Snorkel AI just hosted the first day of The Future of Data-Centric AI conference 2022. This conference brings together data scientists, ML engineers, and AI leaders to share insights, best practices, and research on how to evolve the ML lifecycle from model-centric to data-centric approaches. This conference takes place over two days with 40+ sessions, 50+ speakers, and thousands of attendees from all around the world.
The first day at The Future of Data-Centric AI 2022 started by Aarti Bagul, a Snorkel AI ML Solutions Engineer and one of the conference hosts, warmly welcoming the audience and laying out the plan of the day for the attendees. The agenda included more than 27 talks across three tracks running in parallel: Data, Techniques, and Applications. Don’t worry if you are like me and want to see more sessions than you can catch live: you will be able to watch all of them later on at future.snorkel.ai.
This article will provide highlights from day one, including the morning keynote talks and a handful of the many-track talks of this first day.
Specifically, I will cover 12 out of 27 sessions:
- Operationalizing Knowledge for Data-Centric AI by Alex Ratner, CEO and Cofounder, Snorkel AI
- Fireside chat: Adopting Data-Centric AI in Financial Services with Ron Papka, Head of Modeling, NLP, and Analytics for Global Banking Technology, Bank of America by Henry Ehrenberg, Co-founder, Snorkel AI
- Knowing, Getting and Using Cyber Data To Enable Your Cyber Team to be Proactive and Preemptive by Rich Baich, Chief Information Security Officer, CIA
- Scaling NLP to the Next 1,000 Languages by Sebastian Ruder, Research Scientist, Google
- Combining Human and AI with Human-in-the-Loop ML by Daniel Wu, Head of AI & Machine Learning, Commercial Banking, JPMorgan Chase
- Real-Time Machine Learning by Chip Huyen, Co-founder & CEO, Claypot AI
- Transforming Drug Discovery Using Digital Biology by Daphne Koller, CEO and Founder, Insitro
- Lightning talk: Data-Centric AI at the Smithsonian Institution by Mike Trizna, Data Scientist, Smithsonian Institution
- Lightning talk: Hyperproductive ML with Hugging Face by Julien Simon, Chief Evangelist, Hugging Face
- Extracting the Impact of Climate Change from Scientific Literature Using Snorkel-Enabled NLP by Prasanna Balaprakash, R&D Lead and Computer Scientist, Argonne National Lab
- Data-Centric AI at Comcast in Voice and Conversational Interfaces by Jan Neumann, VP, Machine Learning, Comcast
- Applying Engineering Practices to Data-Centric AI by Matei Zaharia, Chief Technologist, Databricks
Yes—these are a lot of interesting and diverse sessions to listen to for anyone interested in learning more about data-centric AI with valuable insights to take away. You’ll be able to find even more on future.snorkel.ai once the recordings are available.
Before we dive in, make sure to join us for Day 2 sessions, where Xuedong Huang, CTO of Azure AI at Microsoft will kick off the sessions with his talk: A Wholistic Representation Towards Integrated AI. Register on future.snorkel.ai.
Operationalizing knowledge for data-centric AI
Snorkel AI’s co-founder and CEO, Alex Ratner, laid the foundation for day 1 by covering the essential cliff-notes of data-centric AI. He then dove deeper into the core topic of his talk, providing a roadmap for how AI/ML teams can make far better use of all knowledge relevant to their AI problems, both from within and outside of their organization. Alex highlighted how programmatic labeling operationalizes knowledge across three examples: existing manual data annotations, organizational resources, and foundation models. Existing manual annotations, even when imperfect, can be optimally integrated when Snorkel Flow estimates the accuracies and expertise areas of manual annotators. Existing organizational resources such as ontologies or rule-based systems, which are rigid on their own, provide valuable signal for weak supervision. Finally, knowledge from foundation models, which is vast but offers limited expertise against domain-specific problems, can be extracted during development and used to train faster, less expensive that run in production.
