Simran Arora is a machine learning researcher at Stanford University. She presented “Ask Me Anything: How are Foundation Models Changing the Way We Build Software” at Snorkel AI’s Foundation Model Virtual Summit 2023. A transcript of her talk follows. It has been lightly edited for clarity. Learn more about large language models here.
I’m excited to share some of my recent research and thoughts around building software systems with foundation models. The particular focus of today’s talk will be a recent method we developed for using foundation models, which is called Ask Me Anything.

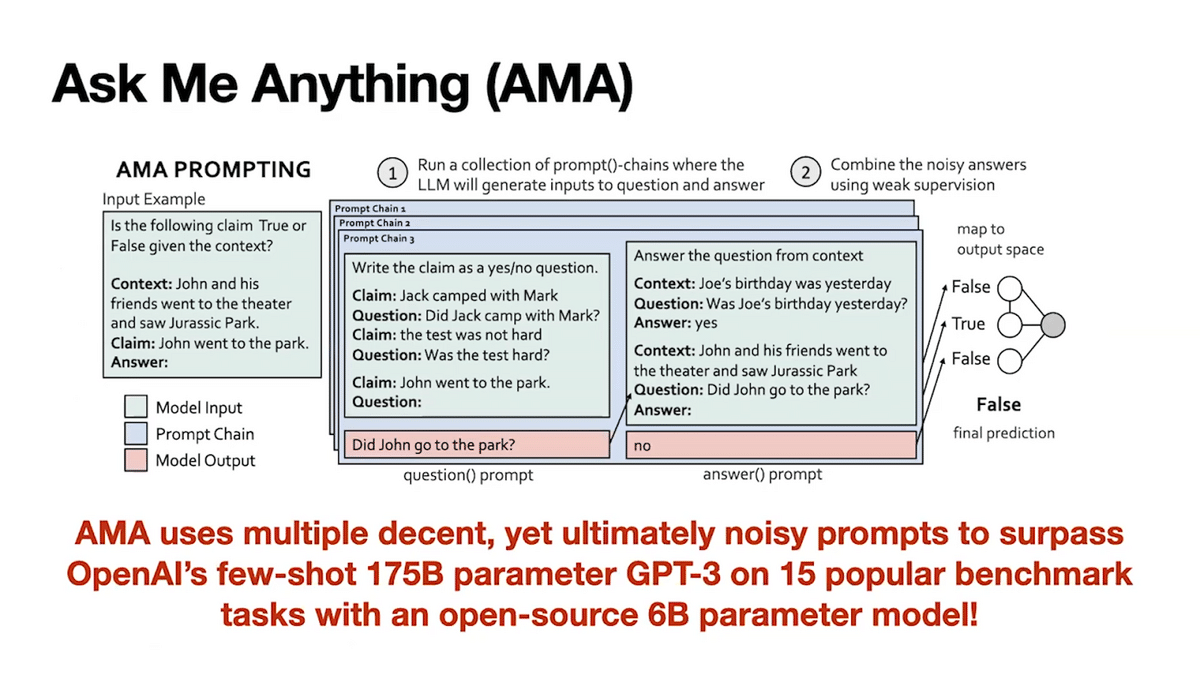
“Ask me anything,” or AMA for short, is a procedure for adapting foundation models to tasks of interest without any training whatsoever. We demonstrate AMA on a broad range of tasks ranging from classification to question answering, to natural language, understanding, and inference.
AMA enables an open-source model to outperform a closed-source model that is 30 times larger in size on 15 popular tasks. Specifically, the closed source model is the popular 175 Billion parameter model called GPT-3, which was developed by an organization called OpenAI. We also find AMA’s performance improvements are general. They hold across 14 unique foundation models that span five orders of magnitude and model parameter size.
Today I’ll talk about how we arrived at AMA and why we think these results are exciting in the broader context of using foundation models for building software systems. I’ll start with some context on foundation models and how they’re already providing a new way of attacking classical problems and systems. Next, I’ll discuss some of the challenges we see in terms of the industrial deployment of such solutions. Finally, I’ll dive into the Ask Me Anything method.
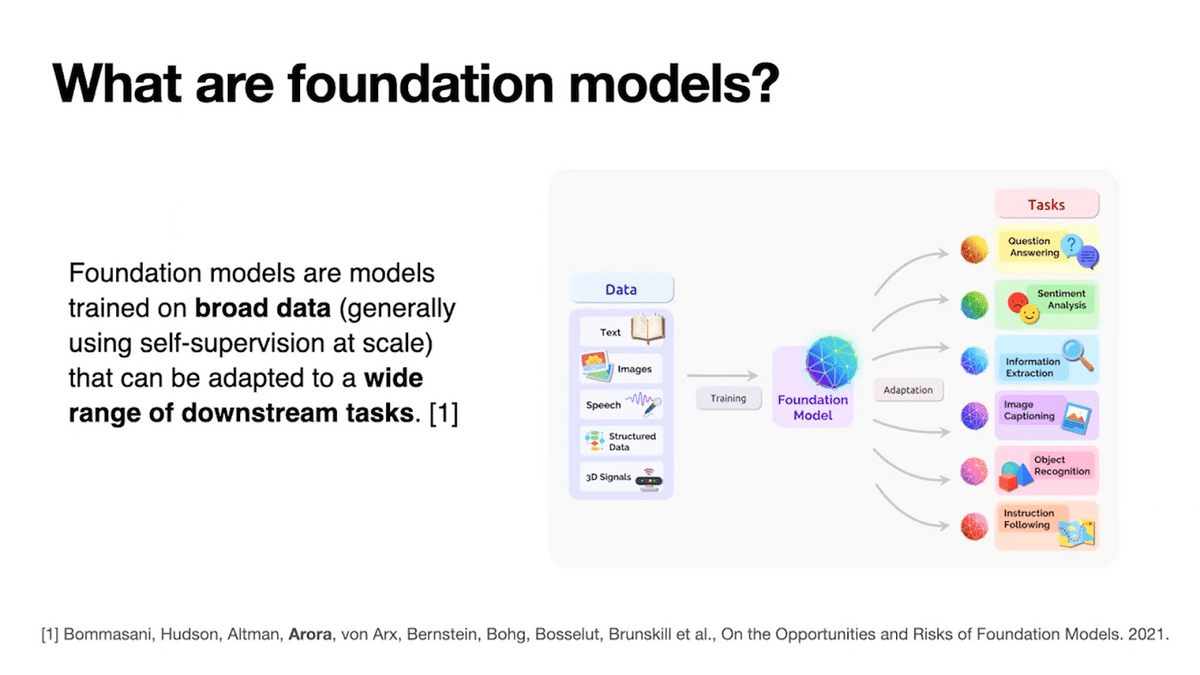
Foundation models are models that have been trained on diverse, massive amounts of data—for instance, hundreds of billions of tokens from the internet. These models are trained in a general manner rather than for specific downstream machine learning tasks.

Before foundation models, we would train a model from scratch for each task. But today, foundation models are often used as a starting point. Because the models have seen so much data, they have learned general-purpose patterns that prove useful for a wide range of downstream tasks. The size of available foundation models has been rapidly increasing in recent years from models like BERT at the 100 million parameters scale to the 500 billion parameter PaLM model trained at Google.
We have seen exciting new model capabilities emerge as we scale the amount of data, number of parameters, and computational resources that are used to train our foundation models.
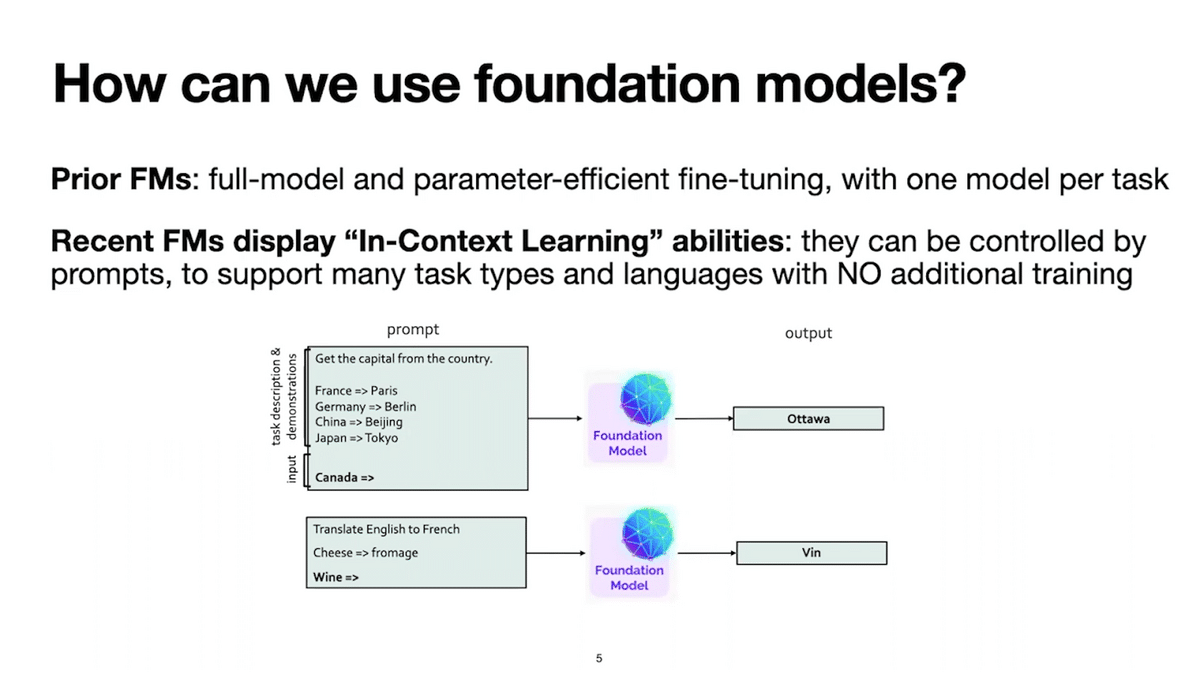
In particular, this new scale is giving rise to exciting new capabilities. While early foundation models, or FMs for short, are adapted to new tasks by further fine-tuning them on specific data from our downstream task, recent FMs are able to perform new tasks without any additional training whatsoever via a capability called in-context learning.
What is in-context learning? Consider a foundation model that has been trained on tons of language data in a general-purpose manner. All it’s trained to do is predict the next word in a text sequence. For instance, suppose I give the sequence “the cat in the.” We might expect the model learns to place a high probability on “hat” as that last word. That prefix, “the cat in the,” is commonly called a prompt.
As users of foundation models, by constructing that prompt appropriately, we can get the model to perform our downstream tasks out of the box. The model essentially performs our task by conditioning only on this prompt context, and hence this process is referred to as in-context learning.

