Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
LLMs high priority for enterprise data science, but concerns remain
Enterprises—especially the world’s largest—are excited to use large language models, but they want to fine-tune them on proprietary data. This presents a challenge, as high-quality labeled training data remains the primary blocker of machine learning projects—at least according to poll data collected from The Future of Data-Centric AI 2023 attendees.
Snorkel AI recently hosted a two-day conference where experts from Fortune 500 enterprises, AI providers, and ML researchers along with thousands of data scientists discussed challenges, opportunities, and solutions to adopt LLMs for enterprise use.
During the conference, hundreds of attendees gave their insight into the current state of enterprise AI by responding to a set of polls. We’ve broken the poll respondents into two groups: those who we know to work at for for-profit companies with a known value of $1 billion or more, and those who don’t. We examine some of the results below.
75% of respondents expect to adapt LLMs using data
More than half of our attendees indicated that they expected their organization to use fine-tuning with prompts and responses to improve the performance of large language models. This approach was less popular among our attendees from the wealthiest of corporations, who expressed similar levels of interest in fine-tuning with prompts and responses, fine-tuning with unstructured data, and prompt engineering.
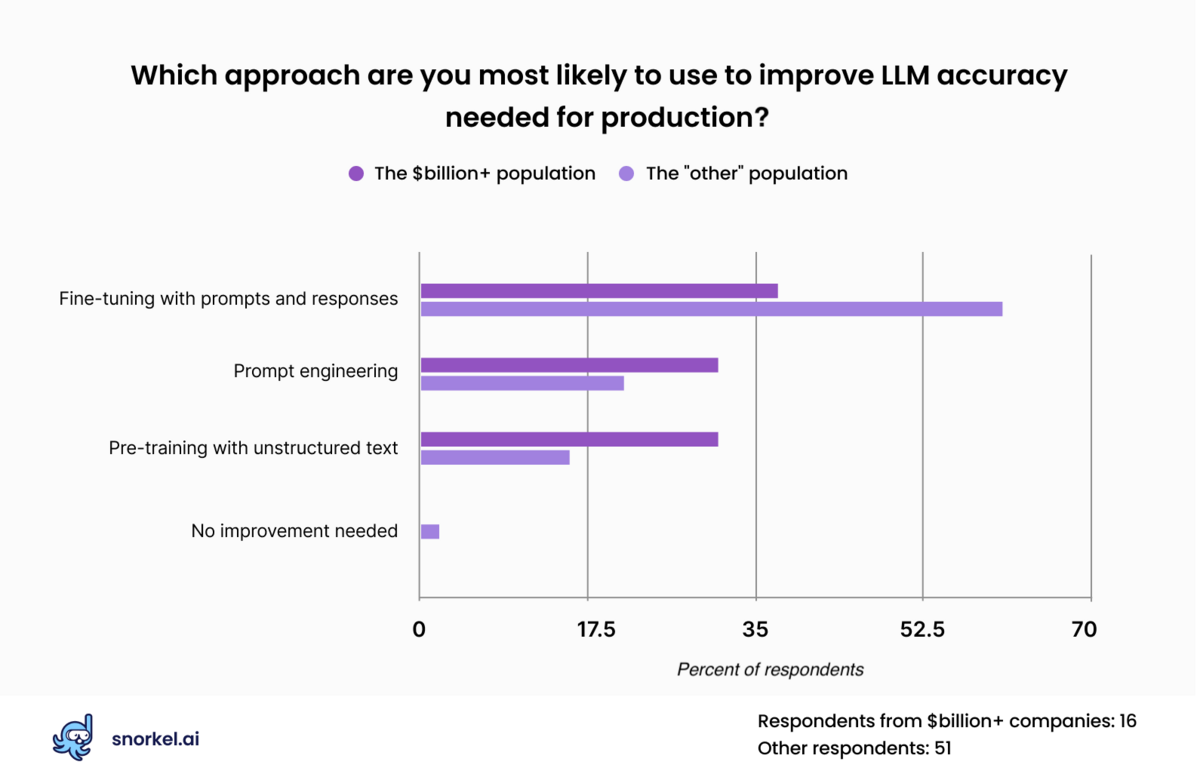
Fine-tuning with prompts and responses adjusts the performance of large language models by feeding the model inputs in the form of prompts and comparing its output to responses deemed appropriate to those prompts. This practice adjusts the weights in the underlying model and yields more useful performance from LLMs.
