone with a smartphone can take photos of their skin lesions. And also there are many underdiagnosed skin cancer cases every year around the world. If you can catch them early, then that can potentially save a lot of lives. Here at Stanford, we’re very interested in trying out some of these technologies for diagnosing skin cancer.
So we took three of the state-of-the-art models, including some from commercial vendors, and we evaluated patients here at Stanford. Now, these models, all have actually very good performance. If you look at their original reported papers and publications, the AUC is often above 0.9. So when we applied these models to actual patient data from Stanford, the AUC had actually declined to about 0.6.
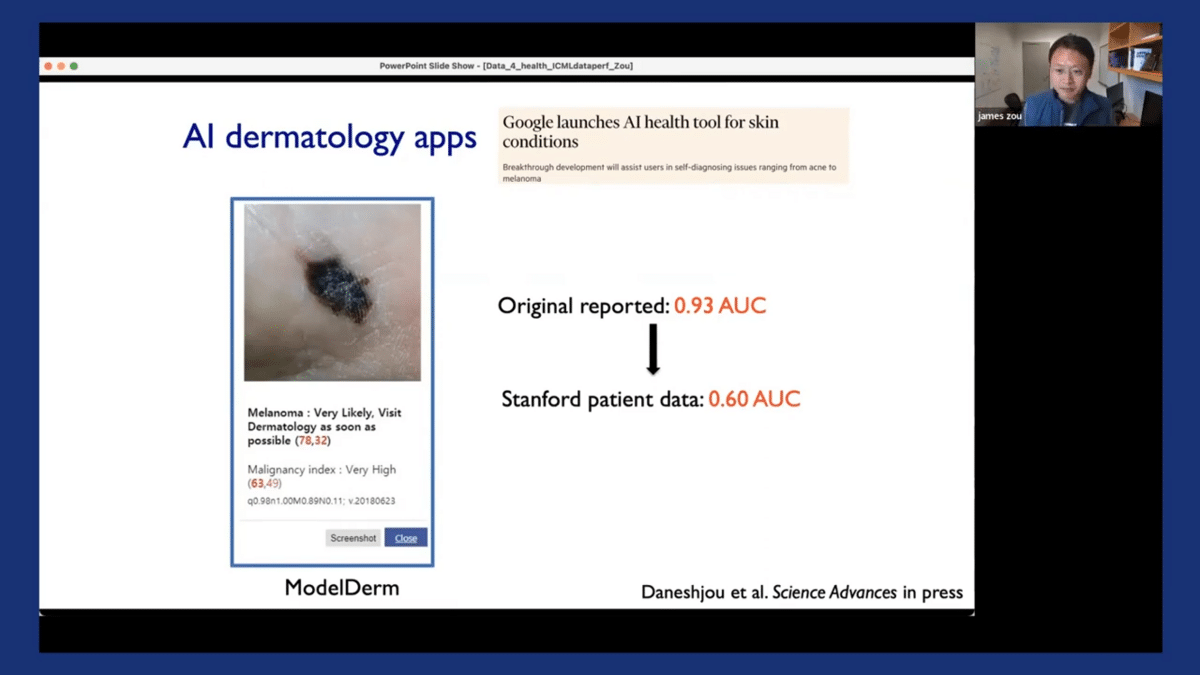
And just to be clear, these are actually real Stanford patients. There are no prohibitions on the data, we actually took these images directly from the electronic healthcare systems. So the puzzle, the mystery that we want to solve is, “Why did this happen? Why did these models’ performance drop so much when they’re applied to the actual patients?”
So we did a systematic audit to try and identify some of the issues with these models that led to this drop off from the original reported AUC from 0.9 to about 0.6. I think this is going to be illustrative and will set the broader context of why we want to have this data-centric perspective on responsible AI.
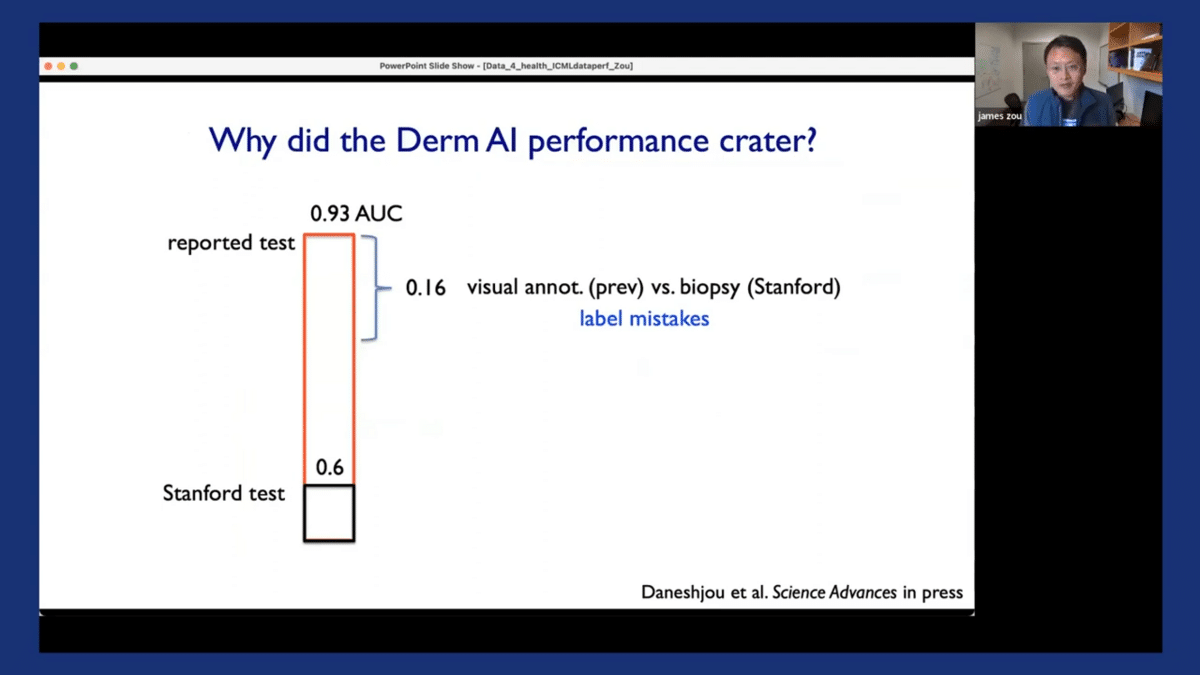
So it turned out that one of the biggest reasons that contributed to this drop-off is that there were a lot of label mistakes. It turned out that the original test data, the original images that were used to test and evaluate these algorithms had a substantial number of incorrect annotations in the label set.