Recent foundation models are amazing and they have gained a lot of attention in research and industry. We’re super excited by their potential. The natural language interface enables a wide audience of both ML and non-ML experts to engage with the models. The ability to prompt foundation models to perform a range of tasks with no additional training requirements allows us to rapidly prototype new ideas and build apps in hours that would’ve previously taken years.
So what are some of the exciting opportunities presented by these models when it comes to building systems?

First, we show that in-context learning is providing a new approach for building systems that assist users with personal tasks. Because personal context is often sensitive, we require systems that protect privacy.
Consider a user, Jenna, who has her private email inbox and wants to train a model that automatically classifies her email. There are two key approaches in prior work. First, with local training, Jenna can train that model only on her own data, her own laptop. She’s good to go. No one can learn anything about her data or even what tasks she performed.
But users do not typically have enough personal data to train robust models themselves. To address this issue, federated learning has emerged as a popular recent topic with thousands of papers each year. The main idea is to assemble users who are interested in the same task, pull their data to train the model, and the key feature is that the model is actually trained without Jenna’s data ever leaving her laptop. However, federated Learning provides much weaker data privacy guarantees, and notice that the task Jenna is performing is fully exposed to everyone. So can we get privacy and good quality at the same time?
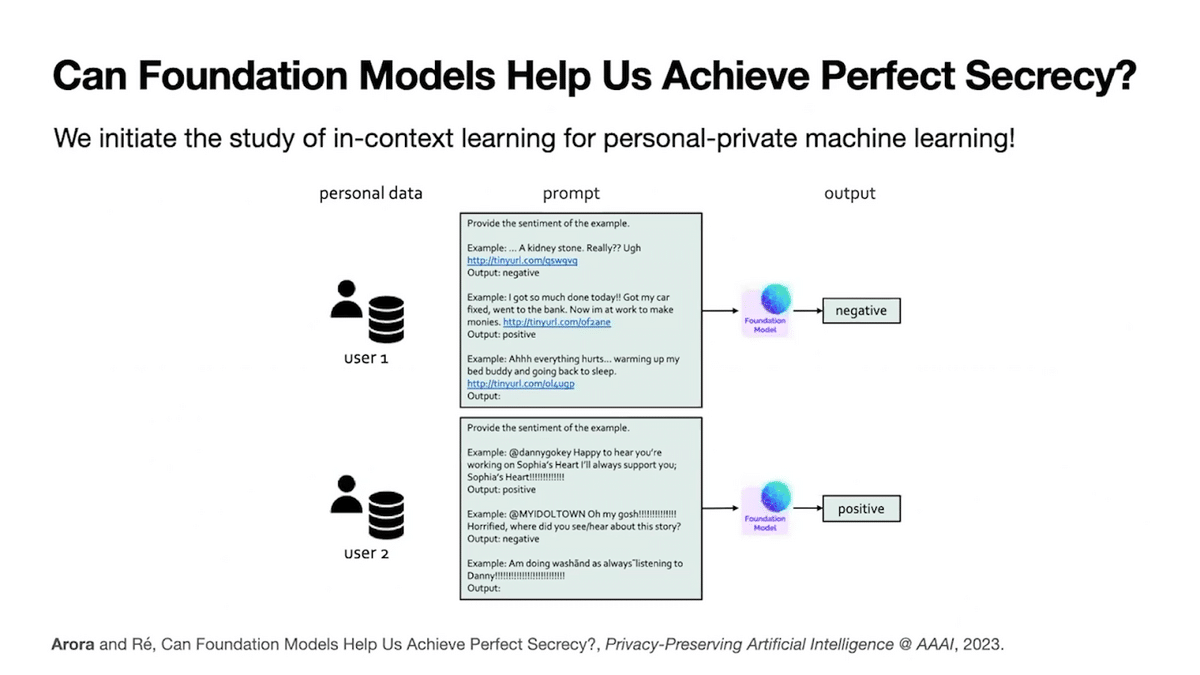
In our recent work, we excitingly show that in-context learning offers both the strongest possible data and task privacy guarantees, while also providing competitive quality to those prior training-based approaches for private machine learning. Recall in-context learning requires no training whatsoever.
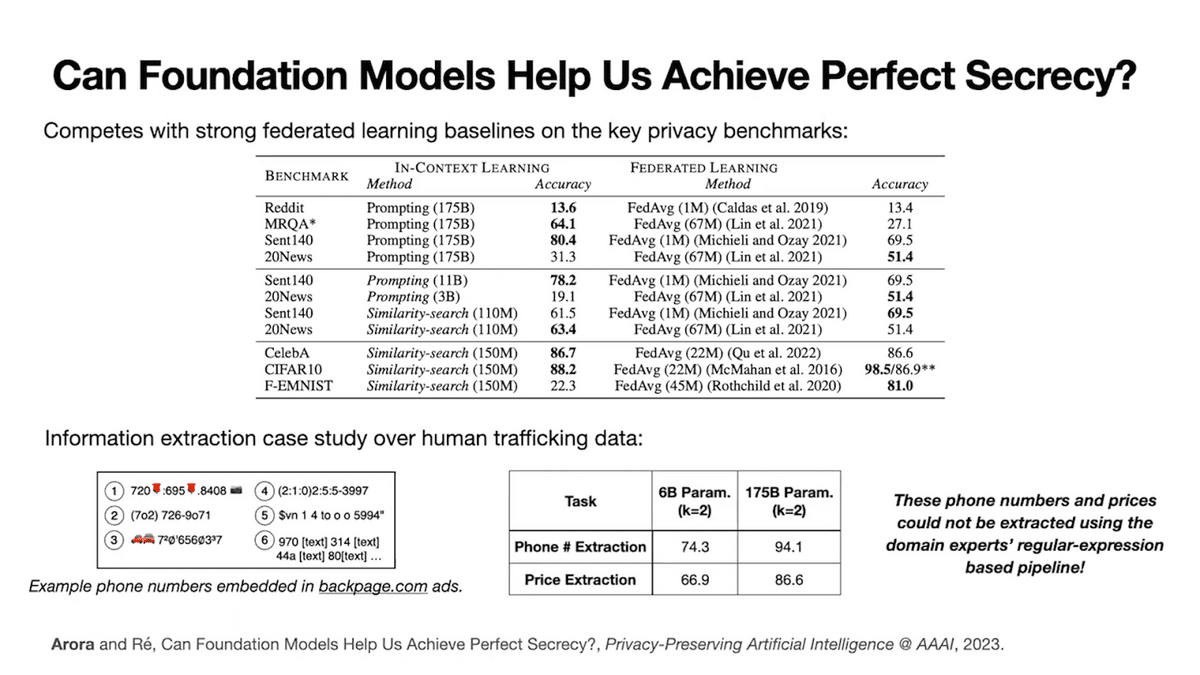
These key results on privacy benchmarks are shown up top. The one interesting question you might ask is whether the model only does well on these benchmarks because they’re somehow similar to the large swaths of internet data that our foundation models are trained on. Therefore, I also just want to highlight tasks that are likely to be highly different from any data the foundation model has seen.
Specifically, we apply the method to extract phone numbers and prices from human trafficking ads to support our collaborators working on human trafficking prevention. In these ads, phone numbers are written highly adversarially, so computers and law enforcement cannot detect them easily. Some examples of the phone numbers as they’re embedded in the ads or presented on this slide.
We show that foundation models succeed even on this highly noisy data, but you can notice that the small model, 6 billion parameters, is comparatively worse than the larger model. This leads me to some of the challenges with the proposal.