But this approach requires labeled data—and a fair amount of it. Documentation from OpenAI recommends that users supply 100 examples per class to instruction-tune its models for classification tasks. That’s a multiplier that quickly adds up for complex enterprise applications with 10-100s of classes.
Labeled data remains biggest blocker
More than a quarter of respondents said that the lack of high-quality labeled data presented the biggest blocker for enterprise AI projects. That made it the most frequently-cited challenge for those who answered our polls—and by a wide margin.
That challenge is likely to remain, even as data science teams shift their focus from traditional model architectures to foundation models and large language models.
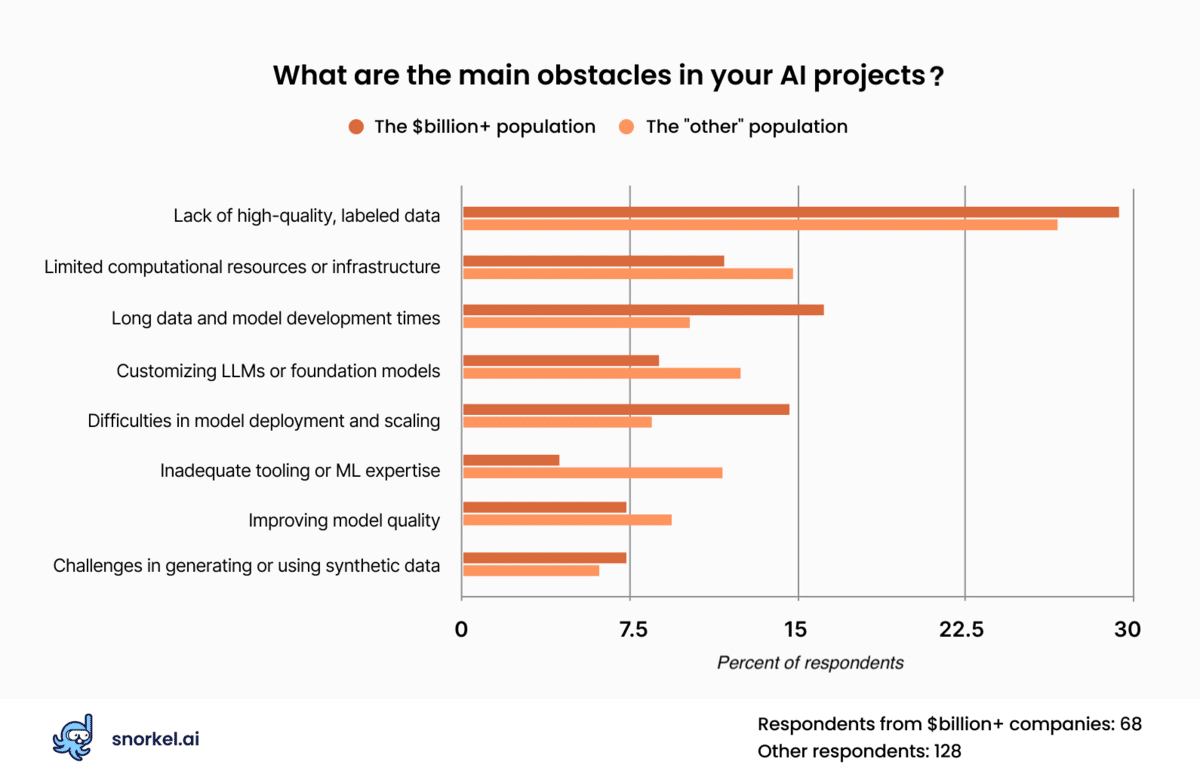
As indicated in the previous section, a majority of our respondents—and all of the respondents from companies worth at least a billion dollars—believe that off-the-shelf LLMs won’t be up to their enterprise-specific tasks and will require fine-tuning or pre-training. While fine-tuning an LLM may require labeling fewer records than might be called for by a traditional model, such as a neural network or XGBoost, their impact is far higher. Any error introduced into an organization’s custom LLM would persist into all applications downstream from it.
