
Three experts from Capital One’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. Erin Babinsky, Director of Data Science, Bayan Bruss, Senior Director of Applied Machine Learning and Research, and Kishore Mosaliganti, Head of Data and Machine Learning, discussed their team’s data-centric approach to solving problems. A transcript of their discussion follows, lightly edited for readability.
Piyush Puri: Please join me in welcoming to the stage our next speakers who are here to talk about data-centric AI at Capital One, the amazing team who may or may not have coined the term, “what’s in your wallet.”
Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of Data Science, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Great to have you all here and really excited for the discussion and I’ll leave it to you all. Thanks Erin.
Erin Babinski: Thank you all and thank you, Piyush, for that welcome. Thank you all for attending this talk. It’s wonderful to be here. My name is Erin Babinski and I’m a data scientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI.
I’m going to kick things off, and go high level. Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community.

All right, so let’s set the stage first with some examples: a focus on data quality leads to better ML-powered products. Think of a time when you felt surprised and delighted when your music app served up a suggested playlist that was right on point, or when your streaming service recommended a movie that deeply moved you, or a time when you were searching for a unique gift for that friend who’s impossible to shop for, and the perfect item appeared in a carousel of recommended products. The magic behind these experiences is most often attributed to artificial intelligence and machine learning. What can get less attention is the foundational element of what makes AI and ML shine. That’s why we’re all here. That’s data.

At Capital One, real-time intelligent experiences are enabling and empowering our customers. AI, ML, and data are central to how we build our products and services for customers and to how we run our company. These elements are at the core of our focus to better understand customer needs and deliver truly personalized experiences.
For example, when customers log onto our website or mobile app, our conversational AI capabilities can help find the information they may want. The same applies for buying a car with Capital One. Using our Capital One navigator, the customer starts interacting with the website or app and the models behind our car-buying engines start to learn in real time what the customer may be looking for.
Overall, the magic behind these experiences is most often attributed to AI and ML, but really, to double-click on this one, it’s also critically about the data. Data is the air businesses breathe.
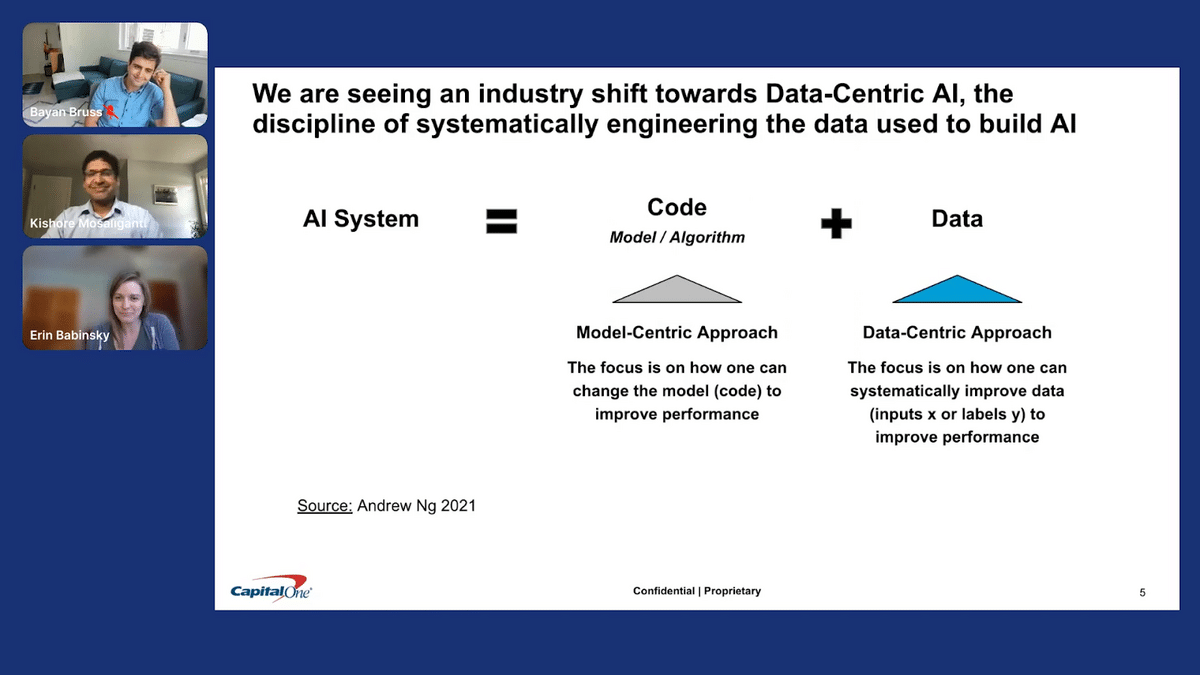
We are seeing an industry shift toward data-centric AI, the discipline of systematically engineering the data used to build AI.
To borrow a framework from Andrew Ng, we can think of AI systems as code + data. Traditionally, a model-centric approach focused on how one can change the model to improve performance via the code. Now, we still do this. We care about the model. But we also see leverage in the data. We are leaning into the data-centric approach where the focus is on how one can systematically improve data, inputs X and labels Y, to improve performance.
This is really the fun part. In an academic sense, we can think about systematically improving our inputs and labels in a lot of different ways. The trick is also, in the application sense: what do we do? What’s the most important?

