Snorkel has worked with hundreds of customers on predictive classification problems. We’ve learned a lot about the practical challenges and opportunities that enterprises face every day with advanced classification tasks. When done right, ML-driven classification cultivates significant business value and automation, unlocks new business lines, and reduces costs.
Earlier this year, I presented a talk titled “Tackling Advanced Classification Using Snorkel Flow” at Snorkel AI’s The Future of Data-Centric AI conference. We summarized our main points here.
Building enterprise-grade AI: use a data-centric approach
AI rarely works out of the box for enterprise applications. Like an employee, models need to be trained and/or adapted to your business and domain area to solve meaningful problems and minimize the risk of incorrect outputs.
Traditionally, data science teams have iterated on models with hyper-parameter tuning or prompting—what we call “model-centric” development. This falls short in the age of foundation models (FMs) and large language models (LLMs).
We’ve found the only viable way to build and adapt generic FMs or LLMs for your domain is via the training data. This is the labeling, prompting, and integration of knowledge sources to develop, curate, and shape datasets and make them useful for downstream model development. We call this “data-centric” AI.

Challenges and opportunities: task definition, getting to your first model, and long-tail iteration
Having a flexible way to iterate on your schema is critical. Being stuck with a rigid schema often leads to thrash later in the model development lifecycle. Teams also often become blocked by manual labeling—sometimes called a “cold start” problem. Even after training an initial model, teams struggle with model-centric iteration, an inefficient “whack-a-mole” process to drive down errors on rare but critical data slices.
To minimize these challenges, Snorkel’s users employ a data-centric approach to significantly accelerate each step of their process.
The challenge of formulating your task definition
Defining a label schema is one of the most common challenges we see when working with customers. Some enterprises choose to inherit from existing ontology, while others build a new custom schema. The former can lead to ambiguity, while the latter can create too much complexity. Both can produce unclear distinctions between classes.

In the image above, you can see on the left that categorical “overlap” is sometimes intentional. For example, a long video can include air travel, beach travel, and cruises. This scenario, where more than one label can apply, is called a multi-label classification.
The overlap can also be unintentional—the result of confusion, organizational/technical debt, or changes over time. In addition to ambiguity, many high-impact enterprise problems are very high in cardinality, involving hundreds to thousands of classes. This multiplies the challenges resulting from ambiguous label schemas.
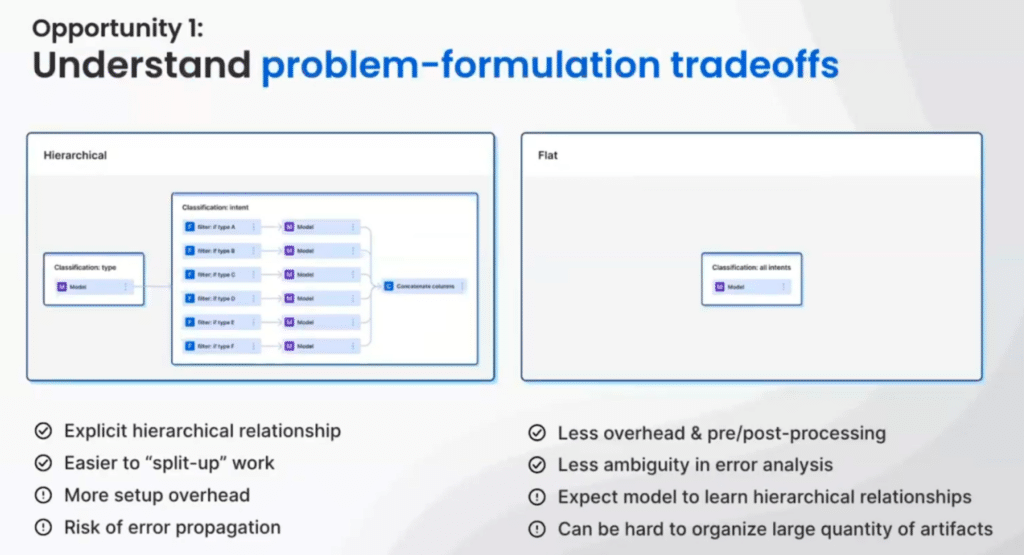
Two approaches to structuring your advanced classification schema
There are two primary methods for structuring the problem––one is hierarchical, the other is flat.
The hierarchical setting uses multiple models. Each performs a subset of classifications. For instance, you can first classify documents by type. Then, depending on the type, you can classify a smaller set of intents specifically for that document type. You can subsequently build an explicit hierarchical relationship from the start, which simplifies the division of work through compartmentalization. The downside to this approach is greater setup overhead and risk for error propagation.
The “flat” approach eases setup and reduces ambiguity throughout error analysis. Without a built-in hierarchy, we expect the model to learn any inherent hierarchical relationships through the training data. However, in a high-cardinality scenario, it can become difficult to organize large quantities of artifacts.
There’s no right or wrong choice. The way a business decomposes its problem will often dictate the right approach.