After data struggles, our poll respondents indicated that their other top AI obstacles are lack of computational infrastructure or resources, long data and model development times, customizing LLMs or foundation models, and difficulties in model deployment and scaling.
Responses from large corporation attendees roughly tracked or topline findings, with two exceptions. Respondents from companies with billion-dollar-plus valuations were nearly twice as likely to be concerned about model deployment and scaling, and roughly a third as concerned about ML tooling or experience.
Organizations are eager to use LLMs
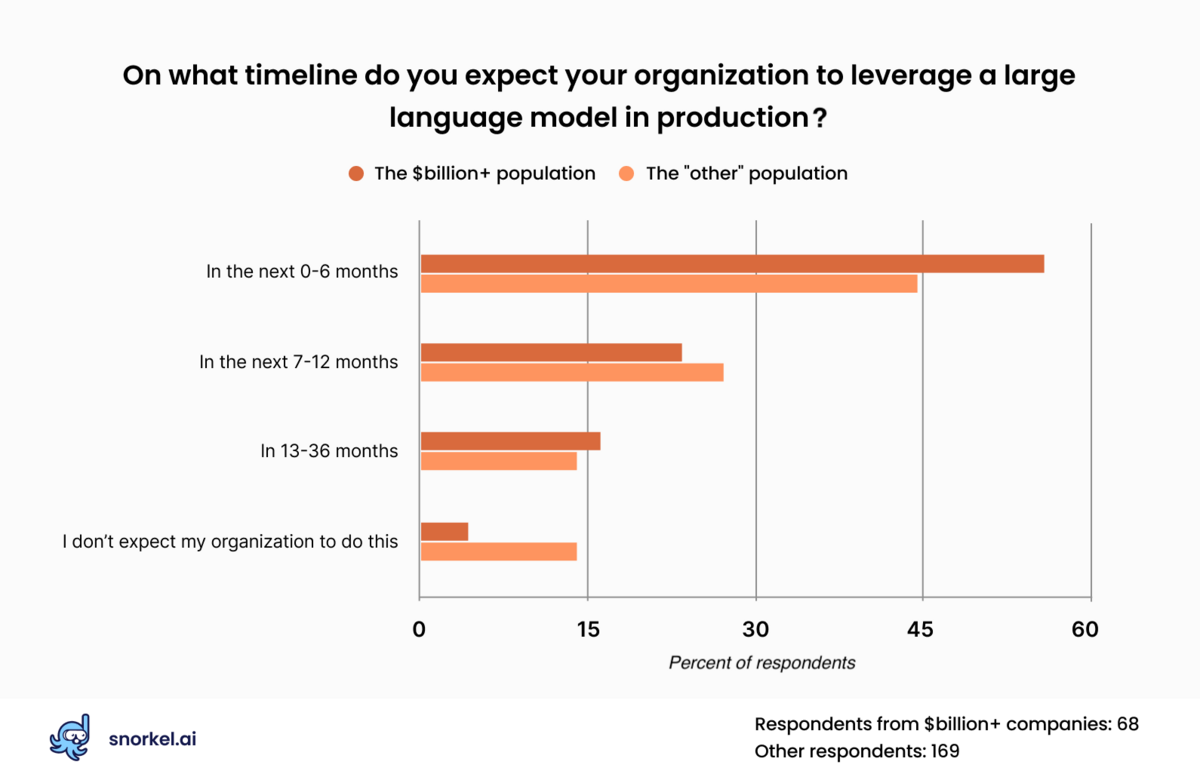
Nearly half of our respondents—and more than half of large company respondents—said they expect to leverage a large language model in production in the next six months. Another quarter said they expected to do so in seven months to a year.
