Continuous Model Feedback, available in beta as part of the new Studio experience, is Snorkel Flow’s latest capabilities to make training data creation and model development more integrated, automated, and guided.
The new features make it radically faster to train a model and get near-instant feedback. The rich set of analysis tools and guidance you receive as you label programmatically equip you to iterate strategically to improve your data quality (and model performance) and get to production faster.
In this post, we’ll:
- Describe the challenges machine learning teams face as they work to improve data quality
- Show how Snorkel Flow’s data-centric workflow for AI development is the solution to these challenges
- Introduce Continuous Model Feedback, our most recent innovation, to provide integrated model analysis and guidance as you develop your training data.
Current-state data quality challenges
Across research and experience with our customers, we’ve observed a persistent flaw of traditional AI development: the silo between training data creation (done by in-house subject matter experts or outsourced to annotators) and model training (performed by the data science and machine learning teams). In addition to creating a massive bottleneck for AI development, these silos make it difficult to achieve training data quality goals for two reasons.
First, improving data inherently requires iteration, but iterating is extremely difficult when the labeling process is siloed and manual, making collaboration inefficient. Data science teams have to wrestle through cumbersome back-and-forths with busy domain experts and annotators who are at an arm’s length from the overall model development process.

Next, even if inefficient iteration weren’t a pervasive problem, most teams lack timely insight into data quality (or lack thereof) during the labeling process. They’re flying blind about what changes to the training data will correct (or cause) model errors and therefore don’t know what to focus on or solve for as they iterate. Given the cost and effort to iterate when labeling manually across silos, not knowing the best use of iteration effort is a painful blind spot.
Break down silos with Snorkel Flow
These challenges (among others) were our original motivation to unify training data and model development into a data-centric AI workflow with Snorkel Flow. In doing so, the platform dramatically improves collaboration between data science and subject matter experts and maximizes the flywheel of improving data to improve model performance.
With traditional AI approaches that treat data as a precursor to the “real” development process, you often collect labels without knowing if they address your model’s needs. Once you begin model development, you likely rely largely on model-centric levers to improve performance, given the pain points described above—lack of insight into data quality and the pure difficulty of data iteration. You spend time tuning hyperparameters and hoping you’ll find a better local optimum.
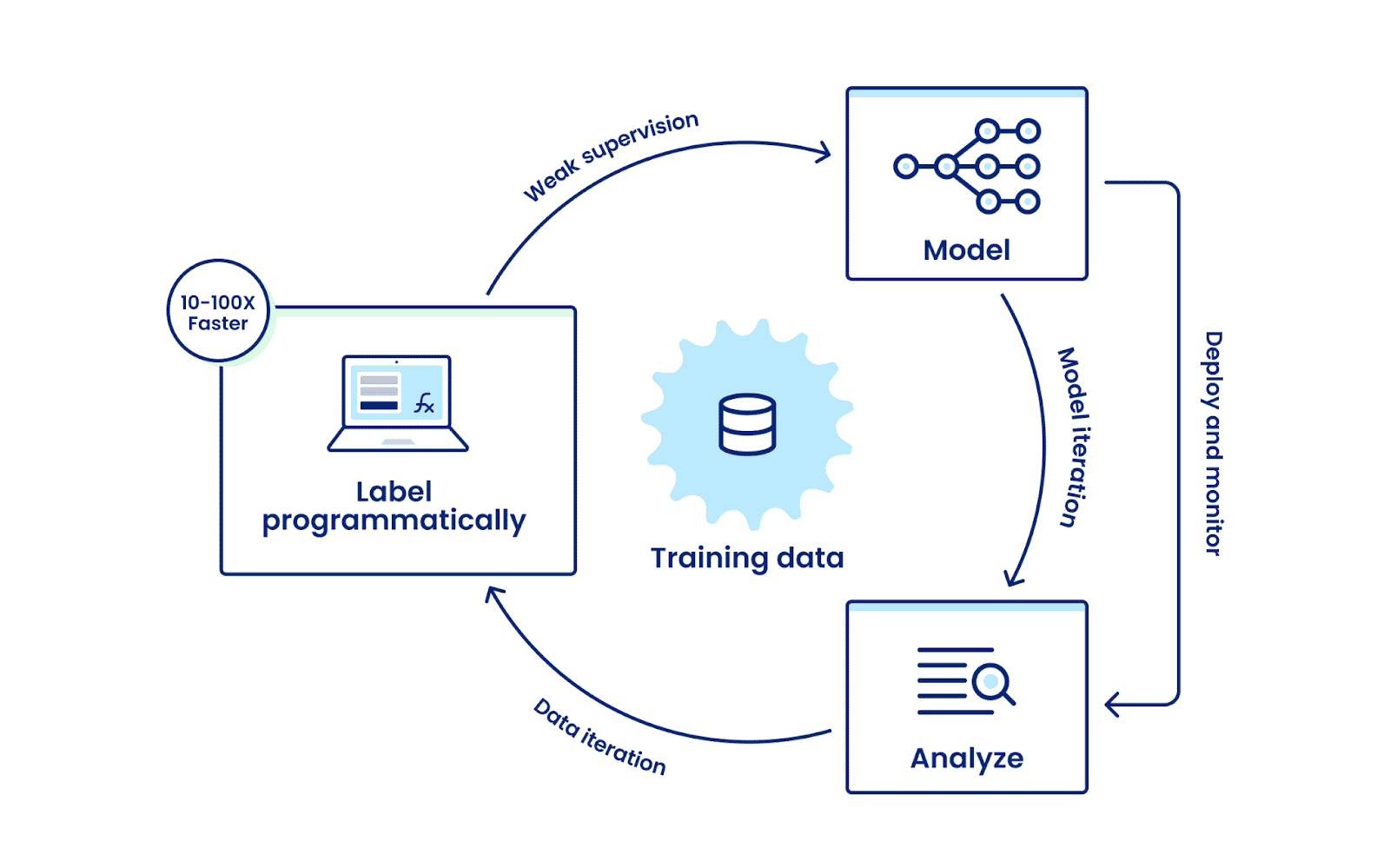
There’s a better way. In Snorkel Flow, the data-centric AI workflow reflects and supports the reality that training data creation is an inherently iterative process. First, programmatic labeling, the core technology Snorkel AI pioneered, dramatically scales and speeds labeling, whether for initial creation or ongoing iteration to solve edge cases or reflect label schema changes.