Schema iteration
Once you have formulated the problem, you need to plan for some amount of schema iteration. It’s often hard to define the final schema until you explore the data and adjust accordingly. This creates an opportunity to use the data to drive the schema iteration process.
Snorkel Flow offers several tools for this. You can assess ground-truth data, for example, by asking whether the data set includes differing labels on similar documents or even on the same spans—a correctable error. You can also measure the conflict between manual data annotators by tracing their annotations back directly to the source. Then, you can see the result of a correction interactively.
Finally, Snorkel Flow allows users to establish the schema definition programmatically, which supports an iterative data-centric approach. Changing the label for a given example or modifying the schema programmatically enables traceability—especially when splitting or combining labels.
Data scientists may need to adjust the schema definition further throughout development. Data-centric approaches are crucial for enabling the flexibility to do so.
The path to your first model
Many enterprises rely on manual labeling for model development. For complex enterprise use cases, this often involves hand-labeling tens of thousands to millions of examples. This can stop many enterprise AI projects before they start.
Outsourcing this onerous task is risky. It creates privacy and auditability concerns, and potential poor label quality since outsourcing firms rarely have the expertise required for domain-specific problems. On the other hand, In-house subject-matter experts also come with high opportunity costs; labeling data takes them away from their primary responsibilities.

Snorkel Flow enables you to use existing resources to programmatically “warm start” the process. You can leverage internal domain experts or an existing ontology, or you can build with off-the-shelf resources using prompts and embeddings. Snorkel Flow’s programmatic labeling process quickly and effectively combines all of these resources.
Let’s dive deeper to see what this looks like.
Snorkel Flow warm start
The example below uses a standard ontology for diseases. For a given diagnosis, you can pull keywords from the disease definition and turn them into ontology-based labeling functions (LFs).
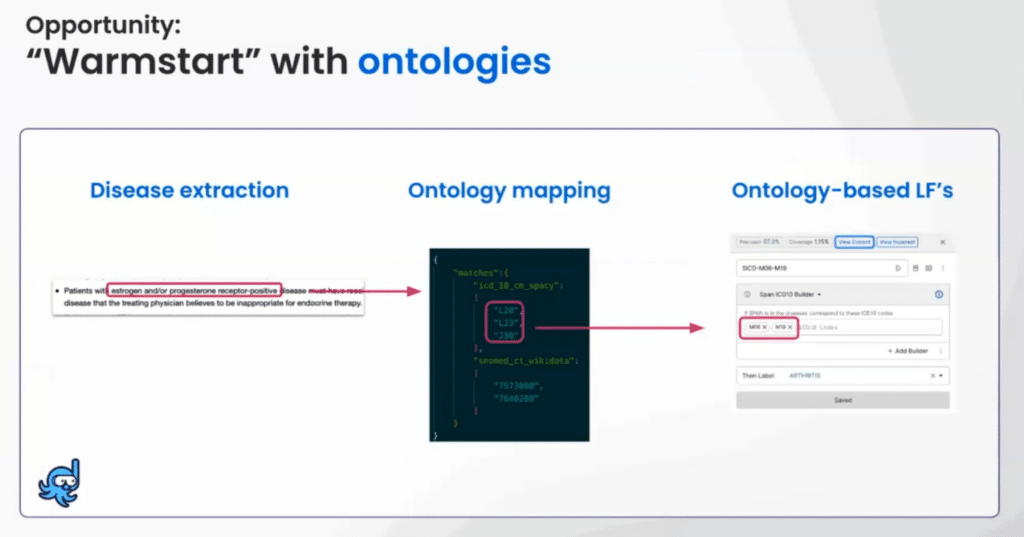
In many cases, companies already have a legacy system that can be easily plugged into Snorkel Flow by turning it into LFs.
In addition, recent advances in FMs and LLMs present exciting new opportunities. Snorkel Flow makes iterating with FMs straightforward; you can perform zero-shot or few-shot learning with just a few clicks.
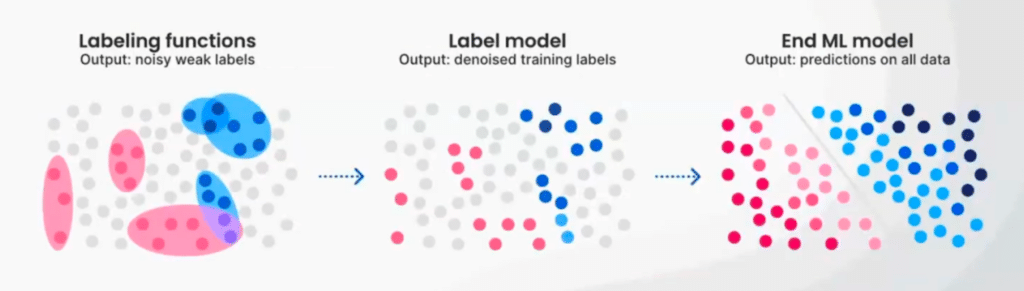
Signals from existing resources can be noisy, but Snorkel’s programmatic labeling pipeline combines sometimes-conflicting sources of signal to create high-quality training labels. Our users then use these labels to train an end model, which will generalize beyond any of the information users provide explicitly.
Long-tail iteration
Long-tail performance is critical. Errors on rare slices of data can have significant business consequences—NSFW tags on social platforms, for example. Additionally, these data slices change with world events and business needs over time.