But the big takeaway is this: only 11% of respondents said they didn’t expect their organization to use foundation models. This means that 89% of respondents do expect their organization to use foundation models at some point in the foreseeable future. That result was sharper among respondents from billion-dollar-plus corporations: only three out of 68 expected that their organization would not use LLMs.
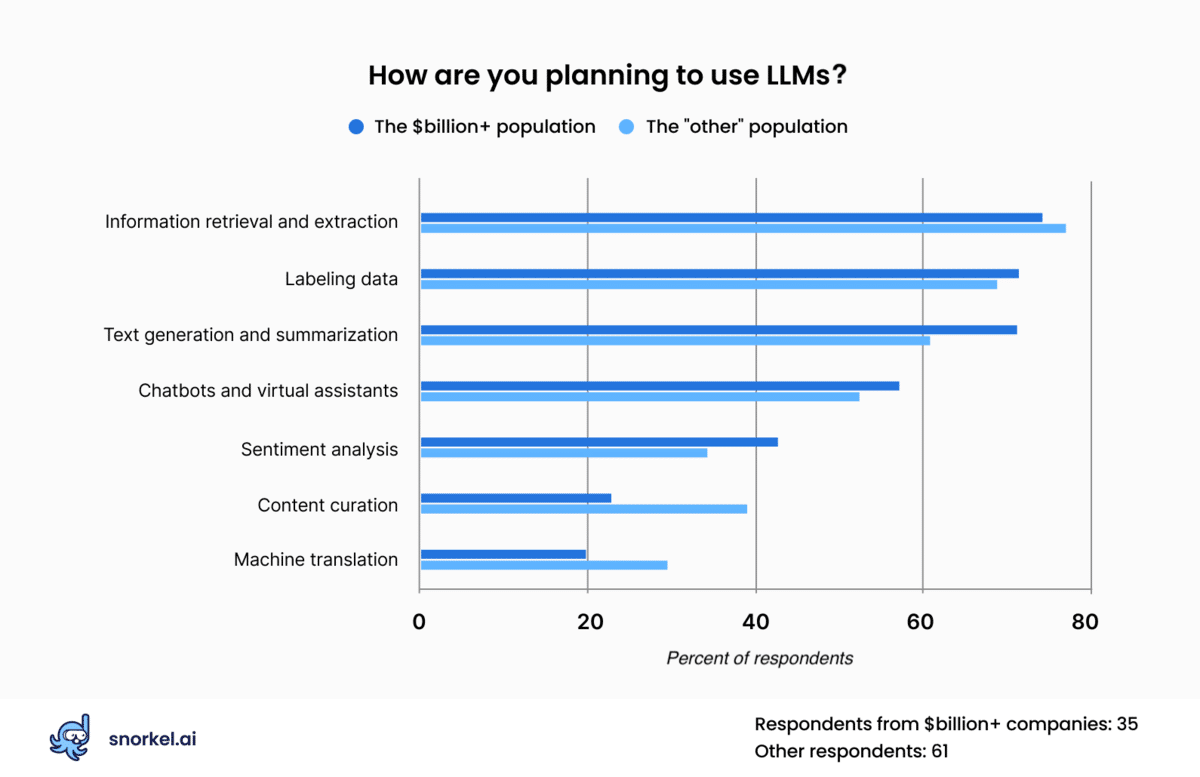
Top applications: extraction, labeling, and text generation
We asked conference attendees how they expected to use LLMs in their business. Among respondents, information retrieval and extraction, labeling data, and text generation topped their lists.
For reference, “information extraction” tasks use LLMs to isolate information from a document, such as finding the writer of an article or the company referenced in a financial filing. “Labeling data” is when data scientists use an LLM to apply a categorical label to a document, such as categorizing an article as business or sports. “Text generation” tasks create text that teams can modify and use in various places, such as on their website, in emails, or on social media posts.
This poll differed from others, in that we allowed respondents to select multiple applications instead of just one.