So what happened was that the original test datasets for these models were mostly generated by having dermatologists visually inspect these images. And the reason was that it is easy to collect that kind of data, right? So the dermatologists look at the image and say, “Is this skin cancer or not skin cancer?”
And it turned out that dermatologists visually inspecting the images also make a lot of mistakes. So the actual ground truth data, which is what we use here at Stanford, comes from taking a biopsy of the skin lesion and then doing pathology testing to see whether it’s skin cancer or not. And when compared to the ground truth, the visual inspections that are used to annotate datasets actually had a lot of mistakes. And this can contribute to about half of the drop-off in the models’ performance.
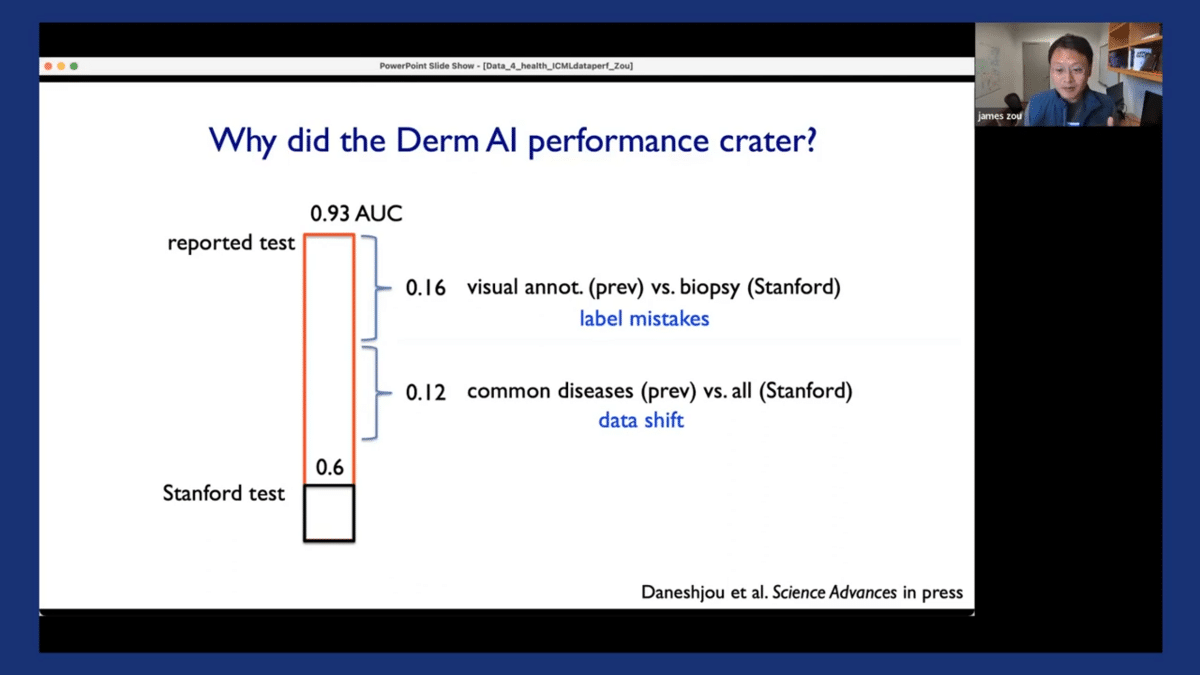
A second big factor is that there’s a substantial amount of data shift. So the original models were all evaluated on relatively common skin cancer diseases. And here at Stanford, our dataset had both common diseases and also less common diseases. So data shifts in the disease types also contribute to the models’ drop-off.