How do organizations address this in practice? Many organizations pursue model-centric iteration, such as hyper-parameter tuning and prompt engineering. This might net a few extra performance points, but ad hoc approaches rarely achieve consistent long-tail performance.
In contrast, the idea behind data-centric iteration is simple. Examine your data. Focus on error hotspots, and programmatically drive down errors while using human supervision. The resulting iteration loop helps systematically raise performance and reduce errors.
A key aspect of data-centric iteration is programmatic labeling. Using heuristics, rules, models, existing ontologies, and knowledge from subject-matter experts, you streamline the training data development process. As previously mentioned, many existing resources may be noisy. However, Snorkel’s approach integrates these noisy sources of information. In practice, this leads to radically faster ML development.
Another critical step in data-centric iteration is guided error analysis, which eliminates the guesswork associated with model-centric development. Snorkel Flow has several features that make this process effortless, including fast model-guided feedback to identify errors, active learning or model-assisted learning to suggest data slices that need attention, and tag-based analysis. All of these features help support an effective human-in-the-loop workflow, whereby a machine suggests slices of data or specific data points to focus on to improve downstream performance.
Case study: advanced classification of videos
Now let’s look at a case study inspired by a real customer experience to illustrate all of this.
This data company wants an AI application to classify videos. Before Snorkel, they manually labeled videos into more than 600 categories. After working with Snorkel and using Snorkel Flow, the company produced high-quality, deployable models with over 90% accuracy in weeks.
During task formulation, the customer wanted to use an existing taxonomy for categorizing and labeling videos. Very quickly, the customer embraced the intentional overlap of classes that is often seen with existing taxonomies, and decided on a multi-label schema format.
While they could have used a hierarchical setup for their modeling environment, they chose a flat schema for several reasons. They had a relatively small team and wanted to reduce the setup and management overhead to start labeling and testing immediately.
The customer then looked into organizational resources to help them warm start across the 600 or so classes. They didn’t have ground-truth labels, but they utilized zero-shot learning to jumpstart the creation of their first training data. Subsequently, they used prompt builders powered by various foundation models to correct errors from an out-of-the-box result.
During long-tail iteration, the customer leveraged embeddings, keyword labeling functions, and LLM-assisted labeling techniques. Additionally, to resolve conflicts between ambiguous classes during error analysis, the customer used tools that Snorkel Flow provides that do not require ground truth (e.g. keyword conflict analysis, margin distance, etc…).
Advanced classification will never be easy, but it can be easier
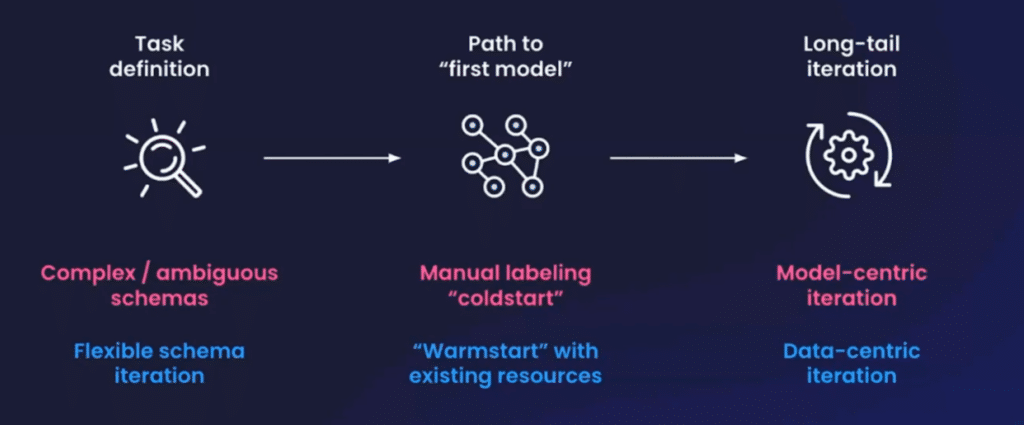
As we showed in our case study, enterprises interested in advanced classification tasks need to strongly consider three things:
- Task definition: Complex and ambiguous schemas can create big problems downstream if you’re not thoughtful about tradeoffs. After you begin, Snorkel Flow can help detect errors and iteratively define your schema over time.
- The path to the first model: Enterprises can become blocked by a manual-labeling cold-start problem. With Snorkel Flow, you can use programmatic labeling and existing resources to warm start your labeling process and expedite the time to your first model.
- Long-tail iteration: Snorkel Flow systematizes error analysis with data-centric methods. Examine your data, identify slices of errors, and correct them with additional supervision, driving robust models in production.
With Snorkel Flow and some thoughtful planning, your team can get from data to model faster than ever before.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.
Angela Fox, AI/ML product designer at Snorkel AI, cowrote and co-presented the presentation we derived this article from.
