As machine learning practitioners, few of us would expect the first version of a new model to achieve our objective. We plan for multiple rounds of iteration to improve performance through error analysis, and the Snorkel Flow platform provides tools to enable this kind of iteration within the data-centric AI framework.
Traditional, model-centric AI development focuses its iteration loop on the model itself. In this framework, the machine learning practitioner experiments with different architectures, engineers features, and tunes hyper-parameters while treating training data as a somewhat static artifact.
This approach has drawbacks. For example, there’s no way to isolate how changes in hyperparameters impact specific subsets of the data, which can leave us balancing between two kinds of errors. It can also be unclear what a change to a particular hyperparameter will actually do.
In contrast, it’s easy to understand the impact of increasing and improving your training data. If you add an accurately-labeled training point, the model will likely perform better on examples similar to it.
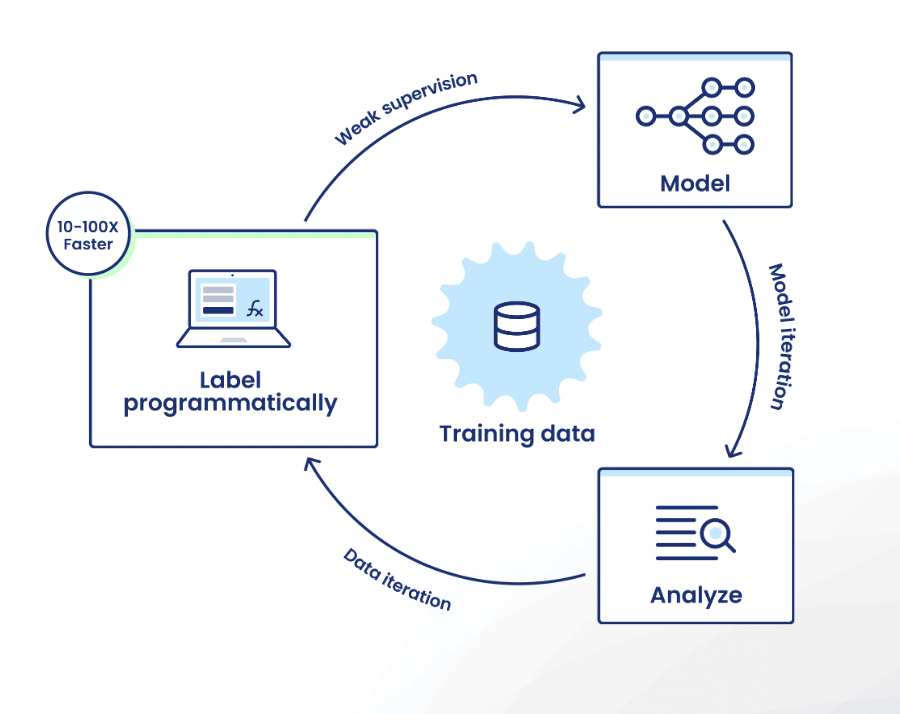
The Snorkel Flow iteration loop
Standard data-labeling approaches cost a lot of time, energy, and money. For complex or private data, this often requires collaborating with time-strapped subject matter experts, which can be so expensive as to make a project untenable.
Snorkel Flow eases this challenge with its programmatic, data-centric approach. If you’re not familiar with the Snorkel Flow platform, the iteration loop looks like this:
- Label programmatically: Encode labeling rationale as labeling functions (LFs) that the platform uses as sources of weak supervision to intelligently auto-label training data at scale.
- Model: Train proxy models for immediate label quality feedback.
- Analyze: Use a suite of analysis tools to identify shortcomings in both your model and your training data.
- Iterate: Capitalize on this analysis by adding or editing a few labeling functions.
We continue to release additional capabilities for step three. As of our 2022 year-end release, these features included
- Unsupervised confusion matrix.
- Streamlined tagging workflows.
- Improved tagging analysis.
- Auto-generated tag-based LFs.
- Labeling function quality analysis.
Let’s dive into a sample use case!