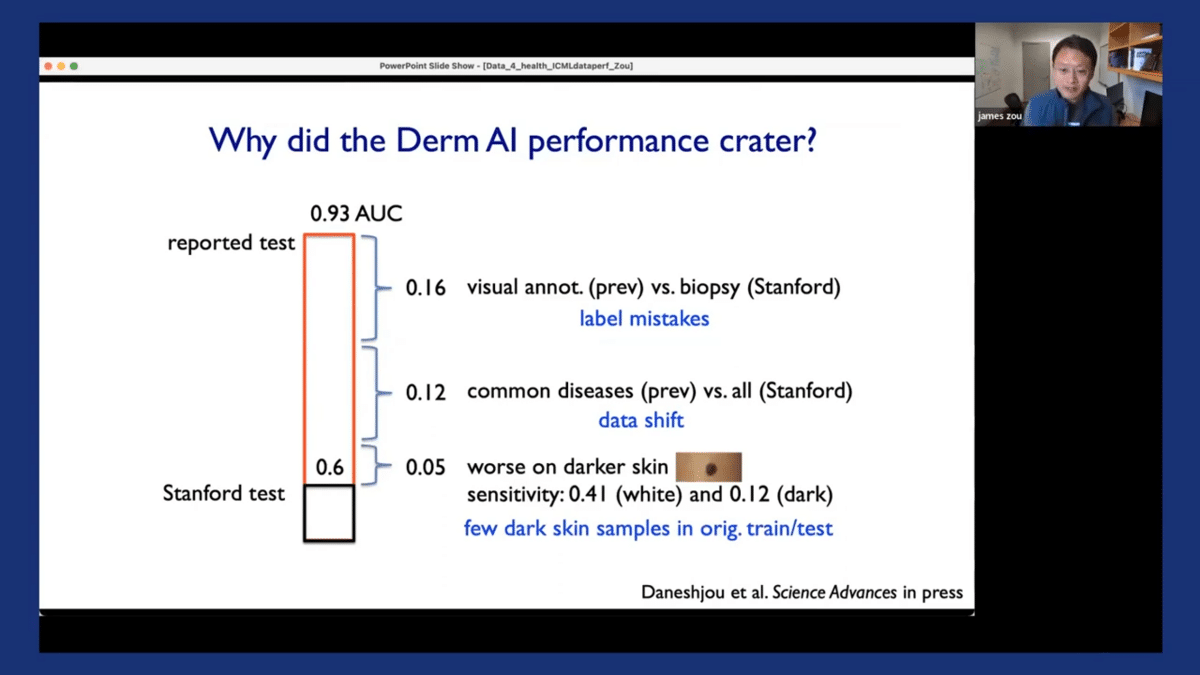
The third factor, which is also critical, is that we discovered that all of the algorithms had much worse performance when applied to images from darker-skinned patients. Specifically, if you look at the sensitivity of the model, which is, “If the patient actually has skin cancer, how often would the algorithms say that they have skin cancer?” That’s what we really care about. The sensitivity is actually quite poor on images from dark-skinned patients. And when we looked deeper into this, we discovered that there are very few dark-skinned images in the original training of test datasets for these models. So this is one case study that we performed which looked into dermatology AI models, and discovered there are a lot of challenges in the data that was used to train and evaluate these models.

Now in related work, we also performed similar kinds of audits for many other medical AI systems that were approved by the FDA. The FDA is the gold standard for approving medical-related interventions, drugs, and vaccines, including AI systems. So we looked at over 130 FDA-approved AI systems. They’re summarized in this plot that we have here, the paper that we had described in similar detail.
Each of these symbols corresponds to one of the FDA-approved AI algorithms, and I stratified them by which body part they apply to. So there is a lot of interesting information that we discovered, but perhaps the main thing that we want to note here is that actually, 93 out of these 130 AI systems that we audited reported only performance from one location.
Moreover, in 126 out of 130, the evaluation is performed on retrospectively collected data. So that means that it’s possible for these algorithms to be evaluated on previously collected, maybe benchmark datasets and from one location. And as we saw from the case study of the dermatology AI models, this kind of limited evaluation at one location on retrospective data can potentially mask a lot of limitations, weaknesses, or biases in the models.
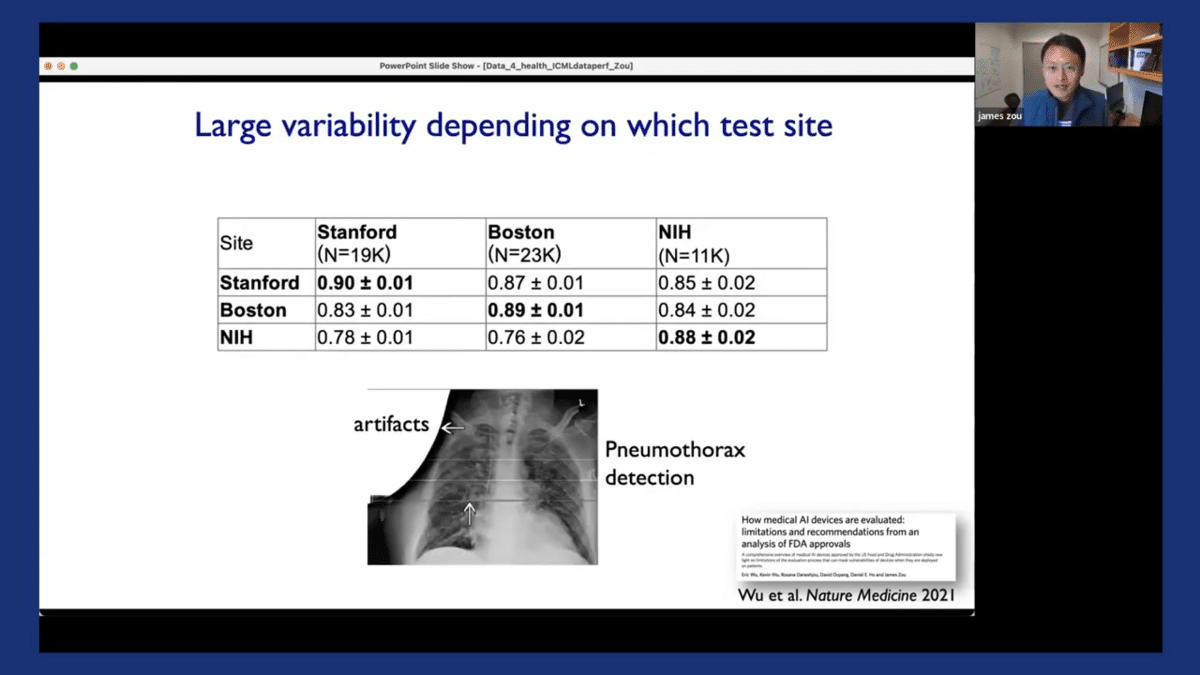
And we’ve also shown that the performance of the model can be highly variable, depending on which location they were tested on. To illustrate this, here I’m showing you three models that are used to detect pneumothorax from chest X-ray images. They were trained at three different locations, including Stanford, Boston, and at the NIH. We also evaluated them on test datasets from these three different locations. The diagonal here corresponds to the performance of the model when it’s tested at the same location where they’re trained. And off-diagonal corresponds to when it’s tested on data from different locations.
