Enterprises that aim to build valuable, useful generative AI applications must view them from a systems-level. While large language models form the core of these applications, they exist as part of an ecosystem that connects numerous components, each of which plays a vital role in the end-users experience.
I recently discussed some of my work on generative AI (GenAI) applications in a talk called “Data Development for GenAI: A Systems Level View” at Snorkel AI’s Enterprise LLM Summit. My talk focussed on the importance of understanding the larger ecosystem in which large language models (LLMs) exist and how fine-tuning all system components with expert feedback can improve application performance.
You can watch the entire talk on our YouTube page, but I’ve summarized the main points below.
LLM application ecosystems
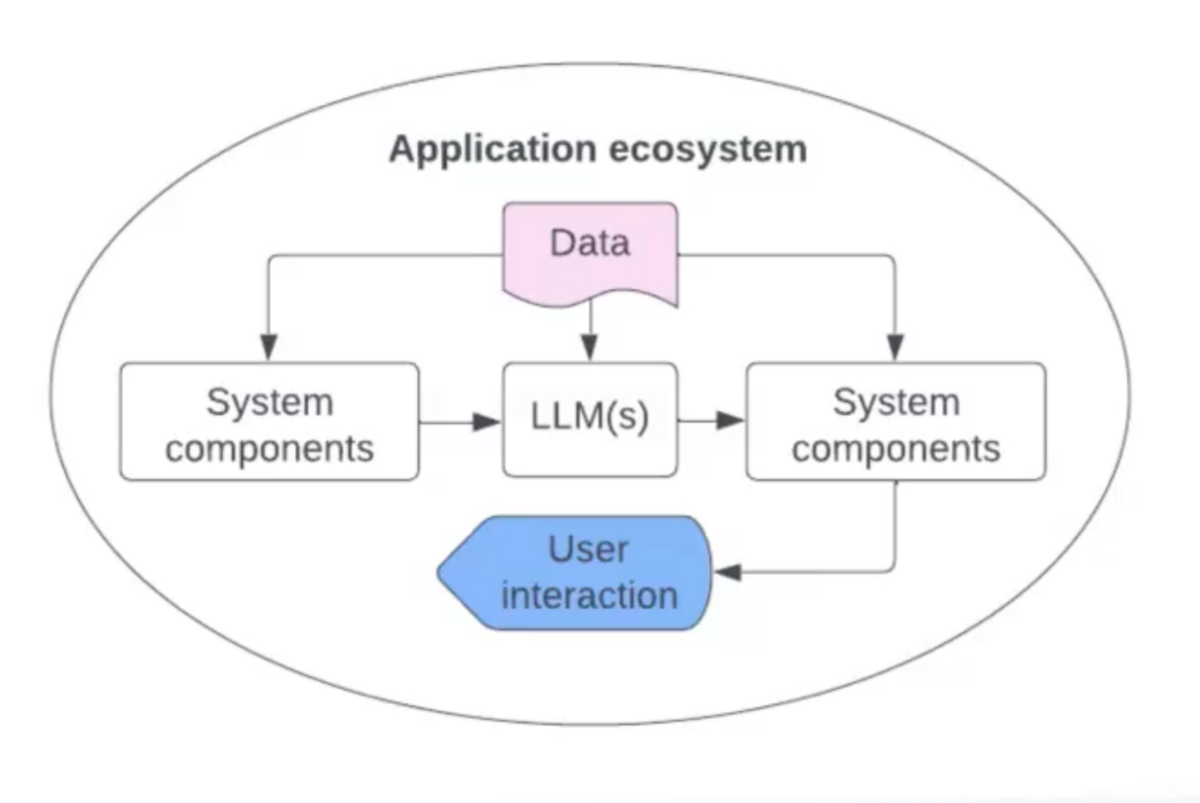
LLMs don’t exist in a vacuum. Used correctly, they form the foundation of an application ecosystem where data feeds various system components both upstream and downstream.
