Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Sambanova on using LLMs to squeeze value from business data
Stefano Lindt served as the Head of Technology, ISV, and GTM Partnerships at Sambanova. He presented “Lightning Talk: Leveraging NLP to Extract Value From Business Data” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. A transcript of his talk follows. It has been lightly edited for reading clarity.
In this short presentation, I hope to give you a quick overview of how you can leverage large language models to extract valuable information from your data.
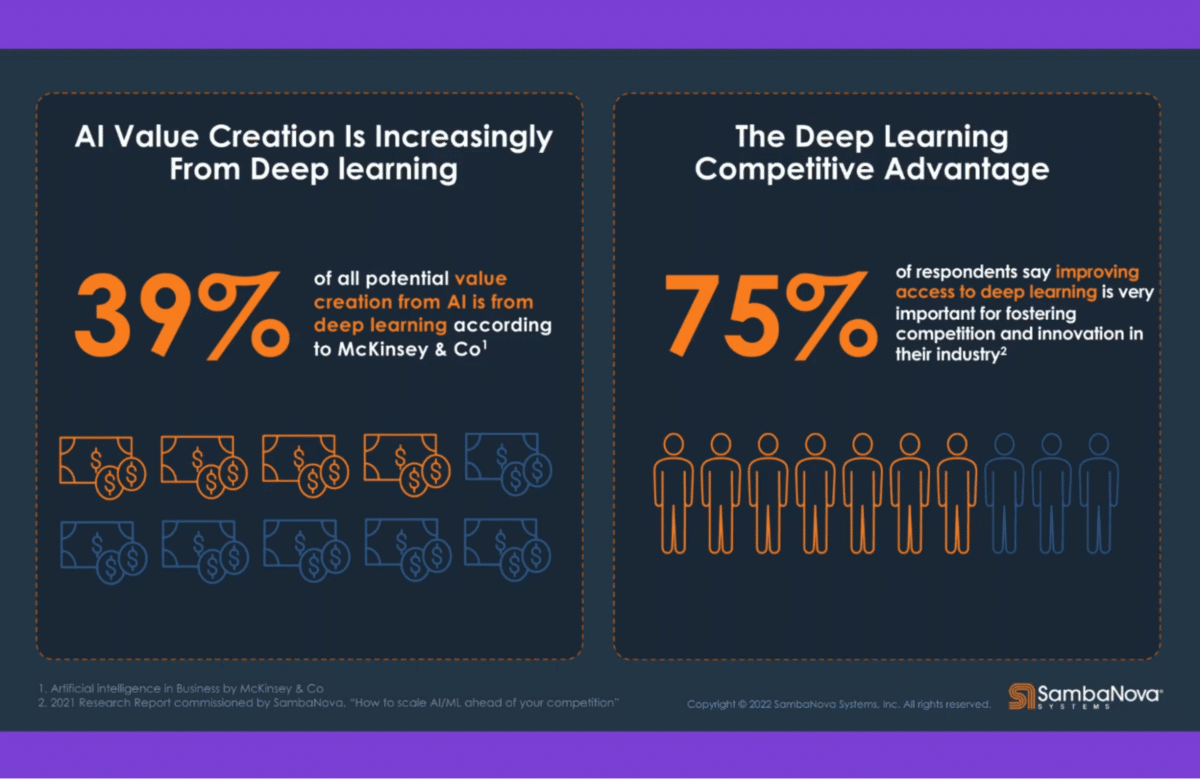
We are all familiar with the notion that deep learning language models and computer vision are technologies that will be widely used in business going forward. Some people think that machine learning, AI, and deep learning is more important than the web and will have a bigger impact on transformation than the web.
Deep learning is one thing. Machine learning is another. The challenge with deep learning is that a lot of our data is unstructured. Structured data lends itself very well to machine learning, but when it comes to deep learning, it’s all about extracting insight and information from that unstructured data.

Let me just start with one example that I think most of us are familiar with—the contact center. Everything is, pretty much, unstructured data. There’s voice, there is chat, there might be emails, there might be other forms of communication.