And you can see it’s actually quite apparent that the models’ performance on new test locations is sometimes substantially worse. For example, for the bottom row here, there can be a more than 10% drop off in the models’ performance once tested at a different site.
So all of this highlights the importance of really taking a data-centric perspective in biomedical AI, both in building the AI systems and also in evaluating and monitoring the performance of these AI systems.

So for the rest of the presentation, I want to quickly highlight the three areas we’ve been working on improving and the lessons we’ve learned in improving responsible data-centric AI for biomedical and healthcare applications.
So the first area is related to data maps, which is the idea of characterizing the landscape of the data that are being used for different biomedical algorithms. Second, we identify critical limitations in existing landscapes of datasets, and attempt to create new datasets. And lastly, we perrform more data valuations as a way to clean and improve biomedical data.

So the idea of a data map is to create a comprehensive mapping of the landscape of a particular domain to see what kinds of data are available and what kinds of data are being used to train and evaluate all of the algorithms in that domain. Here’s an example of a data map that we created for dermatology as our running example. So each of the squares here corresponds to one of the AI dermatology papers.
And each of the circles corresponds to a dataset that was used to train or evaluate the particular algorithm in that paper. You can see that they’re linked together. What’s interesting is that the color of the circle corresponds to whether a dataset is private—if it’s colored red—or if it’s a public dataset, it’s colored green.
So the private datasets are basically ones that nobody really has access to. And the size of the circle is proportional to how big that dataset is. So one thing that’s interesting is that there are a couple of large public benchmark datasets, like dataset one here that’s used in many of these papers. On the other hand, about half of the papers, especially the ones that are on top here, were trained and evaluated on relatively small private datasets. And based on our experience with our team and the systems here at Stanford, we can see that there are potential limitations in the algorithms that were trained and evaluated on private datasets. We also learned from doing this data mapping, that actually most of the existing datasets have very few images from dark-skinned patients, and many of them are very noisy in that they did not rely on the ground truth annotations which resulted from taking biopsy samples.
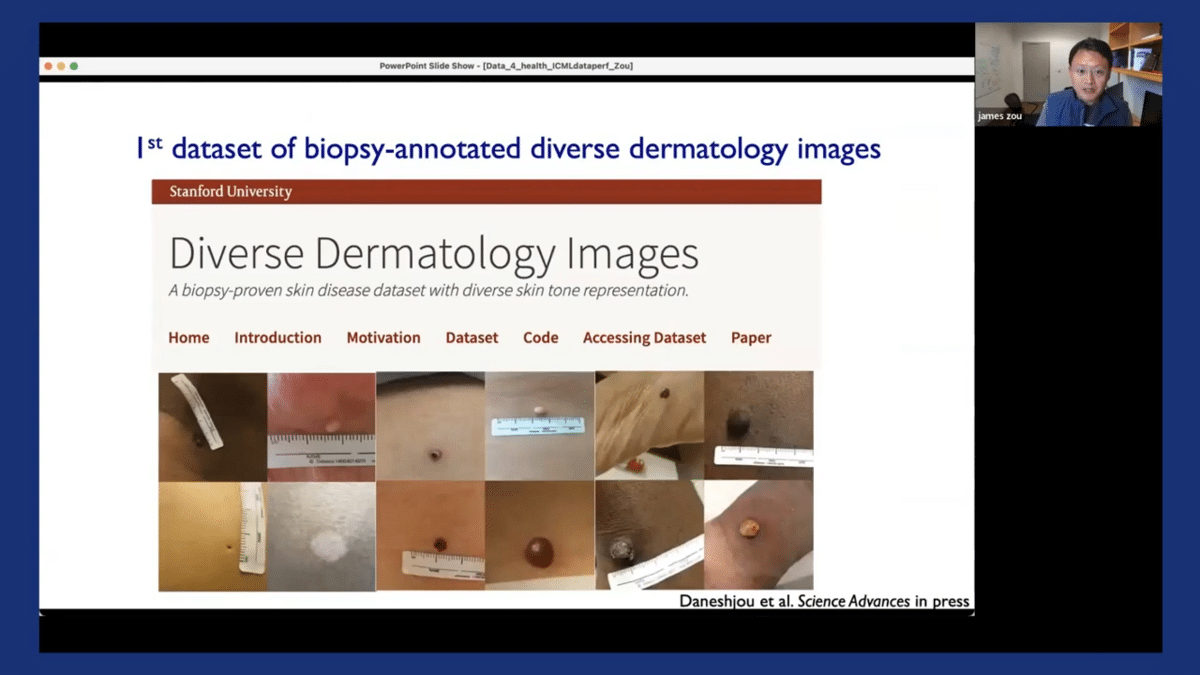
In order to address this limitation, we used Diverse Dermatology Images dataset, which is the first publicly available dataset that has high-quality labels from biopsy annotations, and also covers balanced images from across all the different diverse skin tones. This is work led by my postdoc Roxana in an upcoming paper, and the dataset will be available for researchers and the community to benchmark their models.
