Join our inaugural Reading Group in San Francisco on April 29. Register now
Google’s Dr. Arsanjani on Enterprise Foundation Model Promise and Challenges
Dr. Ali Arsanjani, director of cloud partner engineering at Google Cloud, presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Below follows a transcript of his talk, lightly edited for readability.
Hope you can all hear me well. I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone.
Today we’re going to be talking essentially about how responsible generative-AI-model adoption can happen at the enterprise level, and what are some of the promises and compromises we face. We’re going to look at a very quick rendition of the evolution of LLMs (large language models) and foundation models, take a look at LLMs at Google, and then look at enterprise applications. What are the promises? What are the challenges and compromises? Then we’re going to talk about adapting foundation models for the enterprise and how that affects the ML lifecycle, and what we need to potentially add to the lifecycle.

The foundation of large language models started quite some time ago. And essentially what led to foundation models (large language models being a subset of foundation models) and the whole generative AI “movement,” was basically taking a vast amount of training data, specifically textual data—and of course there are multi modalities in the other generative AI capabilities and models—and training them as a basis for other models. So there’s obviously an evolution. It came to its own with the creation of the transformer architecture: Google’s BERT, OpenAI, GPT2 and then 3, LaMDA for conversation, Mina and Sparrow from Google DeepMind.
Really quickly, LLMs can do many things. One is, obviously, the most popular these days, which is to act as a conversational agent—to create human-like dialogue and maintain conversational context. We can have code generation in the same mechanism, write code with a natural language description and start modifying that code, translating code from one language to another.
It can do reasoning, extractive question answering, common sense reasoning, joke interpretation, multi-step arithmetic, and essentially using standard prompting and chain of thought prompting.
There’s some degree of conceptual understanding that can be awarded to large language models. They can distinguish cause and effect, and then combinations of various appropriate contexts.

As we look at the progression, we see that these state-of-the-art NLP models are getting larger and larger over time. The largest one, the Pathways language model, is 540 billion parameters. These are obviously not just focused on one task. They’re focused on many, many downstream tasks and activities, and the capabilities they have stem from the fact that they are leveraging some pathway within the neural network, not the entire neural network necessarily.
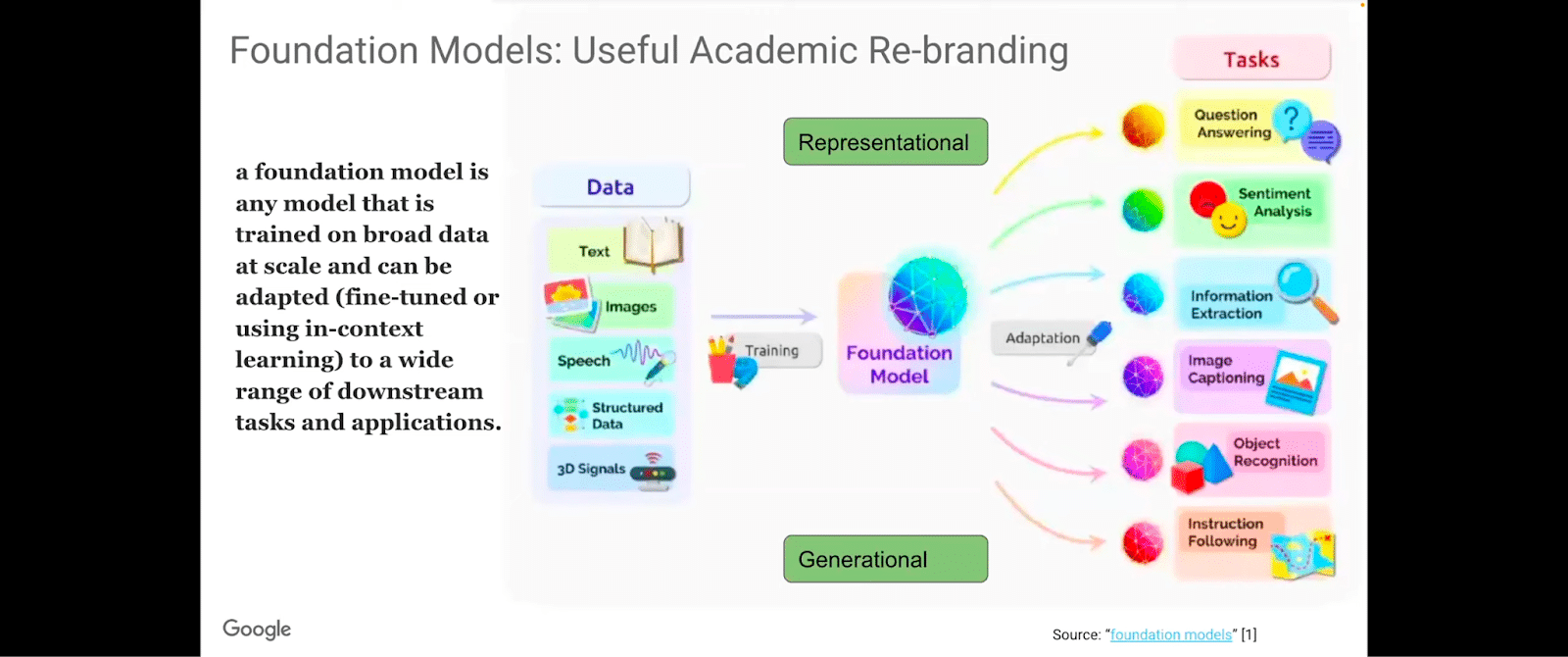
A significant amount of researchers at Stanford and other places got together and built this paper—what we’re just going to refer to as the foundation model paper. This was effectively an academic rebranding of what initially was these large language models and then different modalities came into being. The fact that they have to be fine-tuned with in-context learning and adapted to a wide stream of downstream tasks and applications caused this movement to be very appropriate at its time.
There are basically two ways of looking at it: representational and generational viewpoints in foundational models, that approach the problem of how do we build foundation models, such as language models.
The representation viewpoint looks at it from the input text and input data perspective, where you have a pre-training of a large dataset of unannotated text. From the generation viewpoint, you have a large dataset of annotated text. In the representation view, you can fine-tune on specific tasks to improve performance, and you can also do that in the generation view. Obviously, the generation model is good at generating texts. It’s similar to the input, but it may not be able to learn general representations of the data, and to capture the underlying patterns and infrastructure in the data. Whereas the representation view is very good at learning representations of the data, the underlying patterns, structure, and capabilities, but may not be able to generate texts. And there are mechanisms in terms of combining these approaches.
This foundation model paper explored these opportunities and risks of foundation models, where you take a small lightweight LLM, trained on a diverse set of tasks in an unsupervised fashion, and we discussed the effectiveness here of the foundation model as a starting point for fine-tuning on downstream tasks.
This paper is about 200 pages, so there’s a lot to read. If you’re interested in looking, it’s more encyclopedic. It’s not necessarily one cohesive read. You can look at it in “angles”.