The idea of improving data to achieve better ML outcomes is not new, but it’s getting traction with better tools and processes. We’ll be talking a bit more about that. Bayan will also introduce one of those tools that we’re developing in-house that’s open source, but we can take a look at the recent milestones and evolution of AI. Compute, big data, large commoditized models—all important stages. But now we’re entering a period where data investments have massive returns from all performance as well as business impact. And I believe Andrew Ng also said that this is going to be the decade of data-centric AI. We’re really leaning into that thought leadership there.
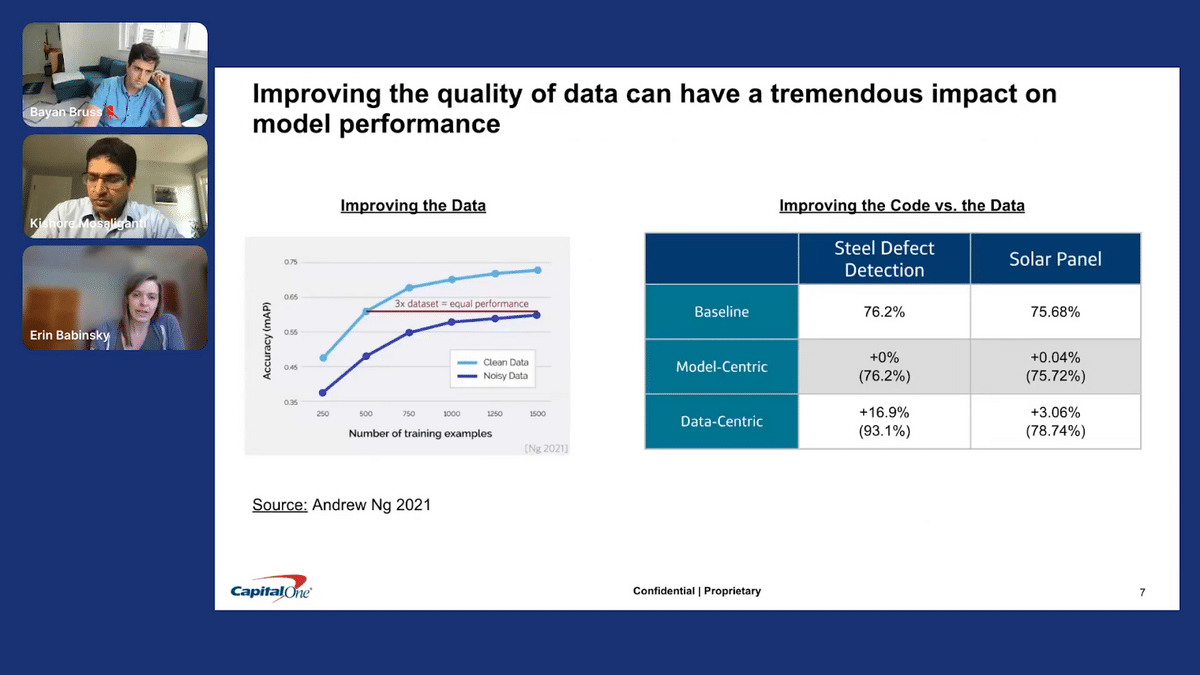
To borrow another example from Andrew Ng, improving the quality of data can have a tremendous impact on model performance. This is to say that clean data can better teach our models. Another benefit of clean, informative data is that we may also be able to achieve equivalent model performance with much less data. This is powerful if you imagine we’re training ML solutions with millions of data points, and we need to adapt those models over time.
These are all important pieces that really set the stage. For a lot of folks, it may not be new, but for other folks it’s important that we lean into these foundational elements and the thought leadership of the folks who’ve gotten us to this point, including Andrew Ng.
I’m gonna hand off to Kishore now to talk more about some of the opportunities we see within our world.