The key challenges are that the models that give good in-context learning quality are quite large, and the best-in-class models are closed source—only accessible by sending our data to an API. We can’t send private data such as medical records to an API, and therefore we need small open-source models to improve the feasibility of our proposal.

A next huge challenge is data preparation, or data wrangling tasks, such as identifying and filling in missing values or detecting data entry errors and databases. These tasks can take up to 80% of a data analyst’s time, a well-cited statistic. This has led to significant effort and research on data wrangling systems over the years. Excitingly, simply using in-context learning and no additional training can outperform those state-of-the-art systems for these tasks. Led by my lab-mate Avanika, we put out the first proof of concept in-context learning-based data wrangling system in our recent work.
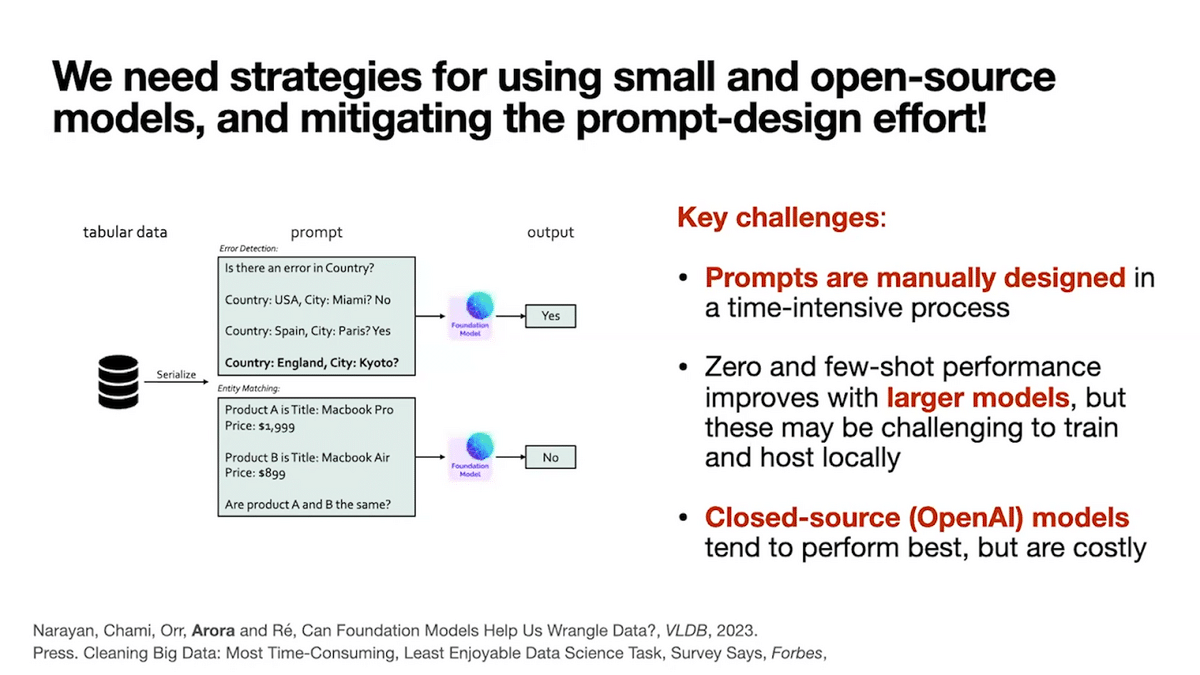
But again, there are challenges. In-context learning can be brittle. The proof of concept involved writing up manual prompts and quality is overall quite sensitive to prompt design. We also achieved good quality using large and closed source, 175 billion parameter foundation model from OpenAI, which is costly to use.
This motivates methods that mitigate the high degree of effort required in prompt design, and that again enable the use of small and open source foundation models.

Beyond privacy and data wrangling, there are so many more exciting use cases for foundation models out there in research and industry, even with today’s relatively early foundation models. But again, I mentioned some very real challenges for deploying the types of systems I discussed.
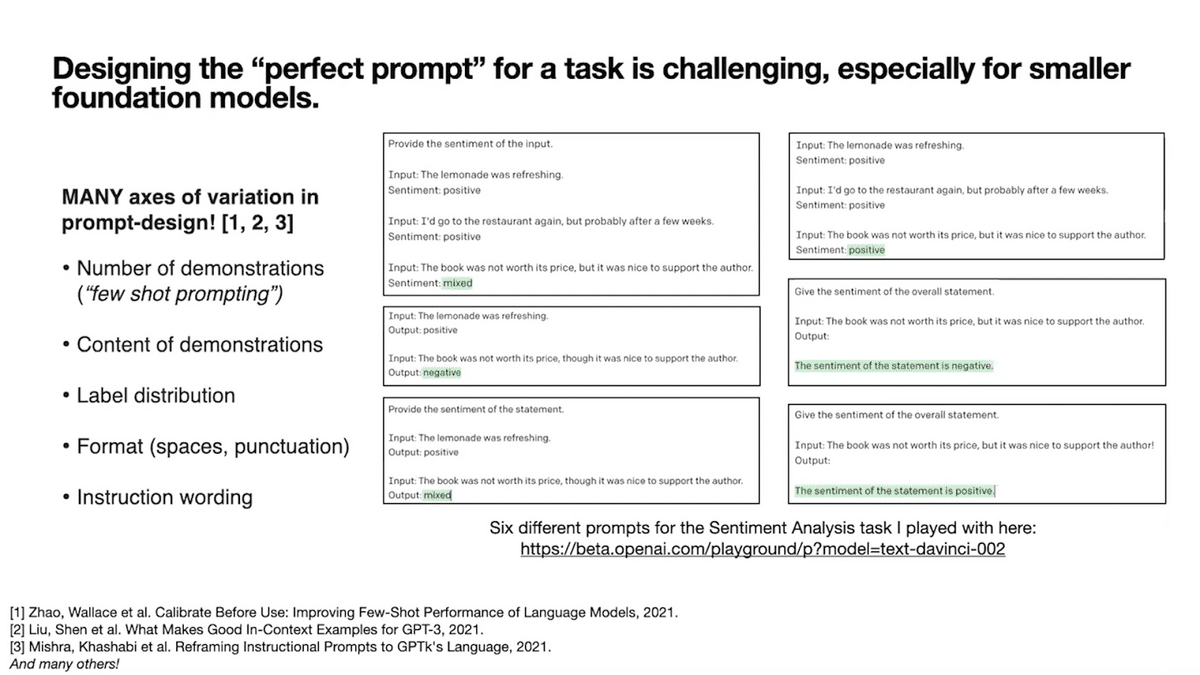
To recap: One, small variations to the prompt can lead to wide and unexpected differences in how the model behaves. Here, I took the same sentiment analysis example and prompted one of OpenAI’s popular model versions in six different ways. You can see the predictions are all over the board, from predicting the example as negative to positive to neutral in sentiment. It’s painstaking to design a single perfect prompt for a task.
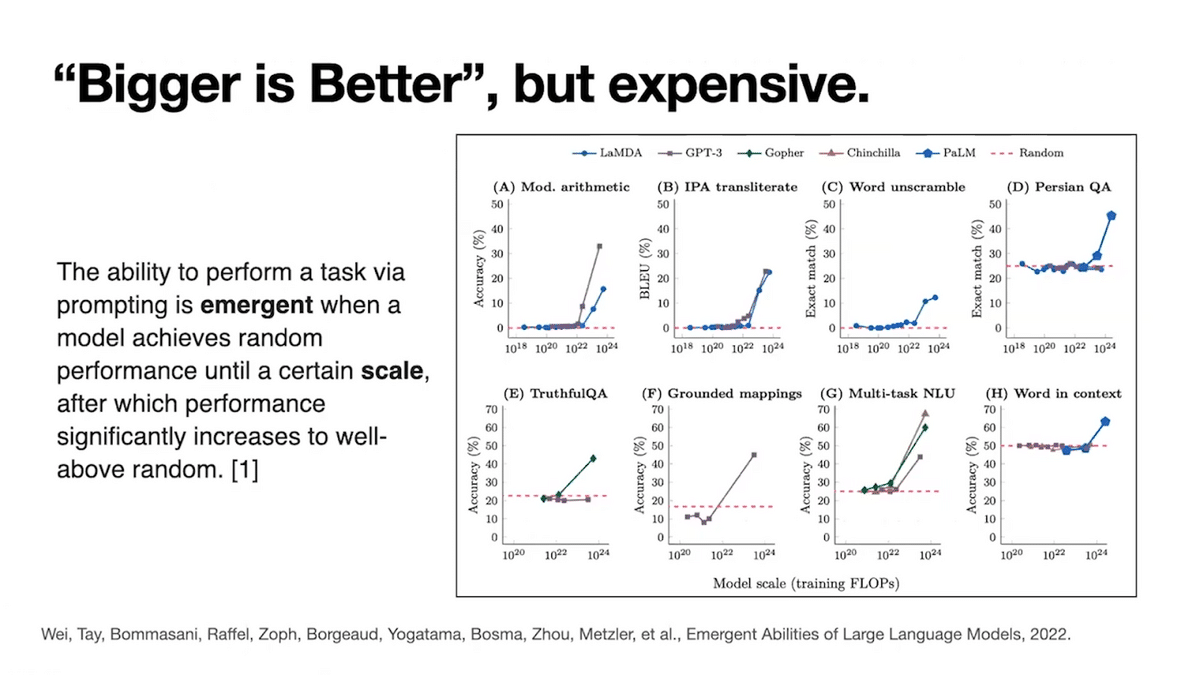
Two, bigger models are better, but less accessible and more costly for many researchers and organizations to train and host.