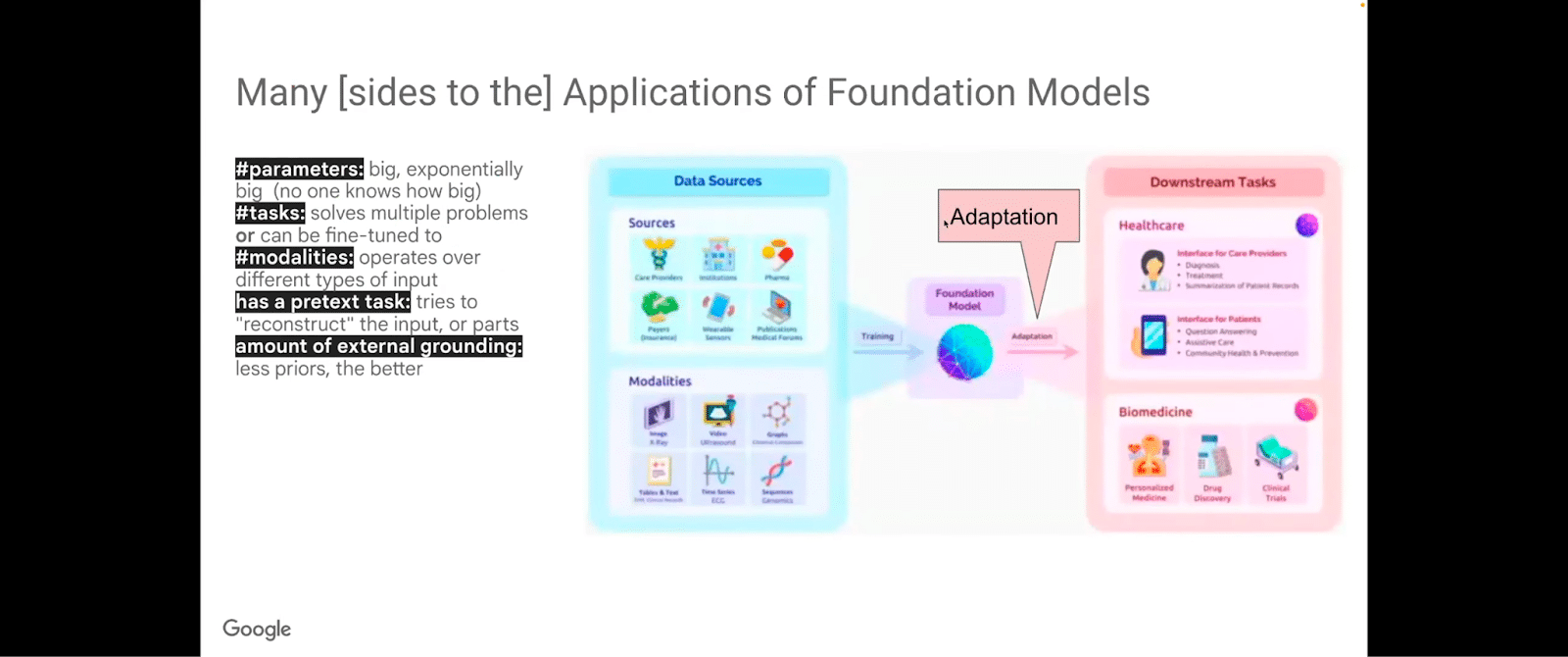
One of the angles from which we’re going to look at it today is this adaptation for enterprise implementation of LLMs and foundation models.
Of course, foundation models have various, if you will, “degrees of freedom,” or hyperparameters, almost. These are the parameters of the model. They are exponentially big, different tasks, different modalities, and basically have a pretext task to reconstruct the input or parts of the input. And there is an amount of external guiding that occurs.
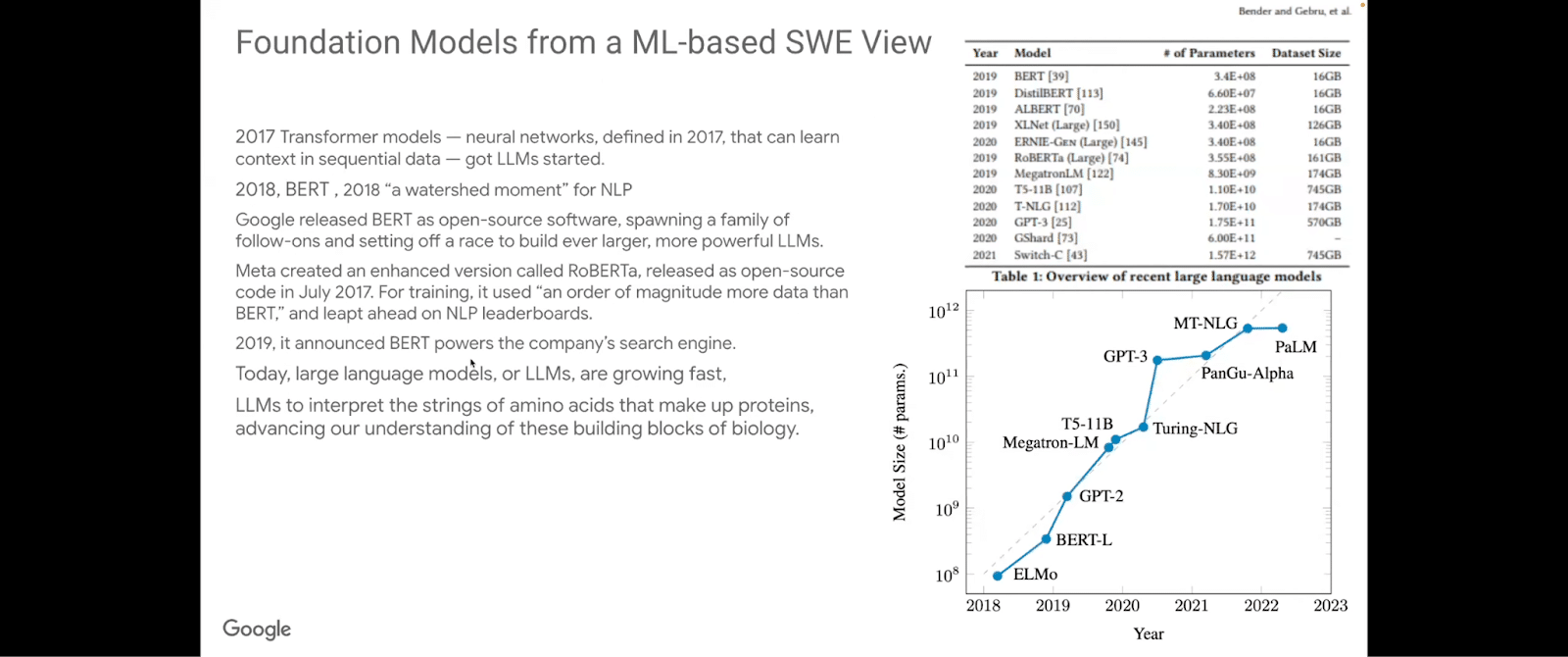
From a software engineering perspective, machine-learning models, if you look at it in terms of the number of parameters and in terms of size, started out from the transformer models. Gradually, as folks adopted the transformer model and various architectures of the encoder-decoder architecture, they started growing these language models and making them applicable to very specific areas, such as interpreting strings of amino acids—like an alpha fold that make up proteins and help us advance our understanding of the basic building blocks of biology, just to name one very specific example. So the application started to go from the pure software-engineering/machine-learning domain to industry and the sciences, essentially.

Looking at the capabilities of all these different large language models (and there are a significant number of them). Billions of parameters. Very large core pie, and very efficient in certain sets of things. Some of them are more geared and tuned toward actual question answering, or a chatbot kind of interaction. Others, toward language completion and further downstream tasks.
One interesting observation is that there’s the Gopher one from DeepMind, and Chinchilla, which was a much, much smaller version of Gopher, but it demonstrated that even a much smaller, distilled model can work as well, or almost as well, if the right parameters are chosen and the right paths are chosen through that model.
