New Snorkel benchmark leaderboards. See the results.
Applying Weak Supervision Research
ScienceTalks with Paroma Varma
In this episode of Science Talks, Snorkel AI’s Braden Hancock chats with Paroma Varma – a co-founder of Snorkel AI and one of the first and leading contributors to the Snorkel project. We discuss Paroma’s path into machine learning, her work in optimization and signal processing during her undergrad, weak supervision and image data during her Ph.D. at Stanford and her journey with Snorkel AI.
This episode is part of the #ScienceTalks video series hosted by the Snorkel AI team. You can watch the episode here or directly on Youtube:
Below are highlights from the conversation, lightly edited for clarity:
How did you get into machine learning?
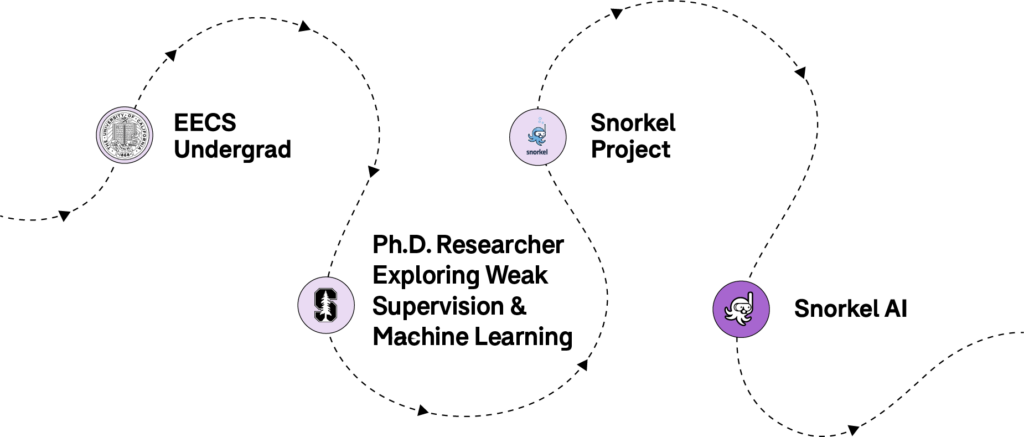
Paroma’s journey into machine learning.
Paroma: I completed my undergrad at The University of California – Berkeley, where I pursued a Bachelor of Science in Electrical Engineering and Computer Science, where I started taking classes in both — I didn’t really consider Machine Learning as something I wanted to do till I got to grad school.Interestingly, the first lab that I worked at during my undergrad was a neuroscience lab with Dr. Robert Knight, where I was applying machine learning to analyze EEG/ECoG data, but I was more focused on the applications and connections to signal processing back then. I eventually started working at Professor Laura Waller’s Computational Imaging Lab, where I had the opportunity to explore applications to imaging as well as connections to other fields like optimization.I started my Ph.D. at Stanford with a similar focus and continued to explore opportunities where there was a close relationship between the theoretical work and practical impact — I don’t remember how, but I ended up learning about Chris Ré’s work, joining his lab, working on Snorkel AI with the now co-founding team – and here I am! Definitely not a path into machine learning that was planned from the beginning.
The Hazy Research Lab at Stanford where Paroma Varma and her co-founding team started Snorkel.
What made you want to pursue a Ph.D.?
Paroma: I decided to pursue a Ph.D. during my junior or senior year. I always enjoyed research and started talking to Professor Waller about the idea of independent research and getting to deep dive into specific topics. I also hung out with graduate students while I was an undergrad, and I felt they were having a ton of fun doing what they wanted to do. So, I thought it would be fun to apply for a Ph.D. It was very different than I had imagined it to be when I applied, but I’m glad I did.
When you think back to a typical day in the life of a Ph.D. student, what comes to mind?
Paroma: Going into the Ph.D., I thought that we, as researchers, spent a lot of our time thinking and brainstorming different ideas, probably because most of my interactions with grad students up till that point had been during that stage.Thinking back, I don’t believe there was one day where I could describe that it would represent the years throughout the Ph.D., maybe other than getting coffee every day. There were different “types” of days — brainstorming, fun whiteboard discussions, and then coding, doing various experiments, keeping track of what is working and especially what is not working and why, and last but definitely not least, writing and communicating your ideas — which is such an important skill to have.Pursuing a Ph.D. is incredible because it forces you to go through all these different phases and sharpen your skills in every single one. I’m incredibly grateful I went through that experience and got to learn from a group of amazing people.
What were some of the challenges you faced while applying weak supervision to images?