This ecosystem can include:
Input data pre-processing
Metadata, such as document tags
Embedding spaces, eg for vector databases
Document retrieval systems
LLM prompt templates
The LLM itself
LLM response detection algorithms (eg hallucinations, private company information)
Front-end components to facilitate user interaction
The pre-processing stage cleans and prepares data for the LLM. Next steps may include embedding models and a retrieval systems to find appropriate passages to inject as context in the final prompt. Then, the model itself ingests the prompt and yields a response, but the process isn’t over. The post-processing stage refines the response. This stage might, for instance, detect hallucinations to ensure the AI’s generated content is coherent and sensible before delivering the final output to the user.
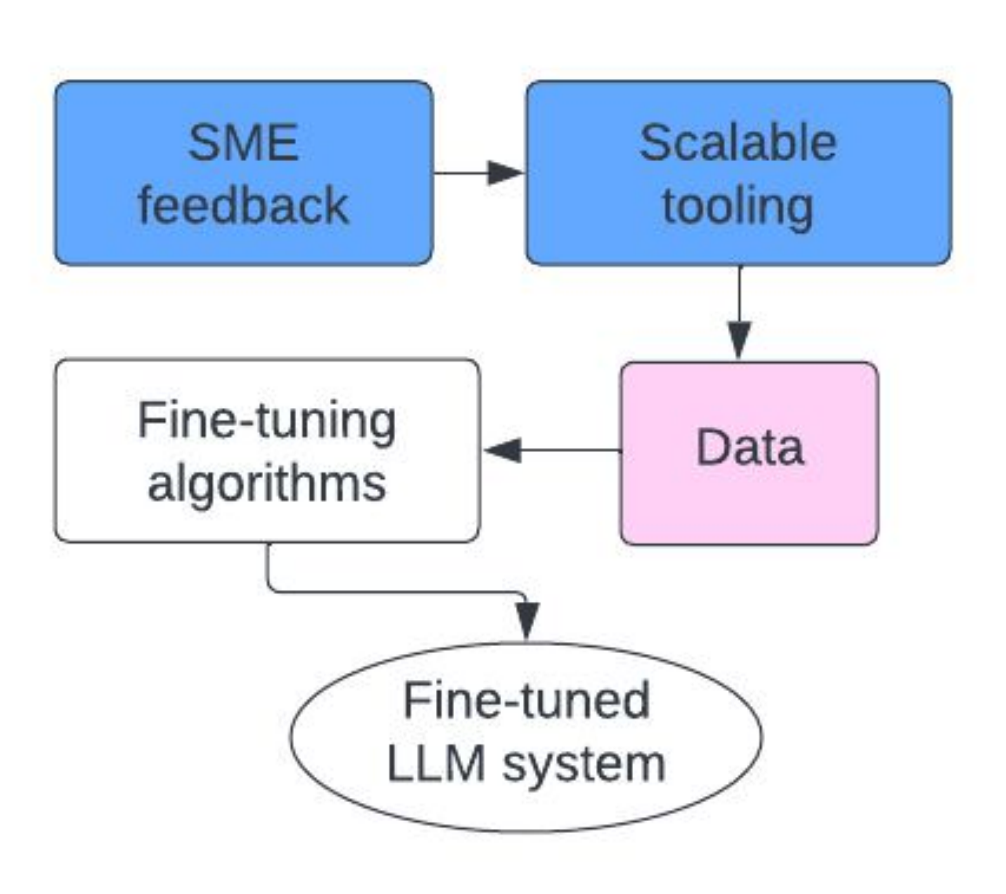
Each of these components plays a crucial role in the system’s performance. However, their performance isn’t static. They require fine-tuning based on expert feedback
Incorporating expert feedback into the fine-tuning process has previously been a challenge—primarily due to scalability issues. AI projects often demand vast amounts of data, and experts rarely want to review and annotate each record individually.