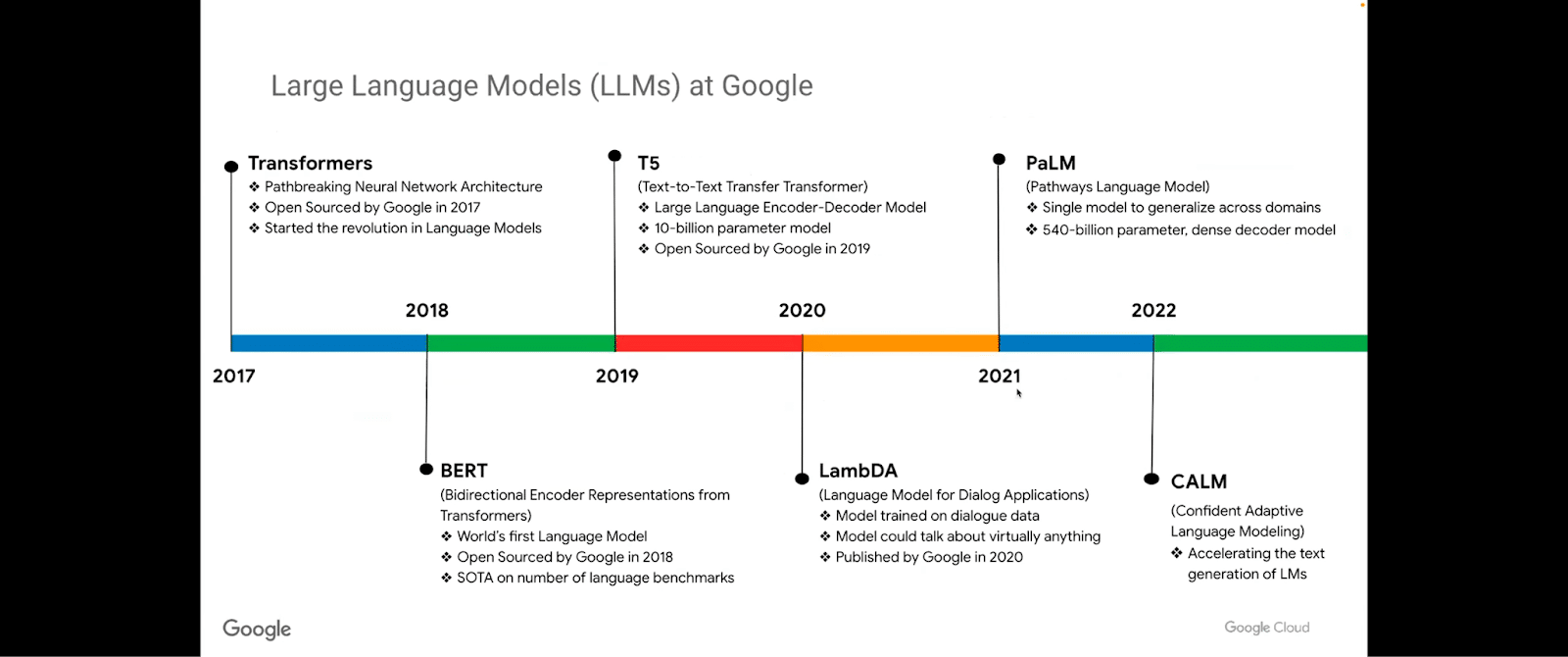
Within Google, we can see the progression of large language models starting from the Transformers, BERT, and then the T5 model, LaMDA, which is the language model for dialogue-based applications. There are various offshoots of that—Mina and Minerva, et cetera. And then the Pathways language models (PaLM). And, lately the Confident Adaptive Language Models (CALM), which is a version of PaLM.
I’ve provided you with some links here–you can check them out later—on what these Google dialogue-based (very focused on dialogue) LLMs can do, which ones are kind of state-of-the-art. One of the latest ones is Sparrow, which is in the paper: “Improving alignment of dialogue agents via targeted human judgements.”

Sparrow is basically an open-domain dialogue agent that’s trained to be more helpful, more correct, and more harmless. It does so through three things. It employs reinforcement learning from human feedback (RLHF). It actually provides evidence of the claims it makes. And there are a set of rules that it abides by.
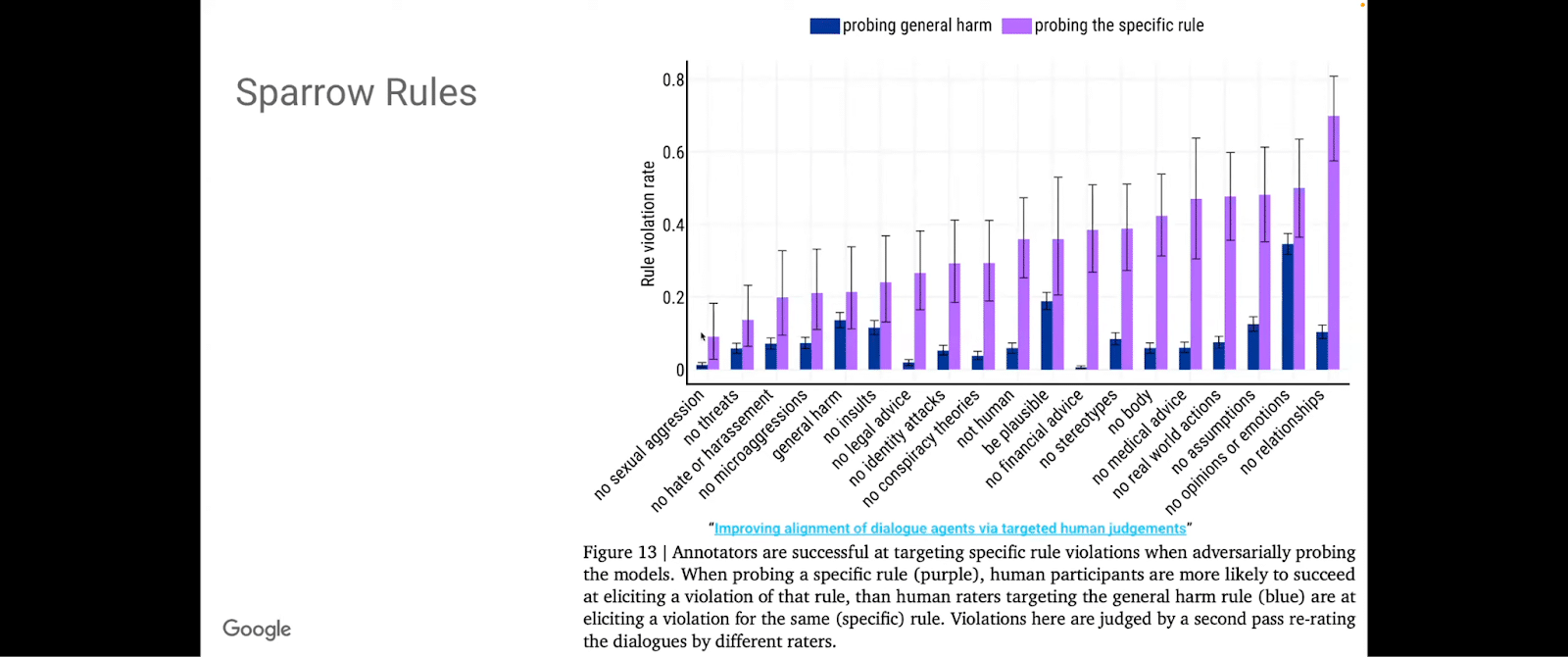
Some of these rules, if you look in the paper, are outlined here. Humans were asked: “how did this response violate which of these rules?” The humans, in a reinforcement-learning-based approach, provided feedback on this. This set of rules makes this kind of dialogue agent less harmful. And, essentially looking at all these things: no threats, no harassment, no microaggressions, no general harm, no insults, no legal advice, no identity attacks, et cetera, et cetera, et cetera.
These are elements that gradually make it safer and safer for us to think about enterprise applications, what the promises are, what the challenges are, and what the compromises are.
There are definitely compelling economic reasons for us to enter into this realm. Now, the suitability of these models for widespread deployment is yet somewhat uncertain, even though models are out there today, and it’s important to be very cautious and establish some professional norms for responsible research and deployment.