An interesting note on their responses: machine translation—the task that the entire field of natural language processing began with—ranked last.
Cloud deployments and LLM concerns
Rounding out our Future of Data-Centric AI survey, we asked attendees about issues that may make them hesitant to use large language models in production, and how they plan to host AI applications.
The largest group of respondents (38%) said they planned to deploy their machine learning tools in some combination of cloud and on-premise environments over the next twelve months. Almost half of the respondents said they expected their organization to deploy machine learning applications exclusively through cloud deployments, with public cloud resources like AWS, Google Cloud Platform, and Microsoft Azure narrowly beating out private cloud options.
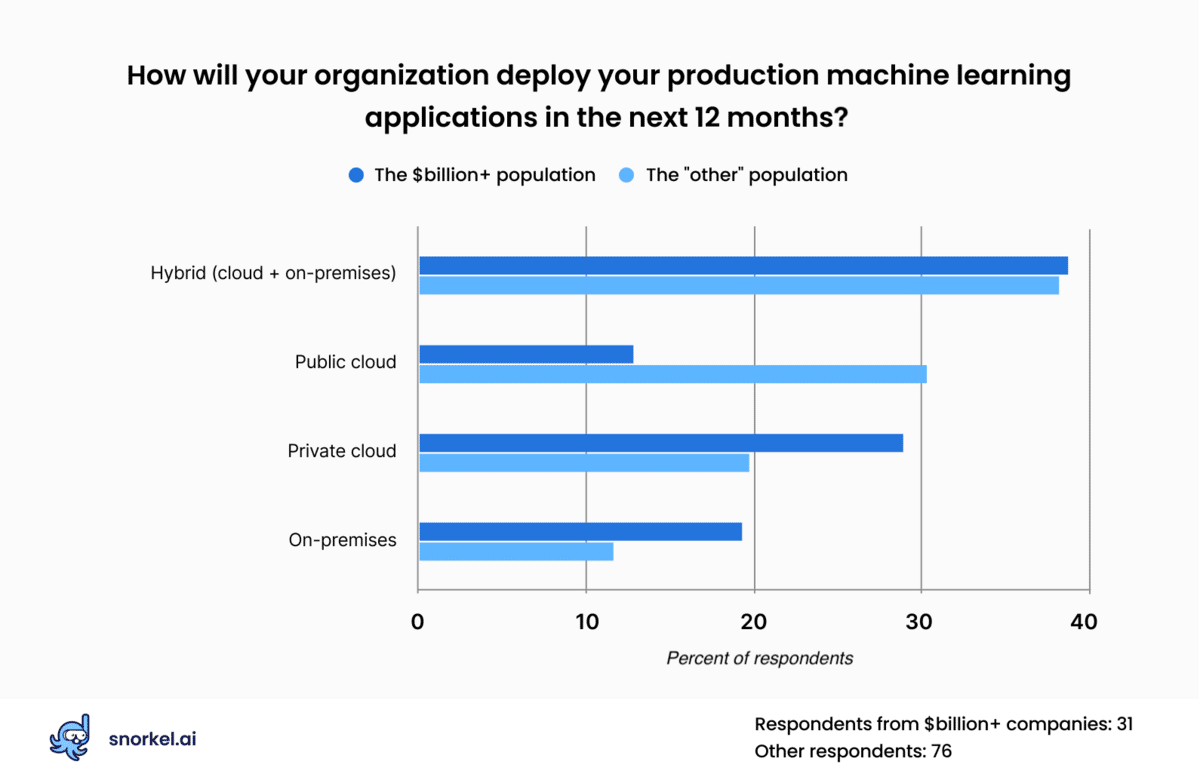
Respondents from the largest companies in our audience were much more likely to prefer on-premises on private cloud deployments, with just 13% saying they preferred public cloud options.
Our poll found concerns about governance as practitioners’ biggest challenge in leveraging LLMs, followed closely by the cost to adapt deploy or use the models and concerns about quality or accuracy.