Next, for programmatic labeling to be maximally impactful, you need feedback on the quality of your labeled data from a model during development. Without this model in the loop, you won’t know where your data is driving model errors or where you have gaps in training data required to teach your model to do what it needs.
Snorkel Flow embeds automated, real-time model training and analysis throughout the data labeling process, giving you explicit insight and guidance to improve the training data and the model in tandem. You’re taken directly to the source of problems so you can troubleshoot over specific slices of the data.
Is this different from Active Learning?
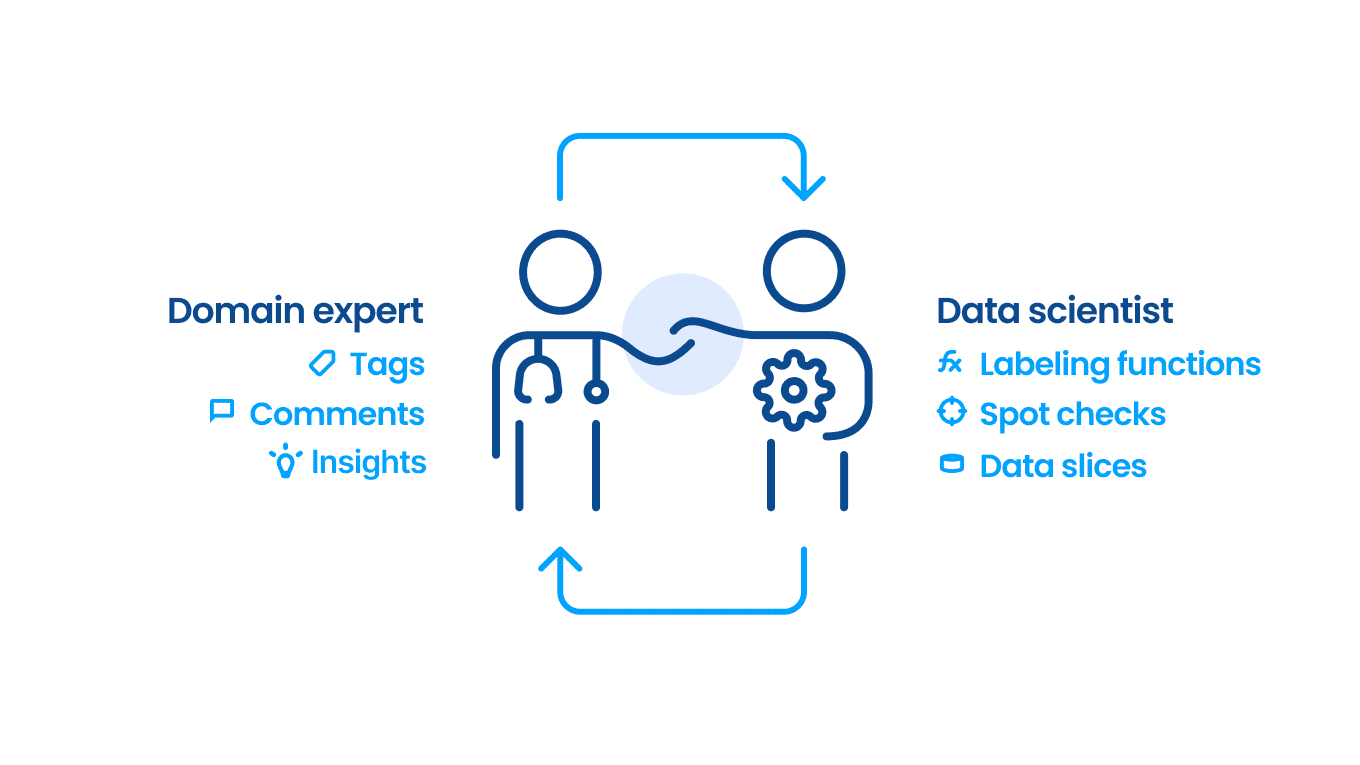
Snorkel Flow offers Active Learning, the standard technique of guiding annotators to label slices of data that are estimated to be of higher value to the model, and makes it more powerful by pairing it with programmatic labeling.
Beyond suggesting what data point to label next, each automatically trained model comes with multiple analyses providing insights like strengths and weaknesses of the current model, whole groups of data points where the model is conflicted or uncertain, recommendations on what actions to take next to improve the model further, and more.
Critically, acting on this guidance with Snorkel Flow is practical and efficient because you’re labeling programmatically. The image below shows that analysis from the model highlights a need for more training data for a particular class. The user can click to view this slice of data and create a new labeling function (using the UI or Python code) that will label many examples like the ones in that error bucket.
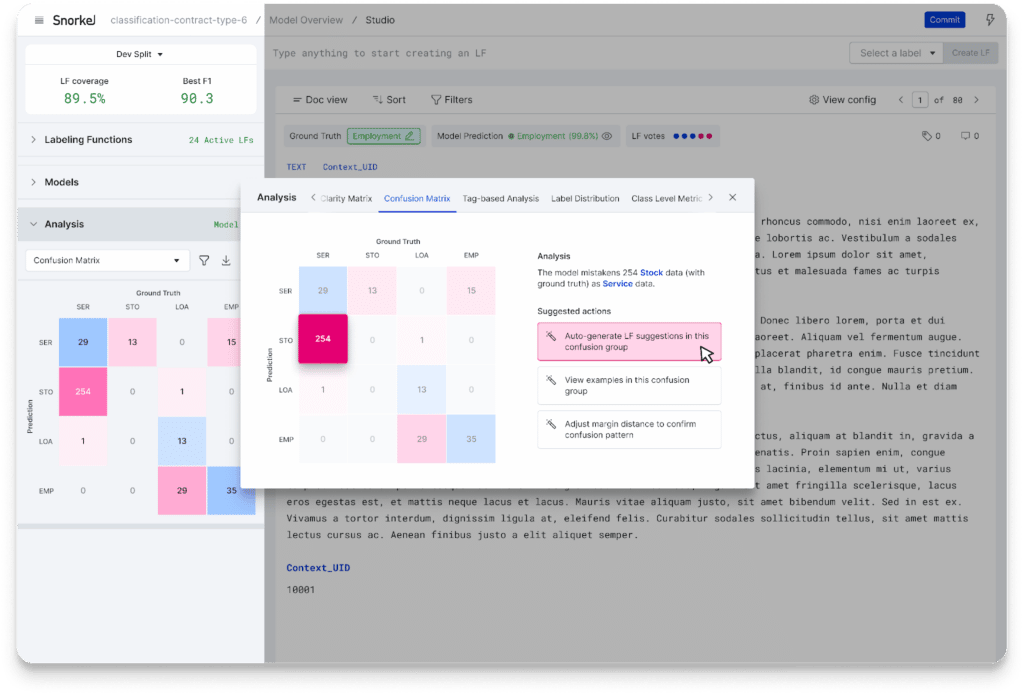
This combination of programmatic labeling and integrated, model-guided error analysis allows you to rapidly improve your data quality to reach model performance goals and get to production faster.
