
In this episode of Science Talks, Snorkel AI’s Paroma Varma chats with Frederic Sala – an assistant professor of Computer Science at the University of Wisconsin Madison and a research scientist at Snorkel. We discuss with Fred his path into machine learning, the central thesis that ties together his multidisciplinary research, his thoughts on the future of weak supervision, as well as his decision to go into academia.
This episode is part of the #ScienceTalks video series hosted by the Snorkel AI team. You can watch the episode here:
Below are highlights from the conversation, lightly edited for clarity:
How did you get into machine learning?
Fred: In my undergraduate a decade ago, I studied information theory – the beautiful science of how to communicate information, how to transfer it efficiently, and how to deal with noise. It’s a natural field to go into if you are excited about the information age.
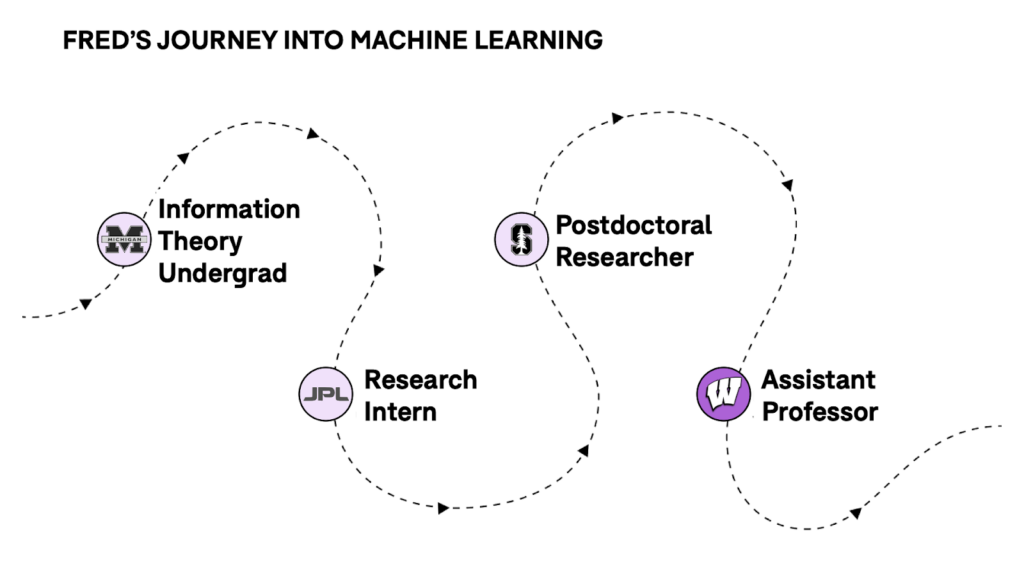
The first real aspect of information theory was the Morse code that happened one and a half centuries ago. This was the first time when people tried to encode information efficiently. It took up until the 1940s and 1950s for the field to be created, all thanks to Claude Shannon. Everything else that we have been doing since then has been filling in the footnotes and details.
I worked on making information memory more efficient by correcting noise, which was fun because it’s basically about dealing with communication through time. For example, if you record the information on your hard drive, you want to come back a decade later and ensure that the information is still there. As I was working on these problems of protecting memories from errors, I realized that noise is everywhere in the data to start with, and it didn’t always make sense for us to protect the data from noise.
Why do we care if the data is noisy?
We already do noisy things like Stochastic Gradient Descent to learn our models in machine learning. And then, we expect our models to be robust to some amount of noise. Thus, I aimed to make information theory and machine learning cooperate so we don’t have to give up our bandwidth to protect ourselves from the noise we don’t care about.
In terms of working with Chris Re, I observed that his lab had people with very diverse backgrounds: mechanical engineering, mathematics, and even music performance. I became excited about the possibility of collaborating with folks who approach problems from different perspectives. Furthermore, as I chatted with Chris about some work I was doing that involves a math tool called a generating function, he immediately understood that very esoteric problem. Then, it became a natural choice for me to work in his lab.
What connects theoretical and empirical aspects of machine learning?
Fred: The theory of machine learning is not quite as esoteric as the theory in math, which tends to be relatively obscure. At the same time, even though machine learning is an empirical field, we are still looking to understand the fundamentals and push the limits for its theoretical underpinnings. So both the theoretical and the empirical aspects inform each other, which is the best scenario in this case.
Weak supervision is an example where the theory helps us in practice, which creates new questions for the theory to answer, repeating this cycle continuously. Both of us have worked quite a bit on that. For example, during our project that applied weak supervision to video understanding, none of our existing methods could scale up to what was required for weak supervision to work in practice. But then we realized that we could do all kinds of crazy theoretical work to make that happen.

What is the next big thing for weak supervision?
Fred: Snorkel has been working on classification problems and getting better results at them across many domains. An area that I’m curious to explore is making weak supervision perform well for regression problems, which will cover many different kinds of tasks out there that we have yet to tackle.
I’m also excited about the multi-domain, multi-task, multi-everything approach to weak supervision. We would like to scale up to diverse tasks and handle any system that we are thrown into. In general, making weak supervision work well for massively multi-task kind of problem is something that we have been working on for quite a while.
How did you become interested in causal inference and information coding?
Fred: What’s common for these different threads is their data limitations.
- In weak supervision, we either don’t have the labels, or it’s too expensive to gather them.
- In causal inference, we don’t know the causal direction of the variables in the data. We only get to see the co-occurrence or correlations between those variables. Thus we need to deal with the lack of knowledge of the causal direction using other means.
- In information embedding, the data is not in the format that we can directly use for all the models. Maybe the data is not encoded in vectors or matrices, but in relationships between objects. Thus, we have to figure out how to encode the data in a friendly way for machine learning.
Why did you decide to go into academia?
Fred: There’s the classic answer in which you have more freedom to study some particular problems in academia than you would in industry. I believe that there’s a gradient where you can find the right trade-off for yourself – in terms of (1) how much freedom that you want to have and (2) how much influence that you want to impose on the world.
For me, the most exciting thing about academia is the opportunity to work with young people. Something is very energizing about that. It’s fun to see ambitious and enthusiastic students who come in. They have not gotten to the point where they can research independently. They don’t necessarily know all of these different fields. Shaping their research trajectory and seeing them grow intellectually is what I genuinely enjoy.
Finally, academia is similar to the startup world because you have to set things up from the beginning. You need to start a lab from scratch and fully understand the challenges that come with that. Then, to differentiate yourself from other researchers, you want to figure out the right people to work with and ask for advice from people who have experienced this journey.
What would your alternative career be?
Fred: I always like the idea of being an architect because it’s this nice combination of science and art. You get to build cool buildings as a form of self-expression, but you also need to follow engineering rules so that the buildings do not collapse. It’s also a much more competitive career than machine learning, so that’s a good reason why I did not pursue that path.
What have you been reading lately?
“How Democracies Die” by Steven Levitsky and Daniel Ziblatt

Where To Follow Fred: Twitter | Google Scholar | Academic PageAnd don’t forget to subscribe to our YouTube channel for future ScienceTalks or follow us on Twitter!

Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