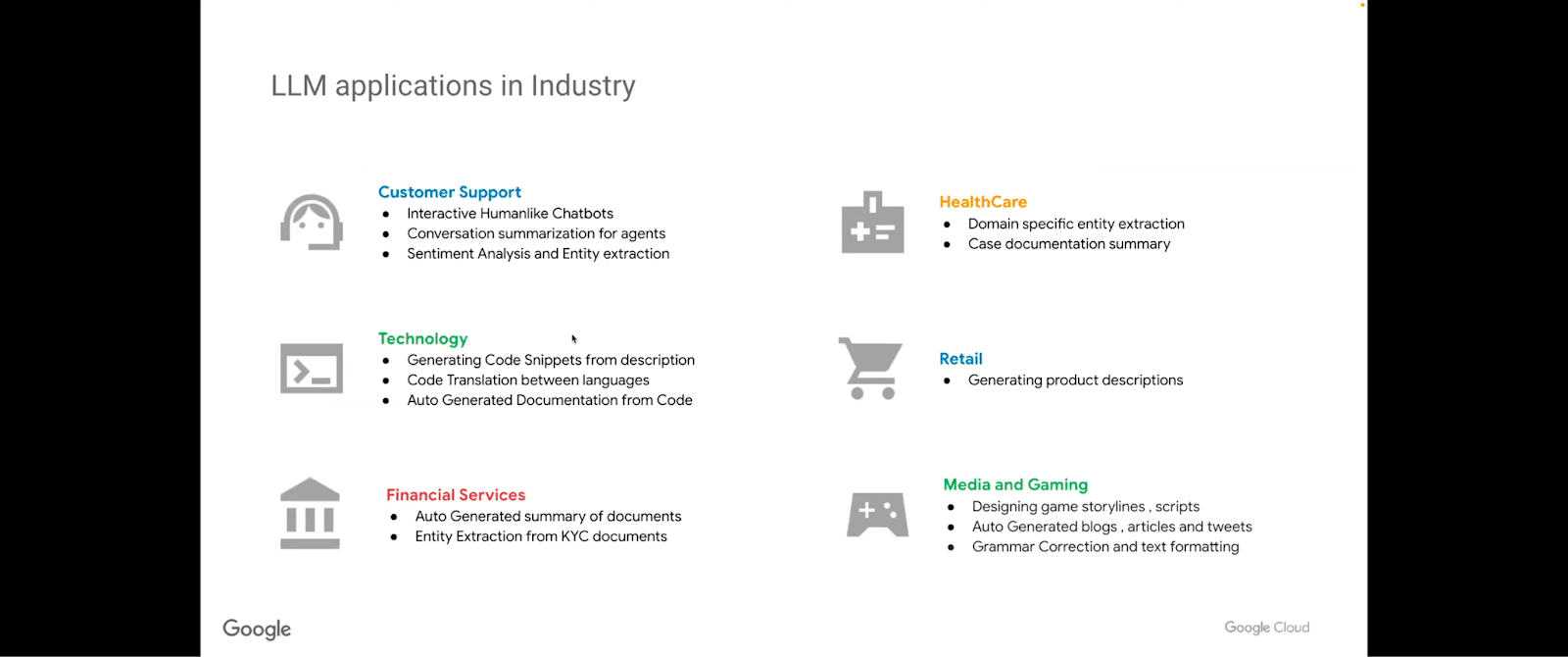
With that, there are some elements of LLMs in the industry that can be applied, such as for customer support. The natural chatbot conversational agent, our contact center comes to mind. In terms of technology: generating code snippets, code translation, and automated documentation. In financial services: summary of financial documents, entity extraction. In healthcare: various domain-specific entity extraction, case summarization. And of course, there are specialized models like Alpha Fold, which actually get into genetics and protein binding, et cetera. In retail: generating product descriptions and recommendations and customer churn and these types of things. In media and gaming: designing game storylines, scripts, auto-generated blogs, articles and tweets, and grammar corrections and text formatting.
There are potential risks associated with each one of these in each of the domains, even though there’s a use case. For example, I’ll just take a look at one of them. Large language models can be used to analyze medical records and extract relevant information like a diagnosis or treatment plan, but accuracy is important so that it can cite information of why it made that diagnosis or why the treatment plan is recommended. These types of risks are mitigated by language models that actually provide those types of further adaptation than just the generation of a cohesive answer.
I’m not going to go through every single application in healthcare, finance, retail, manufacturing, and education. These are obviously areas that we can look at. There are areas in collaborative application, like in your word processor, in your spreadsheets, et cetera, in your contact centers, even inside your Jupyter Notebooks. All areas where positives and negatives reside.
But, in order to actually adapt the foundation model or generative AI process into the enterprise, we need to look at what changes or potential additions we may need to make.
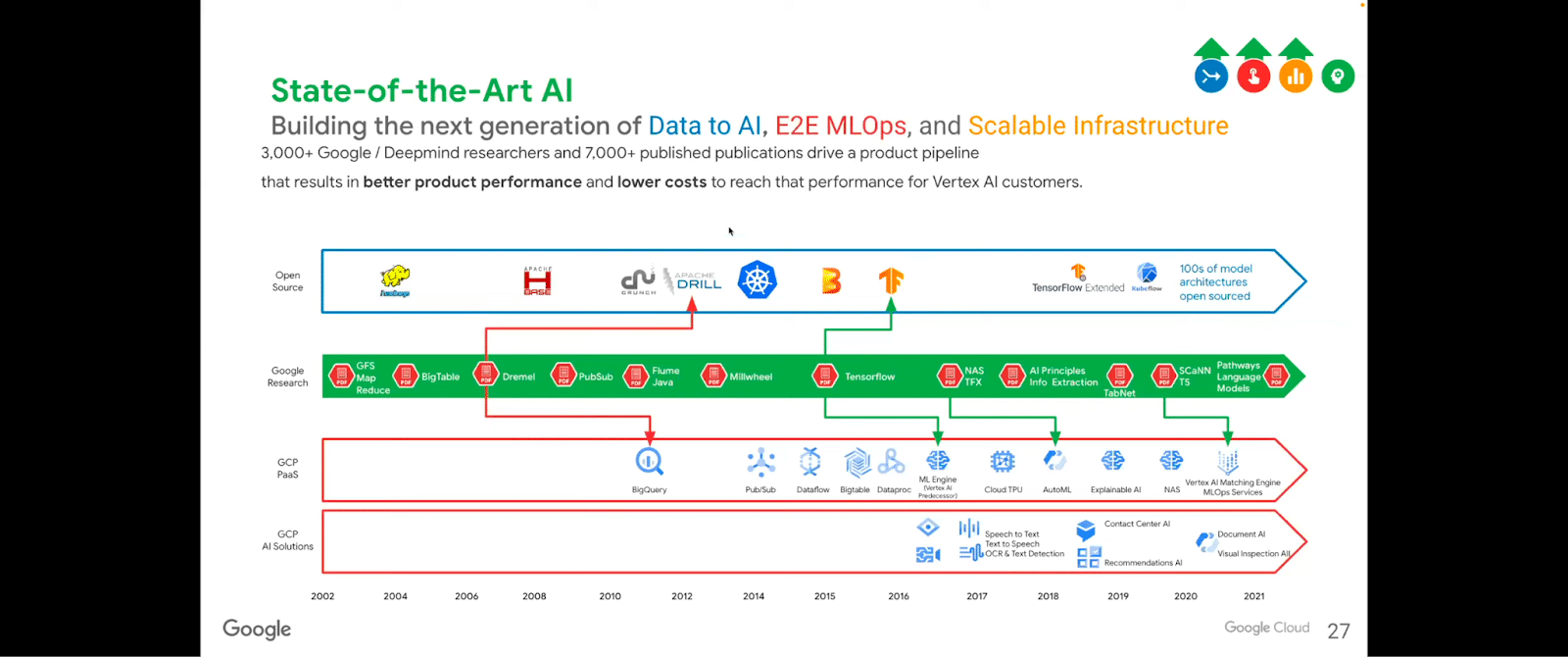
Here, we’re just going to look a very quick second at a lot of the open-source kinds of things that have been happening, specifically focusing on what Google has open-sourced and produced and provided a scalable infrastructure to run these things on.