Three, closed source models are currently ahead—shout out to the HELM work from Stanford’s CRFM—but are expensive to purchase access to. We also typically cannot send private data to model API and there’s low visibility as to how these models are trained. Its suboptimal to perform research over such black boxes.

Four, performance varies widely when we swap out one foundation model for the other in our system. Here, I show results where I take the same exact prompt and two comparably sized models trained by different organizations. The gap in their performance is huge. We need methods that generally improve performance and aren’t just designed around the quirks of one specific foundation model.
All these experiences and challenges we faced in building early systems of foundation models led to the research I’ll focus on for the remainder of this talk—Ask me anything: A simple strategy for prompting language models.
Designing the perfect prompt is difficult. The high level idea in AMA is to apply multiple decent, yet imperfect, prompts to each input example. This means we get multiple votes for the examples labeled. For instance, shown on the far right of this slide, two prompts might vote that the input example is false, and the third might vote that the example is true. We will then aggregate these votes to get our final prediction for our inputs.

The three key questions we report on in this work are, “across tasks and language models, how do we get prompts that are of decent quality?” We need to understand the properties of effective prompts. “How do we generate those effective prompts efficiently at scale?” And, “how do we aggregate the predictions generated by the different prompts reliably?”
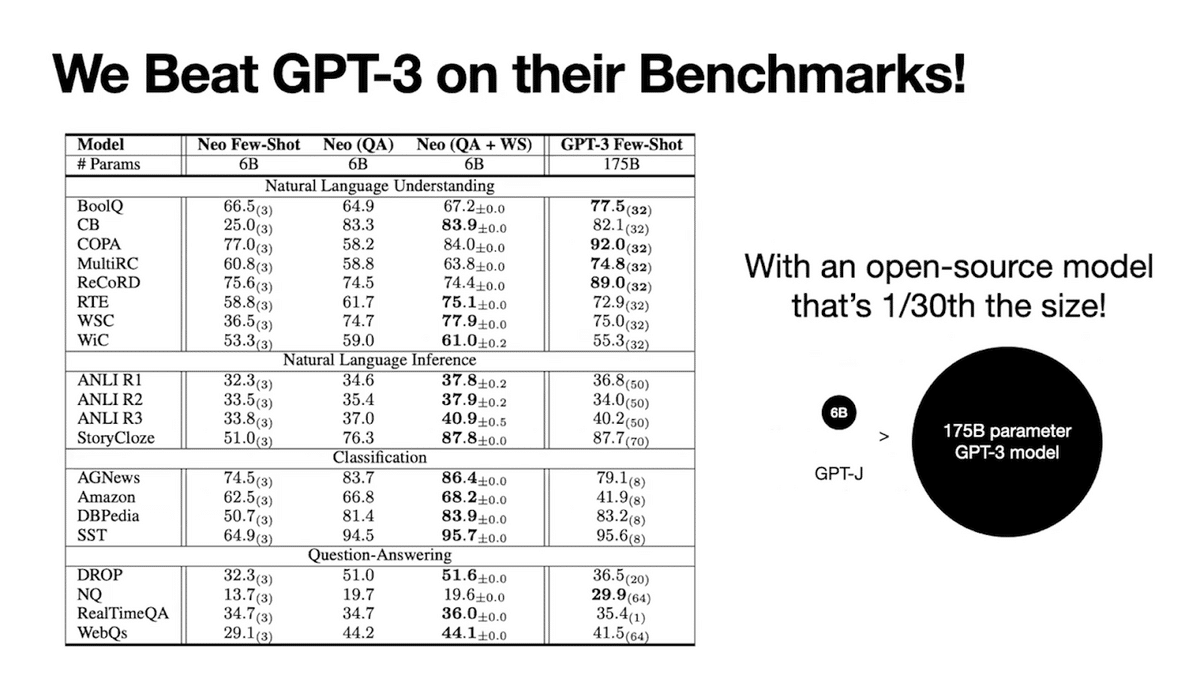
Combining all of these steps, AMA leads to drastic improvements with small open source models. So how do we get here?
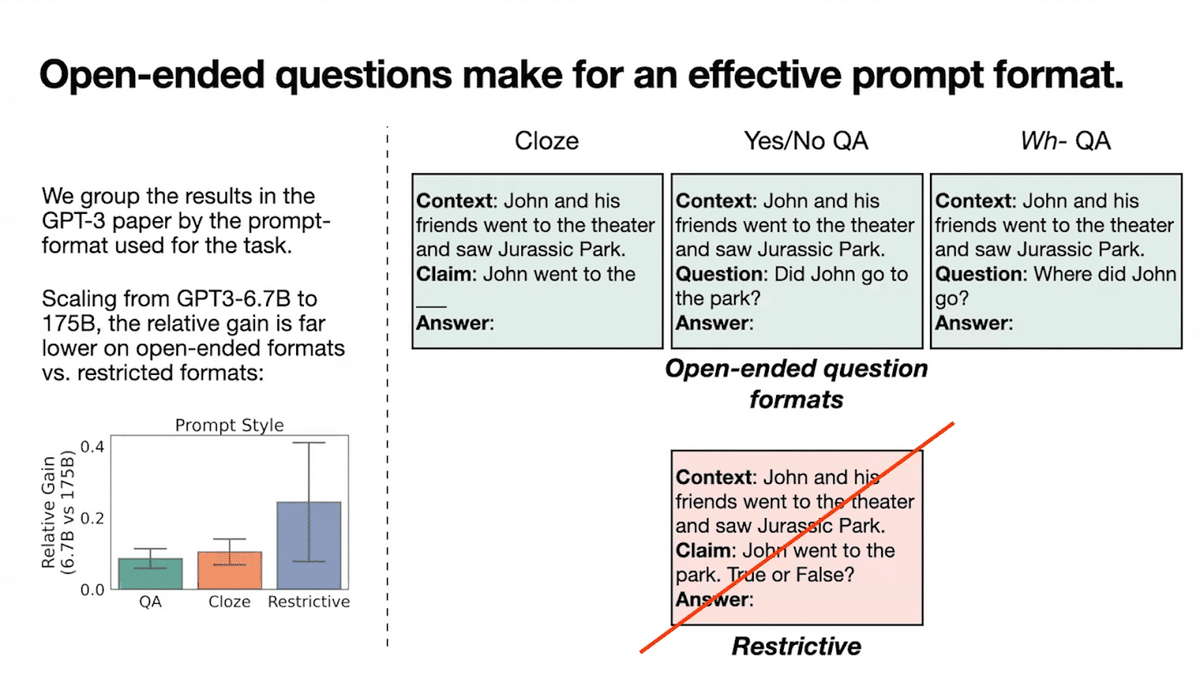
First off, what makes for an effective prompt? To study this question, we start by taking standard prompt formats categorized in OpenAI’s foundational GPT paper.
