Understanding and quantifying people’s opinions has become increasingly important to businesses, but the way people can express multiple thoughts in the same sentence has frustrated practitioners’ efforts to extract those opinions cleanly—a problem we can solve through aspect-based sentiment analysis (ABSA).
This practice allows us to understand people’s opinions at the aspect level. For example, say we have the following customer review of a restaurant:
The shrimp rolls were amazing, but our server Emma was really rude.
With simple sentiment analysis, it would be difficult to encapsulate the customer’s feelings because the process would assign a single sentiment toward the restaurant regarding the entire text. We would prefer that our model tell us that the customer feels positively about the food but negatively about the service, like this chart below.
| Aspect | Target | Sentiment |
| Food Quality | Shrimp Rolls | Positive |
| Service | Server Emma | Negative |
Researchers and developers have built several modeling solutions for this task, using advanced machine learning techniques such as deep learning and neural networks. However, there is often a limited amount of training data available for this task due to a lack of labeled reviews at the aspect level. Additionally, in an enterprise context, domain-specific data is typically crucial for a performant model.
With Snorkel Flow, we can take a data-centric approach to this problem. Snorkel Flow offers the ability to create high-quality training sets for an ABSA task to train a machine learning model, and improve model performance by iterating on training data with directed error analysis.
Platform capabilities
To demonstrate Snorkel Flow’s capabilities for ABSA, we’ll use the SemEval-2016 Task 5 dataset for ABSA with restaurant reviews. We consider 4 aspects: “food quality”, “service”, “ambiance”, and “general.”
In Snorkel Flow, we can perform ABSA in two steps, each with its own machine-learning model:
- Text extraction.
- Classification.
In the text extraction step, we’ll identify each target in a review by first extracting high-recall candidate spans, In other words, the model will extract as many spans as possible that could be targets of aspect. After this, we can then classify each span and perform sentiment analysis using the surrounding text to assign a sentiment to each aspect we’ve identified in the review.
In both steps, we use labeling functions to provide sources of weak signals. We start out with a small amount of ground truth to help guide our labeling function development, as well as a validation dataset that allows us to evaluate our final model performance. Snorkel Flow uses these labeling functions to programmatically label training data for the two models.
Extracting targets and aspects
The first step in the modeling process is to extract targets (different elements or topics the reviewer is discussing), and assign them one of the four aspects. To take our example from before, in this step we identify the span of text corresponding to the target of the service aspect, and the span of text corresponding to the target of the food quality aspect.

To identify high-recall candidate spans, we use an extractor to identify noun chunks leveraging out-of-the-box functionality from the spaCy NLP library. spaCy describes noun chunks as “a noun plus the words describing the noun”. For example, “the terrible ravioli” or “the restaurant staff.” The Snorkel Flow interface highlights our noun chunks with their respective aspect or marks them as unknown if they do not correspond to an aspect of interest.
In the example below, we can see that spaCy has extracted three noun chunks, the first corresponding to “food quality”, the second corresponding to “atmosphere”, and the third corresponding to “general”.

Labeling functions for assigning aspects to the targets can encompass a wide range of strategies and leverage various resources. We can use simple keyword builders, such as looking for the word “waiter” or “host” in the span of text (the noun chunk) to indicate that the reviewer is discussing “service.” Snorkel Flow also offers labeling functions specifically designed to classify spans such as looking at words within a certain character or word window of a span, the location of a span within a review, and more.
For example, perhaps we find that reviewers tend to talk about the quality of food first and comment on other aspects secondary. In this case. We could build an LF that checks if the span occurs within the first 5 words of the review, or occurs before a span from another class to classify it as food quality.
We can also leverage more complex sources of signal, such as knowledge bases or ontologies. In this example, we import a dictionary of common food words, and search for these words within a span of text to classify them with the aspect “food quality”.
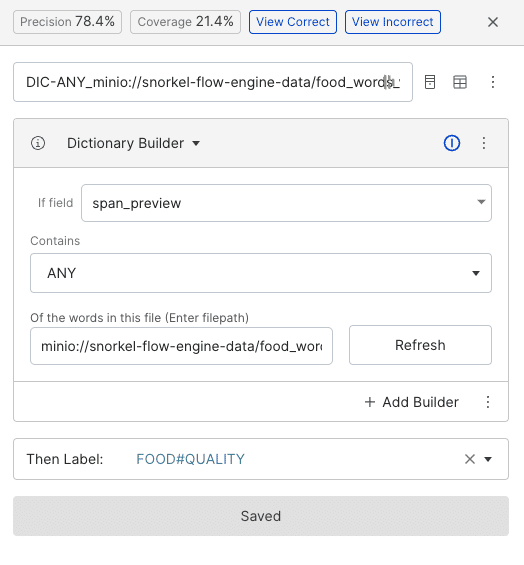
If an out-of-the-box utility such as the spaCy noun chunk extractor is not sufficient for identifying the targets, we can also accomplish this task with sequence tagging.
Sequence tagging is a slightly different and more computationally intensive workflow offered in Snorkel Flow. Rather than extracting high-recall spans using an extractor, we use a named entity recognition model to extract and classify spans. With sequence tagging, we use a distillBERT model to make predictions for extracted spans and their corresponding category.
Weak supervision and refinement
Our labeling functions do not have to be completely precise or cover all of our data. The label model denoises these functions and automatically labels the training data.
After we automatically label a training set, we can then train a weakly supervised machine learning model. Using directed error analysis, we can then iterate on our training set by refining and creating labeling functions.
Getting the “sentiment” for aspect-based sentiment analysis
The second step in ABSA is to analyze the sentiment of the extracted targets. This way, we can better understand how the reviewer feels about the various aspects of the restaurant.