Introducing Continuous Model Feedback
With the new Continuous Model Feedback, we’ve made model-guided error analysis more streamlined and faster than ever. Models are now trained automatically to allow for nearly real-time feedback as you label programmatically, making data-centric AI more guided, assistive, and faster for our customers. Here’s a peek into two ways this innovation benefits your AI development.
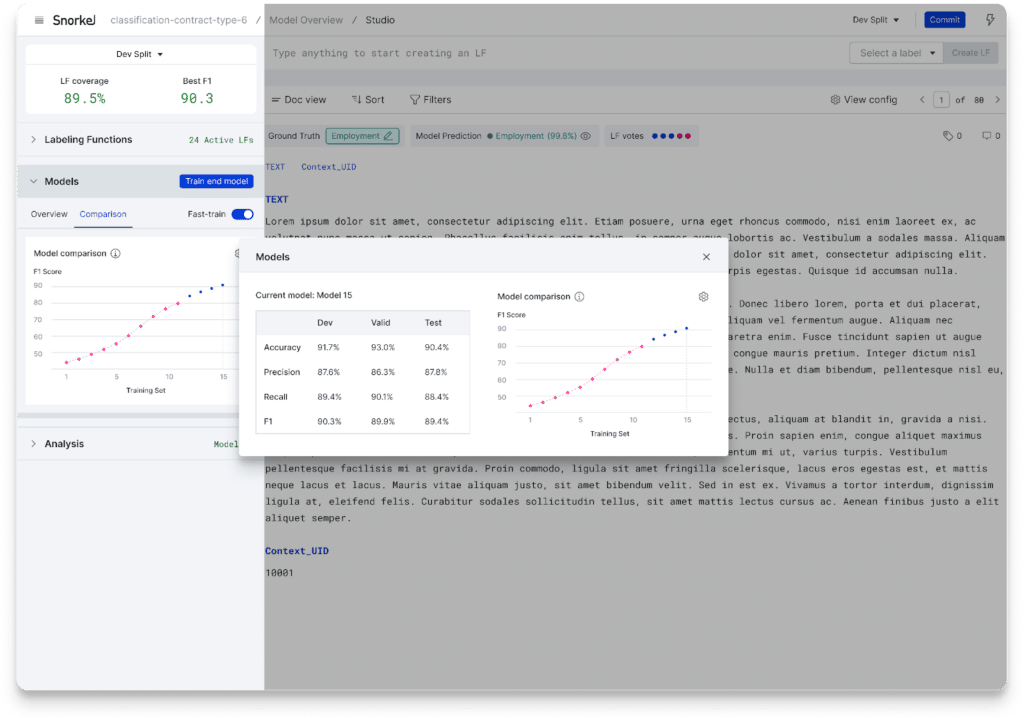
Fast-train model feedback
Model-based error analysis requires training a model, which can take time. Given how important iteration and experimentation are in AI development, we now offer “fast-train,” which provides automated, real-time quality feedback from a simpler but faster model as you create labeling functions. Once you reach the desired quality benchmark, you can train an end model on your entire data set to increase generalization and model performance.
Persistent pulse on progress
As you work in Snorkel Flow to create labeling functions, train models, and iterate, you always have a clear view of your progress and how each action you take impacts results. This means you’re never left wondering if you’re headed in the right direction or if you’ve reached your training data quality and model performance goals.
Improve your data quality with Continuous Model Feedback
Modern, data-centric practices are key to improving data quality and accelerating AI development. The Snorkel Flow platform provides concrete capabilities and streamlined, unified workflows to get the most from data-centric AI.
Schedule a demo with our team today to see how you can speed AI delivery with data-centric AI.