Kishore Mosaliganti: Thank you, Erin. Hello everyone. This is Kishore Mosaliganti. I’m an AI lead in Capital One’s Enterprise Products and Experience Team. As Erin articulated, data-centric AI has a big emphasis on labeled data, cleaning up that data, making it more consistent, accurate, and higher quality.
Now, while labeled data is important for training a model and achieving strong performance numbers, a less emphasized aspect is the quality of input data flowing into the model. Think of this as the X and not just the X-not, and Y-not. At Capital One, we believe that improving X can improve model performance, which is not what the math and the cost function says, for example. We believe that improving the quality of our data ecosystem overall can pay rich dividends in terms of delivering intelligent, real-time products and solutions.
For a moment, just consider the typical ML lifecycle from end to end. It starts with defining the model intent, sourcing and prepping the data, verifying the data in terms of its quality and version control, the lineage of that data, the latency of reporting, doing some exploratory data analysis to gain insights, creating and storing features, assembling labeled datasets, training the model, iterating to evaluate the performance of the model, and then finally, deploying the model.

It comes as no surprise that in most companies, data science teams spend more than 50 to 80 percent of their end-to-end development time on the data prep stage. That is a staggering statistic—50 to 80 percent of the end-to-end time is in data prep. The reason is that most teams do not have access to a robust data ecosystem for ML development. Recent research published in the Harvard Business Review in 2018 suggests that nearly $31.5 billion is lost by Fortune 500 companies because of broken data pipelines and communications. A lot of problems get solved repeatedly, and duplicative work is done. If you think about the upstream platform and data teams, they do not consider data as a product, essentially, and data scientists as their end consumers. Publishing standards for data and governance of that data is either missing or very widely far from an ideal.
The end result is that data science work is duplicated and a lot of data science teams end up doing non-DS work in order to assemble strong data pipelines, leaving them with very little time to focus on innovation, via feature engineering or model selection, and therefore lower performance. This is not very obvious if you just focus on the math.

At Capital One we also believe that our data lifecycle needs to meet the needs of the ML lifecycle. Our data teams focus on three important processes. First, data standardization, then providing model-ready data for data scientists, and then ensuring there’s strong data governance and monitoring solutions and tools in place.
Standardization refers to data publishing standards that make sure that data attributes align with a naming convention or an ontology, that they have descriptions that are interpretable, and that datasets are standardized, especially when coming from different sources, and that there are good search and discovery tools in the ecosystem to automatically find and use relevant data.
Model-ready data refers to a feature library. For example, where verified data is present, the latencies are quantified. It enables users to aggregate, compute, and transform data in some scripted way, thereby promoting feature engineering, innovation, and reuse of data.
Data governance and monitoring. These teams focus on ensuring data is monitored for drift, either in terms of its schema or the data itself. They make sure the data has a verifiable lineage and present some latency guarantees for downstream use. Together, these data ops efforts ensure that model development time is efficient, model performance is robust, and teams focus more on innovation and customer experience, which is what matters.
Now I’m going to pass it on to Bayan, who’s going to focus on another very important aspect of data, which is variability and explainability.
Bayan Bruss: Thanks Kishore.