Scenario: Entity linking with payroll data and job classifications
I’m building an entity-linking app to connect job listings in a payroll system to a job categorization system developed by the Bureau of Labor Statistics. This should allow us to build aggregate statistics like “what are the pay bands of software engineers in Minneapolis, Minnesota?”.
We’ll receive two datasets:
- The job listings in the payroll system.
- Job categories.
Here’s a description of each entity:
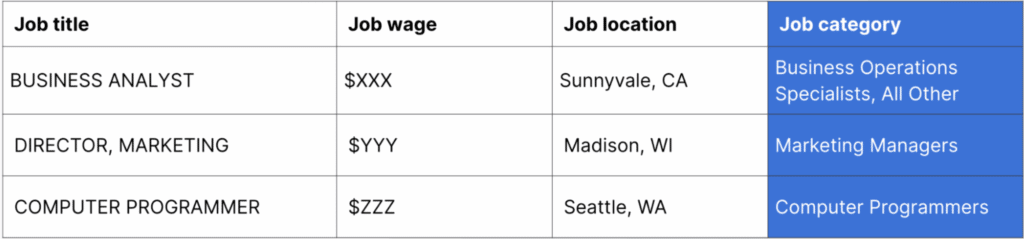
In the pipeline we’re developing, we’ll generate job/category pairs for every job listing, and then use a binary classifier to predict whether the job listing belongs to the job category. We call this process “entity linking.”
Step 1: Create baseline LFs with LF AutoSuggest and simple thresholding
I jump in and establish a foundation for our data set by writing a few use-case agnostic labeling functions.
Our entity-linking model will accept a variety of similarity metrics for two specified examples. This will include a metric for the job titles’ string similarities as well as the distance between their mean pay. The model will take these numerical values and calculate a final similarity metric along with a threshold by which to declare whether two titles refer to the same job.
So, a good initial LF is “If any of the similarity measures are three standard deviations away from the average, then it’s a match.” These won’t be perfect, but we don’t need them to be perfect; the label model can denoise any spurious outlier cases.
Step 1.5: Prepare ground truth data to unlock full analysis
While I write our initial labeling functions, our domain experts label a small amount of ground truth (GT) data using Snorkel Flow’s Annotator Suite. They use the streamlined interface to tab through examples and label them as “True” for matching pairs or “False” for non-matching pairs.
This should be quick. We need only enough ground truth examples to evaluate the strength of our labeling functions as we dive into the core workflow.
Step 2: AutoSuggestion and first-pass
Once our domain experts finish labeling a small amount of ground truth data, I can build more labeling functions quickly and easily. I run AutoSuggest, which will mine the labeled data for patterns and suggest LFs.
With several LFs written, we’re ready to create a training set. Snorkel Flow uses a label model to intelligently de-noise and reconcile the labeling functions. The label model outputs a large, probabilistic training data set that the platform can use to train a full ML model, which generalizes beyond the label model.
This initial model won’t be perfect, but that’s what error analysis is for.
Step 3: Train a model to understand data quality and model performance
Now, we’re going to go ahead and train a model from the model zoo. We’ll start with a simple logistic regression model. This model will ingest our similarity metrics as features—such as string similarities between names, differences between job wages, and the average wage for the job category.
This model achieves 88.8% precision for the True class. Our contract says that we should have at least 90% precision. Let’s see how we can get closer to that number.
Step 4: Error analysis to guide iteration in LF Quality view
Snorkel Flow offers several model-guided error analysis tools to give insight into where our model can improve. The LF Quality View shows us the behavior of our LFs on our small batch of hand-labeled data that we use as ground truth.
