AI systems are well-suited to tasks involving recognizing and predicting data patterns. Supervised classification systems categorize unseen data into a finite set of discrete classes by learning from millions of hand-labeled labeled sample points. These classifiers are powerful business tools – they automate document sorting, customer sentiment analysis, sales performance, and other distinct business problems. However, they also require an immense amount of labeled examples that are arduous and expensive to acquire. In particular, multi-label classification problems reveal a Herculean challenge in data management.
A brief overview of classification problems
Binary classifiers decide between exactly two options (such as determining whether or not an e-mail is spam or not spam). Multi-class classifiers generalize further, selecting exactly one out of many possible classes. Multi-class classification problems rear their heads often in the real world, from text recognition (each symbol must map to one character) to image classification (determine whether we are looking at an image of a cat, bird, or dog).
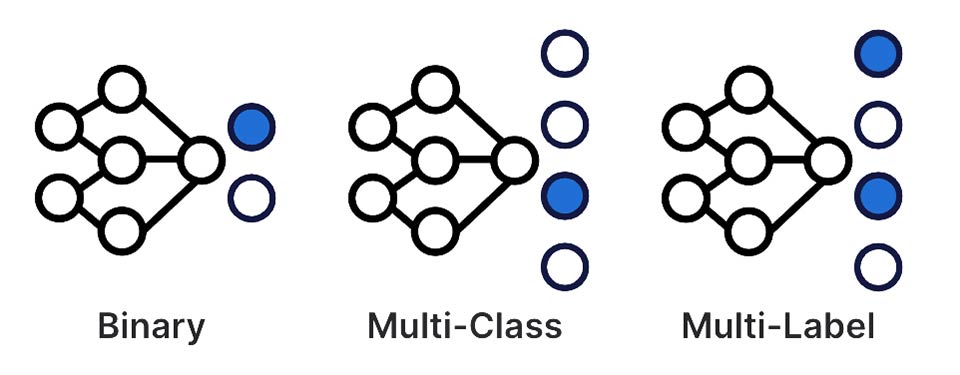
The third class of classification problem removes the mutual-exclusivity condition imposed by the binary and multi-class cases. Multi-label classifiers operate assuming that a single data point may belong to multiple classes simultaneously. For example, an e-mail can be labeled simultaneously as both “personal” and “urgent.” An insurer may wish to tag claims with multiple possible types of insurance risk.
Data-centric solutions to multi-label classification challenges
For supervised classification to be effective, modern-day AI models demand enormous amounts of labeled training data. Acquiring this labeled data can be costly in terms of time and money—this bottleneck stops many AI projects from ever getting off the ground. Binary and multi-class applications have the benefit of mutual exclusivity; if an underwriter at a bank labels a document as a “loan,” that document cannot be classified as anything else. An annotator only needs to assign a single label to each document in the training dataset.
Label volume
The hand-labeling process for single-output problems is already laborious – the multi-label problem with k classes multiplies the work k-fold. Now, every document requires a decision on every class, since a single class being present for a document does not mean every other class is absent. Multiple classes may be present at once (and multiple may be absent); we lose the guarantee of mutual-exclusivity that exists in multi-class applications. For k classes, you are faced with what reduces to k independent binary decisions on each of your n datapoints; labeling n documents now becomes a task of assigning n * k labels.
Programmatic labeling is a powerful tool that is made even more powerful in a multi-label context. Snorkel’s enables programmatic labeling, where data scientists and subject matter experts can leverage their domain expertise to assign probabilistic labels to huge chunks of training data. Labeling functions – user defined heuristics that capture domain knowledge and external supervision sources – scale exceptionally well in multi-label domains, where individual labeling functions can assign labels to multiple classes at once.
Snorkel Flow’s built-in auto-suggest features capture the most important features (relative n-gram frequency, etc) for each label class, and intelligently suggest labeling functions that identify those classes. Our multi-label model zoo consists of a suite of off-the-shelf classical and deep learning models, from multi-label logistic regression to deep-learning-based classifiers. Snorkel Flow’s AutoML capabilities offer a one-click solution to hyperparameter search and model selection. These capabilities combine to streamline the O(n * k) volume problem and make it accessible to even small teams with limited resources.
Non-mutual exclusivity
In a multi-label setting, we are now tasked with not only providing signals when a class is present, but also when it is absent. Labeling functions are effective when we can express domain expertise and human rationales for why we consider specific examples to be present for a label; the definitions for when a class is present are intuitive. Identifying patterns for when a label is not present, however, is more challenging. In the example of assigning multiple tags to e-mails, it may be straightforward to determine whether an e-mail can be tagged as “personal”; it is much less straightforward to narrow down the specific rules and qualities for when an email is not personal.