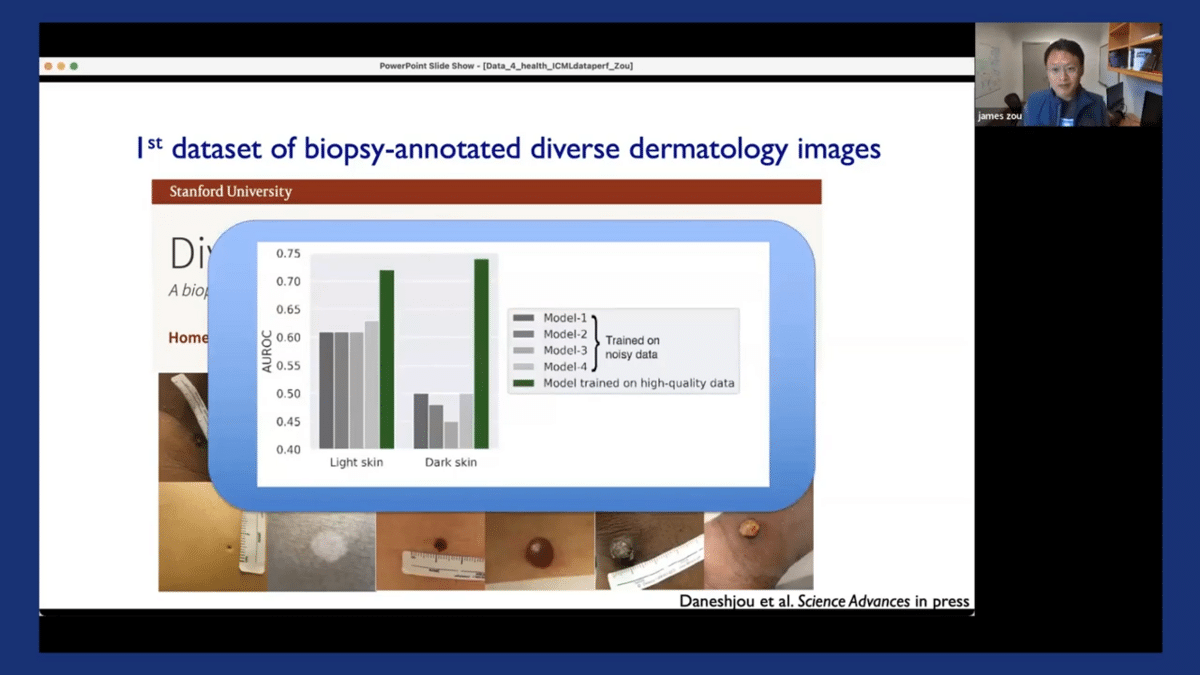
We’ve shown in this paper that by fine-tuning existing dermatology AI models on our new Diverse Dermatology Images dataset, we can substantially improve the models’ performance, especially on dark-skinned images. The green bar here obviously corresponds to the performance of the model when it’s fine-tuned on our diverse dataset.
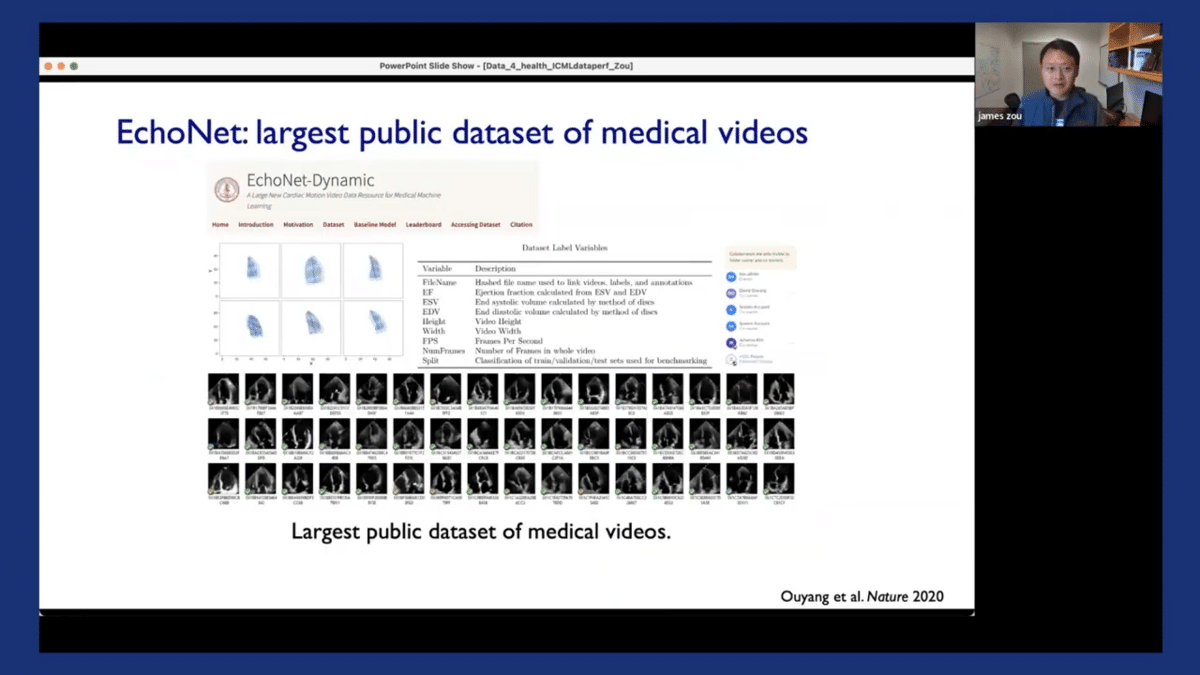
Another limitation in a different domain which we identified is that there are actually very few medical video datasets. To address this, we released EchoNet, which is one of the largest, maybe the largest publicly available dataset of medical videos. So it contains ultrasound videos of the heart, and also different medical annotations of the heart.