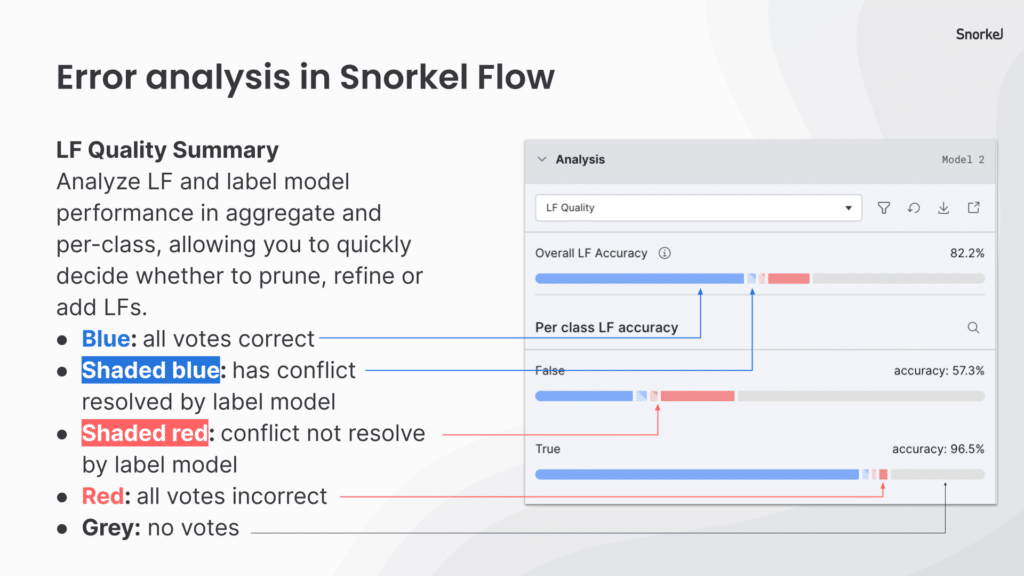
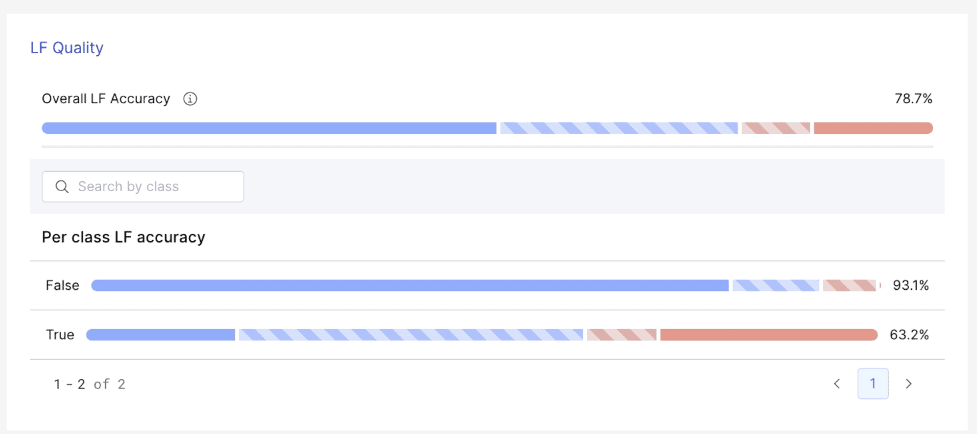
As you can see, we have 100% coverage, but our accuracy is quite low. Some of our automatically-generated baseline LFs need pruning or refinement. I use our histogram view to set more conservative thresholds.
After adjusting my labeling functions, I recreate the training set and train a new model. The champion-challenger view on our analysis page shows that the precision is above our 90% goal. Now, we can move on to improving the recall using open-ended analysis.
Step 5: Analyze errors to guide iteration: confusion matrices
Snorkel Flow includes a traditional ground truth confusion matrix as well as our margin confusion matrix. The margin confusion matrix uses active learning techniques to estimate the size of several error buckets. Since I care about increasing the model’s recall, I want to fix errors where our model incorrectly predicts that a job/category pair are different. I’ve been looking at the data points I labeled, and I don’t want to overfit on them. So, I’ll use our margin confusion matrix.
Clicking on a bucket in the confusion matrix will bring us to the data viewer, where we see the predicted errors in each bucket.
I thumb through the data and look for patterns. I see that the model confuses software engineering managers with software engineers, and biologists with biology teachers. I write two LFs that mark anything without manager or teacher agreement as non-matches.