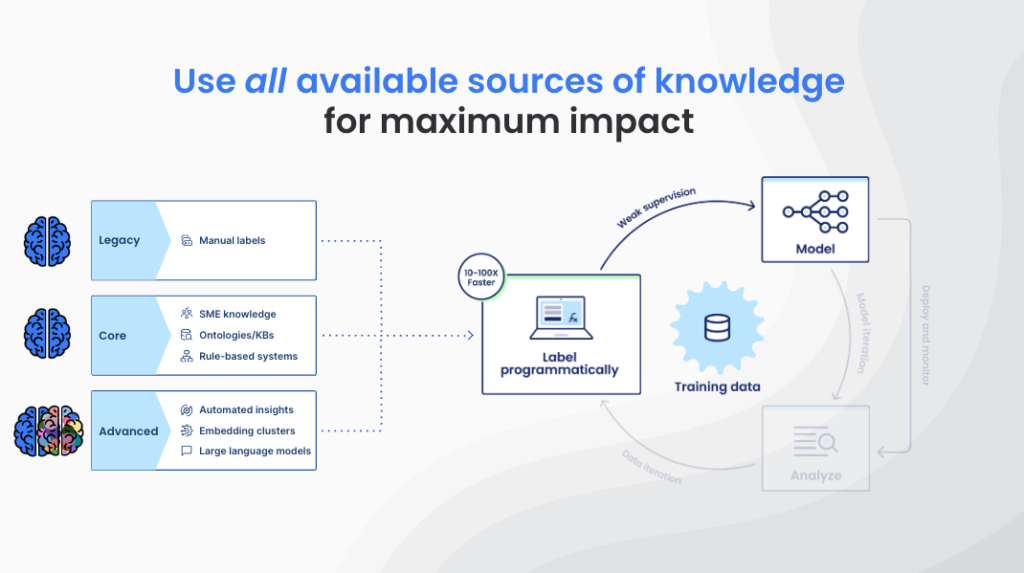
“Foundation models still need significant training and development—teaching—to zero in and perform at quality against your specific problems. Programmatic labeling is the bridge between this rich knowledge and practical use.”
Alex Ratner
CEO and Cofounder, Snorkel AI
Fireside chat: Adopting data-centric AI in financial services
This session was hilarious! It started with a technical issue—as with all online (or even in-person) events. Ron was unable to hear Henry’s questions but advanced preparation helped them stay astonishingly in sync. Ron Papka, Head of Modeling, NLP, and Analytics for Global Banking Technology, discussed how data-centric AI is used in financial services like banking and the challenges of introducing new technologies in Fortune 500 companies more generally. He mentioned the importance of humans-in-the-loop as well as the difficulty of retaining expert knowledge in data and within the team. Ron talked in depth about the pitfalls of bias in AI and how data-centricity along with SME collaboration can be used to manage or mitigate some of these critical challenges.
”When using AI for credit decisions, you have to make sure you’re not excluding groups because of your AI, or that you’re not building models that inadvertently create ‘clubs.’ Always need to look at unintended consequences of AI”
Ron Papka
Head of Modeling, NLP, and Analytics for Global Banking Technology, Bank of America
Ron continued with how change can be introduced to Fortune 500-scale organizations. He highlighted that to uncover use cases, “AI teams need to build relationships with stakeholders to drive more opportunities with motivated partners. There’s a tremendous backlog of opportunities in financial services, especially with NLP. At Bank of America, literally every week someone has another idea they want to implement using AI.”
Knowing, getting and using cyber data to enable your cyber team to be proactive and preemptive
This session was both fascinating and complex, especially for someone (like myself) with no cyber security background. Still, it opens your eyes to all the challenges behind making a platform secure to use especially for mission-critical purposes. Joseph “Rich” Baich, CIA’s Chief Information Security Officer (CISO) and Director of the Office of Cyber Security (OCS) discussed what AI and ML mean in the cyber context and how cyber operators can use ML in their job to make software safer. For example, one way AI can improve efficiency is by automatically replacing easily exploitable classic “admin/admin” passwords. Rich puts emphasis on the importance of automating tasks and having good practices in place instead of “patching” exploits and concludes by answering a few very interesting questions by the viewers such as how the government (and more precisely the CIA) uses AI. The answer: they use AI to take the human out of it as much as possible to allow them to focus on areas we can’t automate yet. That raises an interesting question: what happens when everything is automatable? Will we end up with only algorithms fighting to hack each other?