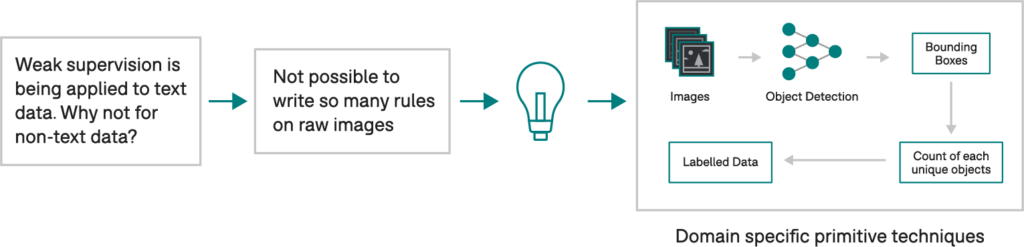
A representation of the challenges of weak supervision in non-text data.
Paroma: When I first joined the lab, the team was exploring applications of weak supervision to text data, where users could write heuristics, or labeling functions, using regex patterns, keyword searches, parts of speech tags, etc. Given that most of my experience was with image and video data, I wanted to apply a similar technique to that domain, but the first blocker I hit was that you couldn’t write interpretable rules over raw pixel values of images.Imagine that we are trying to identify how many people are riding a bike. Describing anything related to that over the RGB values of the pixel wouldn’t work. So, one of the first steps that we came up with was defining what we call domain-specific primitives 1, essentially interpretable characteristics, or building blocks of data, allowing you to write rules as you could do for text.To access domain-specific primitives for image, video, and other non-text data modalities, we could take advantage of a lot of the work done in the past, such as image processing pipelines that extract regions of interest and characteristics like area and eccentricity. We could also rely on existing ML models, such as object detectors, to get bounding boxes and write rules to say count objects or define the spatial relationship among objects.We eventually ended up applying these techniques to unblock a variety of applications — identifying abnormal heart valve structure using MRI data. This collaboration was published in Nature Communications 2, enriching an existing visual knowledge base 3 used for various state-of-the-art computer vision models and more. The chance to collaborate with multiple groups within and outside of Snorkel to continue refining this idea was wonderful.
Another project you worked on was Snuba to “automate” weak supervision. Where does that make more or less sense as an approach?
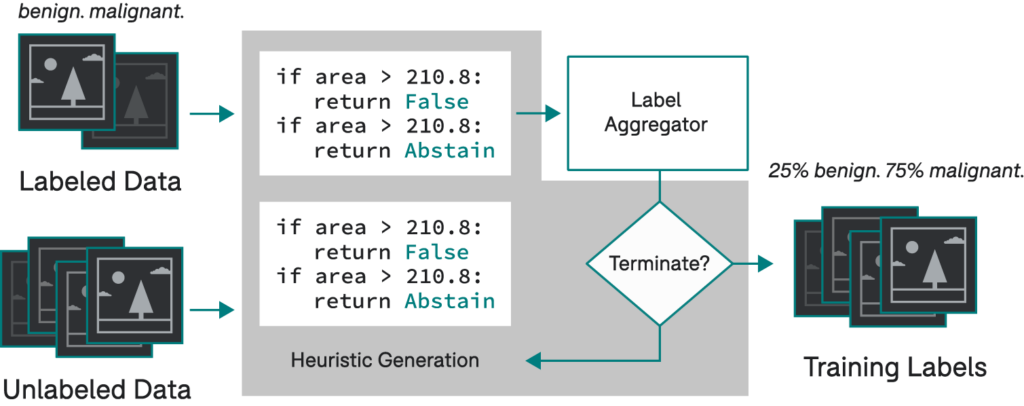
Snuba used a small labeled and a large unlabeled dataset to generate heuristics iteratively. Using existing label aggregators to assign training labels to the large dataset 4.
Paroma: Snuba is one of the projects I wanted to work on because the motivation and pain points were something I experienced directly. For example, developing labeling functions over domain-specific primitives for image and video data often meant writing conditional statements that relied on numerical thresholds. Meaning, a lot of our time was going into guessing and checking different numbers, something that felt like we could automate.The second inspiration came from one of your projects, Babble Labble 5, which looked at how we can take natural language explanations and then convert that into weak supervision signals. This idea of making it easier for people to encode their knowledge and code weak supervision for machine learning lowered the barrier even more.When I started working on Snuba, I was very focused on image and video data, where the majority of the domain-specific primitives were numerical, and automating LF development worked well in that area. It didn’t work as well with text since automated functions of the form I explored were not rich enough to capture signals that users can.Reflecting back, I would say that it is challenging to replace domain expertise completely. The ideal solution is to inject the domain expertise and then automate different parts of this pipeline while also ensuring that the human knowledge and domain expertise are still somehow injected into your system.
What are the benefits of an end-to-end AI pipeline?