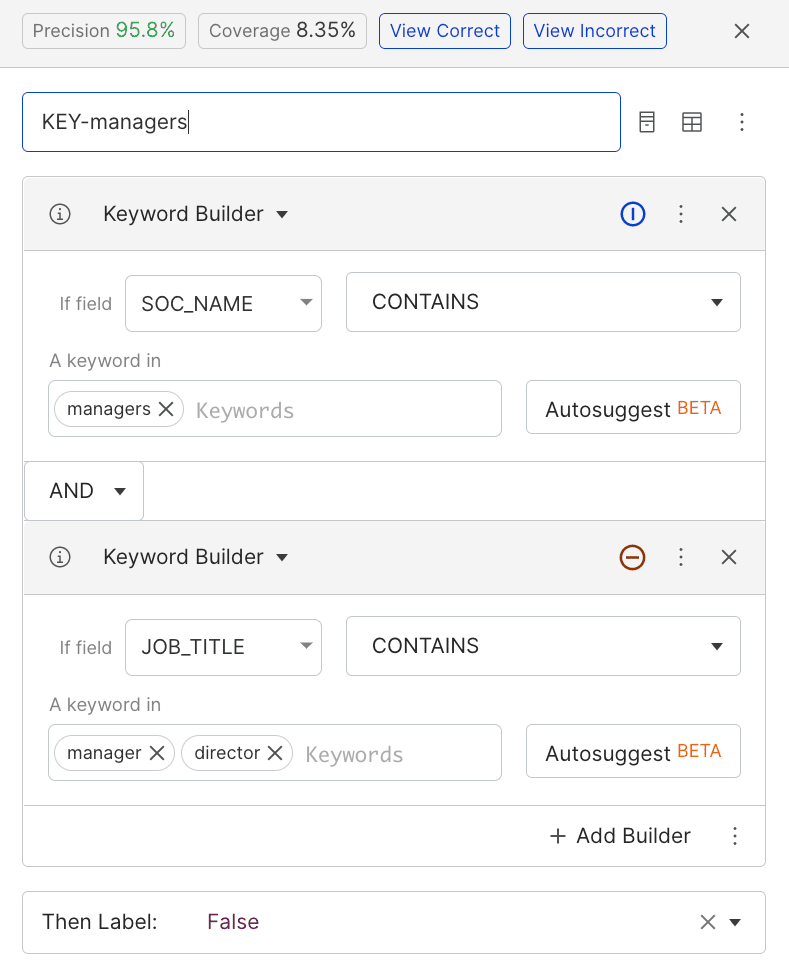
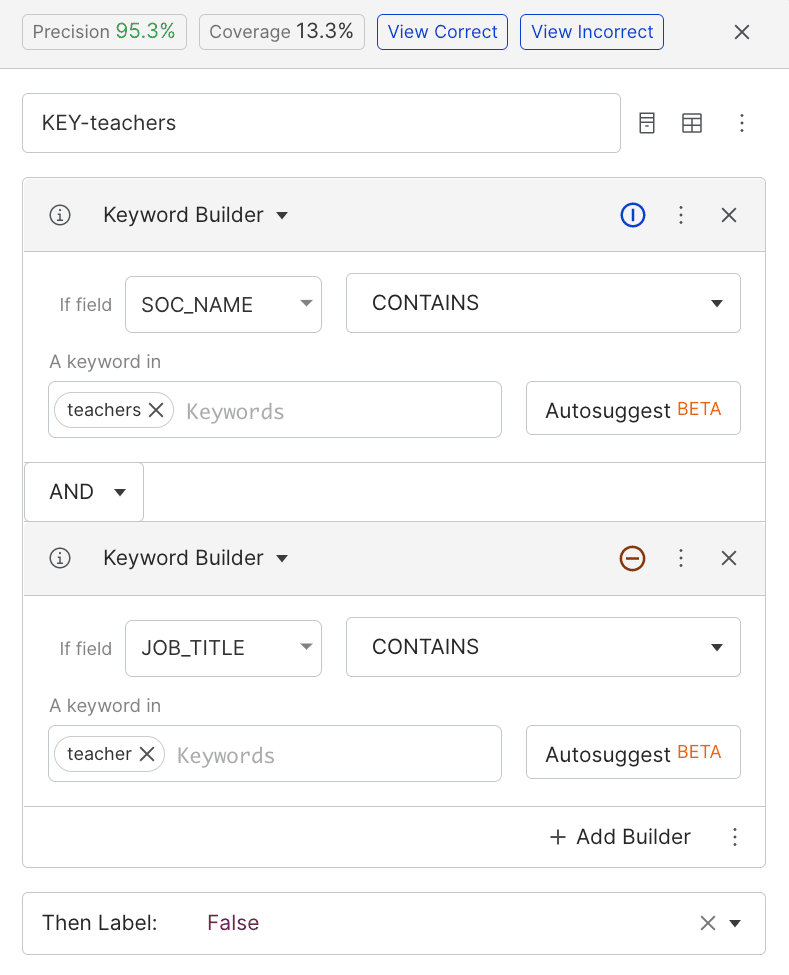
Both of these LFs have high precision and medium coverage. We see the recall improved slightly along with precision when we retrain with them, but we appear to be plateauing.