Case study: improving a RAG system for a global bank
A team of researchers and engineers at Snorkel recently completed a collection of enterprise GenAI projects, including one that improved a retrieval augmented generation (RAG) system for a top global bank. This system handled complex, unstructured financial documents and answered business-critical questions about them.
Through a combination of programmatic data development techniques, we fine-tuned every component of the RAG system. The result was a significant accuracy boost, with only a minimal amount of time required from subject matter experts (SMEs) to explain how to interpret document language and where to look for key pieces of information.
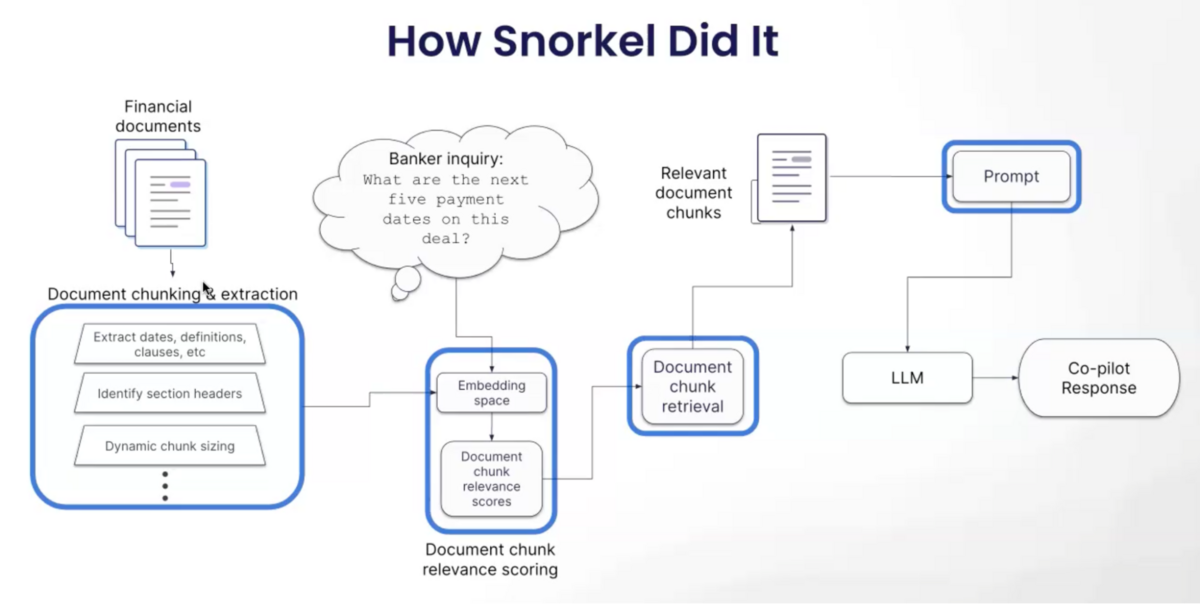
Document chunking and tagging
First, we had to improve how the application chunked and tagged documents. For example, the retrieval model struggled with questions about dates. Dates may seem like a simple concept, but these documents often referenced dates in subtle ways the model missed.
We consulted with an SME to create a custom date extractor. This new extractor, developed in only four hours, had a 99 macro average F1 score.
We also discovered that the retrieval system struggled with legal definitions. With some more SME help, we developed a model to identify these legal terms. With about four hours of work, we achieved a 93 macro average.
These two support components set the stage to help our users find the information they needed when they needed it.