We’ve used this dataset to also develop a model that I mentioned in the very beginning, where we use computer vision to assess cardiac functions directly from these cardiac ultrasound videos. This work was led by my postdoc David and student Brian, and it was published in Nature, and we’re currently doing more in-depth evaluations and deployment of the system.

So this data map helps us to identify limitations/biases in existing datasets, and then we can create new critical datasets to address those limitations. In addition to creating new datasets, we also find it very important and helpful to think about different ways to increase data accountability in our machine learning pipeline.
I’ll briefly show you some of the work we’ve done using a concept called Shapley values as a way to improve the accountability of data-centric machine learning pipelines. The concept of the Shapley value is the following: in most machine learning pipelines, we have these three different components. We have training data, which can come from different hospitals or different vendors, and different sources. We have our favorite learning algorithm, which could be XGBoost or your favorite neural network. And you have a performance metric you’re interested in, which in our case is the deployment performance, or the F1 score of the models in deployment.
So data accountability basically means that if the model achieves certain levels of performance that I am interested in, I would like to attribute that performance with 80% accuracy back to the individual training and data sources. Similarly, if my model makes mistakes or exhibits certain biases, I would also like to identify those biases/mistakes and identify which training data might have contributed to those biases/mistakes, perhaps because of misannotations, noise, or other spurious correlations in the training set. If I can achieve an entire pipeline of accountability, then I can potentially improve the accountability and transparency of my entire machine learning system.

So the Shapley value is basically a method for assigning these evaluations. I won’t go into too much detail here, but I just want to highlight that we have a series of works, including some recent work for computing these data Shapley values, and also scalable ways that can be applied to very large datasets, of hundreds of thousands of images for example.
So I want to quickly demonstrate the output of the Shapley value and how we can use that in practice. So going back to our running example of dermatology AI models, we have our training datasets and we see that the training dataset can often be very noisy and can have misannotations. Additionally, the model that’s trained on this dataset, when it’s deployed in the clinical settings, the performances we observed are often quite poor—there’s a drop off in the model’s performance. So the Shapley value assigns a score to each of the individual training images. The score could be positive or negative. If the score is negative, it indicates that that particular image is detrimental to the model’s performance in deployment. Perhaps it’s introducing some label noise, or maybe it’s introducing certain spurious correlations in the model. If the score is positive, it means that that particular image is quite informative to the model ad helps us make good decisions in practice.
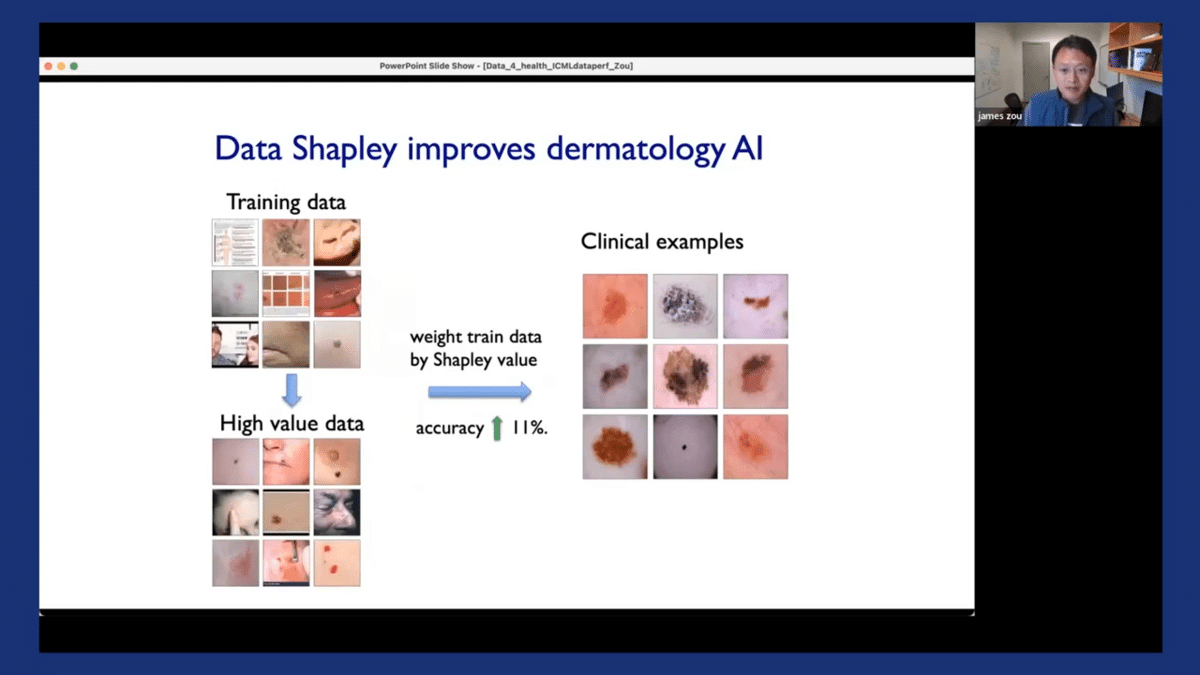
So it’s actually very useful to have these scores. One thing we can do with them is that we can weight the training data based on these Shapley scores, and then simply retrain the original model on this weighted dataset. This basically encourages the model to pay more attention to the data points that are more informative and pay less attention to data points that are likely to be more noisy. By performing this weighted training, we can substantially improve the model’s performance in deployment—in this case, by over 10%. And the benefit of doing this is that it’s very easy to do. We didn’t have to go out and collect additional new data. All that we needed was the existing data that we had already collected.