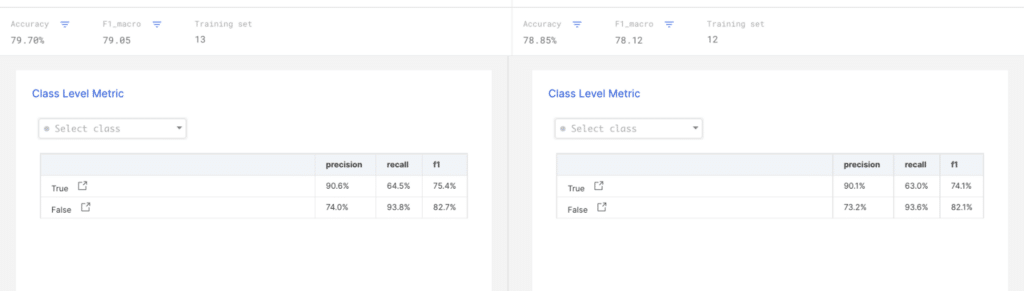
Step 6: Reporting and re-orienting with tag-based analysis
Using the confusion matrices, we notice a lot of subfield mistakes. Our model marked mechanical and chemical engineers as similar when they’re different professions. This error likely can’t be fixed by improving our training data. We use the search functionality to find similar examples and use the filter-to-tag option to tag them.
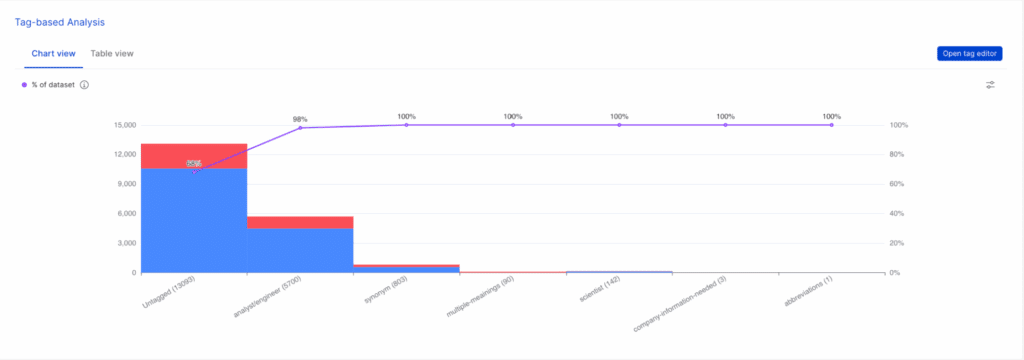
Clicking into tag-based analysis, a chart visualization of our tags shows that analyst/engineer mismatch and synonym tags account for most of our errors.
Results summary
In just a few iterations, we built a model with over 90% precision and 64% recall using a simple model architecture. While we could improve our performance by switching to a deep neural network architecture, we’re happy enough with this performance for the purpose of this demonstration.
This underscores the power of data-centric AI: building better training data creates more impact on the final model than anything else we can do as ML practitioners. However, without efficient labeling workflows, putting data-centric AI into practice can be out of reach.
To learn more about Snorkel Flow and see if it might serve your team, request a demo today.

Recommended articles
View all articles

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 29, 2026
•

Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration
June 25, 2026
•