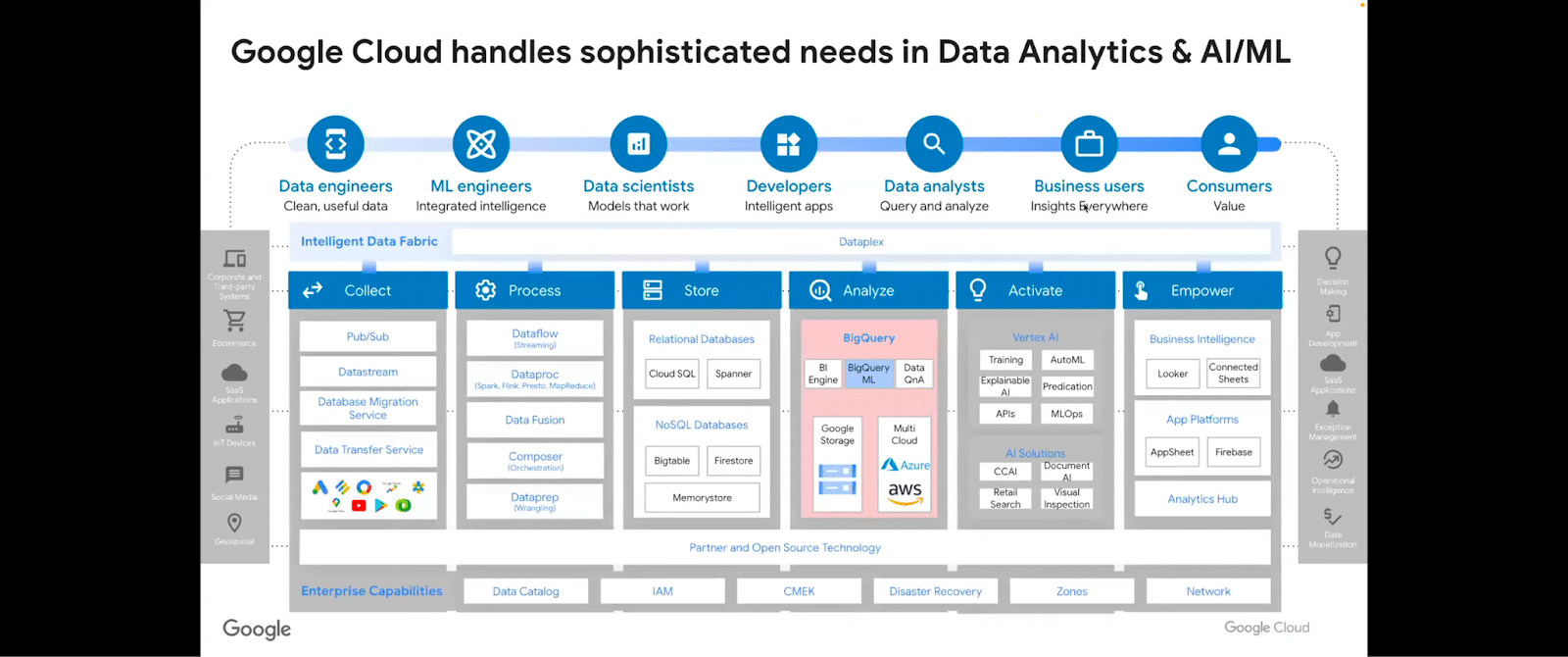
And of course, Google Cloud provides the scalable infrastructure for us to run our workloads, whether we’re doing large language models and foundation model building or fine-tuning. It can cover the gamut.
There are a number of traditional machine learning activities across the lifecycle that we do. Data preparation, train and tune, deploy and monitor.
But: these are not going to be adequate for supporting generative AI. So this very typical model needs to change.
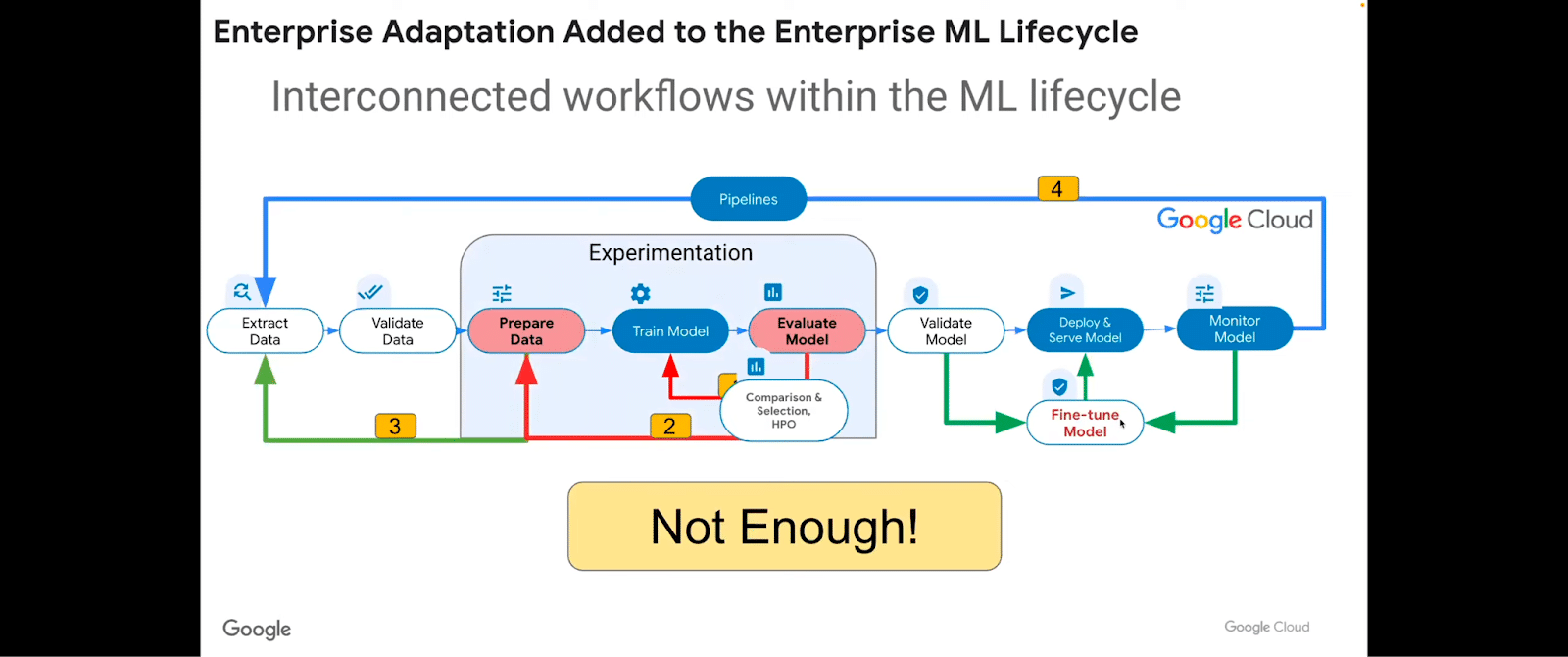
The way it changes is not just through adding a fine-tuning step toward the end here. That’s not enough.
But rather to make sure that we’re aware that just fine-tuning and performing transfer learning in the era of large language models may not necessarily be adequate, whichever of these types of models we’re using.
The adaptation has to come into account along with the fine-tuning. In the adaptation, you’re creating a new model based on an existing foundation model, yes. You’re fine tuning in some shape or form. Maybe you’re prompt tuning, et cetera. But it involves additional modules, custom rules, evidence, and classifiers of the model, as well as combining it with other complimentary signals. We’re going to explore what these signals are in the context of enterprise deployment. Adaptation is very, very important for identifying and mitigating the potential harms that can be caused by problematic models.
If you distill it down, some of these “laws” or recommendations for foundation model enterprise adoption:
Adaptation very specifically needs to take into account more than fine tuning. It needs to take into account adaptation drift. So you’ve adapted the model and now it’s supposedly safe, but over time, does it remain safe? Similar to when you train a model, it has a certain degree of, let’s say, an F1 score or accuracy or what. Over time you monitor its drift. And in the same way, you need to monitor adaptation drift and add that to the ML lifecycle. The responsible AI measures pertaining to safety and misuse and robustness are elements that need to be additionally taken into consideration.