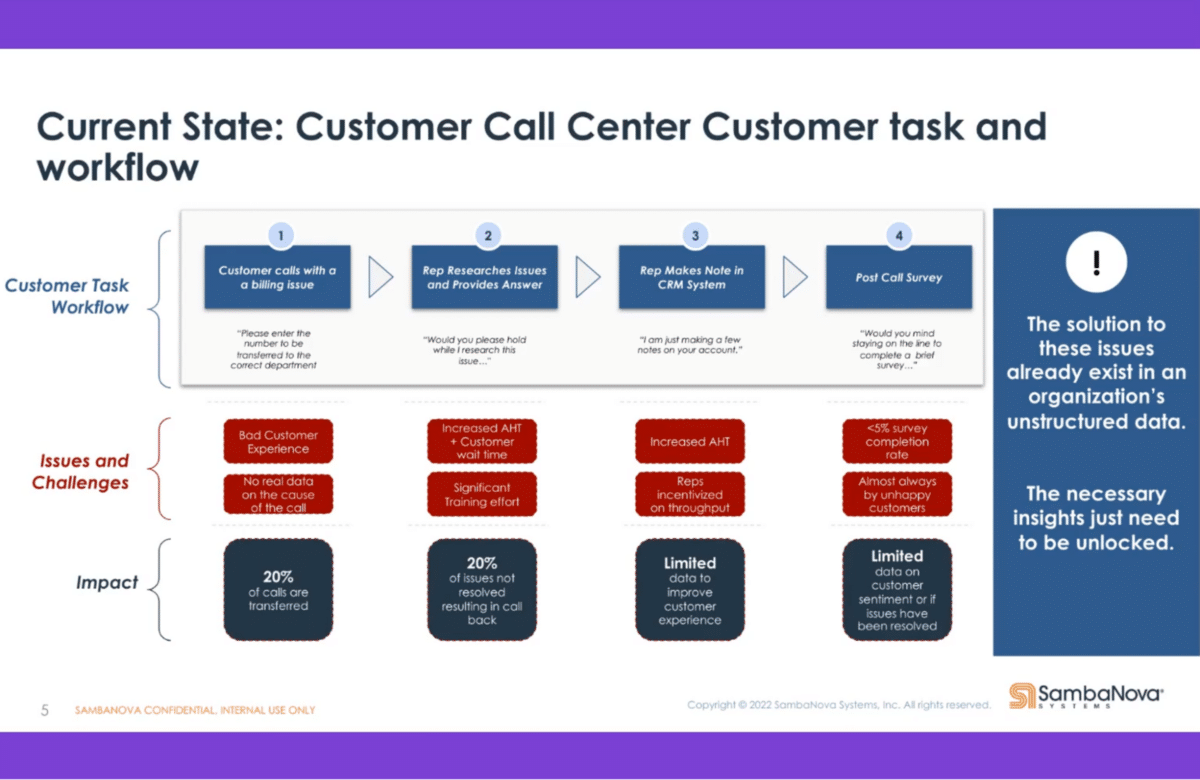
I think all of us have been in a situation where we logged onto a vendor site where we have an account, we have a question, and then the little chat window opens on the right bottom. We try to get an answer to the question we have, only to have to reauthenticate ourselves, which is really annoying. After we tell them what the question is, we don’t get an answer but they refer us to somebody at a call center, so we end up calling them anyway. This is one example of how deep learning can help solve that problem and actually address my questions directly.