We find prompts that encourage open-ended answers, such as the prompt “Where did John go” to be more effective than prompts that restrict the model output to specific tokens—for instance, the prompt “John went to the park,” I’ll put the token “true or false”. On the left, we grouped the results from the GPT-3 paper by the prompt format they used for the task, including two types of open-ended formats, namely QA and cloze, and then the restrictive.
The results show the performance improvements that are reaped when we use a 175 billion parameter model instead of the 6 billion parameter model. The gaps between the small and large models are far lower on closed QA open-ended formats in comparison to the restricted category, suggesting language models are trained in a manner that leads them to be effective on open-ended prompt formats.
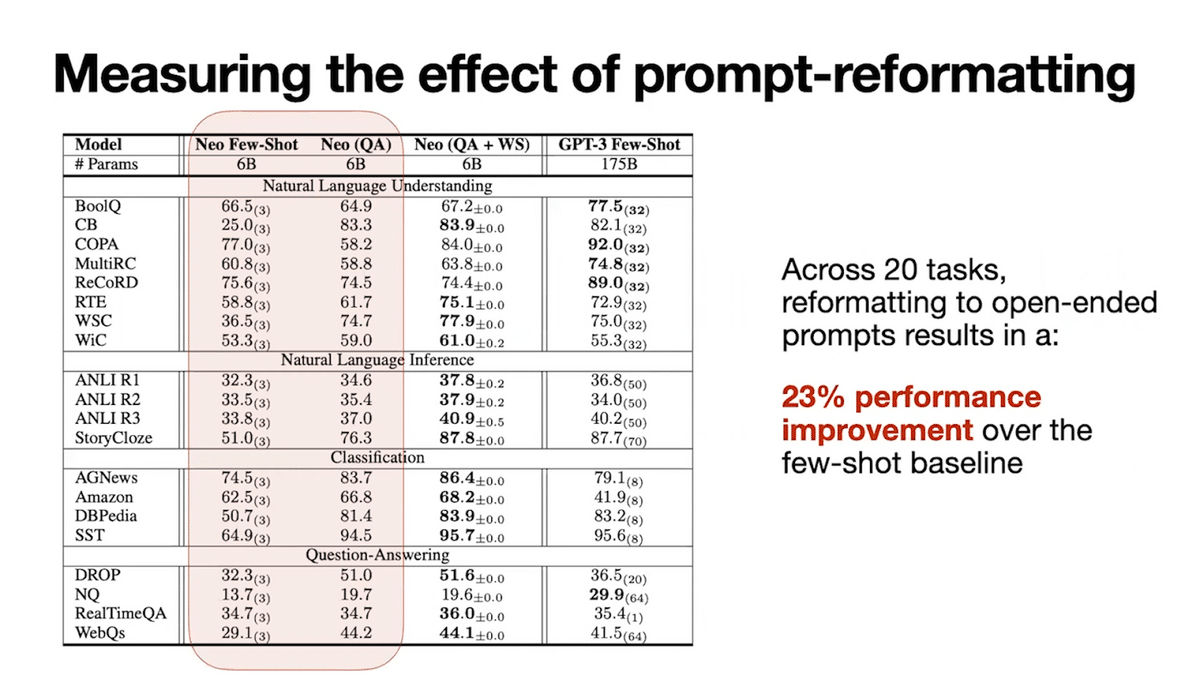
In evaluations across 20 tasks, reformatting the prompts leads to a 23% improvement over the baseline prompted method when using a 6 billion parameter open source model. So open-ended questions are effective, but tasks come in many different diverse formats and have thousands of examples in them. How can we reformat tasks to be effective in open-ended question format?
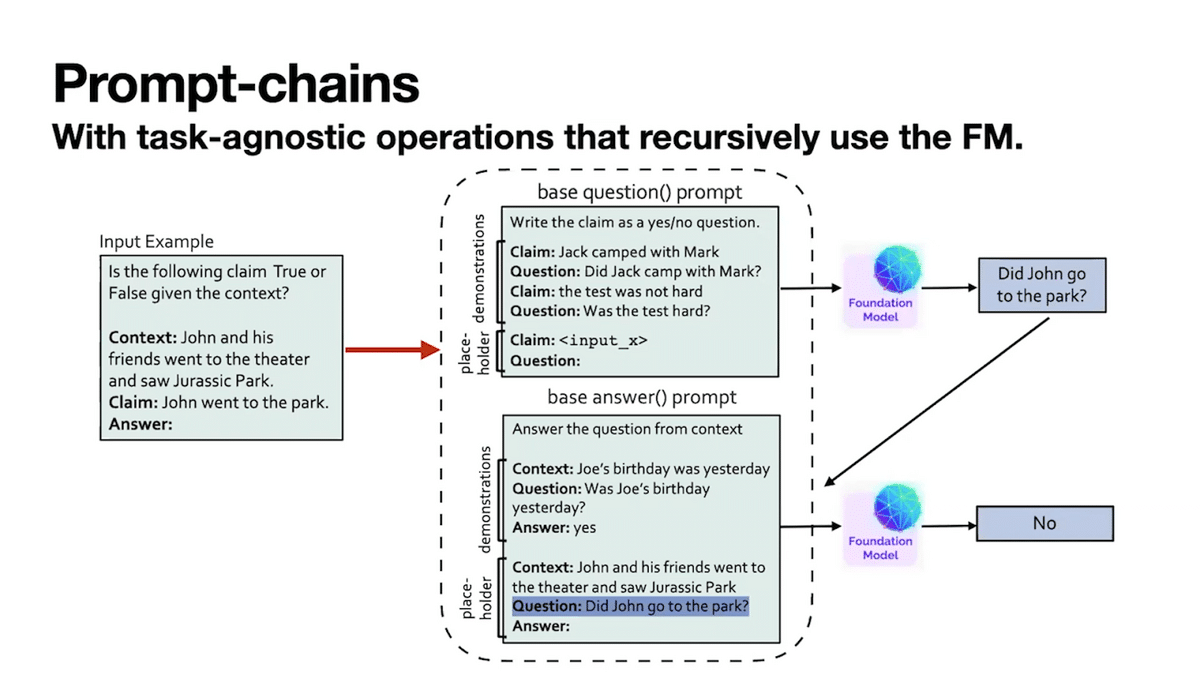
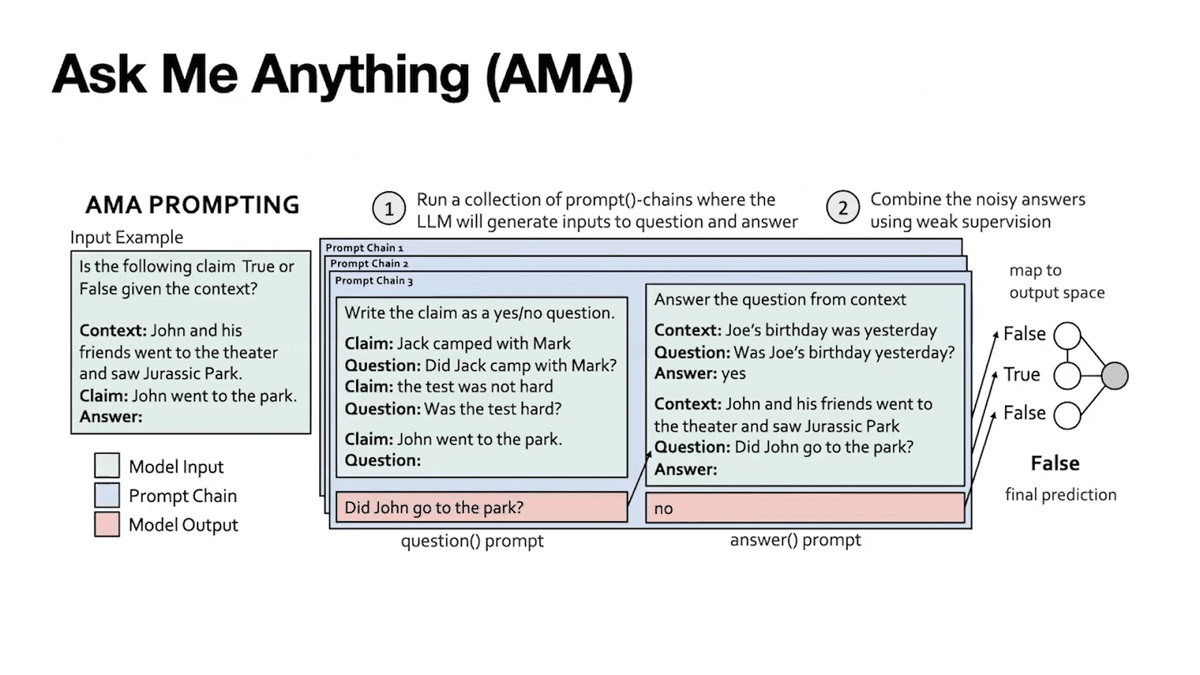
To produce prompts in the effective open-ended format, our insight is to recursively apply the foundation model in what we term a prompt chain. In AMA, the prompt chain includes two task-agnostic operations that are applied to all input examples in all tasks. These are “question generation” and “question-answer”.
Consider the input example asking whether the claim “John went to the park” is true or false, given the context “John saw Jurassic Park at the theater.” First, the question generation step includes a prompt that shows a bunch of generic examples of statement and question pairs. We use these demonstrations in this prompt to get the foundation model to convert our input to an open-ended question. For instance, the statement “John went to the park, true or false,” was converted to the open-ended question, “did John go to the park?” Then, in the second step of the prompt-chain, the answer step uses a prompt with demonstrations of how to answer a question given context. This is applied using the foundation model and the previously generated question to produce our final answer.