Number two is the model transparency and reproducibility. Yes, everybody publishes model sheets, hopefully more and more, but the training context, the background, the training scenarios used, the usage scenarios, the toxicity, polarization, misinformation—all these factors pertaining to the model and whether they have been tested on the model needs to also be incorporated in the model sheets. This goes into the model risk management in analyzing the metadata around the model, whether it’s fit for purpose with automated or human-in-the-loop capabilities.
Let’s take a look at what the breakdown is. We have data pipelines and data preparation. We have adaptation, we have experimentation, and in the training and hyperparameter optimization phases, deploying, monitoring and managing, and prompt engineering.
Okay, let’s spread out these cards here and get into a little bit more detail.
So each of them may require some repositories from a data lake house/analytics hub kind of thing for sharing data, to a feature store, to a model hub, to the responsible AI (known sets of things that you need to guard against), to a model registry. A database of prompt examples may need to be required for each of these phases.
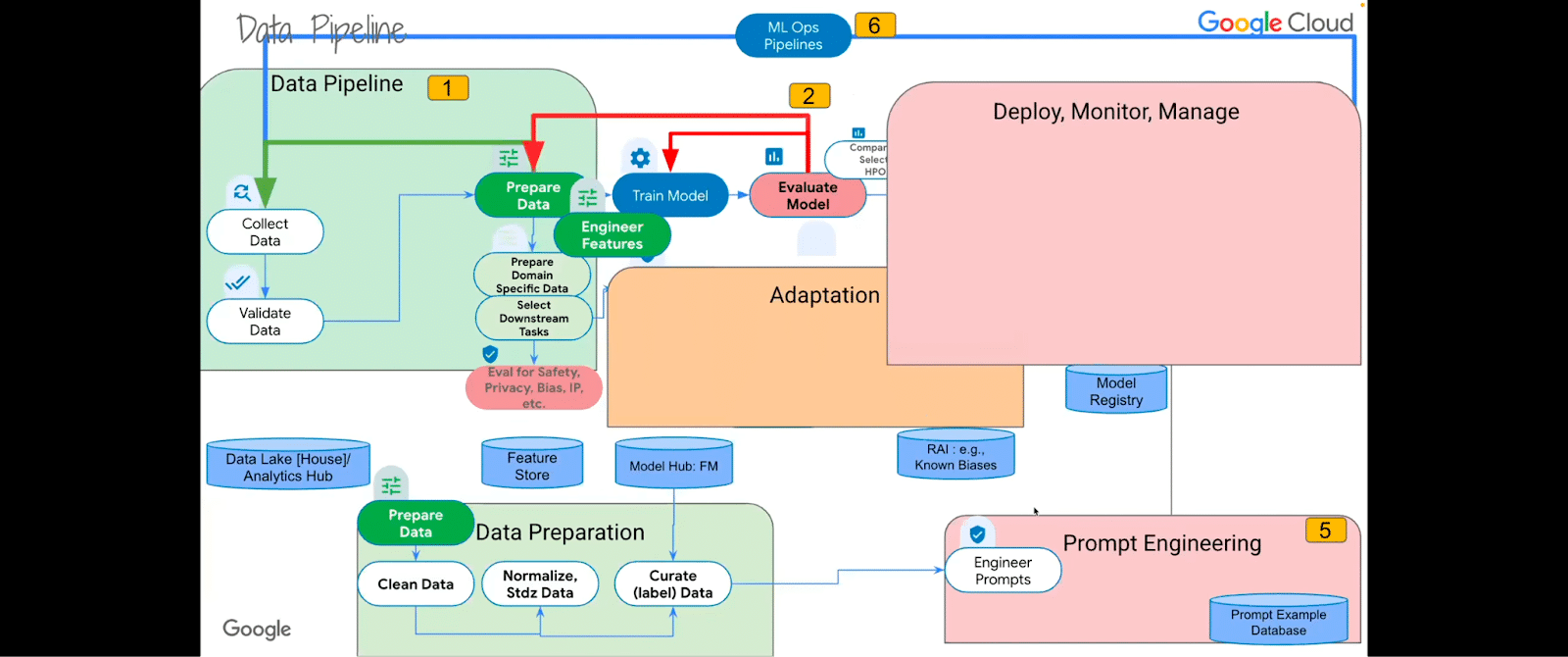
Let’s check out what some of these phases look like in more detail. In the data pipeline phase—I’m just going to call out things that I think are more important than the obvious. So the basic ones: you collect and validate and prepare data.
But then there are preparations for domain-specific data. Think biology. Think genomes. Think financial services applications. Very specific data and very specific downstream tasks that need to be evaluated at that data stage for safety, privacy, bias, et cetera, in the data. Because that’s the data that’s going to be training the model. And if the data has those biases in them, the trained model will also have those biases embedded in it.
In the data preparation, you obviously clean, normalize, and standardize your data, and you curate and label the data. This is one critical area that’s a big bottleneck. Snorkel AI is an excellent advocate of unblocking this in the enterprise.
Some of the negative aspects of using foundation models in this respect are that there could be a single point of failure that’s a prime target for attacks against applications derived from this model. It can be, alternatively, on the flip side of the coin, imbued with very strong security and privacy properties that could form the backbone, and everything else derives from it. These are the two sides of the coin.
Data poisoning, in terms of permissive data collection where there’s lack of direct training supervision, could inject hateful speech, for example, targeted at a specific individual, a company, or a minority group, and may be exacerbated by the growing size and accuracy of today’s models.
There could be function creep, where you could be challenged to constrain or foresee possible nefarious uses of foundation models or misuses of the model at design time. For example, CLIP is a model that was originally trained to the generic task of predicting image text pairs. But in doing so, it actually learned to capture rich facial features. But the model card doesn’t show that. It doesn’t really show that it could be used for surveillance that was deemed out-of-scope, for example. And this example illustrates that it may be challenging to constrain the possible nefarious misuses of a foundational model.
And of course, when you have several modalities of models, the adversarial attacks may attack one type of modality and not the other one. Let’s say in an autonomous driving system, it could primarily see a billboard with the word green on it and mistakenly interpret it as a green light if it’s a multimodal model.
On the positive side, it could act as a security choke point in a positive way. Defense against poisoning, model stealing, or resource depletion attacks.
There could be private learning that is cheaper—because typically these foundation models are trained on public data—if they could be adapted to perform tasks with significantly less amounts of confidential data.
Then there’s robustness to adversarial attacks at scale. Understanding how best to leverage this over-parameterization and unlabeled data to achieve adversarial robustness. Given their [foundation models’] unprecedented scale, they’re uniquely positioned to benefit. But, FMs seem to have little gains in robustness to worst-case adversarial perturbations.
The key takeaway here is this robustness is a big deal. Robustness to distribution shifts in real-world machine learning systems. You need to make sure that there is a system where the robustness is checked and maintained and monitored.
There are still ways in which we can affect robustness. For example, freezing a foundation model and training only the head. This can lead to better out-of-distribution (OOD) performance than just fine tuning the entire model, and is less costly. But the full fine tuning can distort the pre-trained features in even a simple setting. It’s still poorly understood why freezing the parameters seems to improve out-of-distribution performance.
Current adaptation methods may suffice for good in-distribution [ID] generalization, but they may not suffice for out-of-distribution or domain-adaptation situations.

The key takeaways and changes for adopting LLMs in terms of the changes to the life cycle are safety (which includes privacy, bias, toxicity, polarization, IP mitigation, or IP infringement types of things, via traditional rules or adversarial detection models) and misuse and robustness components.
And of course, making sure that the actual model sheets reflect what these were intended for and the potential side effects of what they are, and monitoring for adaptation drift and not just for things like skew.