Scaling NLP to the Next 1,000 Languages
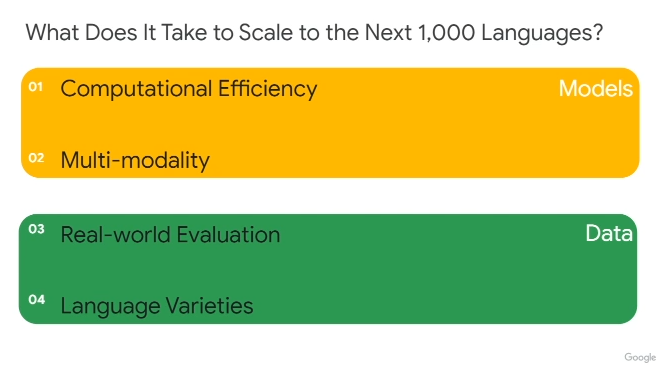
In this session, NLP expert and Google senior research scientist Sebastian Ruder covered the challenges of developing multilingual models, particularly for “smaller or low resource languages” mostly spoken and not available online. Languages like Vietnamese, Swahili, Hindi, Thai, Urdu, Bengali are spoken by a large population of people but not on the internet. Sebastian described four main challenges: computational efficiency, multi-modality (being able to jointly use text and speech for training models), real-world evaluation (difference between training data and the real world), and language varieties (e.g. varieties within Chinese languages). He then described each of these,and suggested research avenues to tackle them. Sebastian also underscored the importance of community efforts such as BLOOM and the difference between one bigger model (e.g. NLLB-200) versus having multiple smaller models for multilingual approaches all while answering great questions from the audience.
Combining Human and AI with Human-in-the-Loop ML

This insightful talk by Daniel Wu, Head of AI & Machine Learning at Commercial Banking JPMorgan Chase, covered Human-in-the-Loop (HITL) AI systems. Daniel started by defining HITL and how it can improve model quality. He followed with problems tackled using HITL and how it enables us to transfer human intelligence to our code. Daniel then shared a few examples of real-world applications using HITL and best practices for AI teams.
Real-Time Machine Learning
In this session, well-known Chip Huyen, co-founder of Claypot AI, author, blogger, AI influencer, and ex-Snorkeler, covered real-time machine learning in three steps. Starting with online predictions, Chip shared how to achieve efficient predictions using multiple techniques such as batch predictions and batch features. Chip followed with challenges using both online and offline features to make decisions, such as ETA tasks and which tasks can be tackled in the real world using continual learning. She then spoke comprehensively about using continual learning in a real-time application and how to maintain such a model. This is an excellent talk for any hands-on person that wants to learn more about online, dynamic applications.
Transforming Drug Discovery Using Digital Biology
Very interesting talk by CEO and co-founder of Insitro Daphne Koller on how the confluence of data and biology can accelerate drug discovery (and lower drug costs) thanks to AI! Daphne shared that 95% of the drugs discovered are never approved and distributed—a big issue for research costs and discovery efficiency. This is where ML comes into play to help fix this efficiency issue and, hopefully, the production of fewer unused drugs in the future. In this practical yet incredibly inspiring talk, Daphne covered the different ways machine learning can address those efficiency issues, mainly using self-supervision to uncover genetic drivers, biomarkers, and more that can be used to identify patient populations predisposed to diseases. These patterns would be undiscoverable by humans, even those with extensive expertise, given the sheer volume of biometric data at play. Daphne described what they are currently doing at Insitro and provided insights in what she called the “Digital Biology” field.
95% of the drugs discovered are never approved and distributed—a big issue for research costs and discovery efficiency.”