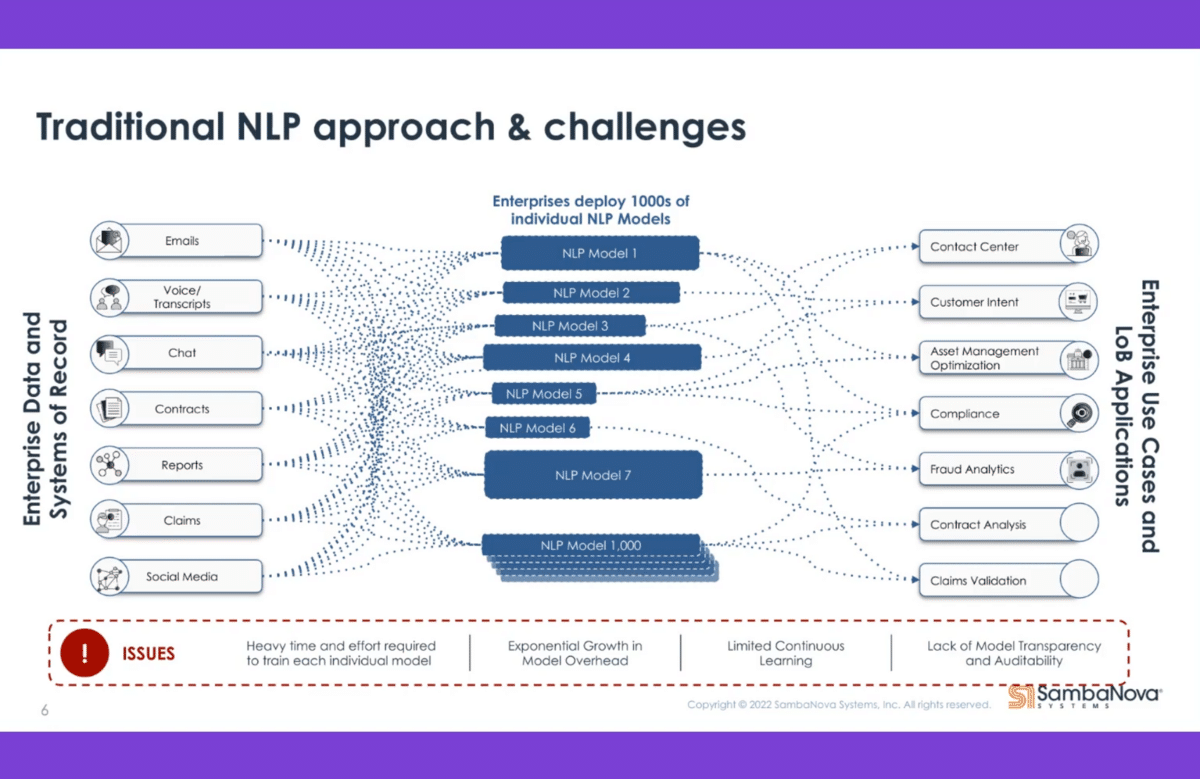
Today you have a multitude of channels. You call a call center. You have chats, you have a chat box, you might have messages, you might have email, you might have a Facebook page where you interact with your customer—you have tons of different channels where you interact with your customer.
The challenge with that is how you can aggregate all that information. Companies use different models for different channels that are distinct. They might use a language model for voice, which translates the voice into text, for example, then analyzes the text. They might use a model to analyze the tonality of your voice to identify if you’re happy or if you’re not happy and accordingly address that. Companies are using many different models, which makes it hard to have a consistent experience across these channels.
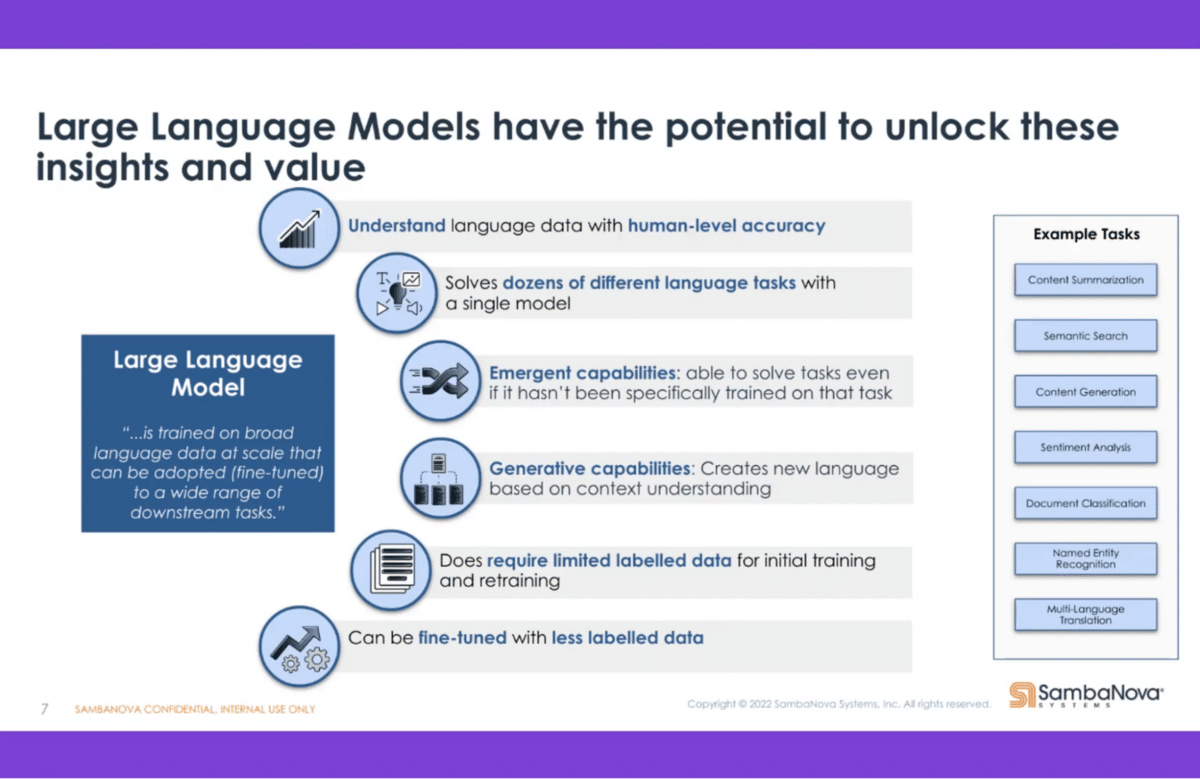
That’s where the large language models come in. When we think of large language, that’s language models that can have up to a couple of hundred billion parameters that are being used for executing the tasks. Google announced a model with over a trillion parameters back a month or two ago. These models are getting bigger and bigger. They get more and more precise and exact to address the need of the customers and the companies. They can do multiple tasks simultaneously, so you don’t have to have these multiple models like the prior example. You can have one model that helps you with the analysis of your unstructured data.