Recall our challenge: getting one perfect prompt or prompt chain is painstaking. Different modifications can lead to drastic differences in performance. In AMA, we propose to produce multiple prompt chains so that in aggregate, they tend towards the right answer, even if one prompt makes a mistake. We will apply all of these prompt chains to our task and aggregate over the predictions produced by each of them. So here you can see “did John go to the park?” could also be, “where did John go?”
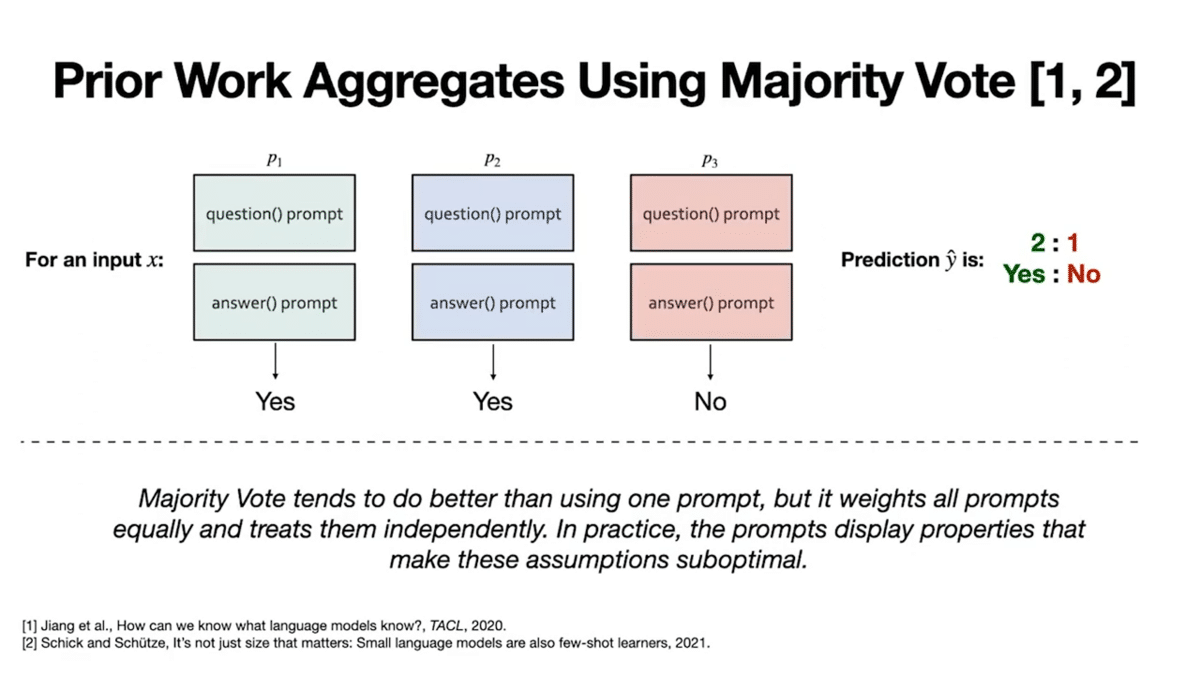
Suppose we have three prompt chains and use these to get three votes on our example, X is true, label y. Prior work aggregates the votes using majority vote, and by simple 2-to-1 majority, we can see that the label “yes” would be chosen for our example X.
Mathematically, majority vote means that all prompts get equal voting power and are treated as independent voters. In our work, we show these assumptions do not hold.
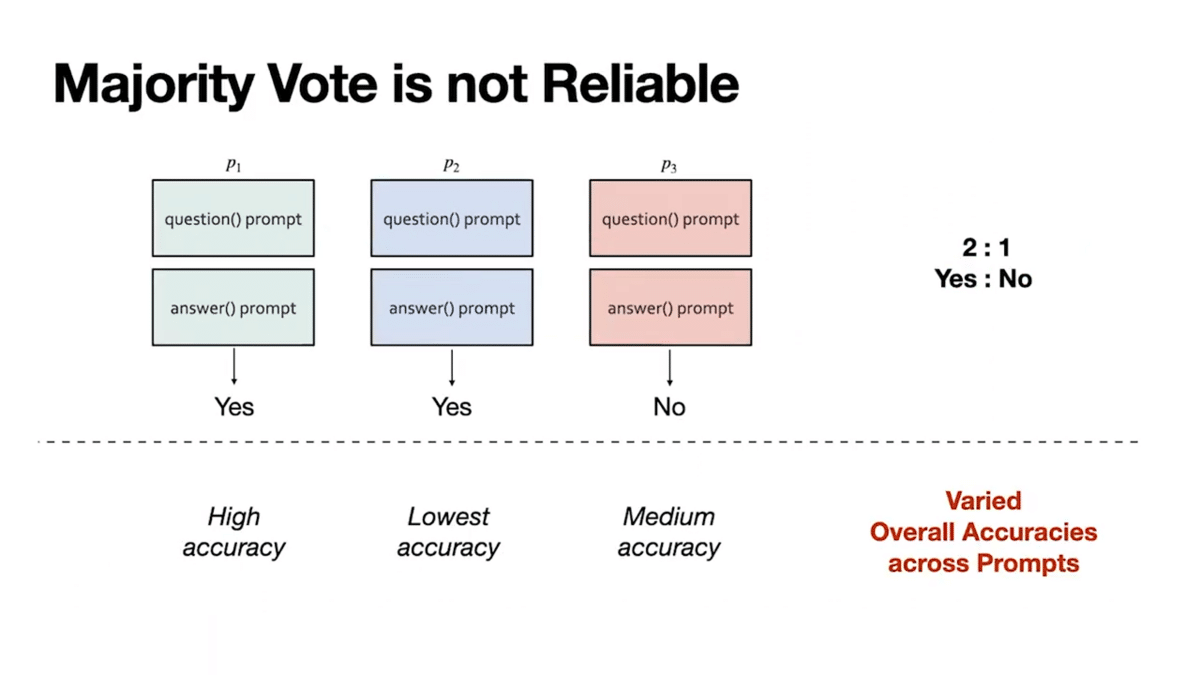
First, different prompts are of different quality. Intuitively, we should weigh the votes of higher-quality prompts more. Breaking it down further, class-conditional accuracies are varied across prompts. What this means is prompt-chain 1 could be really good on the yes class and relatively worse on the no class.
Lastly, prompts can be highly correlated. We show even prompts that are designed to be very different can unexpectedly make predictions in very similar ways. Why does this matter? Say prompt 1 and prompt 2 always vote together and are of lower quality, while prompt three is amazing. If we simply use the majority vote, we will always output the low-quality vote from prompts 1 and 2.
Taking these properties together, we need to model the accuracies and dependencies between the prompt predictions to reliably aggregate. How do we aggregate our voters, then? We’ll turn to weak supervision: a procedure for modeling and combining noisy predictions without any label data. (Shout out to the Snorkel team for leading much of the work we reference here.) We apply weak supervision to prompting broadly for the first time in this work, showing it improves the reliability of prompting with off-the-shelf foundation models and no further training in the setup.
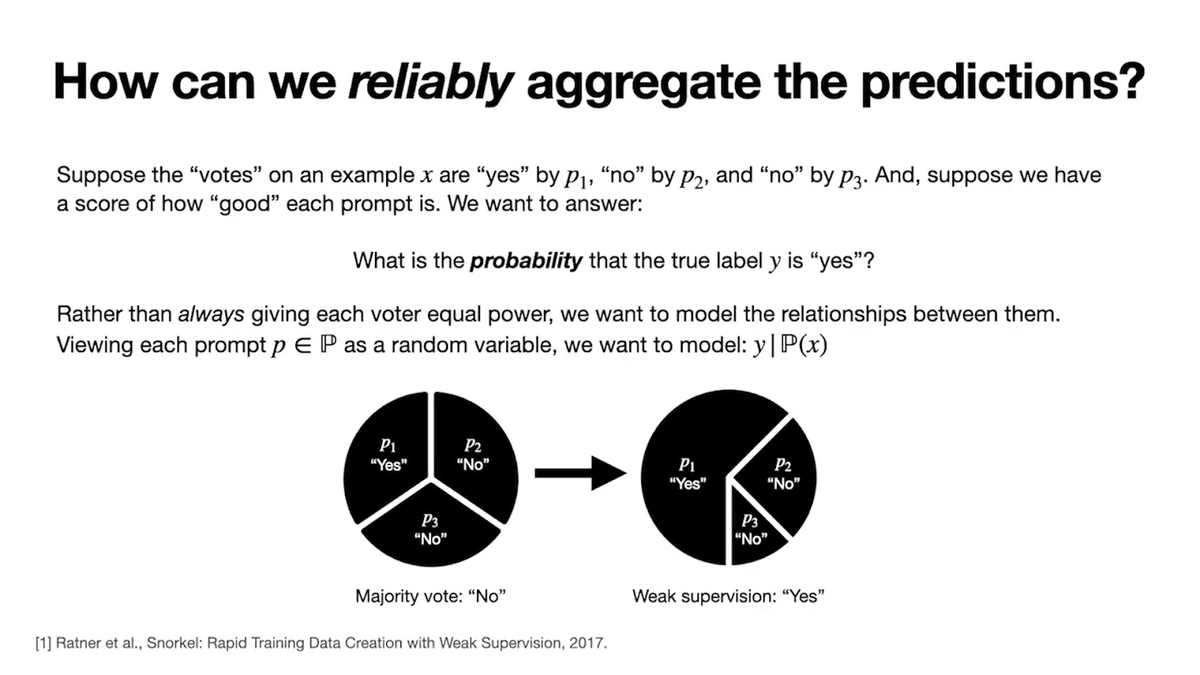
In this setup, we are basically going to take the individual votes from each prompt and come up with a probability on what the true label is. What is the probability, for instance, that the true label for our example is the “yes” class? Treating each prompt as a random variable, we ultimately want to model the probability the true label takes on some value, such as yes or no, conditioned on the sets of votes produced by the set of prompts on the example X.
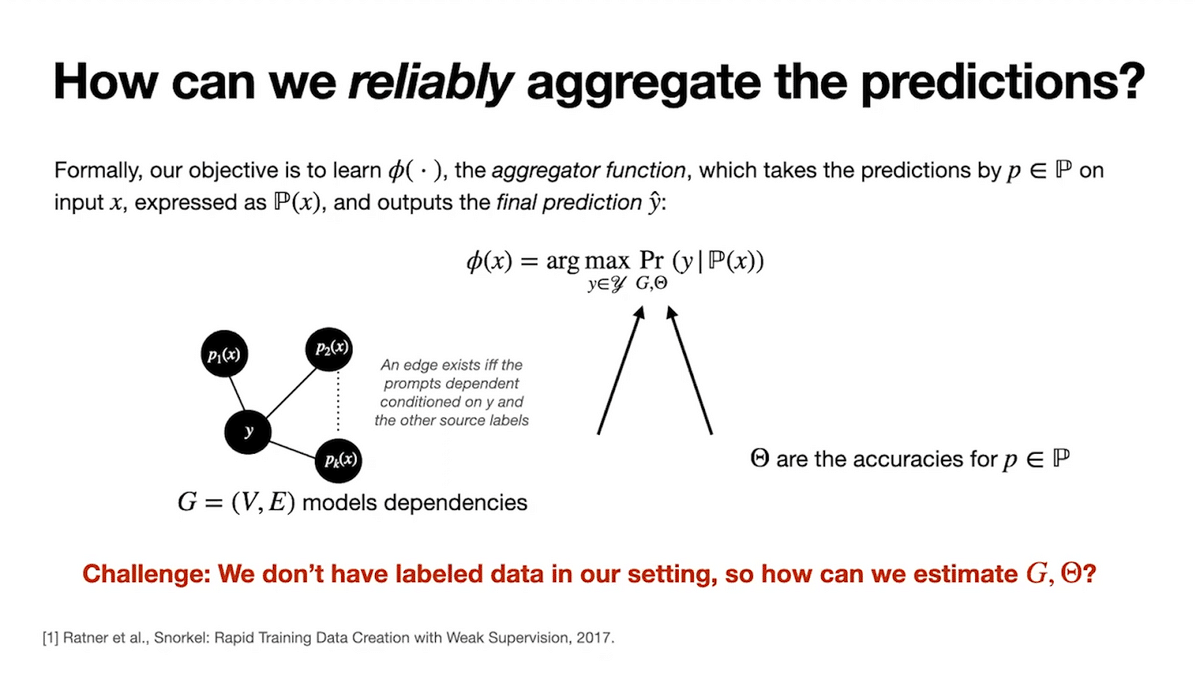
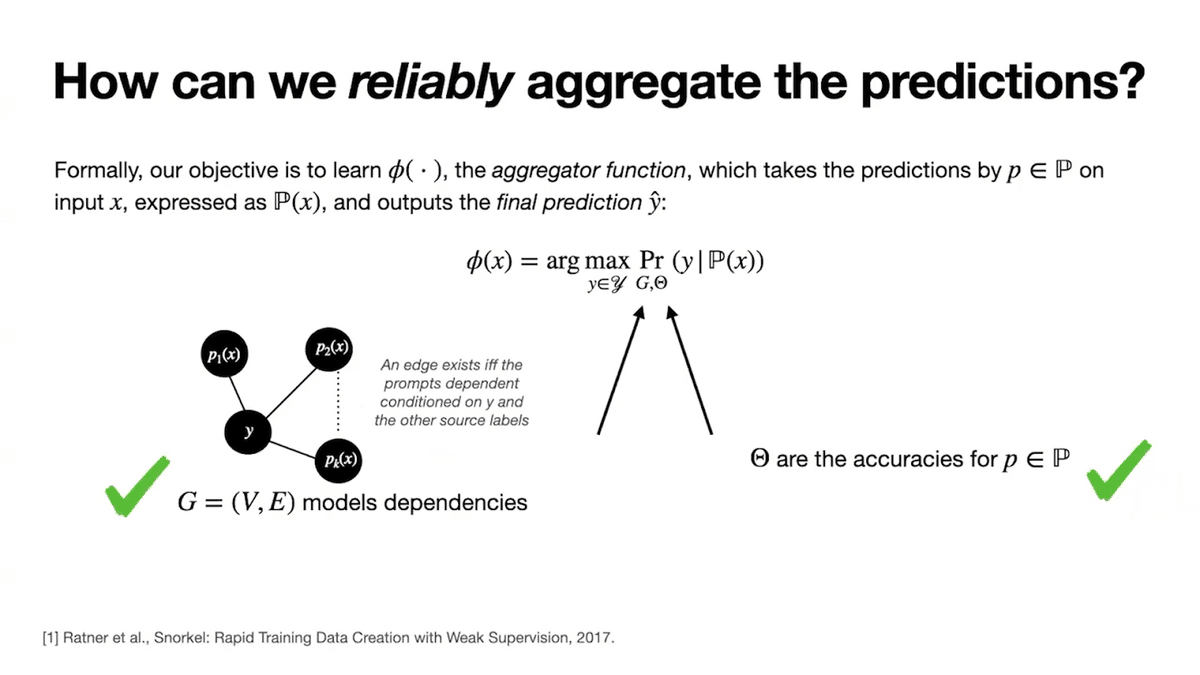
Formally, let Phi (ɸ) be our aggregator function that we want to learn that models our conditional probabilities of interest. Recall that we want Phi (ɸ) to account for:
- The dependencies or correlations between the prompt votes, which is represented by a dependency graph G, and
- The differing accuracies across the prompts, which is represented as Theta (Θ).
We’re going to parametrize our aggregator function by G and Theta (Θ).
The major challenge for us is that we are in this unlabeled regime. How do we actually measure the accuracies of our prompts when we have no labeled data? How can we proceed?