Daphne Koller
CEO and Co-founder, Insitro
Lightning talk: Data-Centric AI at the Smithsonian Institution
In this 10-minute lightning talk, Mike Trizna, a data scientist at the Smithsonian Institution, gave a quick background on the Smithsonian Institution and shared how the work of a data scientist at such a unique institution is inherently interesting. They have access to millions of objects and data to digitize for AI projects; one example he covered is how they built a species detector for plants. The application they built, linksplant shapes to geography using data they have at their fingertips about plants across the world. Mike also shared how AI is used to correct mis-gendering and accurately represent research contributions. If you are into data and building innovative and cool history-related algorithms – this is a worthwhile short talk and a job for you.

Lightning talk: Hyperproductive ML with Hugging Face
In a second 10-minute talk, Julien Simon, Chief Evangelist at Hugging Face, demonstrates how the company is delivering on its mission to democratize ML by making it as simple, straightforward, and accessible as possible. Julien gave a tour of the Hugging Face interface showing how easy it is to find a relevant model (from more than 60K options) using tags and searches, quickly implement models and datasets, and even build a user interface to convey the model’s value outside of a notebook. He emphasized the importance of the last utility—applications to make models and their impact real—as a key step for building buy-in and engagement among non-technical stakeholders, business partners, and budget-approvers—a key takeaway from this talk that we cannot argue with.
Extracting the Impact of Climate Change from Scientific Literature Using Snorkel-Enabled NLP
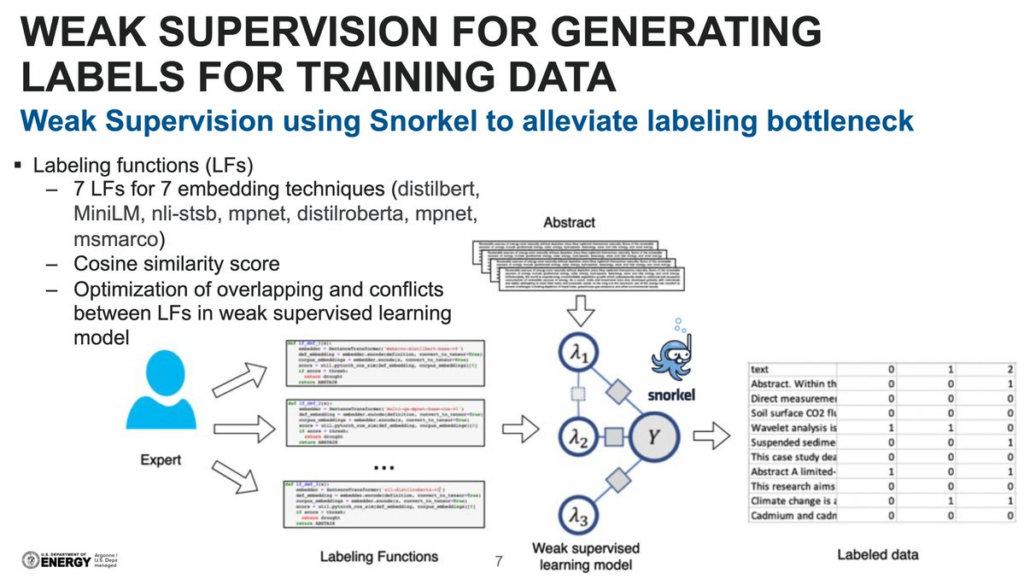
In this session, Prasanna Balaprakash, R&D lead and computer scientist at Argonne National Laboratory, demonstrated using Snorkel-enabled NLP to extract the impact of climate change from the scientific literature. Yes, climate change does exist, and it does impact our world! Prasanna emphasized this critical issue, how it impacts our world, and how machine learning can be leveraged to understand the effects of climate change. He covered how to extract relevant data (especially low-occurring events as in anomaly detection) and what is the infrastructure of such a project. He continued with how to manage and label data with weak supervision, thanks to Snorkel’s labeling functions (LF). Finally, he covered the model’s training process and data/results analysis. This is an amazing session to have a hands-on example of Snorkel’s toolset for a concrete NLP data labeling application.