As capabilities evolve and our needs evolve, you can adjust the model and address these new tasks that might come up. You can also use the models to generate insights from the data. Some of you might have seen the poems that have been written by machines, or news articles that have been compiled by deep learning models where there has not been the involvement of people in that context.
Suddenly, you have one model that allows you to execute all those tasks against all those various channels. This means that you have a much, much higher understanding of your customer. You can much better address the need of your customer.
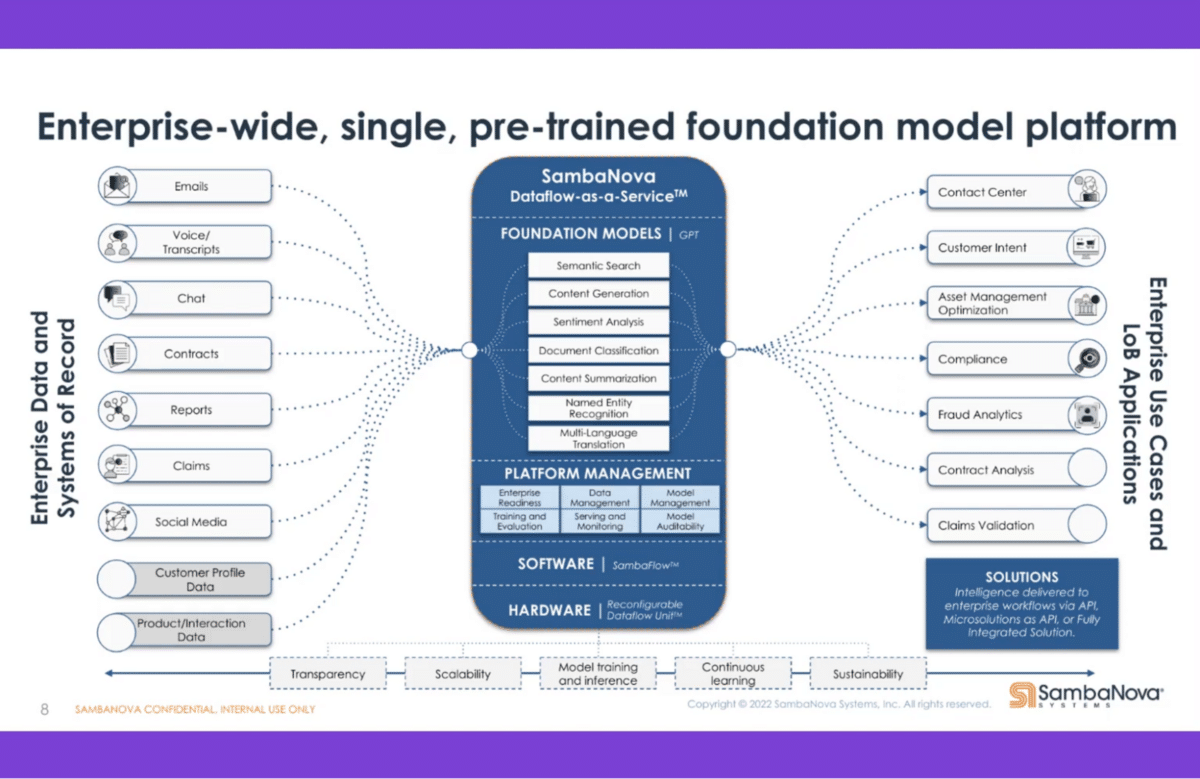
Back to the example at the beginning, if I’m already logged into the website and now go to the chatbot, it should be able to relate to the fact that I’m already logged in and I’m already authenticated—and that I might have a question about an order that I just submitted. This is like some of the airlines today when you call them and they ask you, “Are you calling about this flight?” without you having talked to a person yet. These large language models allow you to execute multiple tasks simultaneously and make it much more effective and efficient to serve your customers.