At a high level, we actually just use the available information of how many times Prompt I and Prompt J make the same predictions across examples in the dataset. This gives us a covariance matrix where and treat PI on PJ is the number of times at which Prompt I and Prompt J make the same prediction across task examples in the dataset. Note that part of this covariance matrix is observable and that anything incorporating the random variable for the label Y is unobservable.

Taking this covariance matrix, we can then exploit properties of graphical models and exponential families to actually recover the estimates of the dependency graph G as well as the accuracies Theta (Θ).
Putting it all together, we have our reliable weak supervision-based aggregator function.
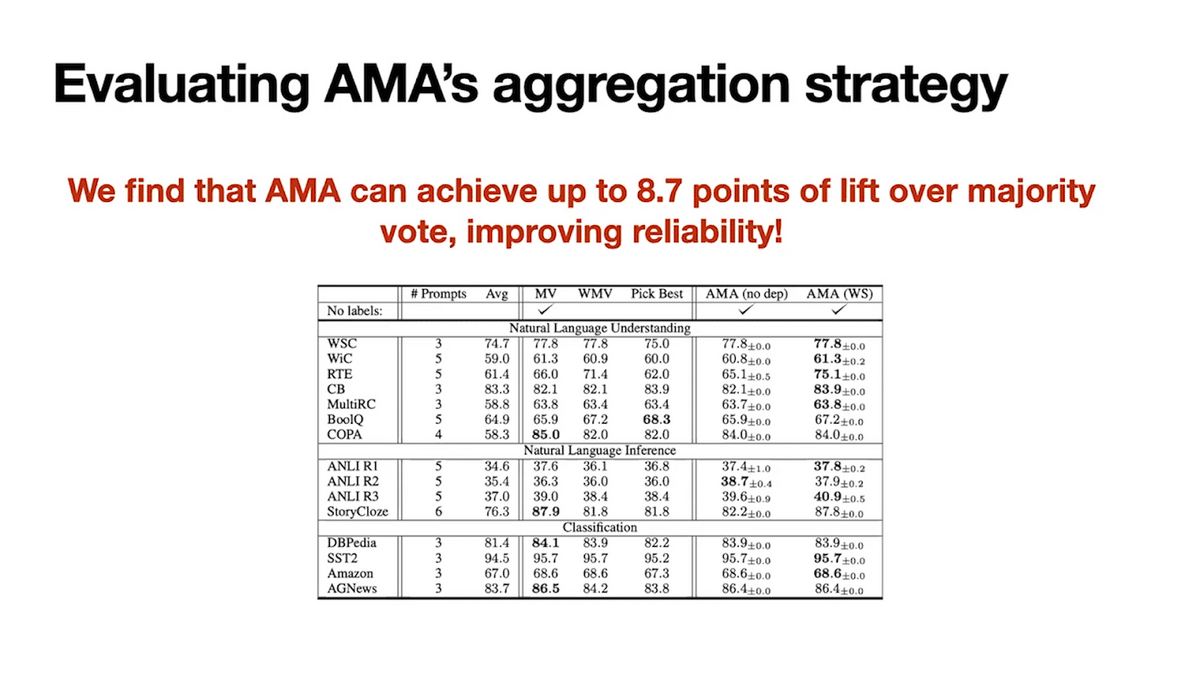
Empirically, we report that weak supervision improves reliability over majority vote. It achieves up to 8.7 points of lift over majority vote in our evaluations.