Data-Centric AI at Comcast in Voice and Conversational Interfaces
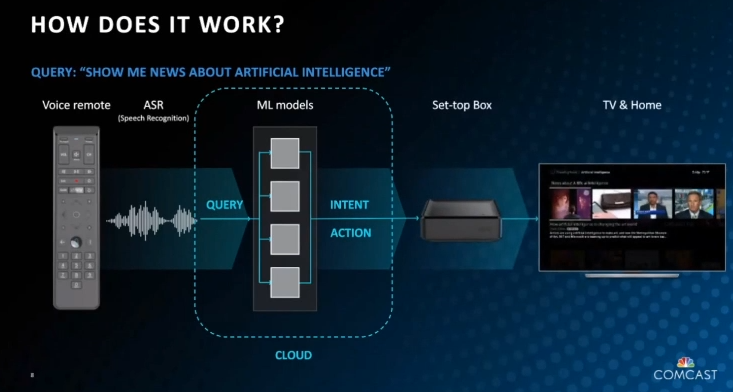
In this session, Jan Neumann, Vice President of Machine Learning at Comcast, dove into their voice and NLP use cases, challenges, and approaches. Jan walked through the whole process from experimentation, data, and how data-centric AI helps their platform. He described how the Comcast voice remote works, from the voice gathering and voice understanding (speech and NLP with encoders and decoders, how to prepare data (hint: using labeling functions!) and train the models for such a complex task), up to the actions performed on the TV. He detailed the challenges of short, diverse queries coupled with a high-degree of ambiguity in phrases before breaking down how the Comcast team solved for these with a variety of techniques, including synthetic data. This is a fantastic and insightful talk for audio AI enthusiasts or professionals to understand better real-world challenges and steps in this highly technically-challenging application.
Applying Engineering Practices to Data-Centric AI

What a fantastic talk to end Day 1! In this last session of the day, Matei Zaharia, Assistant Professor of Computer Science at Stanford University and Chief Technologist at Databricks discussed how to take inspiration from data and ML engineering as you design your platform and processes for data-centric AI development. Matei posed a critical question: “what ideas can we actually transfer to DCAI?”. He then dove into the five matters mentioned in the image above covering the “what, why, how” of all those crucial points. A worthwhile talk for DCAI professionals or students getting into the field to get a real-life overview of what actually happens in practice when using these data-centric approaches.
Join us for day 2
This concludes Day 1 of the Future of Data-Centric AI event. Fortunately, from every ending comes a new beginning, and this one is exciting! As you can see, Day 1 had many amazing talks from a wide variety of speakers and backgrounds, covering data labeling automation, techniques and workflows to accelerate AI, and NLP applications of data-centric AI. Well, Day 2 is no different, with over 25 talks covering these topics and more in-depth. Here are a few of my favorites to whet your appetite:
- Adopting Data-Centric AI at Enterprise Scale – a panel discussion by Devang Sachdev, VP of Marketing, Snorkel AI with Richard Finkelmen, Managing Director, Berkeley Research Group LLC and Sourabh Deb, SVP, Artificial Intelligence Centre of Excellence (AI COE), Citi
- Machine Learning at Bloomberg by Gary Kazantsev, Head of Quant Technology Strategy, Bloomberg
- Unmasking Human Trafficking Risk in Commercial Sex Supply Chains With Machine Learning by Hamsa Sridhar Bastani, Assistant Professor of Operations, Information, and Decisions, Wharton School, University of Pennsylvania
- Closer look at Fairness in Job Ecosystem by Sakshi Jain, Senior Manager, Responsible AI, Linkedin
- MLCommons and Public Datasets by Peter Mattson, Senior Staff Engineer, Google
- And many more
I hope to see you there!

Recommended articles
View all articles

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•

The Art and Science of Building AI Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build AI benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents with
June 16, 2026
•
Snorkel Team

Cua-Bench: benchmarking computer-use agents on professional software
TL;DR We built a benchmark of 25 expert-authored KiCad schematic-editing tasks and ran a frontier computer-use agent against them. The headline numbers: 1. Why build a computer-use benchmark for electrical engineering? Most computer-use benchmarks today live in the same handful of apps: web browsers, file managers, generic productivity suites. Those evaluations are useful, but they share a structural weakness —
June 15, 2026
•
,