The way I like to think about building models is somewhat like building a car. You have a car and you’re in a factory and you design it and you put all the pieces together, and then you do a very robust quality assurance. Then that car drives off the factory lot. When you think about models that way, we spend all of our time focusing on the first part of the car/model lifecycle. All of the time that the car is in the factory, all the steps that it takes to get the model or the car out across the assembly line. But when you actually step back, you realize that the car is going to spend a lot longer outside of the factory than it will ever spend inside of the factory. Its life will extend far beyond the amount of time you spent building it.
That’s true for a model too. Most of the models that we build live in production for a lot longer than the time that they took to build and develop and deploy them. And as you think about a car that goes out onto the road, you start to think, what do you need, once you’ve deployed something, to know that it is still going to work in the real world? The real world is not the pristine factory environment where you have control over everything that you want control over. It needs to be robust to a very bruising environment that it exists within.
The main thing you need is diagnostics. You need to be able to understand what is changing for the model itself. (I’m going to switch back to models and no longer speak about cars cause I’m not an automotive engineer.) You need to be able to understand what is changing in the environment around the model. Models are static, right? We build and deploy models. The models themselves don’t necessarily change unless you’re deploying adaptive models. The model objects themselves are static, and so the things that change in the world around them are the data inputs and the way the model is used.
So, this model needs to be monitored relative to those two things: what is happening to the data, and how is the model being applied in the world? The way that you do that is typically twofold. On the data side, you are looking at changes in the distributions of the data. I’ll talk about some of the tools that we’re starting to develop on that front and open-sourcing those. But it’s important to look not just at the data itself. You also have to look at how the model is interacting with the data and then how the applications that are using the model are interacting with the model, because it’s an end-to-end system. The piece that connects the model to the application and the data is the explainability of the model. It’s the ability to, over time, look at: how is this model using the data to make predictions, and then how are those predictions being used by the application? That ties the whole thing together in a way that helps you understand if something has shifted in your environment.
Now, understanding if something has shifted in your environment is step one. You can’t just know that something has changed. You have to do something about it. There are a lot of different techniques and tactics that you can use. The importance of robust diagnostics over time allows you to decide which one of those things to do.
In the case of data-centric AI, you could be looking at the data. You could be understanding if there are changes in the data, in particular parts of the data that need to be reevaluated or re-analyzed or relabeled by human annotators. And that subsection of the data can be passed back into a human-in-the-loop system for analysis and for labeling. You could just be collecting more information or about specific subpopulations and using that to rebuild your models. Or you can just have a regular refitting cadence if you just know there’s a general stochastic process that needs to be updated periodically. But you don’t know any of those things, nor which of those mitigating strategies to take unless you have good diagnostics about the overall system and how it’s functioning in production.
One of the ways that we are improving diagnostics is building tools and frameworks. We’re building some of them ourselves. We rely on a lot of external tools, open-source tools and things coming out of academia. We take a holistic approach to this at Capital One. But we want to make sure we have standardized tooling for diagnostics around our models as they are being used.

One of these is a library that we open-sourced a little while back called the Data Profiler. The Data Profiler is a library that is really designed for understanding your data and understanding changes in the data and the schema over time. One of the principal ways that machine learning systems fail in production is that the data has changed. It can be in very blatant ways. For example, all of a sudden one of the features in your model is completely NaN values and you didn’t realize it, and now your model is not performing. It can be in very subtle ways, like the relationship between X and Y has changed and you didn’t know that. The Data Profiler is a tool that we developed to help us start to get more insight into what’s happening in our data.
It is essentially a Python library. You can pip install it. It accepts data of a variety of different types, whether that’s Parquet files, or Opera, or CSV and text files, et cetera. It gives you, in a very simple format, a profile of your data. A profile is just a summarization of the data that you’re using for a given model. Then, nicely, you can then compare those profiles over time. So every time your model runs—say, for a day—you get a snapshot of the model and the data, and you can say, “okay, has the data changed in a meaningful way?” You can do statistical tests to compare profiles over time to say, “has the data changed significantly?” You can also run on top of individual attributes within a profile, anomaly detectors and change-point detectors and things like that. All of these help you understand: are there meaningful changes in my data that need to be addressed? And then, once you have identified whether or not there are meaningful changes in your data, it gives you a forking path for how you can mitigate it and make decisions as to what you should be doing.
This is one example. We hope to contribute more in the future. We’d love for you to check it out. We think that this whole DCAI notion is going to be a really great opportunity for companies, industry, and academia to all collaborate in the ways that make us more robust in our deployments of machine learning across all industries.