Fine tuning the embedding space
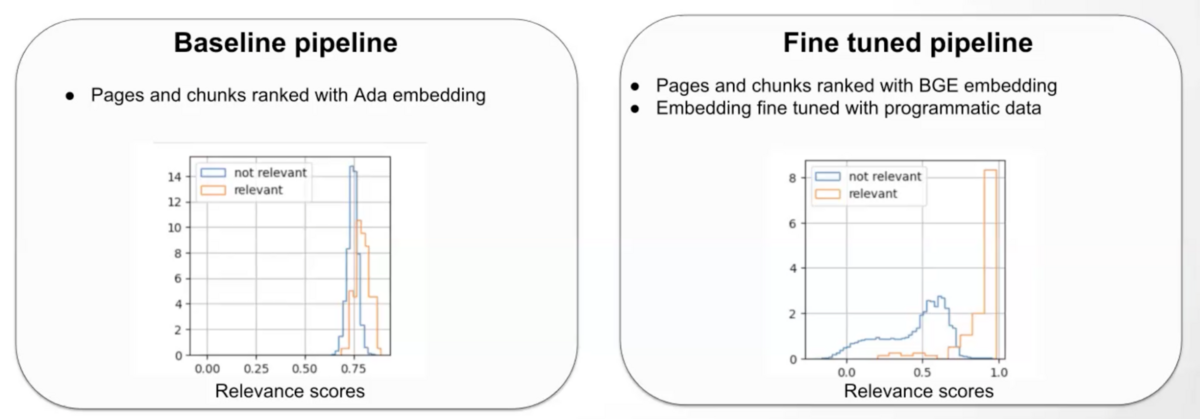
Next, we moved to the embedding space. The off-the-shelf embedding model we started with treated key document sections as being too similar than they were from an SME’s point of view, making them difficult to differentiate. We asked the SME on the project to manually annotate a small number of documents with explanations as to why they made their data annotations. We then adapted the expert’s logic and intuition to label a larger training set that we used to fine-tune our original embedding model. The result was a much clearer distinction between relevant and irrelevant sections of the document.
Improving chunk retrieval
We also improved the chunk retrieval process. The original algorithm used fixed parameters, which proved too rigid. We instead made the process adaptive to the question and the distribution of relevance scores. As a result, our system pulled all of the most relevant chunks that fit within the LLM’s context window.
Results
By fine-tuning all the components of the RAG system, we achieved a 54-point increase in question-answering accuracy in just three weeks. This improvement required fewer than 10 hours from the SME—who spent more time verifying the system’s output than annotating documents.
The role of expert feedback in AI development
Expert feedback has always been a vital component of valuable AI systems. It’s even more important in GenAI systems. In our case study, the insights, logic, and intuition the SME provided guided how we developed and fine-tuned different components. However, incorporating expert feedback into the AI development process historically posed a significant challenge. Their time is valuable, and data labeling can be onerous.
Our approach maximizes the impact of SME involvement through scalable tooling that multiplies expert logic and intuitions without the need for extensive manual annotation. This not only accelerates the development process but also enhances the effectiveness and accuracy of the resulting AI models.
Expert input + systems-level thinking: the key to enterprise AI
Taking a systems-level perspective and incorporating expert input leads to stronger, more valuable, and more useful GenAI applications. Expert feedback plays a crucial role in this process, and scalable solutions allow data scientists to efficiently incorporate this feedback while minimizing the burden on SMEs.
As we continue to develop methods, we look forward to seeing further improvements in the accuracy and effectiveness of LLM-backed and GenAI applications.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.
Chris Glaze is Applied Research Scientist at Snorkel AI. He is an experienced PhD with a demonstrated history of developing novel machine learning tools and mathematical models in academia and industry. Accomplishments span data mining, experimental research, and application to digital technologies.
SlopCodeBench reveals how AI coding agents degrade code quality over time—measuring “slop,” technical debt, and architectural erosion across iterations.
Today, we’re sharing details about the Snorkel Agentic Coding benchmark—a comprehensive evaluation suite designed to test whether agents can handle the full complexity of software engineering work.
We just returned from NeurIPS 2025, and we’re still processing everything we saw. The energy around data-centric AI has never been stronger—and we couldn’t be more grateful to the research community for pushing these ideas forward.
Join our newsletter for expert advice, the latest research, and exclusive events.
By submitting this form, I acknowledge I will receive email updates from Snorkel AI, and I agree to the Terms of Use and acknowledge that my information will be used in accordance with the Privacy Policy.