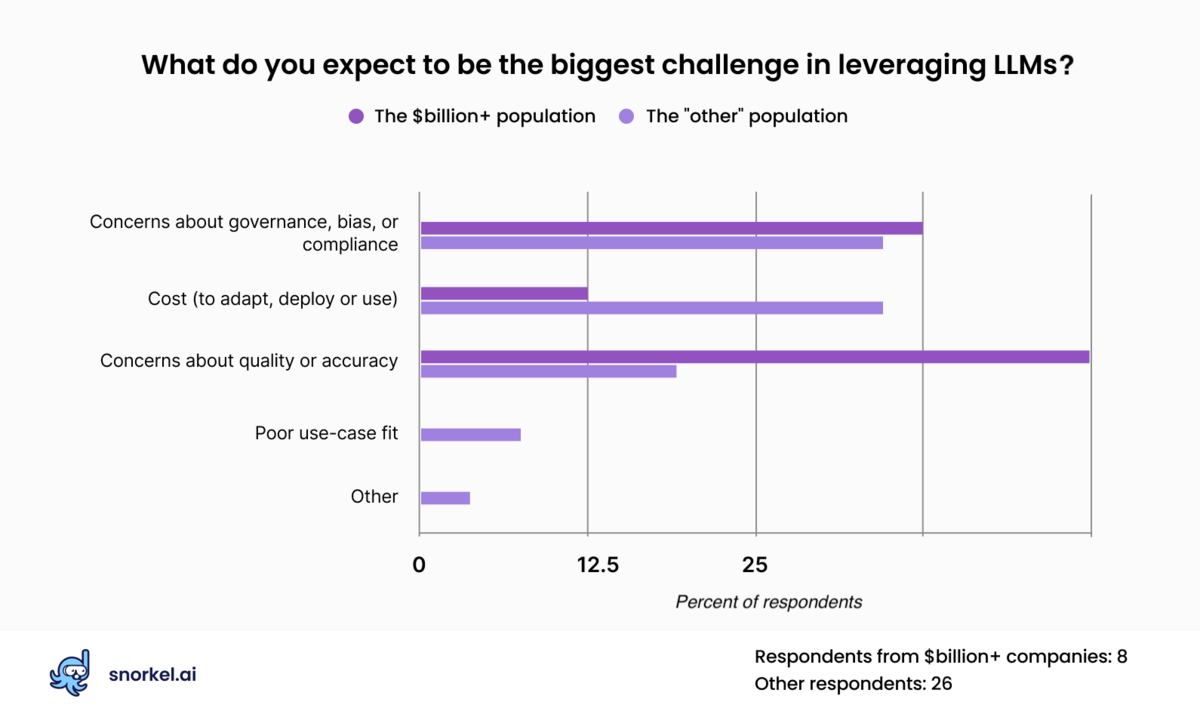
Among our respondents from companies with billion-dollar valuations, they placed concerns about accuracy above all others. Due to the low response rate on this question, these figures are not robust. But it is noteworthy that this is a significant shift from a similar poll we ran in January when respondents were most concerned about accuracy and quality.
Conclusion
Large language models have reshaped the machine learning space quickly, and continue to do so. The skepticism we saw around LLMs immediately after ChatGPT’s debut has given way to enthusiasm or inevitability.
With nearly 90 percent of our respondents predicting that their organization will use large language models, the question has turned from whether to use them to how to use them, and what’s in the way. The biggest blocker, it seems, continues to be labeled data.
Catch the sessions you missed!
The Future of Data-Centric AI 2023, our two-day free virtual conference, brought together thousands of data scientists, AI/ML practitioners, researchers, and the AI community at large to hear about and discuss the latest trends and research in data-centric AI. If you registered for the event but didn't see all the sessions you wanted, you can now catch up. The recorded sessions are available for registrants at the same Zoom portal as the live sessions.

Matt Casey
Matt Casey leads content production at Snorkel AI. In prior roles, Matt built machine learning models and data pipelines as a data scientist. As a journalist, he produced written and audio content for outlets including The Boston Globe and NPR affiliates.