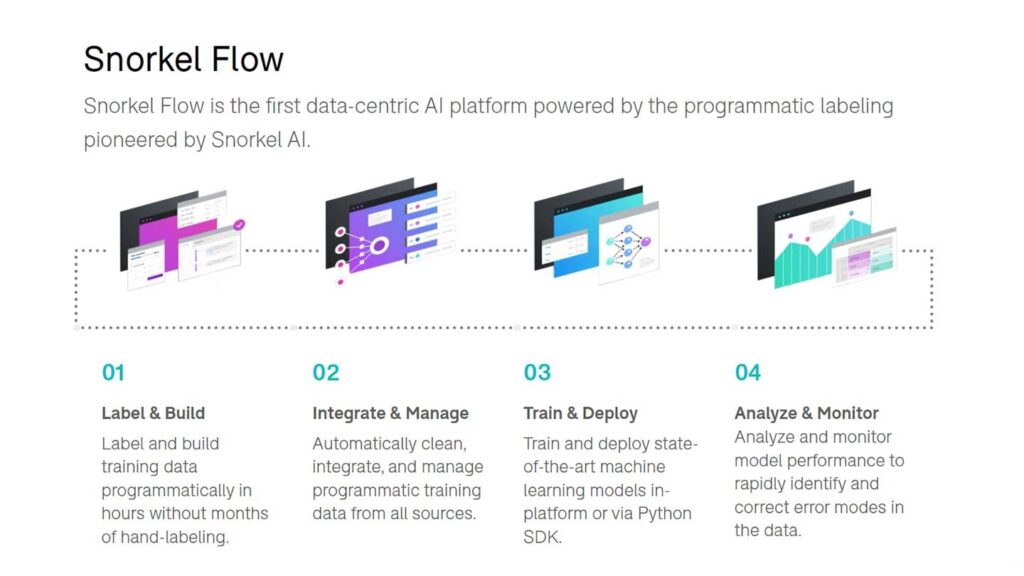
The end-to-end pipeline of Snorkel Flow.
Paroma: One of the most amazing things about what we’re building at Snorkel AI now is the fact that Snorkel Flow is an end-to-end way of iteratively developing your machine learning pipelines. You’re never done after just training a model once. You always have to keep monitoring and analyzing. The biggest thing that Snorkel Flow does is make this error analysis monitoring a lot more automated and everything within one area, which is the real power of what we’re building now.Training data is still the first blocker that we hit, but we also have the rest of the pipeline within the platform. What that means is, when you’re fixing your model with guided error analysis, you know exactly where to look next. For example, go back to your weak supervision signals or model building or specific subsets of data that are important. The end-to-end aspect makes the error analysis much more accessible, supporting the fact that building these ML pipelines is genuinely an iterative process.Much of the work we were doing, especially with image data, was with radiologists who are subject matter experts, and I was trying to look at this from a data science perspective. We have done the same thing with Snorkel Flow, an excellent tool for people from different backgrounds to come together and tackle the task. The entire platform is UI-based but also has an SDK for maximal flexibility.
What is your favorite part about Snorkel AI?
Paroma: My favorite part is that Snorkel AI is full of fantastic people — I know it sounds cheesy, but it’s true, I do get to learn something new every single day. It is incredible watching the team grow and getting to know and learn from each of them. And even now, with remote work, we have done a great job ensuring that we stay a tight-knit group — virtual hangouts and events, game nights, it’s a really fun group! The fact that everyone is so passionate about what they are building replenishes my passion. It has and continues to be a wonderful experience that I’m incredibly grateful for.Where to follow Paroma: Website, Twitter, Linkedin, Github.Please don’t forget to subscribe to our YouTube channel for future ScienceTalks or follow us on Twitter, Linkedin, Facebook, or Instagram.
1 Inferring generative model structure with static analysis, Paroma Varma, Bryan He, Payal Bajaj, Nishith Khandwala, Imon Banerjee, Daniel Rubin, Christopher Ré, Proceedings Of The 31St International Conference On Neural Information Processing Systems”. 2021. Dl.Acm.Org. https://dl.acm.org/doi/10.5555/3294771.3294794
2 Weakly supervised classification of aortic valve malformations using unlabeled cardiac MRI sequences, Jason A. Fries, Paroma Varma, Vincent S. Chen, Ke Xiao, Heliodoro Tejeda, Priyanka Saha, Jared Dunnmon, Henry Chubb, Shiraz Maskatia, Madalina Fiterau, Scott Delp, Euan Ashley, Christopher Ré & James R. Priest, Nature Communications 10 (1). doi:10.1038/s41467-019-11012-3. https://www.nature.com/articles/s41467-019-11012-3
3 Scene Graph Prediction with Limited Labels, Vincent S. Chen, Paroma Varma, Ranjay Krishna, Michael Bernstein, Christopher Re, Li Fei-Fei, Stanford University, https://openaccess.thecvf.com/content_ICCV_2019/papers/Chen_Scene_Graph_Prediction_With_Limited_Labels_ICCV_2019_paper.pdf
4 Snuba: Automating Weak Supervision to Label Training Data, Paroma Varma, Christopher Re, Stanford University, http://www.vldb.org/pvldb/vol12/p223-varma.pdf
5 Training Classifiers with Natural Language Explanations, Braden Hancock, Paroma Varma, Stephanie Wang, Martin Bringmann, Percy Liang, Christopher Ré, ACL Anthology, https://aclanthology.org/P18-1175/

Team Snorkel