The challenge is that these language models, as you can imagine, are very big. They require a lot of resources, require data scientists to help with deploying these models that apply to businesses. You have to build the hardware infrastructure or the cloud vendors. You have to have your data scientists and data engineers internally. You have to adopt the processes that you might have internally. You make sure that any results you generate get to the right place at the right time.
What we do is help organizations shorten that time span by providing the models as a service. At the highest level, how we work is we get your data, we train our models based on your data—we have foundational models that are pre-trained on standard data. We even have models that are already trained, pre-trained on specific industries. Then on top of that, we use the data of the customers to train and refine the models. We then run the inference through those models and provide the customer with the outcome from that model. That can be done in weeks instead of months or years. Customers don’t have to deal with the complexity of these models, but can really get to the results quickly.
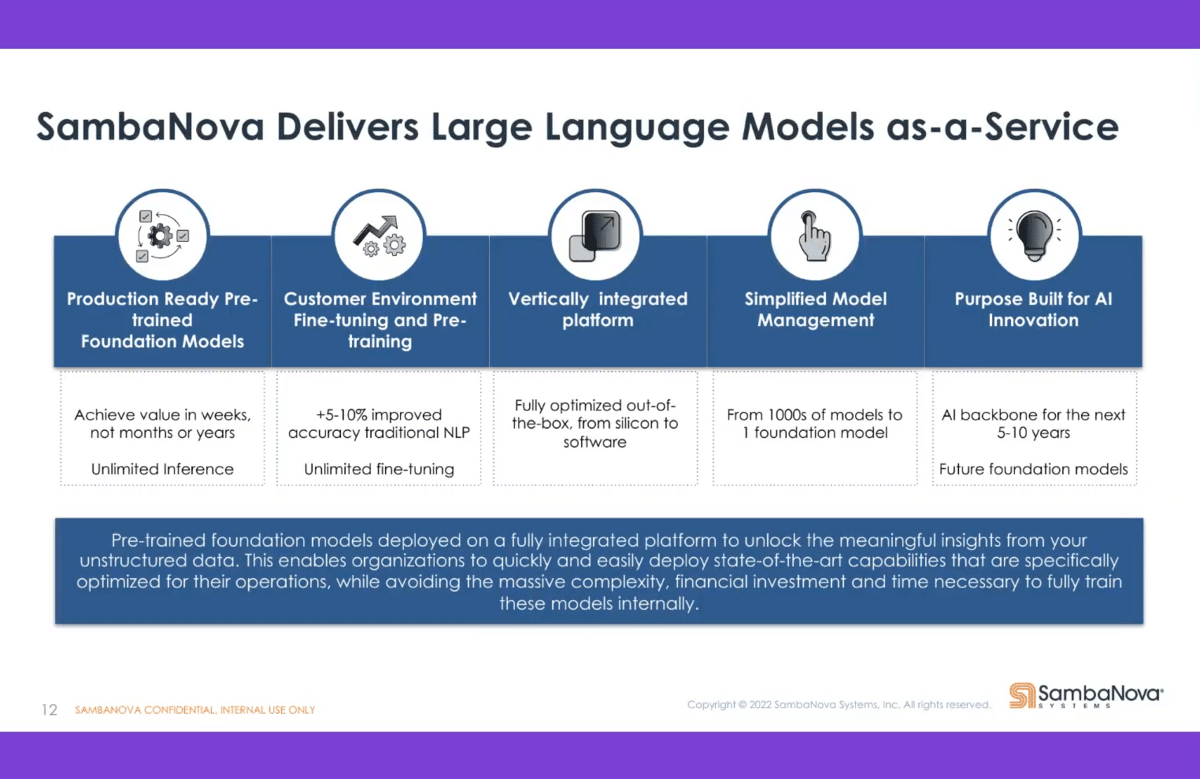
To summarize, we have ready-to-go pre-trained models that can be customized for customers. We can help with the fine-tuning, and we can do some of the pre-training. We simplify the management of the models, depending on the volume you have. Finally, we help organizations build AI into their processes and drive innovation for them.