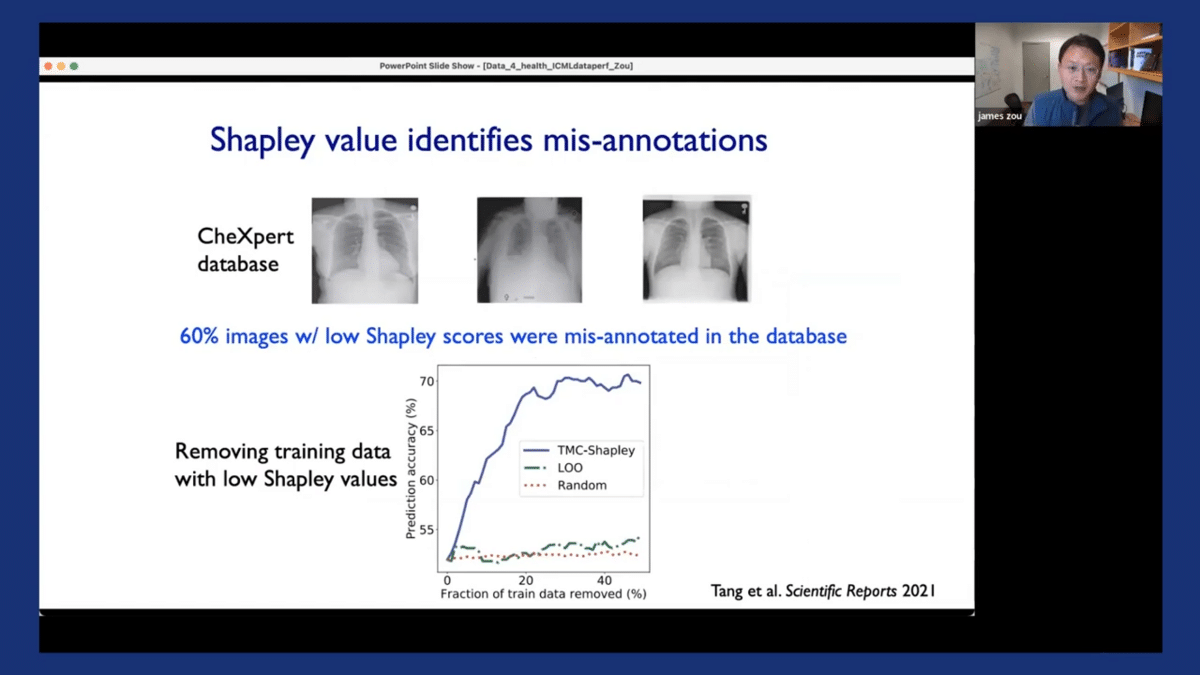
The Shapley values can also help us to identify misannotations, which are quite prevalent, especially in medical datasets. We applied this approach to this CheXpert dataset, which is a very large dataset that’s commonly used that contains these chest X-ray images. What’s really interesting and striking is that when we looked at images that had low or negative Shapley scores—we asked a panel of experienced radiologists to annotate those images—we found that 60% of the images that had these low Shapley scores were misannotated in the original EHR, in the original database.
And we demonstrated that by removing the poor-quality misannotated images that had low Shapley scores, we were able to substantially improve the model’s performance, as the models could be trained on the remaining datasets, which are much cleaner and high quality. So the Shapley scores can also be an effective approach for cleaning datasets by removing noisy samples.
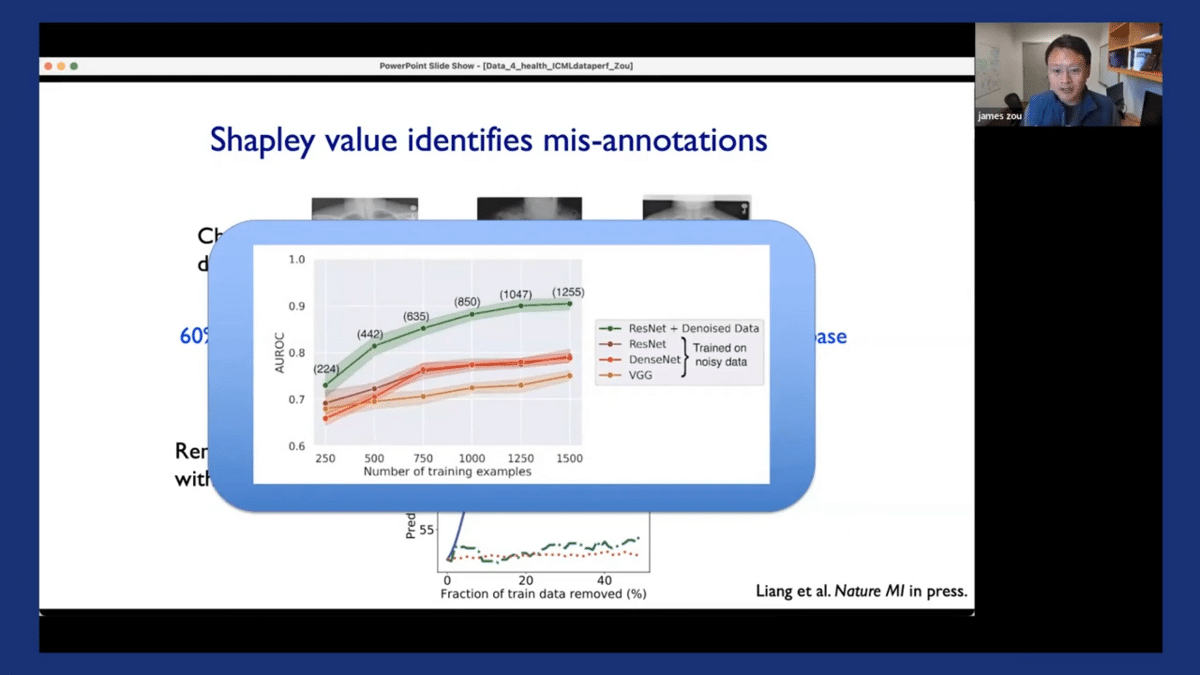
Oftentimes, the performance gains from removing noisy samples by using Shapley scores are actually much larger than performance gains made by trying to change different model architectures on the original noisy dataset. Here’s an illustration of this. So the green curve corresponds to taking one of these models and de-noising the dataset using the Shapley scores. You can see that we can really improve the model’s performance quite substantially. And the different red curves correspond to different ways of training the model using different architectures but training on the same noisy data. And when it’s trained on the noisy data, the model’s performance often saturates. There are much greater improvements potentially coming from this data-centric denoising of the dataset.