But one key question is, did we actually need to reformat our prompts at all? Why couldn’t we just use weak supervision on any old prompt and call it a day? To better understand this, we produced multiple prompts in the baseline format from the GPT-3 paper and then take the majority vote prediction across the prompts for aggregation. Performance is 39% lower than AMA. Even if we use weak supervision to aggregate using those baseline prompts, performance is 28% lower than AMA.
What this highlights is end to end, both reformatting and the reliable weak supervision-based aggregation are critical to the method’s success. AMA is inspired by our understanding of how foundation models are trained and the biases this leads to, as well as the principle of mathematical tools.
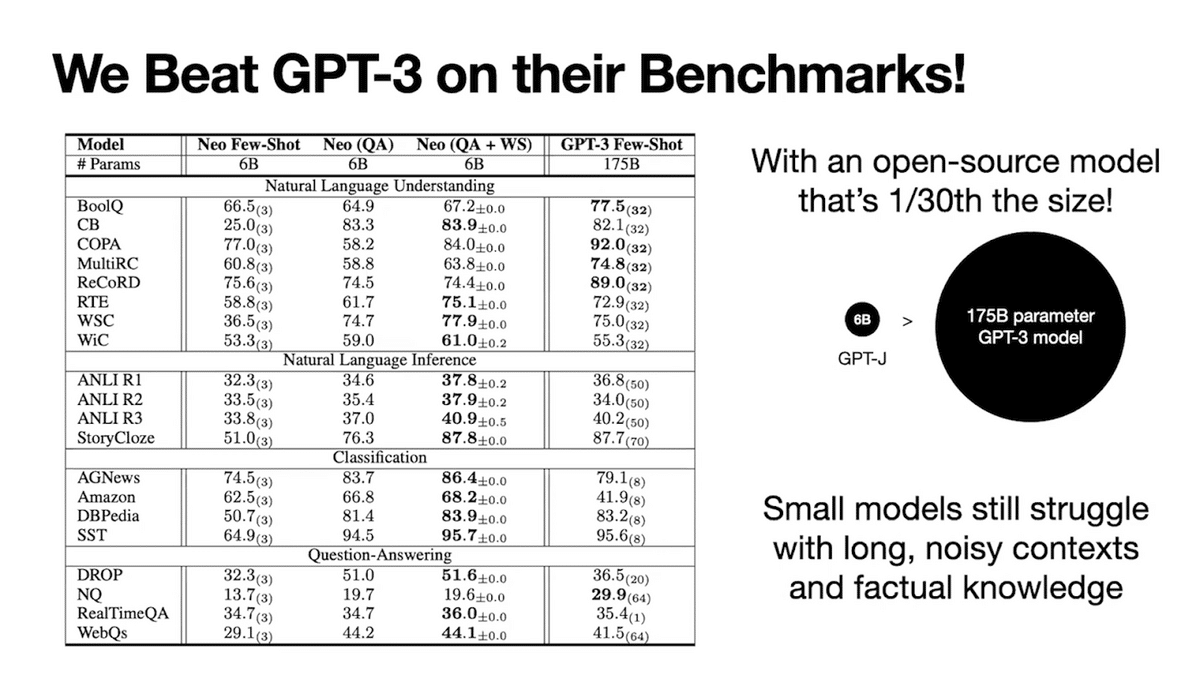
In evaluations, AMA enables an open-source model to outperform open AI’s 30X larger closed-source model on many diverse benchmark tasks.
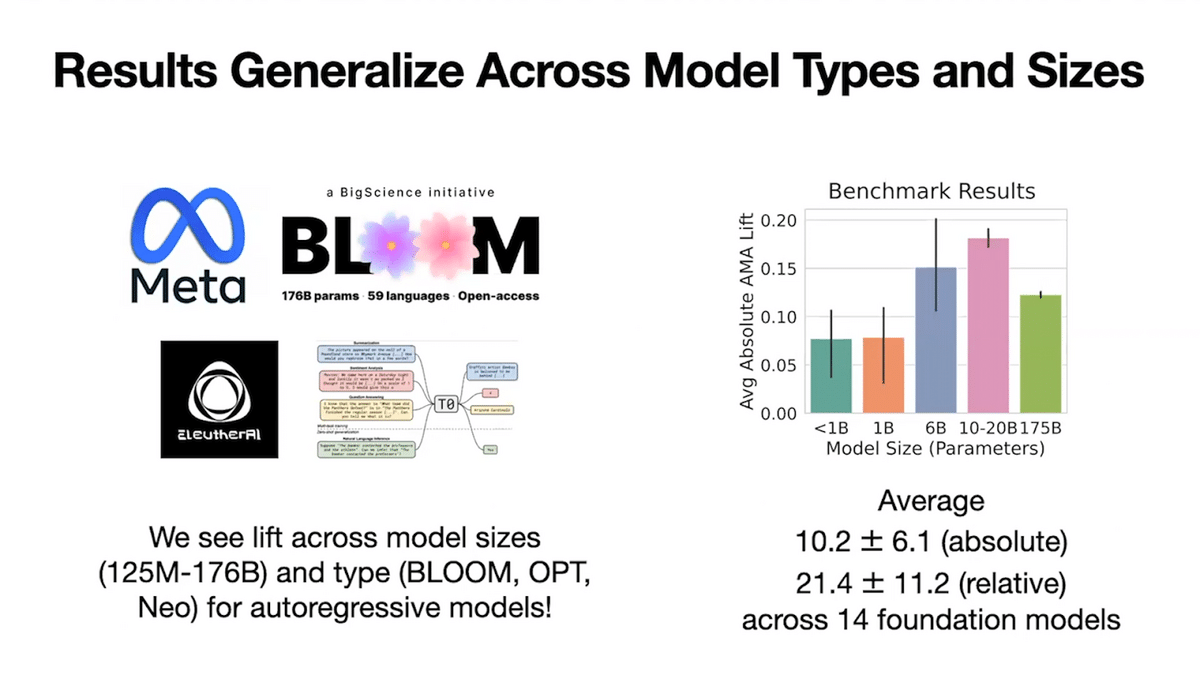
We further show the improvements are general through evaluations on 14 unique language models, ranging from 125 million to 176 billion parameters in size. Though there are still different error modes, which are discussed further in the paper, some of these include the small model’s ability to recover memorized facts on more knowledge-intensive tasks, and the model’s ability to deal with longer contexts. We are excited for future work to continue building our understanding of principled general strategies for using foundation models.

Finally, I wanna give a big thank you to my collaborators, advisor Chris Re, and the groups that supported this work. These collaborators are Avanika, Ines, Laurel, Mayee, Neel and Kush, and organizations include Snorkel, Stanford CRFM, Numbers Station, and Together.
You can find additional resources here:
Code: https://github.com/HazyResearch/ama_prompting
Paper: https://arxiv.org/abs/2210.02441
Blogs: https://hazyresearch.stanford.edu/blog
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.

Recommended articles
View all articles

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•

The Art and Science of Building AI Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build AI benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents with
June 16, 2026
•
Snorkel Team

Cua-Bench: benchmarking computer-use agents on professional software
TL;DR We built a benchmark of 25 expert-authored KiCad schematic-editing tasks and ran a frontier computer-use agent against them. The headline numbers: 1. Why build a computer-use benchmark for electrical engineering? Most computer-use benchmarks today live in the same handful of apps: web browsers, file managers, generic productivity suites. Those evaluations are useful, but they share a structural weakness —
June 15, 2026
•
,