Snorkel promotes a number of approaches to minimize the challenge with unintuitive or challenging “absent” signals. A quick way to bootstrap Snorkel’s iterative workflow is to begin with a swath of very broad absent-voting labeling functions that apply to a large number of data points. This broad set of baseline labeling functions act as a wide prior that can then be refined to more accurately model the absent-condition for each label. For example, a “not personal” labeling function could vote on the condition “any document that does not contain an emoji.” These broad labeling functions may start out with low precision; however, a key strength of the weak supervision approach is the ability to model the noise in a body of noisy labels and determine how to intelligently resolve it.
Iterating in multi-label workflows
The multi-label problem has an advantage over a multi-class formulation in that we may try to leverage the correlations between label classes to bootstrap labeling function generation. Classes in multi-label applications can be, and often are, correlated – for example, an e-mail that is “personal” is also likely to be tagged as “health,” “family,” or “travel.” When classes like these co-occur, it’s a strong sign that labeling functions that can apply to one of these classes will naturally extend to several of them. Classes also naturally sort into hierarchies, especially in settings where the number of classes is large. Thinking about multi-label problems in this hierarchical way may also reveal how to extend existing labeling functions to cover additional classes.
Specific labeling function improvements may also be discovered by way of Snorkel’s suite of analysis tools, which give actionable suggestions for labeling function and end model improvement. Snorkel allows for analysis at the per-class level, where each label class receives its own collection of statistical analysis tools, ranging from standard precision-recall curves to active-learning-based iterative workflows.
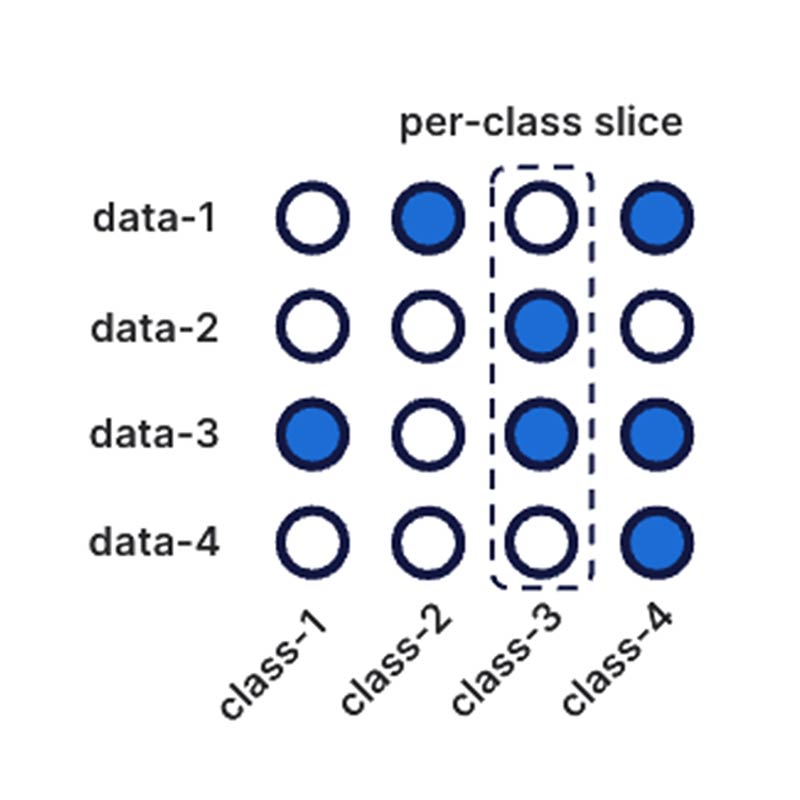
Snorkel customers have been able to tackle multi-label classification problems with thousands of unique classes using some of the methods outlined here. Snorkel Flow’s extensive suite of automated tools and visualizations make it straightforward to write high-quality labeling functions. Approaching multi-label classification from a data-centric point of view massively lowers the barrier to entry to tackling key business challenges, as the task of answering the n * k possible per-class binary questions becomes simplified in a clean, intuitive workflow.
Interested to learn more about Snorkel Flow? Sign up for a demo and follow Snorkel AI on Linkedin, Twitter, and Youtube.
Featured photo by Kelly Sikkema on Unsplash.

Recommended articles
View all articles

Cua-Bench: benchmarking computer-use agents on professional software
TL;DR We built a benchmark of 25 expert-authored KiCad schematic-editing tasks and ran a frontier computer-use agent against them. The headline numbers: 1. Why build a computer-use benchmark for electrical engineering? Most computer-use benchmarks today live in the same handful of apps: web browsers, file managers, generic productivity suites. Those evaluations are useful, but they share a structural weakness —
June 15, 2026
•
,

The Standard for Agents You Can Trust: Lessons from the Federal Front Lines
In the first installment of Agentic in Action — a series about real AI deployments, not demos — Snorkel AI’s Kevin Olivieri sat down with three people who have spent their careers where trust isn’t optional: Chris Sniffen, Federal Applied AI Lead at Snorkel AI; John Hickey, President of August Schell; and Mike Baca, CIO of August Schell. The conversation focused on
June 5, 2026
•
Snorkel Team

Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration
At our latest Snorkel AI Reading Group, Yijia Shao (Stanford NLP) stopped by our San Francisco office to present Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration. As LLM agents get better at automating tasks on their own, a large class of real-world problems still needs a human in the loop – for their preferences, their domain expertise, or simply for control.
June 4, 2026
•