To summarize, I hope to illustrate that, especially in biomedical AI settings and healthcare applications, these data-centric considerations are especially interesting and it’s very important to take a data-centric perspective both in training and evaluating the models.
We’ve also shared three main lessons, based on our experience, that we found to be very helpful practices and approaches to improve the quality of our data-centric pipelines. The data maps helped us to develop a holistic way to see what kinds of data are being used in a particular application domain. And by looking at those data maps, we can identify the critical gaps in the datasets, which helps us to create and to identify new datasets that we can create to contribute to filling in those gaps. Additionally, I believe data evaluation is a quite nice and general approach for further improving and cleaning the datasets.

And here are some of the key references for each of these methods I’ve described. So I just want to stop here and thank you for your attention. All of the papers, data, and code are available on my website. I just want to really acknowledge again the terrific students and postdocs, Roxana, Eric, David Amirata, Yongchan, and Weixin, who’ve led these works.
Questions and answers on AI for Healthcare and Medicine
Priyal Aggarwal: Awesome. That was such an amazing talk. Thanks so much, James. I particularly like the analysis investigating model performance degradation in the Stanford dataset, and you also provided some great solutions to solving some of the challenges that you mentioned. And I think the importance of this data-centric approach to AI really becomes eye-opening, especially in the context of healthcare applications. With that, we have a bunch of questions in the Q&A tab. The first one is from Alec and they say, “How are we able to effectively gather data to properly detect and classify new diseases and viruses? With Covid-19 and now monkeypox it should be a priority for pandemic prevention.”
James Zou: Yeah that’s a great question. So I think actually a lot of the really useful, exciting data are already collected. They’re sitting in different medical records. And I think there’s a lot of value to be gained in leveraging existing datasets in the medical records to be able to do detections of new viruses or studies of Covid-19. And we’ve done some work on all those fronts. I think this is also where the data-centric perspective becomes really critical because a lot of the data is sitting in these medical records, but they’re often very hard to work with for computer scientists and for machine learning folks. Since these datasets contain a lot of unstructured data, it requires a lot of data cleaning, selection, and curation. So that’s why I think actually this kind of healthcare biomedical data is, one of the most impactful areas of more data-centric advances.
PA: That makes a lot of sense. We do have another related question about Covid-19. Alex says, “Covid-19 has had a lot of impact on historical medical data and they’re considering excluding that data from training since it’s so unusual. Are there any other approaches that people are using?”
JZ: Yeah, so that’s also really interesting. We’ve had similar discussions of how to deal with Covid-19 data in some of our works looking at clinical trials, for example. You have clinical trials that happened before Covid-19, like in 2019, and then you have the ones in the last few years. And we found that in some of the cases, it’s actually better to not just throw away all of the data from before two years ago because that really does remove a lot of useful information, a lot of data. I think there are also interesting approaches to still keep the data prior to Covid-19, but use other ways to adjust the distributions to make them more comparable.
PA: That makes a lot of sense. If you’re just deleting some data from your entire training set, then you’re losing other information that could have been very useful for training. Makes sense. The next question is from Fu and they say this is a little off-topic, but they have read that there are some security concerns regarding medical data used in machine learning, and they’re wondering if this is still currently a problem in AI healthcare. If so, do you happen to know some of the steps taken to protect the privacy of patients? And if not, do you know why this is no longer a concern?
JZ: That’s also a very good, interesting question. So I would say it’s still an ongoing concern about the security and privacy of the data, especially from the perspective of the hospitals because if they own the data, they could potentially be sued if the data becomes leaked or public. For many of the patients, on the other hand, I think many of them are actually excited to share their data and make their data available, especially for medical research. So there are efforts in the US like these “All of Us” projects and in other countries where millions of patients actually share their genetics data for research purposes. So I think there’s this interesting trade-off and one area going forward is thinking about how to work directly with the patients. Essentially bypassing the hospital, and going directly to the patients, where we can get the most useful data directly from the source. On the machine learning or technical side, there are also interesting approaches to try to mitigate these potential security concerns. So one of the areas that we’re actually working on is looking at synthetic data and how to generate synthetic data that has good privacy guarantees so it doesn’t leak sensitive information, but is still high utility.
PA: That makes a lot of sense. Thank you so much for sharing. We have a bunch of questions in the chat, but unfortunately, we are running out of time, so we will not be able to get to all of them. But in case the attendees want to reach out to you to ask their questions directly, what would be the best way to connect with you?
JZ: Yeah, so please feel free to email me directly. I’m happy to follow up. Happy to respond.
Catch the sessions you missed!
The Future of Data-Centric AI 2023, our two-day free virtual conference, brought together thousands of data scientists, AI/ML practitioners, researchers, and the AI community at large to hear about and discuss the latest trends and research in data-centric AI. If you registered for the event but didn't see all the sessions you wanted, you can now catch up. The recorded sessions are available for registrants at the same Zoom portal as the live sessions.

Team Snorkel