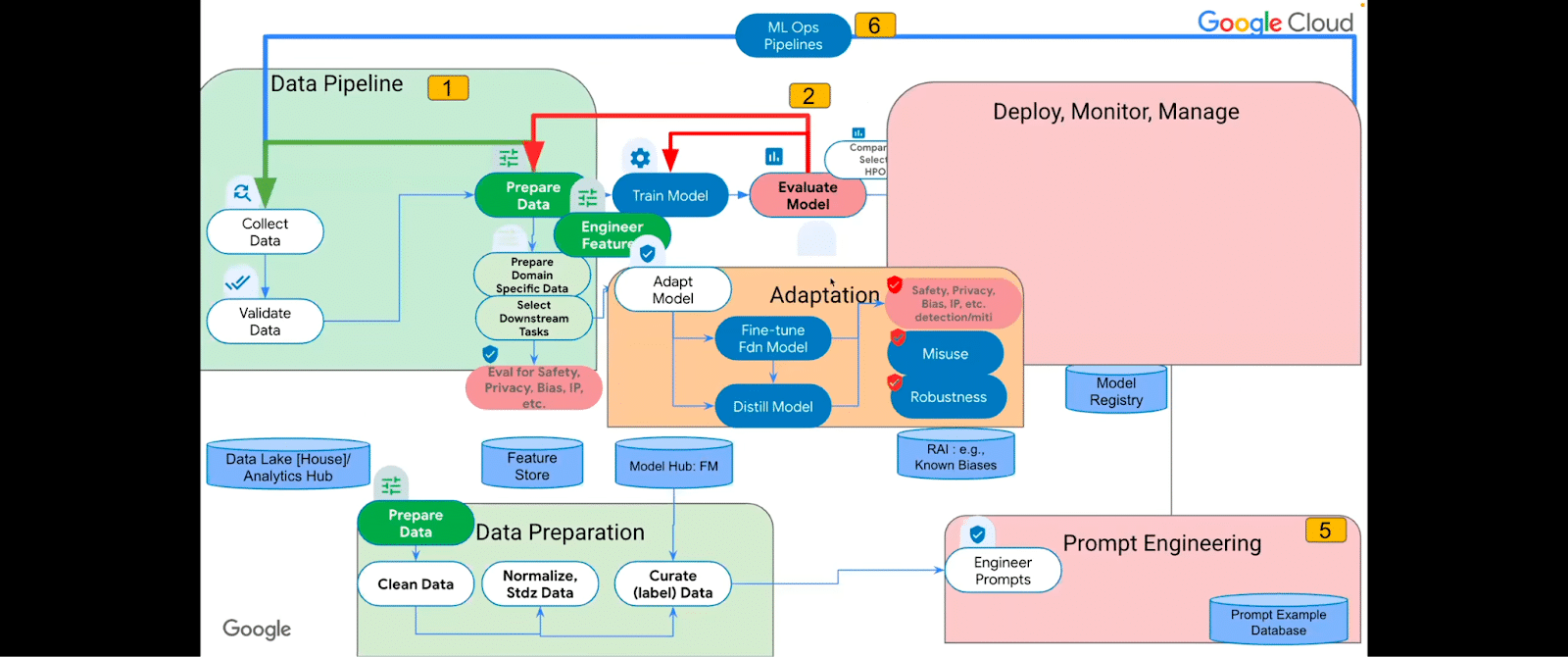
So, with adaptation and fine tuning, you can actually distill models and improve upon them by using these safety, misuse, and robustness guards.
In terms of AI safety, there is something called the control problem, where an advanced AI system enables us to reap the computational benefits while at the same time leaving us with sufficient control, so that when we deploy the system it doesn’t lead to a catastrophic event. That mitigation of the control problem is something that AI safety is concerned about.
There is this thing called Goodhart’s Law, which discusses the risks of optimizing misaligned yet easy to specify goals: the short term, the low hanging fruit. For example, engagement and social media—the negative effects of some recommender systems like polarization and media addiction, which may optimize simple engagement metrics but struggle to understand the harder-to-measure combination of societal, political, and consumer impacts that they may have.

Someone could easily misuse and take from a foundation model generator, combine elements together, and target very specific populations with fake profiles, fake news, and abuse. Detecting these types of misuses becomes a critical part of the adaptation phase.
Again, content quality. Because it could empower disinformation actors, maybe even states, to create content to deceive foreign populations and generate high-quality potential deep fakes, there is an imperative to have models that can detect the quality content that could be generated by these foundational models and are being misused.
The cost of content creation is lowered. So again, this becomes easier—the personalization and hyper-targeting becomes enhanced. Social media posts could be crafted to push certain narratives and target certain populations.
With this, we have to rethink how human interventions come about. For example, malicious practices are uncovered on social media, sometimes removed by humans searching the internet to uncover content origination. This is where the evidence becomes important. Disinformation websites frequently use plagiarized content to mask deceptive content, and foundation models can be used in this regard, but need to have that mitigation so that the actual references and evidence are supplied along with it. And the detection of these foundation models for misuse is also enhanced.
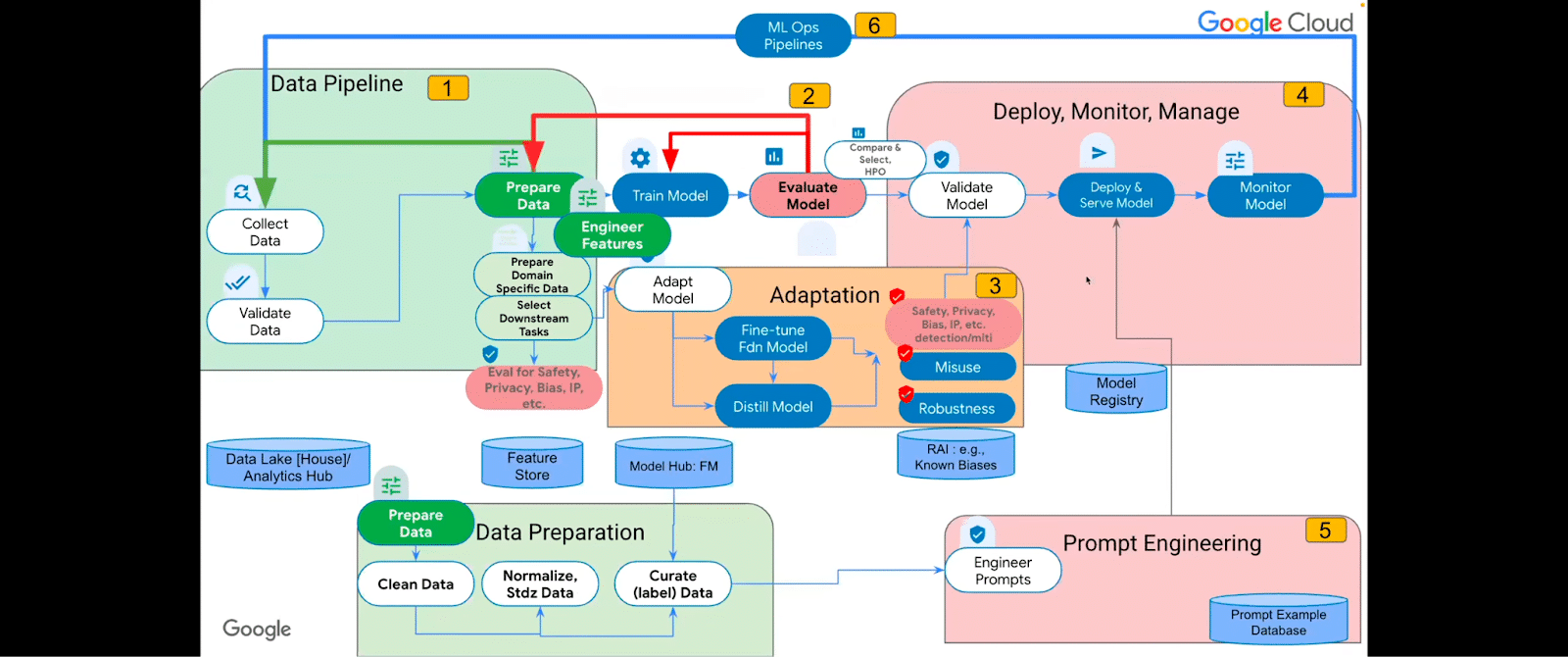
Okay, very good. So this is kind of the broad discussion around, okay, we’ve curated the model, experimented with it, done the adaptation. Now we can deploy and monitor it. Then comes prompt engineering.