Snorkel Flow offers the ability to apply an external model-based labeling function right from the UI. In this case, we apply the NLTK polarity model to the span’s surrounding text (span_preview) to provide a weak signal. For example, if the polarity value output by the model is less than 0.55 in this case, we’ll label the span as negative.
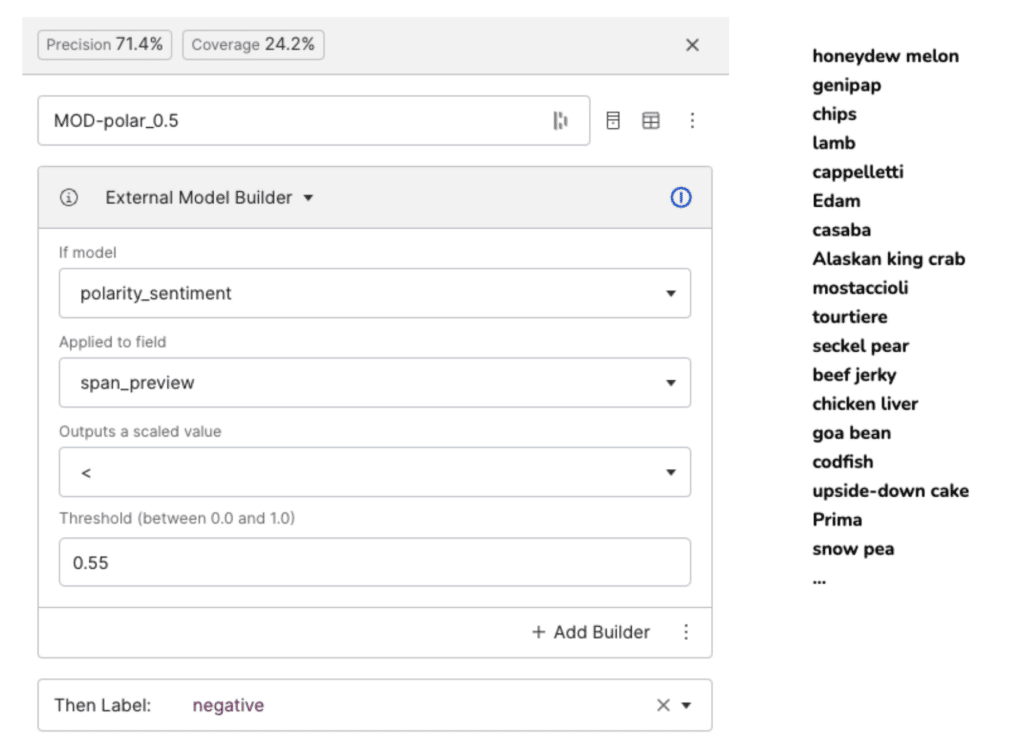
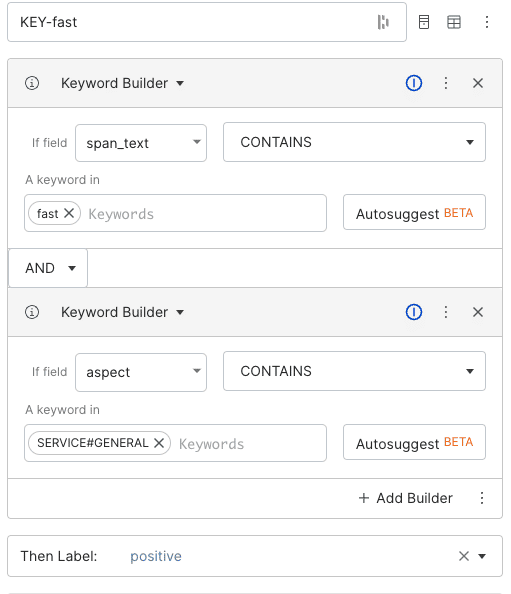
We can create a variety of labeling functions to label documents for sentiment analysis, including keyword builders and regex builders. Additionally, we can leverage the information we have from the aspect we have assigned to the target in the previous step to create more fine-tuned and precise functions, as the language used to describe positive and negative opinions may differ per aspect. For example, we might see that the word “fresh” corresponds to positive sentiment when the aspect is “food”, but not for the aspect “service”. We can write the following labeling function:
The words immediately surrounding a target may not capture completely the feelings towards the aspect. For example, a review might say “…wonderful birthday gift. The restaurant was underwhelming”. In this case, the text surrounding the target “the restaurant” would include the word “wonderful”, perhaps causing some errors.
Within Snorkel Flow, we can create preprocessors to extract linguistic features and dependencies between words to write labeling functions over, thereby leveraging more information within a passage of text. For example, we may find that if a span contains a restaurant name, it is likely of the “general” aspect, and could then build a labeling function to look for proper nouns.
As with the previous step, our labeling functions do not have to be 100 percent accurate or cover all of our data. Using the error-driven workflow, we can iterate on our labeling functions and drive towards a more robust ML model. Users can bring in state-of-the-art transformer-based models, as well as in-house models in the step.
Conclusion
In this example, we used span extraction and classification techniques to identify various aspects users mention within a restaurant review. We then built on it with sentiment analysis to obtain fine-grained aspect-based sentiment analysis of the reviews. After applying our pipeline, we have extracted targets and their aspects, along with the sentiment of the reviewer towards the said aspect. The result is a pipeline capable of parsing a reviewer’s conflicting feelings on a restaurant experience.
If you are interested in learning more about how you can perform aspect-based sentiment analysis or similar workflows within Snorkel Flow, feel free to request a demo with one of our machine-learning experts.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!