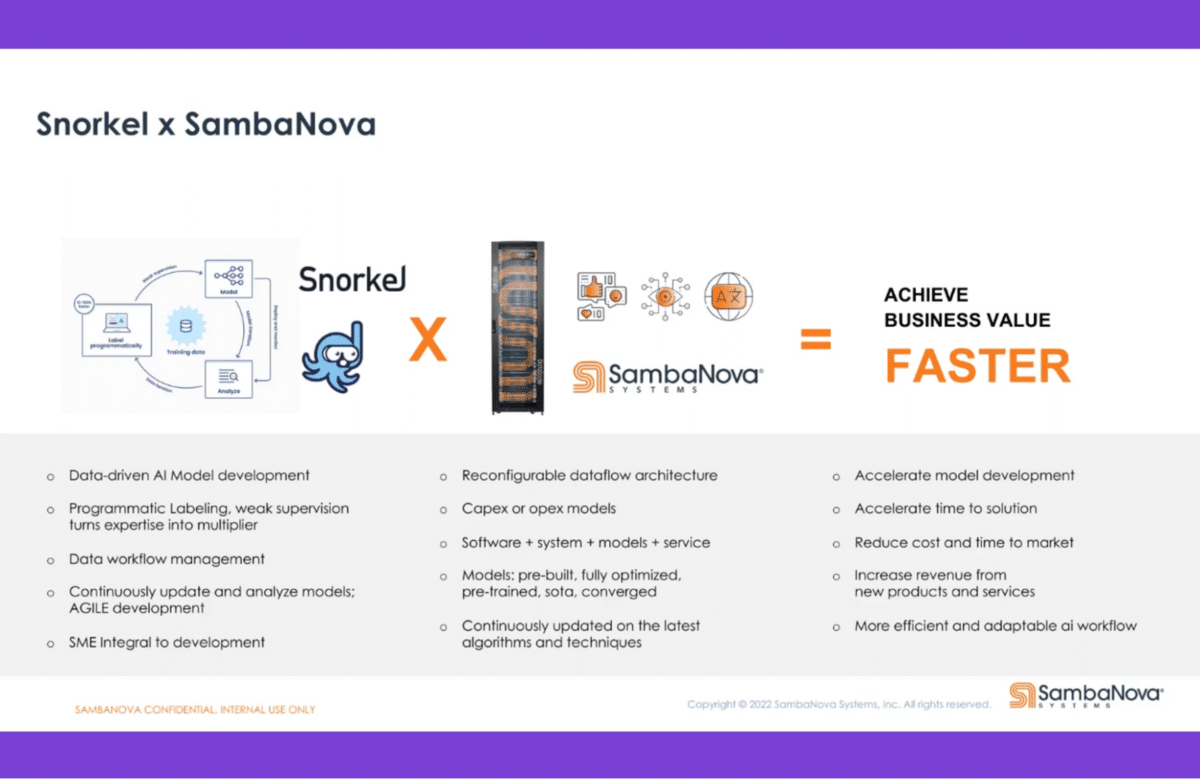
We heard a number of talks today, and a lot of the talks were talking about data and how data was critical in making these models successful. That’s where our partnership with Snorkel comes in—to help us and our customers make sure that the data is properly labeled and properly annotated so that we can effectively and quickly leverage the data from the customer in our models and provide them with value in a short amount of time.
Catch the sessions you missed!
The Future of Data-Centric AI 2023, our two-day free virtual conference, brought together thousands of data scientists, AI/ML practitioners, researchers, and the AI community at large to hear about and discuss the latest trends and research in data-centric AI. If you registered for the event but didn't see all the sessions you wanted, you can now catch up. The recorded sessions are available for registrants at the same Zoom portal as the live sessions.

Team Snorkel