Prompt engineering cannot be thought of as a very simple matter. It’s very experimental. People just basically try different prompts. You will pretty soon need some kind of a database of prompts, the ones that have been more successful, to select, to generate or test prompts and iterate over them based on the domain and downstream activity that you have. These represent the fifth stages.
So, [referring to slide above] one is the pipeline. Two is the experimentation with the training. Three is the adaptation. Four is the deploy, monitor, and manage. Five is the prompt engineering, and then you get into ML ops.
In terms of an enterprise, the safety, the robustness, and the anti-misuse factors should take into account these types of elements here.
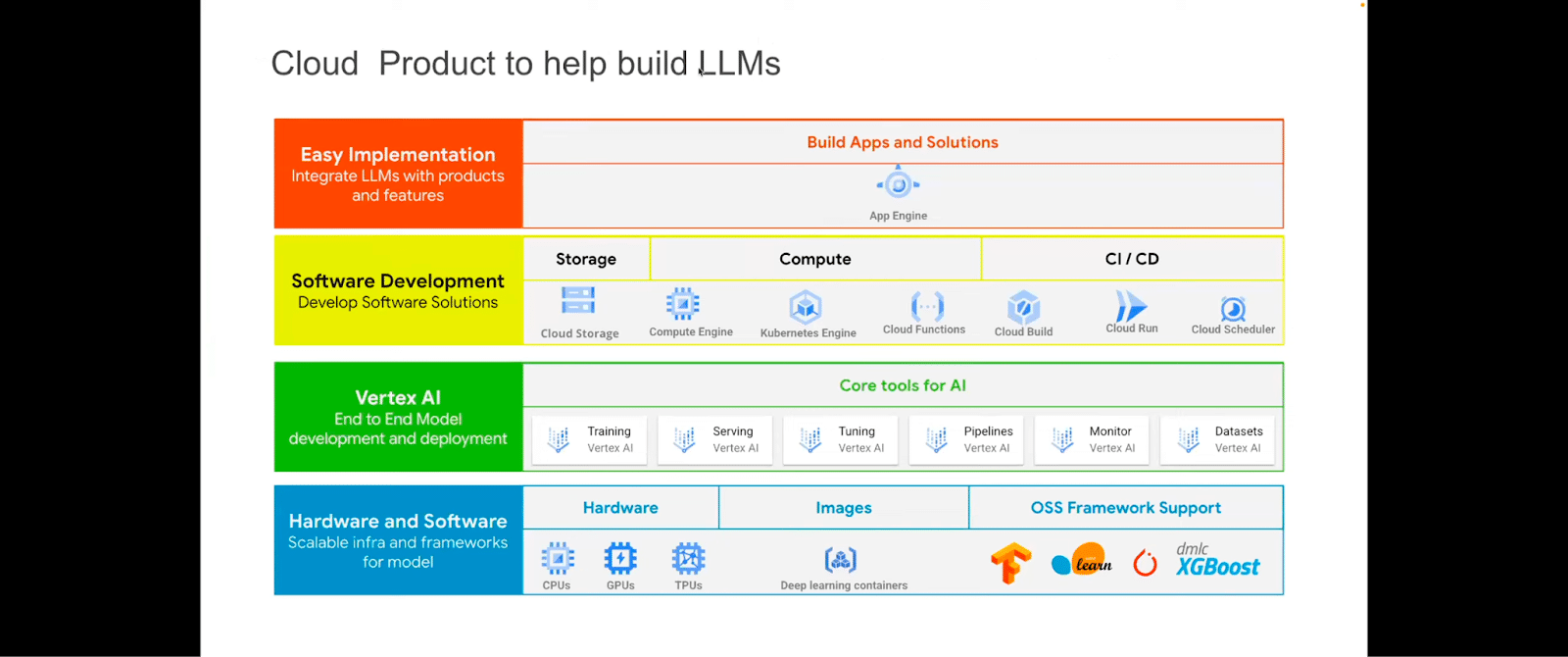
You can use various mechanisms to build LLMs. The Google Cloud platform has these capabilities that can be used to put reference architectures, to pre-train and fine-tune LLMs on the Google Cloud platform.
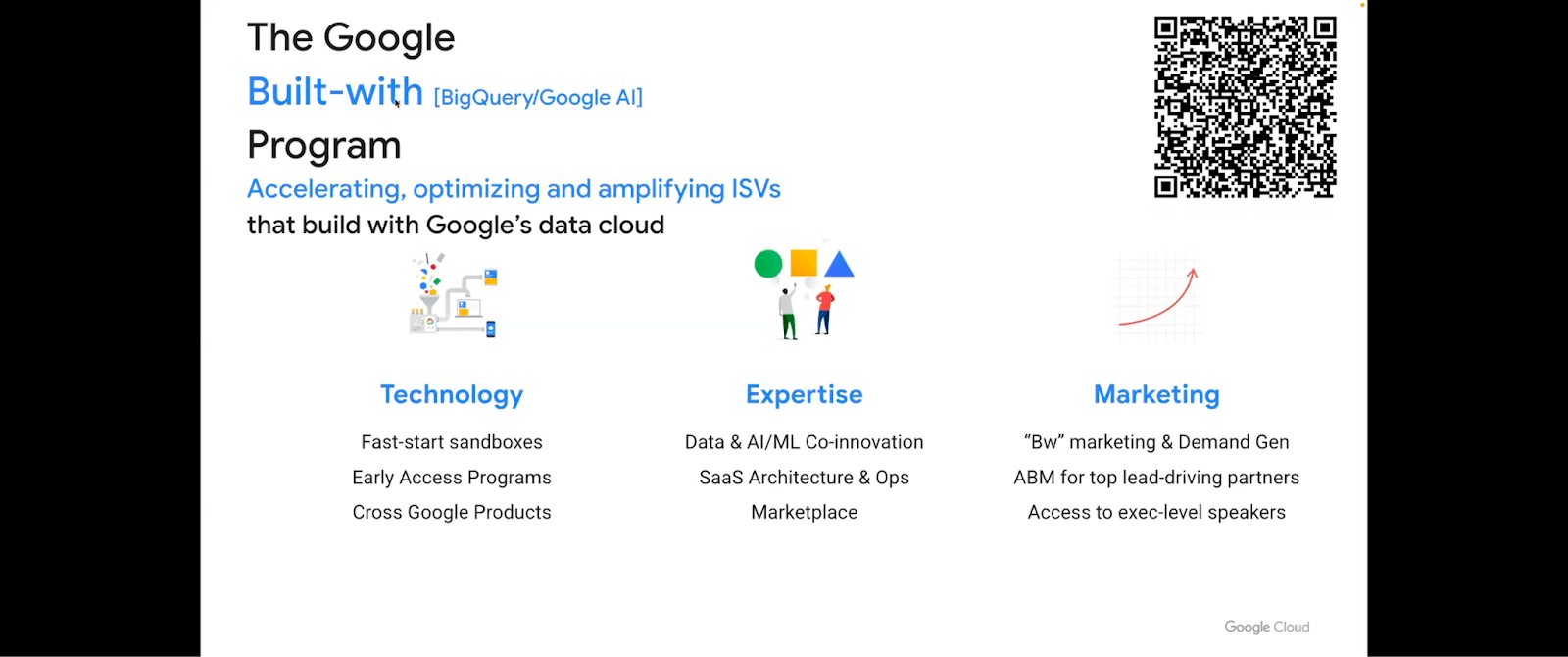
I’ve been asked before, how do we actually build with the Google Cloud program? There is a program that can be utilized if you’re interested in building with the Google Cloud program.
With that, I’d like to thank you very much for listening to this talk, and if you have any further questions, you can use this QR code to submit questions.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.

Team Snorkel