When we step back and we think about this, really what we’re seeing is that data helps to facilitate a virtuous cycle. Data should ultimately serve the needs of its human generators. When we say human generators, we mean the people who are generating the data. The people who are, in our case, using our credit cards, using our mobile app, using our banking products. They’re the ones who are generating the data that we’re using. It is important that the data they are generating returns to them in a way that benefits them. A machine learning model is only effective if it’s running on the right data in the right environment and for the right use case. It’s that pairing or grouping of situations that make machine learning models truly beneficial to the people who generate the data that the machine-learning model is leveraging.
As we look at the future, it is an undeniable fact that both technology and the world are becoming more complex. When we deploy new technologies like machine learning and artificial intelligence, it is so critical that we keep the focus on building it and deploying it in a way that is responsible and well-managed, and in a way that puts people first. That creates this loop that benefits everyone.
And with that, I wanted to say thank you. It was a great opportunity to share some of what we’re doing in this space.
Question and Answer session
Kishore Mosaliganti: I believe there is one question in the Q&A panel. The first question is: with all major banks and credit card companies investing in AI, obviously Capital One is hiring and investing in AAA teams and platforms to keep AI/ML parity. Are there innovations or explorations you are hoping will differentiate Capital One?
Bayan Bruss: Absolutely. I think across all industries, machine learning and its application in industrial systems is fairly new, when you think about the broader time scales. Obviously it’s been around for a few decades in a lot of our systems. That being said, considering how new it is, the opportunity to do it in innovative new ways is critical to our success as a company. We would like to be at the forefront of a wide variety of advancements in the application of machine learning.
Primarily, what my team focuses on is working across our business—working with data scientists, engineers, as well as academic partners across a wide variety of universities— bridging that gap so that the things that are being discovered about how machine learning can solve problems in a new and exciting way can get into how we do business as quickly as possible. That’s where we really see our competitive advantage in this space. Shrinking that time from when some breakthroughs happen to when we can use it in a very high-grade industrial system is such a critical piece of what we do.
KM: Second question. Can you say more on how you are building your feature library? I can take that one.
Obviously in any given enterprise, there are thousands and hundreds-of-thousands of features that one could engineer and build. But there needs to be some priority order by which we consider how to build a feature library, how to group features and categorize them, and then how to join features at different scales—maybe at a customer scale or at a process level. All of this work needs to be done in some prioritized way. We take a look at some of our top use cases driving end-customer experience and use that to prioritize how we build out this library.
Another question. What’s an application you found best serves or delights the human generators of the input data? Bayan?
BB: I’m going to give that back to either you or Erin to talk about some of the ways that we use machine learning in our digital experiences.
Erin Babinski: One that I was thinking of is, we have insights often about your transactions. So for example, if you’ve paid for something twice, if you’ve made charitable contributions that’s helpful at tax season. But there’s also a lot that’s happening within our digital apps. Whether it’s finding the right information you need within those apps, or it’s getting a fraud alert based on activity that was recently encountered. There’s a fine line between bothering our customers to say, “was this you, was this used, can you verify?” versus getting it right, so that you can use your credit card, for instance, and not have friction using that card. But you also want to know if it’s being used fraudulently. There are a few different digital experiences that apply, but I think also even protecting your information, protecting your card, that’s an area where it’s been really important that we lean in to make sure we know when there’s something happening that we need to protect your information.
KM: Final question before we end the session. How are you looking at model evaluation for cases where data adapts rapidly? Wouldn’t it take time for data drift to be detected, labeled, and passed back to the model for training? Erin? Bayan? You want to answer that question? I can briefly start.
One of the ways in which we look to adapt models rapidly is by implementing processes whereby we are able to rapidly automate and scale the collection of labeled data and build tools for error correction and feedback, both into the model as well as to the upstream data engineering processes that are sending the data down to the model.
BB: I think there are a number of situations in which we do get feedback from customers very quickly. For instance, fraud is a great example. Most customers will report fraud as soon as they see it, or very shortly thereafter. And so the data adapts quickly. But, thankfully we get labels almost as quickly. And so we can approach that accordingly. There are a lot of other situations where the data might adapt, but the labels come in much later on, and that’s an area of active research, not just for us, but across academia as well.
PP: Awesome. Thanks so much, Bayan, for that answer, and to Erin, Kishore, all of you, really, for a great presentation. I especially loved some of the analogies to cars and other things. I know you’re not automotive specialists, but thanks so much for joining us here.
Catch the sessions you missed!
The Future of Data-Centric AI 2023, our two-day free virtual conference, brought together thousands of data scientists, AI/ML practitioners, researchers, and the AI community at large to hear about and discuss the latest trends and research in data-centric AI. If you registered for the event but didn't see all the sessions you wanted, you can now catch up. The recorded sessions are available for registrants at the same Zoom portal as the live sessions.

Recommended articles
View all articles

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 29, 2026
•

